
Architettura di base della CNN: spiegazione di 5 livelli di rete neurale convoluzionale
Pubblicato: 2020-12-07Sommario
introduzione
Negli ultimi anni nel settore IT, c'è stata un'enorme richiesta per un insieme di competenze un tempo particolare noto come Deep Learning. Deep Learning un sottoinsieme di Machine Learning che consiste in algoritmi che si ispirano al funzionamento del cervello umano o delle reti neurali.
Queste strutture sono chiamate Reti Neurali. Insegna al computer a fare ciò che viene naturalmente all'uomo. Deep learning, esistono diversi tipi di modelli come le reti neurali artificiali (ANN), gli autoencoder, le reti neurali ricorrenti (RNN) e l'apprendimento per rinforzo. Ma c'è stato un modello particolare che ha contribuito molto nel campo della visione artificiale e dell'analisi delle immagini che è il Convolutional Neural Networks (CNN) o il ConvNets.
Le CNN sono una classe di reti neurali profonde in grado di riconoscere e classificare caratteristiche particolari dalle immagini e sono ampiamente utilizzate per l'analisi di immagini visive. Le loro applicazioni spaziano dal riconoscimento di immagini e video, classificazione di immagini, analisi di immagini mediche, visione artificiale ed elaborazione del linguaggio naturale.
Il termine "Convoluzione" nella CNN indica la funzione matematica di convoluzione che è un tipo speciale di operazione lineare in cui due funzioni vengono moltiplicate per produrre una terza funzione che esprime come la forma di una funzione viene modificata dall'altra. In parole povere, due immagini che possono essere rappresentate come matrici vengono moltiplicate per fornire un output che viene utilizzato per estrarre le caratteristiche dall'immagine.
Impara l'apprendimento automatico online dalle migliori università del mondo: master, programmi post-laurea per dirigenti e programma di certificazione avanzato in ML e AI per accelerare la tua carriera.
Impara: Introduzione all'apprendimento profondo e alle reti neurali

Architettura di base
Ci sono due parti principali di un'architettura CNN
- Uno strumento di convoluzione che separa e identifica le varie caratteristiche dell'immagine per l'analisi in un processo chiamato Feature Extraction
- Un livello completamente connesso che utilizza l'output del processo di convoluzione e prevede la classe dell'immagine in base alle caratteristiche estratte nelle fasi precedenti.
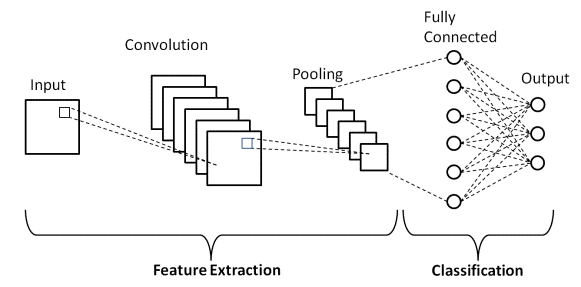
Fonte
Strati di convoluzione
Esistono tre tipi di livelli che compongono la CNN: i livelli convoluzionali, i livelli di pooling e i livelli completamente connessi (FC). Quando questi livelli sono impilati, verrà formata un'architettura CNN. Oltre a questi tre livelli, ci sono altri due parametri importanti che sono il livello di dropout e la funzione di attivazione che sono definiti di seguito.
1. Strato convoluzionale
Questo livello è il primo livello che viene utilizzato per estrarre le varie caratteristiche dalle immagini di input. In questo strato, l'operazione matematica di convoluzione viene eseguita tra l'immagine in ingresso e un filtro di una particolare dimensione MxM. Facendo scorrere il filtro sull'immagine in ingresso, il prodotto scalare viene prelevato tra il filtro e le parti dell'immagine in ingresso rispetto alla dimensione del filtro (MxM).
L'output è definito come la mappa delle caratteristiche che ci fornisce informazioni sull'immagine come angoli e bordi. Successivamente, questa mappa delle caratteristiche viene inviata ad altri livelli per apprendere molte altre caratteristiche dell'immagine di input.
2. Strato di raggruppamento
Nella maggior parte dei casi, uno strato convoluzionale è seguito da uno strato di pooling. L'obiettivo principale di questo livello è ridurre le dimensioni della mappa delle caratteristiche convolte per ridurre i costi di calcolo. Questo viene eseguito diminuendo le connessioni tra i livelli e opera in modo indipendente su ciascuna mappa delle caratteristiche. A seconda del metodo utilizzato, esistono diversi tipi di operazioni di pooling.
