
Perguntas e respostas da entrevista sobre ciência de dados - 15 perguntas mais frequentes
Publicados: 2019-07-08As entrevistas de emprego são sempre complicadas. Para quebrar uma entrevista com sucesso, você deve possuir não apenas conhecimento profundo do assunto, mas também confiança e uma forte presença de espírito. Isso é especialmente verdade se você estiver se preparando para uma Ciência de Dados – ela coloca todas as suas faculdades à prova!
Durante uma entrevista de Ciência de Dados, você terá que enfrentar uma série de perguntas que abrangem diversos tópicos, desde questões básicas de Ciência de Dados a Estatística, Análise de Dados, ML e Aprendizado Profundo. Mas isso não é tudo – suas habilidades sociais (comunicação, trabalho em equipe e muito mais) também serão testadas.
Para facilitar o processo de preparação para você, selecionamos uma lista das 15 perguntas mais frequentes da entrevista sobre ciência de dados. Começaremos com os fundamentos e, em seguida, passaremos para os tópicos e questões mais avançados.
Então, sem mais delongas, vamos começar!
- O que é Ciência de Dados? Como o aprendizado de máquina supervisionado e não supervisionado difere?
Em palavras simples, Data Science é o estudo de dados. Envolve a coleta de dados de fontes díspares, armazenando-os, limpando-os e organizando-os e analisando-os para descobrir informações significativas. A ciência de dados usa uma combinação de matemática, ciência da computação estatística, aprendizado de máquina, visualização de dados, análise de cluster e modelagem de dados. Ele visa obter insights valiosos de dados brutos (estruturados e não estruturados) e usar esses insights para influenciar positivamente as estratégias de negócios e de TI. Essas ideias podem ajudar as empresas a otimizar processos, aumentar a produtividade e a receita, agilizar as estratégias de marketing, aumentar a satisfação do cliente e muito mais.
ML supervisionado e não supervisionado diferem entre si nos seguintes aspectos:
- No ML supervisionado, os dados de entrada são rotulados. No ML não supervisionado, os dados de entrada permanecem sem rótulo.
- Enquanto o ML supervisionado usa o conjunto de dados de treinamento, o ML não supervisionado usa o conjunto de dados de entrada.
- O ML supervisionado é usado para fins de previsão, enquanto o ML não supervisionado é usado para fins de análise.
- O ML supervisionado permite classificação e regressão. No entanto, ML não supervisionado permite classificação, estimativa de densidade e redução de dimensão.
- Python ou R – Qual é melhor para análise de texto?
Quando se trata de análise de texto, o Python parece ser a opção mais adequada. Isso ocorre porque ele vem com a biblioteca Pandas, que inclui estruturas de dados fáceis de usar e ferramentas de análise de dados de alto desempenho. Além disso, o Python é altamente eficiente e rápido para todos os tipos de tarefas de análise de texto. Quanto ao R, é mais adequado para aplicações de Machine Learning.
- Quais são os tipos de dados suportados em Python?
O Python tem uma matriz de tipos de dados integrados, incluindo:
- boleano
- Numérico (Inteiros, Longos, Flutuantes, Complexos)
- Sequências (Listas, Strings, Byte, Tupla)
- Conjuntos
- Mapeamentos (dicionários)
- Objetos de arquivo
- Quais são os diferentes algoritmos de classificação?
Os algoritmos de classificação principais são classificadores lineares (regressão logística, classificador Naive Bayes), árvores de decisão, árvores impulsionadas, floresta aleatória, SVM, estimativa de kernel, redes neurais e vizinho mais próximo.
- O que é Distribuição Normal?
Normalmente, os dados são distribuídos de várias maneiras, com um viés para a esquerda ou para a direita ou, em algumas circunstâncias, podem ficar confusos. No entanto, pode haver casos em que os dados são distribuídos em torno de um valor central sem qualquer viés para a esquerda ou para a direita, atingindo assim uma distribuição normal na forma de uma curva em forma de sino.
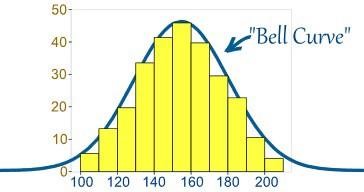
Fonte
A curva representa a distribuição de variáveis aleatórias na forma de uma curva simétrica em forma de sino.
- Qual a importância do teste A/B?
O teste A/B é um teste de hipótese estatística para experimentação aleatória envolvendo duas variáveis – A e B. O teste A/B ajuda a identificar quaisquer alterações ou alterações feitas na página da web para maximizar o resultado de interesse. É um excelente método para determinar as melhores estratégias promocionais e de marketing online para empresas.
