
Pertanyaan & Jawaban Wawancara Ilmu Data – 15 Yang Paling Sering Ditanyakan
Diterbitkan: 2019-07-08Wawancara kerja selalu rumit. Agar berhasil memecahkan wawancara, Anda tidak hanya harus memiliki pengetahuan subjek yang mendalam tetapi juga kepercayaan diri dan pikiran yang kuat. Ini terutama benar jika Anda sedang mempersiapkan Ilmu Data – ini menguji semua fakultas Anda!
Selama wawancara Ilmu Data, Anda harus menghadapi sejumlah pertanyaan mulai dari beragam topik mulai dari pertanyaan Ilmu Data dasar hingga Statistik, Analisis Data, ML, dan Pembelajaran Mendalam. Tapi bukan itu saja – soft skill Anda (komunikasi, kerja tim, dan banyak lagi.) juga akan diuji.
Untuk memudahkan proses persiapan bagi Anda, kami telah menyusun daftar 15 pertanyaan wawancara Ilmu Data yang paling sering diajukan. Kami akan mulai dengan dasar-dasar dan kemudian beralih ke topik dan masalah yang lebih maju.
Jadi, tanpa basa-basi lagi, mari kita mulai!
- Apa itu Ilmu Data? Apa perbedaan Machine Learning dengan Pengawasan dan Tanpa Pengawasan?
Dengan kata sederhana, Ilmu Data adalah studi tentang data. Ini melibatkan pengumpulan data dari sumber yang berbeda, menyimpannya, membersihkan dan mengaturnya, dan menganalisisnya untuk mengungkap informasi yang berarti darinya. Ilmu Data menggunakan kombinasi Matematika, Ilmu Komputer Statistik, Pembelajaran Mesin, Visualisasi Data, Analisis Cluster, dan Pemodelan Data. Ini bertujuan untuk mendapatkan wawasan berharga dari data mentah (baik terstruktur maupun tidak terstruktur) dan menggunakan wawasan tersebut untuk memengaruhi strategi bisnis dan TI secara positif. Ide-ide tersebut dapat membantu bisnis mengoptimalkan proses, meningkatkan produktivitas dan pendapatan, merampingkan strategi pemasaran, meningkatkan kepuasan pelanggan, dan banyak lagi.
ML yang Diawasi dan Tidak Diawasi berbeda satu sama lain dalam hal berikut:
- Dalam ML yang diawasi, data input diberi label. Dalam ML yang tidak diawasi, data input tetap tidak berlabel.
- Sementara ML yang diawasi menggunakan set data pelatihan, ML yang tidak diawasi menggunakan set data input.
- ML yang diawasi digunakan untuk tujuan prediksi, sedangkan ML yang tidak diawasi digunakan untuk tujuan analisis.
- ML yang diawasi memungkinkan klasifikasi dan regresi. Namun, ML tanpa pengawasan memungkinkan klasifikasi, estimasi kepadatan, dan pengurangan dimensi.
- Python atau R – Mana yang lebih baik untuk analisis teks?
Ketika datang ke analitik teks, Python sepertinya merupakan opsi yang paling cocok. Ini karena ia hadir dengan pustaka Pandas yang menyertakan struktur data yang mudah digunakan dan alat analisis data berkinerja tinggi. Selain itu, Python sangat efisien dan cepat untuk semua jenis tugas analisis teks. Adapun R, paling cocok untuk aplikasi Machine Learning.
- Apa saja tipe data yang didukung dengan Python?
Python memiliki array tipe data bawaan, termasuk:
- Boolean
- Numerik (Bilangan Bulat, Panjang, Float, Kompleks)
- Urutan (Daftar, String, Byte, Tuple)
- Set
- Pemetaan (Kamus)
- File objek
- Apa saja algoritma klasifikasi yang berbeda?
Algoritma klasifikasi penting adalah pengklasifikasi linier (regresi logistik, pengklasifikasi Naive Bayes), pohon keputusan, pohon yang didorong, hutan acak, SVM, estimasi kernel, jaringan saraf, dan tetangga terdekat.
