
Domande e risposte sull'intervista sulla scienza dei dati - 15 domande più frequenti
Pubblicato: 2019-07-08I colloqui di lavoro sono sempre complicati. Per superare con successo un colloquio, devi possedere non solo una conoscenza approfondita della materia, ma anche sicurezza e una forte presenza mentale. Ciò è particolarmente vero se ti stai preparando per una scienza dei dati: mette alla prova tutte le tue facoltà!
Durante un colloquio di Data Science, dovrai affrontare una serie di domande che abbracciano diversi argomenti che vanno dalle domande di base di Data Science a Statistica, Analisi dei dati, ML e Deep Learning. Ma non è tutto: anche le tue competenze trasversali (comunicazione, lavoro di squadra e altro) saranno messe alla prova.
Per facilitare il processo di preparazione per te, abbiamo curato un elenco delle 15 domande più frequenti per i colloqui di Data Science. Inizieremo con i fondamenti e poi passeremo agli argomenti e ai problemi più avanzati.
Quindi, senza ulteriori indugi, iniziamo!
- Cos'è la scienza dei dati? In che cosa differiscono l'apprendimento automatico supervisionato e non supervisionato?
In parole povere, Data Science è lo studio dei dati. Implica la raccolta di dati da fonti disparate, l'archiviazione, la pulizia e l'organizzazione e l'analisi per scoprire informazioni significative da essi. Data Science utilizza una combinazione di matematica, informatica statistica, machine learning, visualizzazione dei dati, analisi dei cluster e modellazione dei dati. Mira a ottenere preziose informazioni dai dati grezzi (sia strutturati che non strutturati) e utilizzare tali informazioni per influenzare positivamente le strategie aziendali e IT. Tali idee possono aiutare le aziende a ottimizzare i processi, aumentare la produttività e le entrate, ottimizzare le strategie di marketing, aumentare la soddisfazione dei clienti e molto altro.
Supervised e Unsupervised ML differiscono l'uno dall'altro per i seguenti aspetti:
- Nel ML supervisionato, i dati di input sono etichettati. In ML non supervisionato, i dati di input rimangono senza etichetta.
- Mentre il ML supervisionato utilizza il set di dati di addestramento, il ML non supervisionato utilizza il set di dati di input.
- Il ML supervisionato viene utilizzato a fini di previsione, mentre il ML non supervisionato viene utilizzato a fini di analisi.
- Supervised ML consente la classificazione e la regressione. Tuttavia, il ML non supervisionato consente la classificazione, la stima della densità e la riduzione delle dimensioni.
- Python o R: qual è il migliore per l'analisi del testo?
Quando si tratta di analisi del testo, Python sembra l'opzione più adatta. Questo perché viene fornito con la libreria Pandas che include strutture di dati intuitive e strumenti di analisi dei dati ad alte prestazioni. Inoltre, Python è altamente efficiente e veloce per tutti i tipi di attività di analisi del testo. Per quanto riguarda R, è più adatto per applicazioni di Machine Learning.
- Quali sono i tipi di dati supportati in Python?
Python ha una serie di tipi di dati integrati, tra cui:
- booleano
- Numerico (Interi, Long, Float, Complex)
- Sequenze (liste, stringhe, byte, tuple)
- Imposta
- Mapping (Dizionari)
- Oggetti file
- Quali sono i diversi algoritmi di classificazione?
Gli algoritmi di classificazione cardine sono classificatori lineari (regressione logistica, classificatore Naive Bayes), alberi decisionali, alberi potenziati, foresta casuale, SVM, stima del kernel, reti neurali e vicino più prossimo.
- Cos'è la distribuzione normale?
Di solito, i dati sono distribuiti in vari modi, con una distorsione a sinistra oa destra o, in alcune circostanze, possono diventare confusi. Tuttavia, potrebbero esserci casi in cui i dati sono distribuiti attorno a un valore centrale senza alcuna distorsione a sinistra oa destra, ottenendo così una distribuzione normale sotto forma di una curva a campana.
Fonte
La curva rappresenta la distribuzione di variabili casuali sotto forma di una curva a campana simmetrica.
- Qual è l'importanza del test A/B?
Il test A/B è un test di ipotesi statistica per la sperimentazione casuale che coinvolge due variabili: A e B. Il test A/B aiuta a identificare eventuali modifiche o alterazioni apportate alla pagina Web per massimizzare il risultato di interesse. È un metodo eccellente per determinare le migliori strategie promozionali e di marketing online per le aziende.
- Cos'è il bias di selezione?