- O que é Viés de Seleção?
O viés de seleção é um erro 'ativo' que ocorre quando o pesquisador decide as amostras que serão estudadas. Nesse caso, os dados da amostra são coletados e preparados para modelagem de dados, mas possuem características que não são as verdadeiras representativas da população futura de casos que o modelo considerará. O viés de seleção ocorre quando um subconjunto dos dados da amostra é sistematicamente escolhido e incluído/excluído da análise de dados. Existem três tipos diferentes de viés de seleção:
- Viés de amostragem: um erro sistemático que ocorre quando uma amostra não aleatória de um conjunto de dados faz com que alguns membros do conjunto de dados sejam menos provavelmente incluídos no estudo, levando a uma amostra tendenciosa.
- Intervalo de tempo: ocorre quando um teste de análise de dados é encerrado antecipadamente em um valor extremo. No entanto, o valor extremo pode ser alcançado com maior probabilidade pela variável com a maior variância (mesmo que todas as variáveis possuam uma média semelhante).
- Attrition: Ocorre devido ao desconto de atrito, ou a perda de participantes durante um julgamento que foi encerrado antes da conclusão.
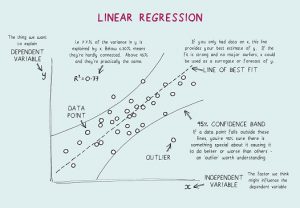
- O que é uma regressão linear? Quais são as suposições necessárias para a regressão linear?
A Regressão Linear é uma ferramenta estatística usada para análise preditiva. Nesse método, a pontuação de uma variável (digamos Y) é prevista a partir da pontuação de outra variável (digamos X). Aqui, Y é a variável critério, enquanto X é a variável preditora.
Na Regressão Linear, existem quatro suposições fundamentais:
- Existe uma relação linear entre as variáveis dependentes e os regressores. Assim, o modelo de dados criado estará em sincronia com os dados.
- Os resíduos dos dados são independentes uns dos outros e devem ser distribuídos.
- Há multicolinearidade mínima entre as variáveis explicativas.
- Existe 'homocedasticidade', o que significa que a variância em torno da linha de regressão é a mesma para todos os valores da variável preditora.
- O que é validação cruzada?
A validação cruzada é um procedimento de validação de modelo usado para. O objetivo aqui é denominar o conjunto de dados de validação para testar o modelo na fase de treinamento para limitar problemas como overfitting e, claro, determinar como o modelo será generalizado para um conjunto de dados independente.
A validação cruzada (CV) é uma técnica de validação de modelo empregada para testar a eficácia de modelos de aprendizado de máquina. É também um método de reamostragem usado para avaliar um modelo em caso de dados limitados. No método de validação cruzada, uma parte dos dados é reservada para teste e validação e é usada para determinar como os resultados da análise estatística serão generalizados para um conjunto de dados independente.

- O que é a Fórmula de Probabilidade Binomial?
A distribuição de probabilidade binomial leva em consideração as probabilidades de cada um dos possíveis números de sucessos de N número de tentativas para eventos independentes, cada uma tendo a probabilidade de ocorrência de π (pi). A fórmula para uma distribuição de probabilidade binomial é:
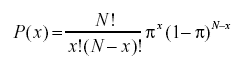
- Qual é a diferença de análise univariada, bivariada e multivariada?
A análise univariada refere-se à técnica de análise estatística descritiva que pode ser diferenciada com base no número de variáveis envolvidas em um determinado momento (por exemplo, gráficos de pizza representando as vendas de um produto em um território específico). Ao contrário disso, a análise bivariada visa entender e determinar a diferença entre duas variáveis ao mesmo tempo como em um gráfico de dispersão (por exemplo, a relação entre o volume de vendas e os gastos).
A análise multivariada envolve o estudo de mais de duas variáveis para entender o efeito das variáveis nas respostas/resultados.
- O que são Redes Neurais Artificiais?
Em termos simples, Redes Neurais Artificiais (RNA) refere-se a um sistema de computação projetado após o cérebro humano. Assim como o cérebro humano, as RNAs são compostas por inúmeros elementos de processamento simples, conhecidos como neurônios artificiais cuja funcionalidade é inspirada nos neurônios das espécies animais. As RNAs podem aprender através da experiência e podem se adaptar às mudanças de entrada para que a rede possa gerar o melhor resultado possível sem ter que redesenhar os critérios de saída.
- O que são Redes Neurais Recorrentes (RNNs)?
