
Che cos'è il classificatore Naive Bayes? [Spiegato con un esempio]
Pubblicato: 2020-12-28Ci sono così tanti casi in cui si lavora su machine learning (ML), deep learning (DL), mining di dati da un insieme di dati, programmazione su Python o elaborazione del linguaggio naturale (NLP) in cui è necessario differenziare i discreti oggetti basati su attributi specifici. Un classificatore è un modello di apprendimento automatico utilizzato allo scopo. Il classificatore Naive Bayes è il punto cruciale di questo post sul blog che impareremo ulteriormente.
Teorema di Bayes
Il matematico britannico reverendo Thomas Bayes, il teorema di Bayes è una formula matematica utilizzata per determinare la probabilità condizionata, che è la probabilità che un risultato si verifichi sulla base di un risultato precedente.
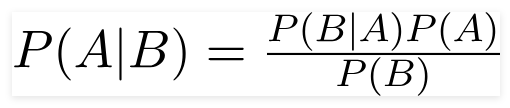
Fonte
Usando questa formula, possiamo trovare la probabilità di A quando si è verificato B.
Qui,
A è la proposizione;

B è l'evidenza;
P(A) è la probabilità a priori della proposizione;
P(B) è la probabilità a priori dell'evidenza;
P(A/B) è chiamato il posteriore e
P(B/A) è chiamata verosimiglianza.
Quindi,
Posteriore = (Probabilità)(Proposizione in probabilità a priori)
_________________________________
Evidenza Probabilità a priori
Questa formula presuppone che i predittori o le caratteristiche siano indipendenti e che la propria presenza non influisca sulla caratteristica di un altro. Quindi, è chiamato "ingenuo".
Esempio di visualizzazione del classificatore Naive Bayes
Stiamo prendendo un esempio di una migliore comprensione dell'argomento.
Dichiarazione problema:
Stiamo creando un classificatore che descrive se un testo riguarda lo sport o meno.
I dati di allenamento hanno cinque frasi:
| Frase | Etichetta |
| “Un grande gioco” | Gli sport |
| “Le elezioni erano finite” | Non sport |
| “Fiammifero molto pulito” | Gli sport |
| “Sono state elezioni serrate” | Non sport |
| “Un gioco pulito ma dimenticabile” | Gli sport |
Qui, devi trovare la frase "Un gioco molto vicino" di quale etichetta?
Naive Bayes, come classificatore, calcola la probabilità della frase “Un gioco molto vicino” è Sport con la probabilità ' Non Sport.'
Matematicamente, vogliamo conoscere P (Sport | un gioco molto vicino), probabilità dell'etichetta Sport nella frase "Un gioco molto vicino".
Ora, il passo successivo è calcolare le probabilità.
Ma prima, diamo un'occhiata ad alcuni concetti.
Ingegneria delle funzionalità
Dobbiamo prima determinare le funzionalità da utilizzare durante la creazione di un modello di machine learning. Le caratteristiche sono i frammenti di informazioni dal testo forniti all'algoritmo.
Nell'esempio sopra, abbiamo i dati come testo. Quindi, dobbiamo convertire il testo in numeri in cui eseguiremo i calcoli.
Quindi, invece del testo, useremo le frequenze delle parole che ricorrono nel testo. Le caratteristiche saranno il numero di queste parole.
Applicazione del teorema di Bayes
Convertiremo la probabilità da calcolare utilizzando il conteggio della frequenza delle parole. Per questo utilizzeremo il teorema di Bayes e alcuni concetti base di probabilità.
P(A/B) = P(B/A) x P(A)
______________
P(B)
Abbiamo P (Sport | un gioco molto vicino), e usando il teorema di Bayes, annulleremo la probabilità condizionata:
P (sport/un gioco molto ravvicinato) = P(un gioco molto ravvicinato/sport) x P(sport)
________________________
P (un gioco molto serrato)
Abbandoneremo lo stesso divisore per entrambe le etichette e confronteremo
P(un gioco molto vicino/Sport) x P(Sport)
Insieme a
P(un gioco molto vicino/Non Sport) x P(Non Sport)
Possiamo calcolare le probabilità calcolando i conteggi la frase “Un gioco molto vicino” emerge nell'etichetta 'Sport'. Per determinare P (un gioco molto vicino | Sport), dividilo per il totale.
Ma, nei dati di allenamento, "Un gioco molto vicino" non sembra da nessuna parte, quindi questa probabilità è zero.
Il modello non sarà di grande utilità senza che ogni frase che vogliamo classificare sia presente nei dati di allenamento.
Classificatore ingenuo di Bayes
Ora arriva la parte fondamentale qui, ' Ingenuo.' Ogni parola in una frase è indipendente dall'altra, non stiamo guardando le frasi intere, ma le singole parole. Ulteriori informazioni sul classificatore bayes ingenuo.
P(un gioco molto vicino) = P(a) x P(molto) x P(vicino) x P(gioco)
Questa presunzione è potente e anche utile. Il passaggio successivo consiste nell'applicare:
P(un gioco molto vicino/Sport) = P(a/Sport) x P(molto/Sport) x P(vicino/Sport) x P(gioco/Sport)
Queste singole parole compaiono molte volte nei dati di addestramento che possiamo calcolare.
Probabilità informatica
Il passo finale è calcolare le probabilità e guardare quale è più grande .