- Apa itu Distribusi Normal?
Biasanya, data didistribusikan dengan berbagai cara baik dengan bias ke kiri atau ke kanan atau dalam beberapa keadaan mungkin menjadi campur aduk. Namun, mungkin ada contoh di mana data didistribusikan di sekitar nilai pusat tanpa bias ke kiri atau kanan, sehingga mencapai distribusi normal dalam bentuk kurva berbentuk lonceng.
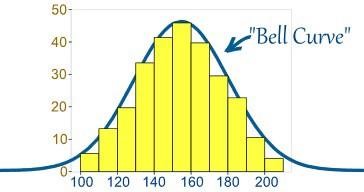
Sumber
Kurva tersebut menggambarkan distribusi variabel acak dalam bentuk kurva simetris berbentuk lonceng.
- Apa pentingnya Pengujian A/B?
Pengujian A/B adalah pengujian hipotesis statistik untuk eksperimen acak yang melibatkan dua variabel – A dan B. Pengujian A/B membantu mengidentifikasi setiap perubahan atau perubahan yang dibuat pada halaman web untuk memaksimalkan hasil yang diinginkan. Ini adalah metode yang sangat baik untuk menentukan strategi promosi dan pemasaran online terbaik untuk bisnis.
- Apa itu Bias Seleksi?
Bias Seleksi adalah kesalahan 'aktif' yang terjadi ketika peneliti memutuskan sampel yang akan diteliti. Dalam hal ini, data sampel dikumpulkan dan disiapkan untuk pemodelan data, tetapi memiliki karakteristik seperti itu yang tidak mewakili populasi masa depan dari kasus-kasus yang akan dipertimbangkan oleh model. Bias pemilihan terjadi ketika subset dari data sampel dipilih secara sistematis dan dimasukkan/dikecualikan dari analisis data. Ada tiga jenis Bias Seleksi yang berbeda:
- Bias pengambilan sampel: Kesalahan sistematis yang terjadi ketika sampel non-acak dari kumpulan data menyebabkan beberapa anggota kumpulan data kurang mungkin disertakan dalam penelitian, sehingga menyebabkan sampel menjadi bias.
- Interval waktu: Ini terjadi ketika uji coba analisis data dihentikan lebih awal pada nilai ekstrim. Namun, nilai ekstrim dapat dicapai lebih mungkin oleh variabel yang memiliki varians terbesar (bahkan jika semua variabel memiliki mean yang sama).
- Atrisi: Terjadi karena pengurangan atrisi, atau hilangnya peserta selama uji coba yang dihentikan sebelum selesai.
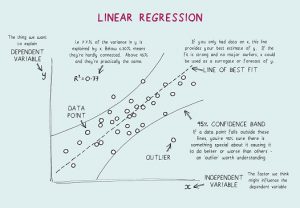
- Apa itu Regresi Linier? Apa asumsi yang diperlukan untuk regresi linier?
Regresi Linier adalah alat statistik yang digunakan untuk analisis prediktif. Dalam metode ini, skor suatu variabel (misalkan Y) diprediksi dari skor variabel lain (misalkan X). Di sini, Y adalah variabel kriteria, sedangkan X adalah variabel prediktor.
Dalam Regresi Linier, ada empat asumsi mendasar:
- Sebuah hubungan linier ada antara variabel dependen dan regresi. Sehingga model data yang dibuat akan sinkron dengan data tersebut.
- Residu data tidak tergantung satu sama lain dan terdistribusi.
- Ada multi-kolinieritas minimal antara variabel penjelas.
- Ada 'homoscedasticity' yang berarti varians di sekitar garis regresi sama untuk semua nilai variabel prediktor.
- Apa itu validasi silang?
Validasi silang adalah prosedur validasi model yang digunakan untuk. Tujuannya di sini adalah untuk menetapkan kumpulan data validasi untuk menguji model dalam fase pelatihan untuk membatasi masalah seperti overfitting dan tentu saja, menentukan bagaimana model akan digeneralisasi ke kumpulan data independen.
