
K Berarti Clustering Matlab [Dengan Kode Sumber]
Diterbitkan: 2020-12-09K-means clustering adalah salah satu teknik yang paling umum digunakan oleh para profesional data. Karena kemanjuran algoritma, itu dituntut oleh banyak industri di berbagai aplikasi.
Pekerjaan seorang data scientist membutuhkan implementasi Clustering dalam banyak tahapan. Banyak proyek skala besar saat ini didasarkan pada algoritme pengelompokan dan telah secara drastis meningkatkan standar untuk permintaan para profesional ilmu data.
Salah satu algoritma tersebut adalah K-means clustering, yang merupakan ide dasar artikel ini dan implementasinya dengan kode sumber MATLAB.
Sebelum memahami topik, mari kita lihat sekilas apa itu Clustering, signifikansinya, dan bagaimana penerapannya dalam kehidupan nyata. Pada akhir posting, Anda akan mengetahui betapa pentingnya algoritme ini untuk memahami data dalam kumpulan besar.
Daftar isi
Apa itu Clustering?
Data adalah komponen paling penting untuk aplikasi apa pun, dan cluster tidak lain adalah akumulasi dari titik data serupa yang digabungkan. Seperti namanya jelas mendefinisikan, Clustering adalah proses membagi sebagian besar data menjadi subkelompok atau hanya cluster berdasarkan pola data.
Dalam pembelajaran mesin, Pengelompokan diterapkan ketika tidak ada data yang telah ditentukan sebelumnya. Tujuan utamanya adalah untuk mengelompokkan data ke dalam kelas-kelas dengan kesamaan Intra-kelas yang tinggi.

Clustering digunakan untuk mengeksplorasi data. Beberapa contoh kehidupan nyata yang dapat digunakan adalah dalam segmentasi pasar untuk menemukan pelanggan dengan perilaku serupa, segmentasi/kompresi gambar, pengelompokan dokumen dengan banyak topik, dll.
Ini adalah langkah yang diperlukan sebelum memproses data untuk mengidentifikasi kelompok homogen untuk membangun model yang diawasi. Pengelompokan K-Means adalah algoritma pembelajaran tanpa pengawasan karena kita harus mencari data untuk mengintegrasikan pengamatan yang serupa dan membentuk kelompok yang berbeda.
Mari kita lihat algoritma K-Means , yang merupakan salah satu algoritma clustering yang paling banyak diterapkan dan paling sederhana.
Pengelompokan K-Means
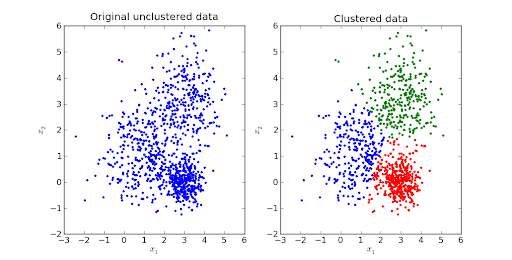
Sumber Gambar
Pengelompokan K-means adalah salah satu algoritma pembelajaran mesin tanpa pengawasan yang paling diinginkan.
Algoritme tanpa pengawasan membuat kesimpulan dari kumpulan data menggunakan vektor input tanpa mengacu pada hasil yang diberi label.
Ini adalah algoritma berbasis jarak atau berbasis centroid iteratif yang memisahkan dataset menjadi K subkelompok (cluster) yang berbeda di mana setiap titik data milik satu kelompok . Kesamaan titik data intra-cluster meningkat, dan jarak antar cluster tetap optimal.
Jarak antara titik data dan pusat cluster dijaga agar tetap minimum, seperti jarak Euclidean. Di K-Means, setiap cluster terhubung ke centroid. Tujuan utamanya adalah untuk meminimalkan jarak antara titik dan masing-masing cluster centroid.
Bagaimana K-Means Clustering Bekerja?
