
Questions et réponses d'entrevue en science des données - 15 questions les plus fréquemment posées
Publié: 2019-07-08Les entretiens d'embauche sont toujours délicats. Pour réussir un entretien, vous devez posséder non seulement une connaissance approfondie du sujet, mais également de la confiance et une forte présence d'esprit. C'est d'autant plus vrai si vous vous préparez à un Data Science – cela met toutes vos facultés à l'épreuve !
Au cours d'un entretien en science des données, vous devrez affronter une foule de questions couvrant divers sujets allant des questions de base en science des données aux statistiques, à l'analyse des données, au ML et à l'apprentissage en profondeur. Mais ce n'est pas tout - vos compétences générales (communication, travail d'équipe, etc.) seront également testées.
Pour vous faciliter le processus de préparation, nous avons dressé une liste des 15 questions d'entretien les plus fréquemment posées en Data Science. Nous allons commencer par les fondamentaux, puis passer aux sujets et problèmes plus avancés.
Alors, sans plus tarder, commençons !
- Qu'est-ce que la science des données ? En quoi l'apprentissage automatique supervisé et non supervisé diffère-t-il ?
En clair, la science des données est l'étude des données. Cela implique la collecte de données provenant de sources disparates, leur stockage, leur nettoyage et leur organisation, et leur analyse pour en découvrir des informations significatives. La science des données utilise une combinaison de mathématiques, d'informatique statistique, d'apprentissage automatique, de visualisation de données, d'analyse de cluster et de modélisation de données. Il vise à obtenir des informations précieuses à partir de données brutes (structurées et non structurées) et à utiliser ces informations pour influencer positivement les stratégies commerciales et informatiques. De telles idées peuvent aider les entreprises à optimiser les processus, à augmenter la productivité et les revenus, à rationaliser les stratégies marketing, à améliorer la satisfaction client, et bien plus encore.
Le ML supervisé et non supervisé diffèrent les uns des autres sur les points suivants :
- En ML supervisé, les données d'entrée sont étiquetées. Dans le ML non supervisé, les données d'entrée restent sans étiquette.
- Alors que le ML supervisé utilise un ensemble de données d'apprentissage, le ML non supervisé utilise l'ensemble de données d'entrée.
- Le ML supervisé est utilisé à des fins de prédiction, tandis que le ML non supervisé est utilisé à des fins d'analyse.
- Le ML supervisé permet la classification et la régression. Cependant, le ML non supervisé permet la classification, l'estimation de la densité et la réduction des dimensions.
- Python ou R - Quel est le meilleur pour l'analyse de texte ?
En ce qui concerne l'analyse de texte, Python semble être l'option la plus appropriée. En effet, il est livré avec la bibliothèque Pandas qui comprend des structures de données conviviales et des outils d'analyse de données hautes performances. De plus, Python est très efficace et rapide pour toutes sortes de tâches d'analyse de texte. Quant à R, il est le mieux adapté aux applications d'apprentissage automatique.
- Quels sont les types de données pris en charge en Python ?
Python possède un tableau de types de données intégrés, notamment :
- booléen
- Numérique (entiers, longs, flottants, complexes)
- Séquences (listes, chaînes, octets, tuple)
- Ensembles
- Mappages (Dictionnaires)
- Objets de fichier
- Quels sont les différents algorithmes de classification ?
Les algorithmes de classification pivot sont les classificateurs linéaires (régression logistique, classificateur Naive Bayes), les arbres de décision, les arbres boostés, la forêt aléatoire, le SVM, l'estimation par noyau, les réseaux de neurones et le voisin le plus proche.
- Qu'est-ce que la distribution normale ?
Habituellement, les données sont distribuées de différentes manières, soit avec un biais vers la gauche ou vers la droite, soit dans quelques circonstances, elles peuvent devenir confuses. Cependant, il peut y avoir des cas où les données sont distribuées autour d'une valeur centrale sans aucun biais vers la gauche ou la droite, atteignant ainsi une distribution normale sous la forme d'une courbe en forme de cloche.
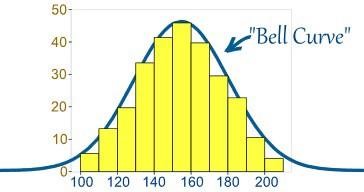
La source
La courbe représente la distribution des variables aléatoires sous la forme d'une courbe symétrique en forme de cloche.
- Quelle est l'importance des tests A/B ?