Uma rede neural recorrente (RNN) é um tipo de rede neural artificial na qual as conexões nodais resultam em um gráfico direcionado ao longo de uma sequência temporal, exibindo assim um comportamento dinâmico temporal. Para entender o RNN, você deve primeiro entender o funcionamento das redes feedforward. Enquanto as redes feedforward canalizam as informações em uma linha reta (sem tocar no mesmo nó duas vezes), as redes neurais recorrentes circulam as informações por meio de um processo semelhante a um loop. Ao contrário das redes neurais feedforward, as RNNs podem usar sua memória interna para processar sequências de entradas. Portanto, as RNNs são mais adequadas para tarefas não segmentadas ou conectadas, como reconhecimento de manuscrito e reconhecimento de fala.
As 17 principais perguntas e respostas da entrevista de analista de dados
- O que é retropropagação?
Backpropagation refere-se a um algoritmo de aprendizado supervisionado que é usado para treinar redes neurais multicamadas. Através da retropropagação, um erro pode ser movido de uma extremidade da rede para todos os pesos dentro da rede, permitindo assim o cálculo eficiente do gradiente. Ele procura o valor mínimo da função de erro no espaço de peso usando a técnica de gradiente descendente. Os pesos que minimizam a função de erro são considerados como a solução para o problema de aprendizagem.
- A retropropagação envolveu as seguintes etapas:
- Propagação direta de dados de treinamento.
- Calcular derivadas usando saída e destino.
- Voltar Propagar para calcular a derivada do erro.
- Use derivadas previamente calculadas para a saída.
- Calculando o valor de peso atualizado e atualizando os pesos.
- Explique a descida do gradiente.
Para entender Gradient Descent, você deve primeiro entender o que é um gradiente. Um gradiente é uma medida de quanto a saída de uma função específica muda em relação a uma pequena mudança nas entradas. Ele mede a mudança em todos os pesos em resposta a uma mudança no erro. Então, em outras palavras, um gradiente é a inclinação de uma função.
A descida do gradiente é um algoritmo de otimização que ajuda a encontrar os valores dos parâmetros (coeficientes) de uma função (f) que minimiza uma função de custo (custo). É mais adequado para casos em que os parâmetros não podem ser calculados analiticamente.
Conclusão
Em uma nota final, você deve saber que não existe uma única ou melhor maneira de se preparar para uma entrevista. É tudo sobre sua base de conhecimento, sua confiança e abordagem, e um pouco de sorte. Embora essas sejam apenas algumas perguntas sobre ciência de dados, esperamos que isso dê a você uma ideia aproximada sobre o tipo de perguntas que podem ser feitas em uma entrevista sobre ciência de dados. Dito isto, prepare-se bem e tudo de melhor para seus empreendimentos!
Aprenda cursos de ciência de dados das melhores universidades do mundo. Ganhe Programas PG Executivos, Programas de Certificado Avançado ou Programas de Mestrado para acelerar sua carreira.
Em uma entrevista de ciência de dados, quantas rodadas existem?
Uma ou duas rodadas de entrevistas de programação podem ser necessárias, mas isso depende totalmente da empresa para a qual você está se candidatando. Algumas empresas fazem o processo de entrevista durar até seis rodadas. Você pode preparar suas respostas para cada pergunta pesquisando as perguntas mais frequentes, fazendo uma lista das perguntas mais comuns e difíceis e analisando-as antes da entrevista.
Quais são as qualidades que os entrevistadores de ciência de dados procuram?
Para se dar bem em uma entrevista de ciência de dados, você precisará saber muito sobre aritmética, estatística, linguagens de programação, fundamentos de inteligência de negócios e, é claro, técnicas de aprendizado de máquina. Você certamente será solicitado a demonstrar como suas habilidades de dados se relacionam com as escolhas e a estratégia da empresa. No mercado atual, quase todos os trabalhos de ciência de dados exigem uma entrevista de codificação. O papel dos cientistas de dados inclui a liberação de código de produção, como pipelines de dados e modelos de aprendizado de máquina, em muitas empresas. Para projetos dessa natureza, também são necessárias fortes habilidades de programação, portanto, você também pode esperar algumas perguntas sobre SQL e Python na entrevista.
Posso conseguir um emprego de cientista de dados pelo LinkedIn?
Não se deve ignorar o poder do LinkedIn nos dias de hoje. O LinkedIn é basicamente o seu currículo digital. Empresas e recrutadores continuam procurando candidatos merecedores no LinkedIn, por isso é importante que você construa um perfil impressionante no LinkedIn, continue procurando trabalho e se candidate a vagas de emprego no LinkedIn. Adicione habilidades relevantes ao seu perfil e continue adicionando todas as suas conquistas profissionais. Dessa forma, suas chances de conseguir um emprego digno de ciência de dados no LinkedIn são altas.