
Veri Bilimi Mülakat Soruları ve Cevapları – En Sık Sorulan 15 Soru
Yayınlanan: 2019-07-08İş görüşmeleri her zaman zordur. Bir röportajı başarılı bir şekilde kırmak için, yalnızca derinlemesine konu bilgisine değil, aynı zamanda kendine güven ve güçlü bir zihin varlığına da sahip olmalısınız. Bu, özellikle bir Veri Bilimi için hazırlanıyorsanız geçerlidir - tüm fakültelerinizi teste tabi tutar!
Bir Veri Bilimi görüşmesi sırasında, temel Veri Bilimi sorularından İstatistik, Veri Analizi, ML ve Derin Öğrenmeye kadar çeşitli konulardan oluşan bir dizi soruyla yüzleşmeniz gerekecek. Ancak hepsi bu kadar değil – sosyal becerileriniz (iletişim, ekip çalışması ve daha fazlası) da test edilecek.
Hazırlık sürecini sizin için kolaylaştırmak için en sık sorulan 15 Veri Bilimi mülakat sorusunun bir listesini hazırladık. Temel bilgilerle başlayacağız ve ardından daha gelişmiş konulara ve konulara geçeceğiz.
O halde, daha fazla uzatmadan başlayalım!
- Veri Bilimi Nedir? Denetimli ve Denetimsiz Makine Öğrenimi nasıl farklıdır?
Basit bir deyişle, Veri Bilimi veri çalışmasıdır. Farklı kaynaklardan veri toplamayı, depolamayı, temizlemeyi ve düzenlemeyi ve ondan anlamlı bilgiler ortaya çıkarmak için analiz etmeyi içerir. Veri Bilimi, Matematik, İstatistik Bilgisayar Bilimi, Makine Öğrenimi, Veri Görselleştirme, Küme Analizi ve Veri Modellemenin bir kombinasyonunu kullanır. Ham verilerden (hem yapılandırılmış hem de yapılandırılmamış) değerli bilgiler elde etmeyi ve bu bilgileri iş ve BT stratejilerini olumlu yönde etkilemek için kullanmayı amaçlar. Bu tür fikirler, işletmelerin süreçleri optimize etmesine, üretkenliği ve geliri artırmasına, pazarlama stratejilerini düzene sokmasına, müşteri memnuniyetini artırmasına ve çok daha fazlasına yardımcı olabilir.
Denetimli ve Denetimsiz ML, aşağıdaki açılardan birbirinden farklıdır:
- Denetimli ML'de giriş verileri etiketlenir. Denetimsiz ML'de giriş verileri etiketsiz kalır.
- Denetimli makine öğrenimi eğitim veri kümesini kullanırken, denetimsiz makine öğrenimi giriş veri kümesini kullanır.
- Denetimli ML tahmin amacıyla kullanılırken, denetimsiz ML analiz amacıyla kullanılır.
- Denetimli ML, sınıflandırma ve gerileme sağlar. Ancak denetimsiz ML, sınıflandırma, yoğunluk tahmini ve boyut küçültme sağlar.
- Python veya R – Metin analizi için hangisi daha iyi?
Metin analizi söz konusu olduğunda Python en uygun seçenek gibi görünüyor. Bunun nedeni, kullanıcı dostu veri yapıları ve yüksek performanslı veri analiz araçları içeren Pandas kitaplığı ile birlikte gelmesidir. Ayrıca Python, her türlü metin analizi görevi için oldukça verimli ve hızlıdır. R'ye gelince, Makine Öğrenimi uygulamaları için en uygun olanıdır.
- Python'da desteklenen veri türleri nelerdir?
Python'da aşağıdakiler de dahil olmak üzere bir dizi yerleşik veri türü bulunur:
- Boole
- Sayısal (Tamsayılar, Uzun, Kayan Nokta, Karmaşık)
- Diziler (Listeler, Dizeler, Bayt, Tuple)
- Setler
- Eşlemeler (Sözlükler)
- Dosya nesneleri
- Farklı sınıflandırma algoritmaları nelerdir?