Cross-validation (CV) adalah teknik validasi model yang digunakan untuk menguji keefektifan model machine learning. Ini juga merupakan metode pengambilan sampel ulang yang digunakan untuk mengevaluasi model jika data terbatas. Dalam metode validasi silang, sebagian data disisihkan untuk pengujian dan validasi dan digunakan untuk menentukan bagaimana hasil analisis statistik akan digeneralisasi ke kumpulan data Independen.

- Apa itu Rumus Peluang Binomial?
Distribusi probabilitas binomial mempertimbangkan probabilitas dari masing-masing jumlah kemungkinan keberhasilan dari N jumlah percobaan untuk peristiwa independen, masing-masing memiliki probabilitas terjadinya (pi). Rumus untuk distribusi probabilitas binomial adalah:
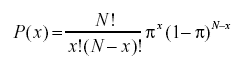
- Apa perbedaan analisis Univariat, Bivariat, dan Multivariat?
Analisis univariat mengacu pada teknik analisis statistik deskriptif yang dapat dibedakan berdasarkan jumlah variabel yang terlibat pada titik waktu tertentu (misalnya, diagram lingkaran yang menggambarkan penjualan produk di wilayah tertentu). Berlawanan dengan ini, analisis bivariat bertujuan untuk memahami dan menentukan perbedaan antara dua variabel sekaligus seperti dalam diagram pencar (misalnya, hubungan antara volume penjualan dan pengeluaran).
Analisis multivariat melibatkan studi lebih dari dua variabel untuk memahami pengaruh variabel pada tanggapan/hasil.
- Apa itu Jaringan Syaraf Tiruan?
Dalam istilah sederhana, Jaringan Syaraf Tiruan (JST) mengacu pada sistem komputasi yang dirancang setelah otak manusia. Sama seperti otak manusia, JST terdiri dari banyak elemen pemrosesan sederhana, yang dikenal sebagai neuron buatan yang fungsinya terinspirasi oleh neuron pada spesies hewan. JST dapat belajar melalui pengalaman dan dapat beradaptasi dengan input yang berubah sehingga jaringan dapat menghasilkan hasil terbaik tanpa harus mendesain ulang kriteria output.
- Apa itu Recurrent Neural Networks (RNNs)?
Sebuah jaringan saraf berulang (RNN) adalah jenis jaringan saraf tiruan di mana koneksi nodal menghasilkan grafik terarah sepanjang urutan temporal, sehingga menunjukkan perilaku dinamis temporal. Untuk memahami RNN, Anda harus terlebih dahulu memahami cara kerja jaring feedforward. Sementara jaringan feedforward menyalurkan informasi dalam garis lurus (tanpa menyentuh node yang sama dua kali), jaringan saraf berulang menggilir informasi melalui proses seperti loop. Berlawanan dengan jaring saraf feedforward, RNN dapat menggunakan memori internalnya untuk memproses urutan input. Oleh karena itu, RNN paling cocok untuk tugas yang tidak tersegmentasi atau terhubung, seperti pengenalan tulisan tangan dan pengenalan suara.
17 Pertanyaan dan Jawaban Wawancara Analis Data Teratas
- Apa itu Propagasi Kembali?
Backpropagation mengacu pada algoritma pembelajaran terawasi yang digunakan untuk melatih jaringan saraf multilayer. Melalui backpropagation, kesalahan dapat dipindahkan dari ujung jaringan ke semua bobot di dalam jaringan, sehingga memungkinkan perhitungan gradien yang efisien. Ini mencari nilai minimum dari fungsi kesalahan dalam ruang berat menggunakan teknik penurunan gradien. Bobot yang meminimalkan fungsi kesalahan dianggap sebagai solusi untuk masalah pembelajaran.
- Backpropagation melibatkan langkah-langkah berikut:
- Propagasi ke depan dari data pelatihan.
- Hitung turunan menggunakan output dan target.