Innanzitutto, calcoliamo la probabilità a priori delle etichette: per le frasi nei dati di addestramento dati. La probabilità che sia Sport P (Sport) sarà ⅗ e P (Non Sport) sarà ⅖.
Nel calcolare P (gioco/Sport), contiamo le volte in cui la parola “gioco” appare nel testo Sport (qui 2) divisa per le parole in sport (11).

P(gioco/Sport) = 2/11
Ma la parola "vicino" non è presente in nessun testo sportivo !
Ciò significa P (chiudi | Sport) = 0 ed è scomodo poiché lo moltiplichiamo con altre probabilità,
P(a/Sport) x P(molto/Sport) x 0 x P(gioco/Sport)
Il risultato finale sarà 0 e l'intero calcolo verrà annullato. Ma questo non è ciò che vogliamo, quindi cerchiamo un altro modo per aggirare.
Levigatura Laplace
Possiamo eliminare il problema di cui sopra con il livellamento di Laplace, dove sommiamo 1 per ogni conteggio; in modo che non sia mai zero.
Aggiungeremo le possibili parole numeriche al divisore e la divisione non sarà superiore a 1.
In questo caso, l'insieme delle possibili parole sono
['a', 'great', 'very', 'over', 'it', 'but', 'game', 'match', 'clean', 'election', 'close', 'the', ' era', 'dimenticabile'] .
Il numero possibile di parole è 14; applicando la levigatura Laplace,
P(gioco/Sport) = 2+1
___________
11+14
Risultato finale:
| Parola | P (parola | Sport) | P (parola | Non Sport) |
| un | (2 + 1) ÷ (11 + 14) | (1 + 1) ÷ (9 + 14) |
| molto | (1 + 1) ÷ (11 + 14) | (0 + 1) ÷ (9 + 14) |
| chiudere | (0 + 1) ÷ (11 + 14) | (1 + 1) ÷ (9 + 14) |
| gioco | (2 + 1) ÷ (11 + 14) | (0 + 1) ÷ (9 + 14) |
Ora, moltiplicando tutte le probabilità per trovare quale è più grande:
P(a/Sport) x P(molto/Sport) x P(gioco/Sport)x P(gioco/Sport)x P(Sport)
= 2,76 x 10^-5
= 0,0000276
P(a/Non Sport) x P(Molto/Non Sport) x P(Gioco/Non Sport)x P(Gioco/Non Sport)x P(Non Sport)
= 0,572 x 10 ^-5
= 0,00000572
Quindi, abbiamo finalmente ottenuto il nostro classificatore che dà "Un gioco molto vicino" l'etichetta Sport poiché la sua probabilità è alta e deduciamo che la frase appartiene alla categoria Sport.
Checkout: Spiegazione dei modelli di machine learning
Tipi di classificatore ingenuo di Bayes
Ora che abbiamo capito cos'è un classificatore Naive Bayes e abbiamo visto anche un esempio, vediamo i tipi di esso:
1. Classificatore multinomiale Naive Bayes
Viene utilizzato principalmente per problemi di classificazione dei documenti, indipendentemente dal fatto che un documento appartenga a categorie come politica, sport, tecnologia, ecc. Il predittore utilizzato da questo classificatore è la frequenza delle parole nel documento.
2. Classificatore Bernoulli Naive Bayes
Questo è simile al classificatore multinomiale Naive Bayes, ma i suoi predittori sono variabili booleane. I parametri che utilizziamo per prevedere la variabile di classe assumono solo i valori yes o no. Ad esempio, se una parola compare o meno in un testo.
3. Classificatore Gaussiano Naive Bayes
Quando i predittori assumono un valore costante, assumiamo che questi valori siano campionati da una distribuzione gaussiana.
Fonte
Poiché i valori presenti nel set di dati cambiano, la formula della probabilità condizionale cambia in,
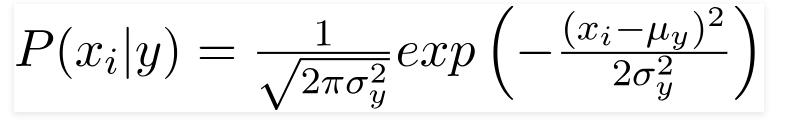
Fonte
Conclusione
Speriamo di poterti guidare su cos'è Naive Bayes Classifier e come viene utilizzato per classificare il testo. Questo semplice metodo fa miracoli nei problemi di classificazione. Che tu sia un esperto di Machine Learning o meno, puoi creare il tuo classificatore Naive Bayes senza dedicare ore alla programmazione.
Se sei interessato a saperne di più, dai un'occhiata ai programmi esclusivi di Upgrad nell'apprendimento automatico. Classificatori di apprendimento con upGrad: dai una spinta alla tua carriera con la conoscenza del machine learning e le tue abilità di deep learning. A upGrad Education Pvt. Ltd. , offriamo un programma di certificazione attentamente progettato e guidato da esperti del settore.
- Questo corso intensivo di oltre 240 ore è appositamente progettato per i professionisti che lavorano.
- Lavorerai su più di cinque progetti di settore e case study.
- Riceverai un supporto professionale a 360 gradi con un mentore dedicato al successo degli studenti e un mentore di carriera.
- Riceverai assistenza per il tuo posizionamento e imparerai a costruire un curriculum solido.
Applica ora!