Temel sınıflandırma algoritmaları, doğrusal sınıflandırıcılar (lojistik regresyon, Naive Bayes sınıflandırıcı), karar ağaçları, artırılmış ağaçlar, rastgele orman, SVM, çekirdek tahmini, sinir ağları ve en yakın komşudur.
- Normal Dağılım Nedir?
Genellikle, veriler ya sola ya da sağa bir sapma ile çeşitli şekillerde dağıtılır ya da birkaç durumda karışık hale gelebilir. Bununla birlikte, verilerin sola veya sağa herhangi bir sapma olmaksızın merkezi bir değer etrafında dağıtıldığı ve böylece çan şeklindeki bir eğri şeklinde normal bir dağılım elde edildiği durumlar olabilir.
Kaynak
Eğri, rasgele değişkenlerin dağılımını simetrik çan şeklinde bir eğri şeklinde gösterir.
- A/B Testinin önemi nedir?
A/B testi, A ve B olmak üzere iki değişkeni içeren rastgele deneyler için istatistiksel bir hipotez testidir. A/B Testi, ilgilenilen sonucu en üst düzeye çıkarmak için web sayfasında yapılan herhangi bir değişiklik veya değişikliğin belirlenmesine yardımcı olur. İşletmeler için en iyi çevrimiçi tanıtım ve pazarlama stratejilerini belirlemek için mükemmel bir yöntemdir.
- Seçim Önyargısı nedir?
Seçim Yanlılığı, araştırmacının çalışacağı örneklere karar verdiğinde ortaya çıkan 'aktif' bir hatadır. Bu durumda, örnek veriler toplanır ve veri modellemesi için hazırlanır, ancak modelin dikkate alacağı gelecekteki vaka popülasyonunun gerçek temsilcisi olmayan özellikleri taşır. Seçim yanlılığı, örnek verilerin bir alt kümesi sistematik olarak seçildiğinde ve veri analizine dahil edildiğinde/hariç tutulduğunda gerçekleşir. Üç farklı Seçim Önyargısı türü vardır:
- Örnekleme yanlılığı: Bir veri setinin rasgele olmayan bir örneğinin, veri setinin bazı üyelerinin çalışmaya dahil edilme olasılığının azalmasına ve dolayısıyla yanlı bir örneğe yol açmasına neden olduğunda ortaya çıkan sistematik bir hata.
- Zaman aralığı: Bir veri analizi denemesi aşırı bir değerde erken sonlandırıldığında oluşur. Bununla birlikte, uç değere, en büyük varyansı taşıyan değişken tarafından daha muhtemel olarak ulaşılabilir (tüm değişkenler benzer bir ortalamaya sahip olsa bile).
- Yıpranma: Yıpranma indirimi veya tamamlanmadan sonlandırılan bir deneme sırasında katılımcıların kaybı nedeniyle oluşur.
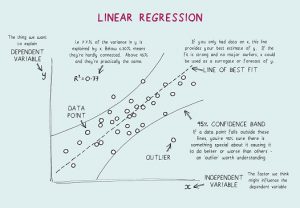
- Doğrusal Regresyon Nedir? Doğrusal regresyon için gerekli varsayımlar nelerdir?
Doğrusal Regresyon, tahmine dayalı analiz için kullanılan istatistiksel bir araçtır. Bu yöntemde, bir değişkenin (örneğin Y) puanı, başka bir değişkenin (örneğin X) puanından tahmin edilir. Burada Y ölçüt değişkeni, X ise öngörücü değişkendir.
Doğrusal Regresyonda dört temel varsayım vardır:
- Bağımlı değişkenler ve regresörler arasında doğrusal bir ilişki vardır. Böylece oluşturulan veri modeli verilerle senkronize olacaktır.
- Verilerin artıkları birbirinden bağımsızdır ve dağıtılacaktır.
- Açıklayıcı değişkenler arasında minimum çoklu doğrusallık vardır.
- Regresyon çizgisi etrafındaki varyansın, tahmin değişkeninin tüm değerleri için aynı olduğu anlamına gelen 'homosedastisite' vardır.
- Çapraz doğrulama nedir?
Çapraz doğrulama, kullanılan bir model doğrulama prosedürüdür. Buradaki amaç, modeli eğitim aşamasında test etmek ve aşırı uyum gibi sorunları sınırlamak ve tabii ki modelin bağımsız bir veri kümesine nasıl genelleşeceğini belirlemek için doğrulama veri kümesini adlandırmaktır.