In Max Pooling, l'elemento più grande è preso dalla mappa delle caratteristiche. Il raggruppamento medio calcola la media degli elementi in una sezione Immagine di dimensioni predefinite. La somma totale degli elementi nella sezione predefinita viene calcolata in Sum Pooling. Lo strato di pooling solitamente funge da ponte tra lo strato convoluzionale e lo strato FC
Da leggere: Idee per progetti di reti neurali
3. Livello completamente connesso
Lo strato Fully Connected (FC) è costituito dai pesi e dai bias insieme ai neuroni e viene utilizzato per collegare i neuroni tra due diversi strati. Questi livelli sono solitamente posizionati prima del livello di output e formano gli ultimi livelli di un'architettura CNN.
In questo, l'immagine di input dai livelli precedenti viene appiattita e inviata al livello FC. Il vettore appiattito subisce quindi alcuni altri livelli FC in cui di solito avvengono le operazioni delle funzioni matematiche. In questa fase inizia il processo di classificazione.
4. Abbandono
Di solito, quando tutte le funzionalità sono collegate al livello FC, può causare un overfitting nel set di dati di addestramento. L'overfitting si verifica quando un particolare modello funziona così bene sui dati di addestramento causando un impatto negativo sulle prestazioni del modello quando viene utilizzato su nuovi dati.
Per ovviare a questo problema, viene utilizzato uno strato di abbandono in cui alcuni neuroni vengono rilasciati dalla rete neurale durante il processo di addestramento con conseguente riduzione delle dimensioni del modello. Al superamento di un dropout di 0,3, il 30% dei nodi viene eliminato in modo casuale dalla rete neurale.
5. Funzioni di attivazione
Infine, uno dei parametri più importanti del modello CNN è la funzione di attivazione. Sono utilizzati per apprendere e approssimare qualsiasi tipo di relazione continua e complessa tra variabili della rete. In parole semplici, decide quali informazioni del modello dovrebbero sparare in avanti e quali no alla fine della rete.

Aggiunge non linearità alla rete. Esistono diverse funzioni di attivazione comunemente utilizzate come le funzioni ReLU, Softmax, tanH e Sigmoid. Ognuna di queste funzioni ha un utilizzo specifico. Per un modello CNN di classificazione binaria, le funzioni sigmoid e softmax sono preferite e per una classificazione multi-classe, generalmente si usa softmax.
Architettura della CNN LeNet-5
Nel 1998, l'architettura LeNet-5 è stata introdotta in un documento di ricerca intitolato "Gradient-Based Learning Applied to Document Recognition" di Yann LeCun, Leon Bottou, Yoshua Bengio e Patrick Haffner. È una delle prime e più basilari architetture della CNN.
È composto da 7 strati. Il primo livello è costituito da un'immagine di input con dimensioni di 32×32. È convoluto con 6 filtri di dimensioni 5×5 risultanti in una dimensione di 28x28x6. Il secondo livello è un'operazione di pooling che filtra la dimensione 2×2 e lo stride di 2. Quindi la dimensione dell'immagine risultante sarà 14x14x6.
Allo stesso modo, il terzo strato prevede anche un'operazione di convoluzione con 16 filtri di dimensione 5×5 seguiti da un quarto strato di pooling con dimensioni del filtro simili di 2×2 e passo di 2. Pertanto, la dimensione dell'immagine risultante sarà ridotta a 5x5x16.
Una volta ridotta la dimensione dell'immagine, il quinto livello è uno strato convoluzionale completamente connesso con 120 filtri ciascuno di dimensioni 5×5. In questo livello, ciascuna delle 120 unità in questo livello sarà collegata alle 400 unità (5x5x16) dei livelli precedenti. Il sesto strato è anche uno strato completamente connesso con 84 unità.
Il settimo livello finale sarà un livello di output softmax con 'n' classi possibili a seconda del numero di classi nel set di dati.
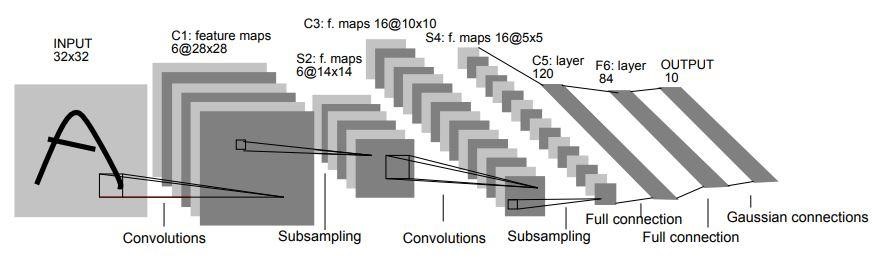
Fonte
Il diagramma sopra è una rappresentazione dei 7 livelli dell'architettura CNN di LeNet-5.