Karena proses clustering berarti beberapa iterasi yang harus dilakukan, algoritma K-Means memiliki cara kerja yang unik. Berikut adalah penjelasan langkah demi langkah tentang cara kerjanya:
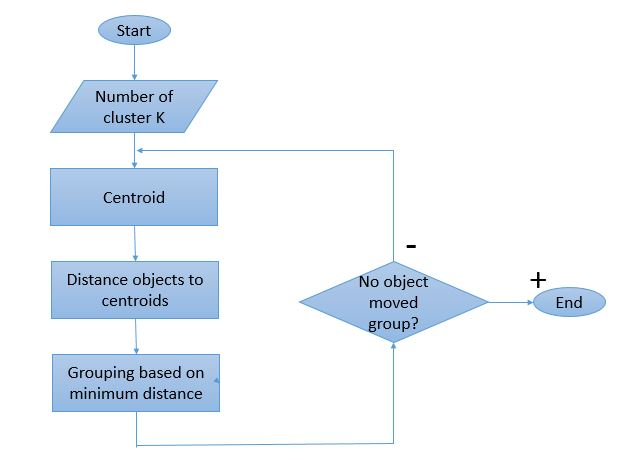
Sumber Gambar
Langkah 1: Awalnya, tentukan jumlah cluster ' Langkah 2: Inisialisasi titik data K acak sebagai centroid untuk setiap cluster.
Jika ada 2 cluster, nilai 'K' akan menjadi 2.
Langkah 3: Lakukan beberapa iterasi hingga titik data yang ditetapkan ke cluster tidak berubah.
Langkah 4: Hitung jumlah jarak kuadrat antara titik data dan centroid.
Langkah 5: Alokasikan setiap titik data ke cluster terdekat (centroid) untuk meminimalkan jarak.
Langkah 6: Ambil rata-rata centroid dari cluster yang dimiliki satu sama lain.
Ini adalah proses iterasi tunggal yang dilakukan untuk menghitung centroid dan menetapkan titik ke cluster berdasarkan jaraknya dari centroid. Setelah semua centroid ditentukan, proses dihentikan.
Contoh Ilustrasi yang Menggambarkan Implementasi K-Means Clustering
Pernyataan: Salah satu rantai makanan terkenal, McDonald's ingin membuka rantai gerai di seluruh California dan ingin mengetahui lokasi yang akan memberi mereka pendapatan maksimum.
Apa yang sudah dimiliki McDonald's?
Kehadiran e-niaga yang kuat
Data pelanggan online untuk menganalisis lokasi dari mana pesanan sering dilakukan
Kemungkinan tantangan yang bisa mereka hadapi
- Menganalisis area dari mana pesanan sering dibuat.
- Pahami berapa banyak outlet yang akan dibuka di area tersebut
- Cari tahu lokasi gerai di semua area untuk menjaga jarak minimum antara toko dan titik pengiriman.
Semua poin ini membutuhkan banyak analisis dan matematika untuk dikerjakan.
Bagaimana Metode Pengelompokan K-means dapat digunakan di sini?
Dengan nilai K yang telah ditentukan sebelumnya, algoritma K-means dapat diimplementasikan dalam langkah-langkah berikut:
- Mengidentifikasi lokasi penyimpanan dengan K Partisi objek menjadi K himpunan bagian tidak kosong.
- Menentukan centroid cluster dari partisi.
- Menetapkan setiap lokasi ke cluster tertentu.
- Menghitung jarak dari masing-masing lokasi dan mengalokasikan titik ke cluster yang jaraknya minimal dengan outlet.
- Setelah satu iterasi, pembagian kembali titik-titik, cari centroid dari cluster baru yang terbentuk.
Demikian pula, algoritma K-Means Clustering dapat diterapkan pada berbagai aplikasi dalam skala yang bervariasi. Industri perhotelan, departemen investigasi kejahatan, dan pengubahan ukuran gambar, adalah beberapa di antaranya.

Algoritma K-Means diimplementasikan menggunakan banyak bahasa seperti R , Python, MATLAB, dll. Pada bagian selanjutnya, kita akan melihat bagaimana K-Means Clustering MATLAB diterapkan.
Baca: Jenis Fungsi di Matlab
Algoritma K-Means Menggunakan MATLAB
K-Means adalah algoritma yang banyak digunakan oleh banyak profesional yang berurusan dengan ilmu data, pembelajaran mesin, kecerdasan buatan, kriptografi, dan keamanan siber.