Çapraz doğrulama (CV), makine öğrenimi modellerinin etkinliğini test etmek için kullanılan bir model doğrulama tekniğidir. Ayrıca sınırlı veri olması durumunda bir modeli değerlendirmek için kullanılan yeniden örnekleme yöntemidir. Çapraz doğrulama yönteminde, verilerin bir kısmı test ve doğrulama için ayrılır ve istatistiksel analizin sonuçlarının Bağımsız bir veri kümesine nasıl genelleneceğini belirlemek için kullanılır.

- Binom Olasılık Formülü nedir?
Binom olasılık dağılımı, her birinin meydana gelme olasılığı π (pi) olan bağımsız olaylar için N sayıda denemeden olası başarı sayılarının her birinin olasılıklarını dikkate alır. Binom olasılık dağılımı için formül:
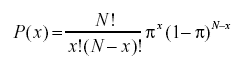
- Tek Değişkenli, İki Değişkenli ve Çok Değişkenli analiz arasındaki fark nedir?
Tek değişkenli analiz, belirli bir zaman noktasında dahil olan değişkenlerin sayısına göre farklılaştırılabilen tanımlayıcı istatistiksel analiz tekniğini ifade eder (örneğin, belirli bir bölgedeki bir ürünün satışını gösteren pasta grafikler). Bunun aksine, iki değişkenli analiz, bir dağılım grafiğinde olduğu gibi bir anda iki değişken arasındaki farkı (örneğin, satış hacmi ve harcama arasındaki ilişkiyi) anlamayı ve belirlemeyi amaçlar.
Çok değişkenli analiz, değişkenlerin yanıtlar/sonuçlar üzerindeki etkisini anlamak için ikiden fazla değişkenin incelenmesini içerir.
- Yapay Sinir Ağları nedir?
Basit bir ifadeyle, Yapay Sinir Ağları (YSA), insan beyninden sonra tasarlanmış bir bilgi işlem sistemini ifade eder. Tıpkı insan beyni gibi, YSA'lar, işlevselliği hayvan türlerindeki nöronlardan ilham alan yapay nöronlar olarak bilinen çok sayıda basit işleme öğesinden oluşur. YSA'lar deneyim yoluyla öğrenebilir ve değişen girdilere uyum sağlayabilir, böylece ağın çıktı kriterlerini yeniden tasarlamak zorunda kalmadan mümkün olan en iyi sonucu üretebilir.
- Tekrarlayan Sinir Ağları (RNN'ler) nedir?
Tekrarlayan bir sinir ağı (RNN), düğüm bağlantılarının zamansal bir dizi boyunca yönlendirilmiş bir grafikle sonuçlandığı ve böylece zamansal dinamik davranış sergilediği bir tür yapay sinir ağıdır. RNN'yi anlamak için önce ileri beslemeli ağların işleyişini anlamalısınız. İleri beslemeli ağlar bilgiyi düz bir çizgide (aynı düğüme iki kez dokunmadan) yönlendirirken, tekrarlayan sinir ağları bilgiyi döngü benzeri bir süreç boyunca döndürür. İleri beslemeli sinir ağlarının aksine, RNN'ler girdi dizilerini işlemek için dahili belleklerini kullanabilirler. Bu nedenle, RNN'ler, el yazısı tanıma ve konuşma tanıma gibi bölümlere ayrılmamış veya bağlantılı görevler için en uygun olanıdır.
En İyi 17 Veri Analisti Mülakat Soruları ve Cevapları
- Geri Yayılım nedir?
Geri yayılım, çok katmanlı sinir ağlarını eğitmek için kullanılan denetimli bir öğrenme algoritmasını ifade eder. Geri yayılım yoluyla, bir hata ağın bir ucundan ağ içindeki tüm ağırlıklara taşınabilir, böylece gradyanın verimli bir şekilde hesaplanmasına izin verilir. Gradyan iniş tekniğini kullanarak ağırlık-uzayda hata fonksiyonunun minimum değerini arar. Hata fonksiyonunu en aza indiren ağırlıklar, öğrenme probleminin çözümü olarak kabul edilir.