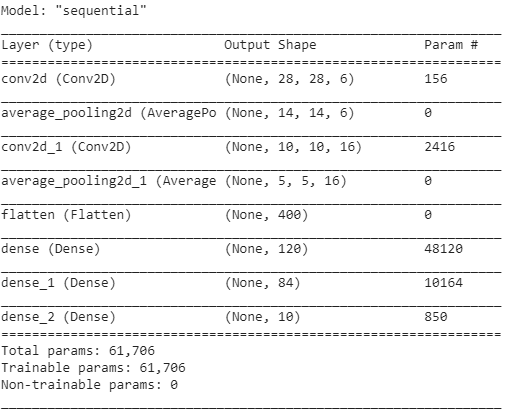
Di seguito sono riportati gli snapshot del codice Python per costruire un'architettura CNN LeNet-5 utilizzando la libreria keras con il framework TensorFlow

Nella programmazione Python, il tipo di modello più comunemente utilizzato è il tipo Sequenziale. È il modo più semplice per costruire un modello CNN in keras. Ci permette di costruire un modello strato per strato. La funzione 'add()' viene utilizzata per aggiungere livelli al modello. Come spiegato sopra, per l'architettura LeNet-5, ci sono due coppie Convolution e Pooling seguite da uno strato Flatten che viene solitamente utilizzato come connessione tra gli strati Convolution e Dense.
I livelli densi sono quelli maggiormente utilizzati per i livelli di output. L'attivazione utilizzata è il 'Softmax' che dà una probabilità per ogni classe e si sommano totalmente a 1. Il modello farà la sua previsione in base alla classe con la probabilità più alta.
Il riepilogo del modello viene visualizzato come di seguito.
Conclusione
Quindi, in questo articolo abbiamo compreso la struttura di base della CNN, la sua architettura ei vari livelli che compongono il modello CNN. Inoltre, abbiamo visto un esempio architettonico di un modello LeNet-5 molto famoso e tradizionale con il suo programma Python.
Se sei interessato a saperne di più sui corsi di machine learning, dai un'occhiata al programma Executive PG di IIIT-B e upGrad in Machine Learning e AI , progettato per i professionisti che lavorano e offre oltre 450 ore di formazione rigorosa, oltre 30 casi di studio e incarichi, Status di Alumni IIIT-B, oltre 5 progetti pratici pratici e assistenza sul lavoro con le migliori aziende.
Quali sono le funzioni di attivazione nella CNN?
La funzione di attivazione è una delle componenti più vitali del modello CNN. Sono utilizzati per apprendere e approssimare qualsiasi forma di associazione variabile-variabile di rete che sia sia continua che complessa. In parole povere, determina quali informazioni sul modello dovrebbero fluire nella direzione in avanti e quali no alla fine della rete. Dà alla rete non linearità. Le funzioni ReLU, Softmax, tanH e Sigmoid sono alcune delle funzioni di attivazione più utilizzate. Tutte queste funzioni hanno usi distinti. Per un modello CNN a 2 classi, sono preferite le funzioni sigmoide e softmax, mentre softmax viene in genere impiegato per la classificazione multiclasse.
Quali sono i componenti di base dell'architettura della rete neurale convoluzionale?
Un livello di input, un livello di output e più livelli nascosti costituiscono reti convoluzionali. I neuroni negli strati di una rete convoluzionale sono disposti in tre dimensioni, a differenza di quelli in una rete neurale standard (dimensioni di larghezza, altezza e profondità). Ciò consente alla CNN di convertire un volume di input tridimensionale in un volume di output. Convoluzione, pooling, normalizzazione e livelli completamente connessi costituiscono i livelli nascosti. Più livelli di conv vengono utilizzati nelle CNN per filtrare i volumi di input a livelli di astrazione più elevati.
Qual è il vantaggio delle architetture CNN standard?
Mentre le architetture di rete tradizionali consistevano esclusivamente di strati convoluzionali impilati, le architetture più recenti esaminano modi nuovi e nuovi di costruire strati convoluzionali al fine di migliorare l'efficienza dell'apprendimento. Queste architetture forniscono raccomandazioni generali sull'architettura per consentire ai professionisti dell'apprendimento automatico di adattarsi al fine di gestire una varietà di problemi di visione artificiale. Queste architetture possono essere utilizzate come estrattori di funzionalità avanzate per la classificazione delle immagini, l'identificazione degli oggetti, la segmentazione delle immagini e una varietà di altre attività avanzate.