Tujuan utama dari penggunaan algoritma ini adalah untuk mengetahui centroid dari setiap cluster. Data yang diberikan kepada seorang programmer bersifat heterogen. Berikut adalah kode MATLAB untuk memplot centroid setiap cluster dan menetapkan koordinat setiap centroid:
Mengelompokkan MATLAB
Kode:
rng default; % Untuk reproduktifitas
X = [randn(100,2)*0,75+satuan(100,2);
randn(100,2)*0,5-satu(100,2)];
opts=statset('Tampilan','final');
[idx,C]=kmeans(X,4,'Distance','cityblock','Replicates',5,'Options',opts);
plot(X(idx==1,1),X(idx==1,2),'r.','MarkerSize',12);
tunggu;
plot(X(idx==2,1),X(idx==2,2),'b.','MarkerSize',12);
plot(X(idx==3,1),X(idx==3,2),'g.','MarkerSize',12);
plot(X(idx==4,1),X(idx==4,2),'y.','MarkerSize',12);
plot(C(:,1),C(:,2),'Kx','MarkerSize',15,'LineWidth',3);
legend('Cluster 1′,'Cluster 2′,'Cluster 3′,'Cluster 4′,'Centroids', 'Location','NW');
title('Tugas Cluster dan centroid');
bertahan;
untuk i=1:ukuran(C, 1)
display(['Centroid ', num2str(i), ': X1 = ', num2str(C(i, 1)), '; X2 = ', num2str(C(i, 2))]);
akhir
Keluaran:
Jendela MATLAB Menampilkan Empat Cluster dan Centroid Masing-masing
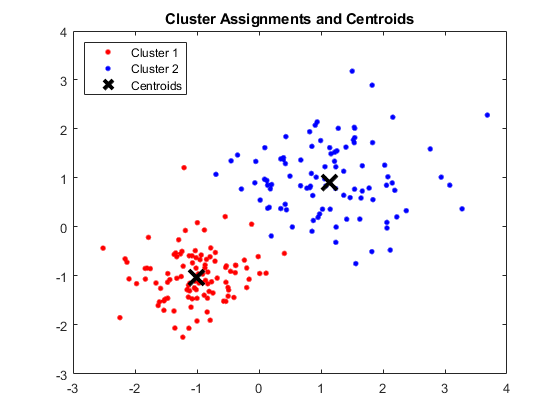
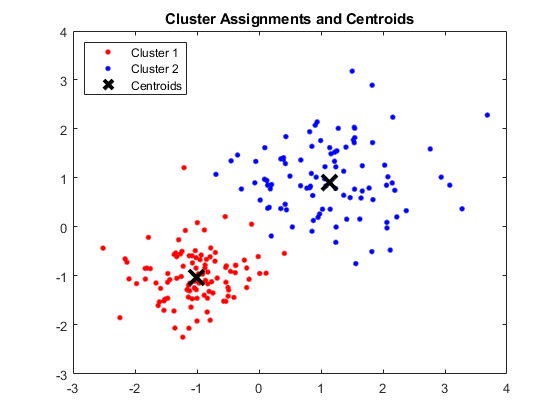
Sumber Gambar
Hasil:
Adapun centroid yang didapat adalah sebagai berikut:
- Nilai X1 & X2 untuk Centroid 1: 1.3661; 1.7232
- Nilai X1 & X2 untuk Centroid 2: -1.015; -1.053
- Nilai X1 & X2 untuk Centroid 3: 1.6565; 0,36376
- Nilai X1 & X2 untuk Centroid 4: 0,35134; 0.85358
Beberapa area bisnis di mana clustering K-Means dapat diimplementasikan
Pengelompokan K-means adalah algoritme serbaguna dan dapat digunakan untuk banyak kasus penggunaan bisnis untuk semua jenis pengelompokan. Beberapa contohnya adalah:
Segregasi Perilaku:
- Divisi menggunakan riwayat pembelian
- Divisi yang menggunakan aktivitas aplikasi, situs web, atau platform
- Identifikasi citra pelanggan berdasarkan minat mereka
- Pembuatan profil dengan aktivitas pemantauan
Penskalaan Gambar
- Kompresi gambar menggunakan Python
Pengukuran sensor:
- Deteksi jenis aktivitas sensor gerak
- Gambar grup
- Bagi audio
- Temukan kelompok pemantau kesehatan
Tentukan bot atau anomali:
- Pisahkan grup aktivitas dari bot
- Buat grup aktivitas yang valid untuk membersihkan deteksi outlier
Klasifikasi inventaris:
- Buat grup inventaris berdasarkan aktivitas penjualan
- Buat grup inventaris dengan membuat metrik
Keuntungan K-Means Clustering
Ada alasan mengapa para profesional papan atas lebih memilih algoritme pengelompokan K-Means. Beberapa manfaat yang ditawarkannya:
- Ini adalah algoritma yang cepat, kuat, dan lebih mudah dipahami.