Il bias di selezione è un errore "attivo" che si verifica quando il ricercatore decide i campioni che verranno studiati. In questo caso, i dati del campione vengono raccolti e preparati per la modellazione dei dati, ma presentano caratteristiche tali che non sono il vero rappresentante della futura popolazione di casi che il modello prenderà in considerazione. La distorsione di selezione si verifica quando un sottoinsieme dei dati del campione viene scelto sistematicamente e incluso/escluso dall'analisi dei dati. Esistono tre diversi tipi di bias di selezione:
- Bias di campionamento: un errore sistematico che si verifica quando un campione non casuale di un set di dati fa sì che alcuni membri del set di dati siano meno probabilmente inclusi nello studio, portando così a un campione distorto.
- Intervallo di tempo: si verifica quando una prova di analisi dei dati viene interrotta anticipatamente a un valore estremo. Tuttavia, il valore estremo può essere raggiunto più probabilmente dalla variabile che porta la varianza maggiore (anche se tutte le variabili possiedono una media simile).
- Attrito: si verifica a causa dello sconto sull'abbandono o della perdita di partecipanti durante una prova che è stata interrotta prima del completamento.
- Che cos'è una regressione lineare? Quali sono le ipotesi richieste per la regressione lineare?
La regressione lineare è uno strumento statistico utilizzato per l'analisi predittiva. In questo metodo, il punteggio di una variabile (diciamo Y) è previsto dal punteggio di un'altra variabile (diciamo X). Qui, Y è la variabile di criterio, mentre X è la variabile predittiva.
Nella regressione lineare, ci sono quattro ipotesi fondamentali:
- Esiste una relazione lineare tra le variabili dipendenti e i regressori. Quindi, il modello di dati creato sarà sincronizzato con i dati.
- I residui dei dati sono indipendenti l'uno dall'altro e da distribuire.
- C'è una multicollinearità minima tra le variabili esplicative.
- C'è "omoscedasticità", il che significa che la varianza attorno alla retta di regressione è la stessa per tutti i valori della variabile predittiva.
- Che cos'è la convalida incrociata?
La convalida incrociata è una procedura di convalida del modello utilizzata per. Lo scopo qui è definire il set di dati di convalida per testare il modello nella fase di addestramento per limitare problemi come l'overfitting e, naturalmente, determinare come il modello si generalizzerà a un set di dati indipendente.
La convalida incrociata (CV) è una tecnica di convalida del modello utilizzata per testare l'efficacia dei modelli di apprendimento automatico. È anche un metodo di ricampionamento utilizzato per valutare un modello in caso di dati limitati. Nel metodo di convalida incrociata, una parte dei dati viene riservata ai test e alla convalida e viene utilizzata per determinare in che modo i risultati dell'analisi statistica si generalizzeranno a un set di dati indipendente.

- Qual è la formula di probabilità binomiale?
La distribuzione binomiale di probabilità prende in considerazione le probabilità di ciascuno dei possibili numeri di successi su N numero di prove per eventi indipendenti, ciascuno avente la probabilità di occorrenza di π (pi). La formula per una distribuzione di probabilità binomiale è:
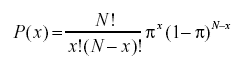
- Qual è la differenza tra analisi univariata, bivariata e multivariata?
L'analisi univariata si riferisce alla tecnica di analisi statistica descrittiva che può essere differenziata in base al numero di variabili coinvolte in un determinato momento (ad esempio, grafici a torta raffiguranti le vendite di un prodotto in un determinato territorio). Contrariamente a ciò, l'analisi bivariata mira a comprendere e determinare la differenza tra due variabili alla volta come in uno scatterplot (ad esempio, la relazione tra il volume delle vendite e la spesa).
L'analisi multivariata prevede lo studio di più di due variabili per comprendere l'effetto delle variabili sulle risposte/risultati.
- Cosa sono le reti neurali artificiali?
In parole povere, Artificial Neural Networks (ANN) si riferisce a un sistema informatico progettato secondo il cervello umano. Proprio come il cervello umano, le RNA sono composte da numerosi semplici elementi di elaborazione, noti come neuroni artificiali la cui funzionalità è ispirata ai neuroni nelle specie animali. Le reti ANN possono apprendere attraverso l'esperienza e possono adattarsi al cambiamento di input in modo che la rete possa generare il miglior risultato possibile senza dover riprogettare i criteri di output.
- Cosa sono le reti neurali ricorrenti (RNN)?