- Kembali Menyebarkan untuk menghitung turunan dari kesalahan.
- Gunakan turunan yang dihitung sebelumnya untuk keluaran.
- Menghitung nilai bobot yang diperbarui dan memperbarui bobot.
- Jelaskan penurunan gradien.
Untuk memahami Gradient Descent, Anda harus terlebih dahulu memahami apa itu Gradient. Gradien adalah ukuran seberapa banyak output dari fungsi tertentu berubah dalam kaitannya dengan perubahan kecil pada input. Ini mengukur perubahan semua bobot sebagai respons terhadap perubahan kesalahan. Jadi, dengan kata lain, gradien adalah gradien dari suatu fungsi.
Penurunan gradien adalah algoritma optimasi yang membantu menemukan nilai parameter (koefisien) dari fungsi (f) yang meminimalkan fungsi biaya (biaya). Ini paling cocok untuk contoh ketika parameter tidak dapat dihitung secara analitis.
Kesimpulan
Sebagai catatan penutup, Anda harus tahu bahwa tidak ada cara tunggal atau terbaik untuk mempersiapkan wawancara. Ini semua tentang basis pengetahuan Anda, kepercayaan diri dan pendekatan Anda, dan sedikit keberuntungan. Meskipun ini hanya beberapa pertanyaan Ilmu Data, kami berharap ini memberi Anda gambaran kasar tentang jenis pertanyaan yang dapat Anda ajukan dalam wawancara Ilmu Data. Yang mengatakan, bersiaplah dengan baik, dan semua yang terbaik untuk usaha Anda!
Pelajari kursus ilmu data dari Universitas top dunia. Dapatkan Program PG Eksekutif, Program Sertifikat Tingkat Lanjut, atau Program Magister untuk mempercepat karier Anda.
Dalam wawancara ilmu data, ada berapa putaran?
Satu atau dua putaran wawancara pemrograman mungkin diperlukan, tetapi ini sepenuhnya tergantung pada perusahaan tempat Anda melamar. Beberapa perusahaan membuat proses wawancara berlangsung hingga enam putaran. Anda dapat mempersiapkan tanggapan Anda untuk setiap pertanyaan dengan meneliti pertanyaan yang paling sering diajukan, membuat daftar pertanyaan yang paling umum dan sulit, dan kemudian menganalisis pertanyaan tersebut sebelum wawancara Anda.
Apa kualitas yang dicari oleh pewawancara ilmu data?
Untuk mendapatkan wawancara ilmu data, Anda harus tahu banyak tentang aritmatika, statistik, bahasa pemrograman, dasar-dasar intelijen bisnis, dan, tentu saja, teknik pembelajaran mesin. Anda pasti akan diminta untuk menunjukkan bagaimana kemampuan data Anda berhubungan dengan pilihan dan strategi perusahaan. Di pasar saat ini, hampir setiap pekerjaan data science membutuhkan wawancara coding. Peran ilmuwan data termasuk merilis kode produksi, seperti jalur pipa data dan model pembelajaran mesin, di banyak perusahaan. Untuk proyek semacam ini, kemampuan pemrograman yang kuat juga diperlukan, sehingga Anda dapat mengharapkan beberapa pertanyaan SQL dan Python juga dalam wawancara.
Bisakah saya mendapatkan pekerjaan sebagai ilmuwan data melalui LinkedIn?
Orang tidak boleh mengabaikan kekuatan LinkedIn hari ini. LinkedIn pada dasarnya adalah resume digital Anda. Perusahaan dan perekrut terus mencari kandidat yang layak di LinkedIn, jadi penting bagi Anda untuk membangun profil LinkedIn yang mengesankan, terus mencari pekerjaan, dan melamar lowongan pekerjaan di LinkedIn. Tambahkan keterampilan yang relevan ke profil Anda dan terus tambahkan semua pencapaian profesional Anda. Dengan cara ini, peluang Anda untuk mendapatkan pekerjaan ilmu data yang layak dari LinkedIn tinggi.