- Geri yayılım aşağıdaki adımları içeriyordu:
- Eğitim verilerinin ileriye doğru yayılması.
- Çıktı ve hedef kullanarak türevleri hesaplayın.
- Hatanın türevini hesaplamak için Geri Yay.
- Çıktı için önceden hesaplanmış türevleri kullanın.
- Güncellenen ağırlık değerinin hesaplanması ve ağırlıkların güncellenmesi.
- Gradient Descent'i açıklayın.
Gradient Descent'i anlamak için önce degradenin ne olduğunu anlamalısınız. Gradyan, belirli bir fonksiyonun çıktısının girdilerdeki küçük bir değişikliğe göre ne kadar değiştiğinin bir ölçüsüdür. Hatadaki bir değişikliğe tepki olarak tüm ağırlıklardaki değişikliği ölçer. Başka bir deyişle, gradyan bir fonksiyonun eğimidir.
Gradyan iniş, bir maliyet fonksiyonunu (maliyet) en aza indiren bir fonksiyonun (f) parametrelerinin (katsayılarının) değerlerini bulmaya yardımcı olan bir optimizasyon algoritmasıdır. Parametrelerin analitik olarak hesaplanamadığı durumlar için en uygunudur.
Çözüm
Sonuç olarak, bir görüşmeye hazırlanmanın tek veya en iyi yolu olmadığını bilmelisiniz. Her şey bilgi tabanınız, güveniniz ve yaklaşımınız ve biraz da şansınızla ilgili. Bunlar sadece birkaç Veri Bilimi sorusu olsa da, bunun bir Veri Bilimi röportajında sorulabilecek soru türleri hakkında size kabaca bir fikir vereceğini umuyoruz. Bununla birlikte, iyi hazırlanın ve çabalarınız için en iyisini yapın!
Dünyanın en iyi Üniversitelerinden veri bilimi derslerini öğrenin . Kariyerinizi hızlandırmak için Yönetici PG Programları, Gelişmiş Sertifika Programları veya Yüksek Lisans Programları kazanın.
Bir veri bilimi röportajında kaç tur var?
Bir veya iki tur programlama görüşmesi gerekebilir, ancak bu tamamen başvurduğunuz şirkete bağlıdır. Bazı firmalar görüşme sürecini altı tura kadar uzatır. En sık sorulan soruları araştırarak, en yaygın ve zor soruların bir listesini yaparak ve ardından görüşmenizden önce bu soruları analiz ederek her soruya yanıtlarınızı hazırlayabilirsiniz.
Veri bilimi görüşmecilerinin aradığı nitelikler nelerdir?
Bir veri bilimi röportajında başarılı olmak için aritmetik, istatistik, programlama dilleri, iş zekasının temelleri ve tabii ki makine öğrenimi teknikleri hakkında çok şey bilmeniz gerekir. Veri yeteneklerinizin şirket seçimleri ve stratejisiyle nasıl ilişkili olduğunu göstermeniz kesinlikle istenecektir. Günümüz pazarında, hemen hemen her veri bilimi işi, bir kodlama görüşmesi gerektirir. Veri bilimcilerinin rolü, birçok firmada veri boru hatları ve makine öğrenimi modelleri gibi üretim kodunun yayınlanmasını içerir. Bu nitelikteki projeler için güçlü programlama becerileri de gereklidir, bu nedenle röportajda bazı SQL ve Python soruları da bekleyebilirsiniz.
LinkedIn aracılığıyla bir veri bilimcisi işi alabilir miyim?
Bugünlerde LinkedIn'in gücünü gözden kaçırmamak gerekir. LinkedIn temel olarak dijital özgeçmişinizdir. Şirketler ve işverenler LinkedIn'de hak eden adaylar aramaya devam ediyor, bu nedenle etkileyici bir LinkedIn profili oluşturmanız, iş aramaya devam etmeniz ve LinkedIn'de iş ilanlarına başvurmanız önemlidir. Profilinize ilgili becerileri ekleyin ve tüm profesyonel başarılarınızı eklemeye devam edin. Bu şekilde, LinkedIn'den hak ettiğiniz bir veri bilimi işine girme şansınız yüksektir.