Una rete neurale ricorrente (RNN) è un tipo di rete neurale artificiale in cui le connessioni nodali risultano in un grafico diretto lungo una sequenza temporale, esibendo così un comportamento dinamico temporale. Per capire RNN, devi prima capire il funzionamento delle reti feedforward. Mentre le reti feedforward incanalano le informazioni in linea retta (senza toccare due volte lo stesso nodo), le reti neurali ricorrenti ciclano le informazioni attraverso un processo simile a un ciclo. Contrariamente alle reti neurali feedforward, le RNN possono utilizzare la loro memoria interna per elaborare sequenze di input. Pertanto, gli RNN sono più adatti per attività non segmentate o connesse, come il riconoscimento della grafia e il riconoscimento vocale.
Le 17 principali domande e risposte per le interviste agli analisti di dati
- Che cos'è la propagazione posteriore?
La backpropagation si riferisce a un algoritmo di apprendimento supervisionato utilizzato per addestrare reti neurali multistrato. Attraverso la backpropagation, un errore può essere spostato da un'estremità della rete a tutti i pesi all'interno della rete, consentendo così un calcolo efficiente del gradiente. Cerca il valore minimo della funzione di errore nello spazio peso utilizzando la tecnica della discesa del gradiente. I pesi che minimizzano la funzione di errore sono considerati la soluzione al problema di apprendimento.
- La backpropagation ha comportato i seguenti passaggi:
- Propagazione in avanti dei dati di addestramento.
- Calcola derivati usando output e target.
- Indietro Propaga per calcolare la derivata dell'errore.
- Utilizzare le derivate calcolate in precedenza per l'output.
- Calcolo del valore di peso aggiornato e aggiornamento dei pesi.
- Spiega la discesa del gradiente.
Per capire la discesa del gradiente, devi prima capire cos'è un gradiente. Un gradiente è una misura di quanto cambia l'output di una particolare funzione in relazione a un cambiamento minore negli input. Misura la variazione di tutti i pesi in risposta a una variazione in errore. Quindi, in altre parole, un gradiente è la pendenza di una funzione.
La discesa del gradiente è un algoritmo di ottimizzazione che aiuta a trovare i valori dei parametri (coefficienti) di una funzione (f) che riduce al minimo una funzione di costo (costo). È più adatto per i casi in cui i parametri non possono essere calcolati analiticamente.
Conclusione
In una nota conclusiva, devi sapere che non esiste un modo unico o migliore per prepararsi per un colloquio. Riguarda la tua base di conoscenze, la tua sicurezza, il tuo approccio e un po' di fortuna. Sebbene queste siano solo una manciata di domande sulla scienza dei dati, speriamo che questo ti dia un'idea approssimativa del tipo di domande che possono essere poste in un'intervista sulla scienza dei dati. Detto questo, preparati bene e tutto il meglio per i tuoi sforzi!
Impara i corsi di scienza dei dati dalle migliori università del mondo. Guadagna programmi Executive PG, programmi di certificazione avanzati o programmi di master per accelerare la tua carriera.
In un'intervista sulla scienza dei dati, quanti round ci sono?
Potrebbero essere necessari uno o due turni di colloqui di programmazione, ma questo dipende interamente dall'azienda per cui ti stai candidando. Alcune aziende fanno durare il processo di intervista fino a sei round. Puoi preparare le tue risposte per ogni domanda ricercando le domande più frequenti, facendo un elenco delle domande più comuni e difficili e quindi analizzandole prima del colloquio.
Quali sono le qualità che cercano gli intervistatori di scienza dei dati?
Per vincere un colloquio sulla scienza dei dati, dovrai conoscere molto su aritmetica, statistica, linguaggi di programmazione, fondamenti di business intelligence e, naturalmente, tecniche di apprendimento automatico. Ti verrà sicuramente chiesto di dimostrare in che modo le tue capacità di dati si relazionano alle scelte e alla strategia dell'azienda. Nel mercato odierno, quasi tutti i lavori di scienza dei dati richiedono un colloquio di codifica. Il ruolo dei data scientist include il rilascio di codice di produzione, come pipeline di dati e modelli di machine learning, in molte aziende. Per progetti di questa natura sono richieste anche forti capacità di programmazione, quindi puoi aspettarti anche alcune domande su SQL e Python nell'intervista.
Posso ottenere un lavoro come scienziato dei dati tramite LinkedIn?
Non bisogna trascurare il potere di LinkedIn in questi giorni. LinkedIn è fondamentalmente il tuo curriculum digitale. Le aziende e i reclutatori continuano a cercare candidati meritevoli su LinkedIn, quindi è importante per te creare un profilo LinkedIn impressionante, continuare a cercare lavoro e fare domanda per offerte di lavoro su LinkedIn. Aggiungi competenze pertinenti al tuo profilo e continua ad aggiungere tutti i tuoi risultati professionali. In questo modo, le tue possibilità di ottenere un lavoro meritevole di data science da LinkedIn sono elevate.