- Efisiensi akhir relatif tinggi
- Menawarkan hasil yang fenomenal ketika kumpulan data berbeda satu sama lain. Untuk nilai variabel yang lebih tinggi, K-Means bekerja relatif lebih cepat
- Cluster yang dihasilkan dengan K-Means relatif lebih rapat dibandingkan dengan metode clustering lainnya.
Harus Dibaca: Tipe Data MATLAB
Kesimpulan
K-means clustering adalah pendekatan yang digunakan secara luas untuk menganalisis cluster data. Setelah Anda mendapatkan perintah, lebih mudah untuk memahami dan menerapkan dan memberikan hasil dengan cepat.
Kami berharap dengan artikel ini; kami dapat memperkenalkan Anda pada teknik analisis ini. Untuk pertanyaan apa pun mengenai algoritma K-means, jangan ragu untuk berkomentar di bawah.
Lebih lanjut, jika bidang studi ini menarik minat Anda, lihat program Diploma PG dalam Pembelajaran Mesin dan AI kami yang secara khusus dikuratori untuk para profesional yang bekerja yang menawarkan 30+ studi kasus & tugas, 25+ sesi bimbingan dari pakar industri, 10 Praktik Hands- di Proyek Capstone, 450+ jam pembelajaran dan bantuan penempatan.
Apa itu pengelompokan K Means dalam pembelajaran mesin?
Ini adalah algoritma pengelompokan populer yang digunakan dalam pembelajaran mesin tanpa pengawasan. Algoritma K Means bekerja berdasarkan prinsip identifikasi K centroid secara acak. Dari langkah selanjutnya, algoritma mencoba untuk memaksimalkan jarak keseluruhan dalam cluster dan juga meminimalkan keseluruhan jarak antar cluster. Algoritma K Means merupakan pendekatan iteratif. Dalam setiap iterasi, ia memilih K Means dari set centroid saat ini. Algoritme kemudian menetapkan setiap pengamatan ke K Mean terdekat. Jarak antara dua cluster dihitung berdasarkan jarak antara dua pengamatan terdekat. Centroid dari sebuah cluster didefinisikan sebagai rata-rata dari semua observasi dalam cluster tersebut.
Apa batasan dari algoritma pengelompokan K Means?
Ada beberapa batasan K Means yang ingin Anda ingat saat menggunakannya. K Means tidak kuat terhadap outlier. Algoritme K Means hanya berfungsi dengan baik jika semua titik data Anda memiliki jarak yang kira-kira sama dari centroid. Jika beberapa titik data Anda jauh dari centroid, ini akan membiaskan penetapan titik data lain ke cluster. K Means tidak menjamin solusi yang unik. Jika Anda memiliki lebih dari satu cluster poin, tidak ada jaminan bahwa K Means akan mengembalikan jumlah cluster yang sama setiap kali algoritma dijalankan. K Berarti konvergen perlahan. Algoritme konvergen sangat lambat, bahkan pada kumpulan data kecil.
Apa keuntungan dari pengelompokan K Means?
Ini efektif untuk dimensi tunggal dan ganda. Ini berlaku dalam dua dan tiga dimensi. Ini sangat berguna dalam situasi di mana ada banyak cluster. Cluster diperoleh pada titik tengah titik data. Nilai rata-rata dihitung untuk setiap cluster. Setiap titik dibagi dengan standar deviasi dan kemudian dibandingkan dengan nilai rata-rata. Nilai rata-rata dan simpangan baku dihitung untuk semua cluster dan titik.