Le test A/B est un test d'hypothèse statistique pour une expérimentation aléatoire impliquant deux variables - A et B. Le test A/B aide à identifier tout changement ou altération apporté à la page Web afin de maximiser le résultat d'intérêt. C'est une excellente méthode pour déterminer les meilleures stratégies de promotion et de marketing en ligne pour les entreprises.
- Qu'est-ce que le biais de sélection ?
Le biais de sélection est une erreur « active » qui se produit lorsque le chercheur décide des échantillons qui vont être étudiés. Dans ce cas, les données de l'échantillon sont collectées et préparées pour la modélisation des données, mais elles présentent des caractéristiques qui ne sont pas le véritable représentant de la future population de cas que le modèle prendra en compte. Un biais de sélection se produit lorsqu'un sous-ensemble des données de l'échantillon est systématiquement choisi et inclus/exclu de l'analyse des données. Il existe trois types différents de biais de sélection :
- Biais d'échantillonnage : une erreur systématique qui se produit lorsqu'un échantillon non aléatoire d'un ensemble de données fait en sorte que certains membres de l'ensemble de données sont moins susceptibles d'être inclus dans l'étude, ce qui entraîne un échantillon biaisé.
- Intervalle de temps : Il se produit lorsqu'un essai d'analyse de données se termine prématurément à une valeur extrême. Cependant, la valeur extrême peut être atteinte plus probablement par la variable portant la plus grande variance (même si toutes les variables possèdent une moyenne similaire).
- Attrition : Cela se produit en raison d'une réduction d'attrition ou de la perte de participants lors d'un essai qui s'est terminé avant la fin.
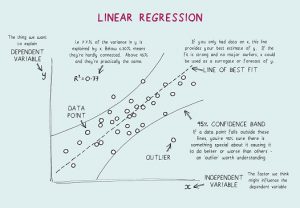
- Qu'est-ce qu'une régression linéaire ? Quelles sont les hypothèses requises pour la régression linéaire ?
La régression linéaire est un outil statistique utilisé pour l'analyse prédictive. Dans cette méthode, le score d'une variable (disons Y) est prédit à partir du score d'une autre variable (disons X). Ici, Y est la variable critère, tandis que X est la variable prédictive.
Dans la régression linéaire, il y a quatre hypothèses fondamentales :
- Une relation linéaire existe entre les variables dépendantes et les régresseurs. Ainsi, le modèle de données créé sera synchronisé avec les données.
- Les résidus des données sont indépendants les uns des autres et doivent être distribués.
- La multicolinéarité entre les variables explicatives est minime.
- Il y a « homoscédasticité », ce qui signifie que la variance autour de la ligne de régression est la même pour toutes les valeurs de la variable prédictive.
- Qu'est-ce que la validation croisée ?
La validation croisée est une procédure de validation de modèle utilisée pour. Le but ici est de nommer l'ensemble de données de validation pour tester le modèle dans la phase de formation afin de limiter les problèmes tels que le surajustement et bien sûr, de déterminer comment le modèle se généralisera à un ensemble de données indépendant.
La validation croisée (CV) est une technique de validation de modèle utilisée pour tester l'efficacité des modèles d'apprentissage automatique. C'est aussi une méthode de ré-échantillonnage utilisée pour évaluer un modèle en cas de données limitées. Dans la méthode de validation croisée, une partie des données est réservée aux tests et à la validation et est utilisée pour déterminer comment les résultats de l'analyse statistique se généraliseront à un ensemble de données indépendant.

- Qu'est-ce que la formule de probabilité binomiale ?
La distribution de probabilité binomiale prend en considération les probabilités de chacun des nombres possibles de succès sur N nombre d'essais pour des événements indépendants, chacun ayant la probabilité d'occurrence de π (pi). La formule d'une distribution de probabilité binomiale est la suivante :
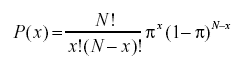
- Quelle est la différence entre l'analyse univariée, bivariée et multivariée ?
L'analyse univariée fait référence à la technique d'analyse statistique descriptive qui peut être différenciée en fonction du nombre de variables impliquées à un moment donné (par exemple, des diagrammes circulaires illustrant les ventes d'un produit dans un territoire spécifique). Contrairement à cela, l'analyse bivariée vise à comprendre et à déterminer la différence entre deux variables à la fois comme dans un nuage de points (par exemple, la relation entre le volume des ventes et les dépenses).
L'analyse multivariée implique l'étude de plus de deux variables pour comprendre l'effet des variables sur les réponses/résultats.
- Que sont les réseaux de neurones artificiels ?
En clair, les réseaux de neurones artificiels (ANN) font référence à un système informatique conçu d'après le cerveau humain. Tout comme le cerveau humain, les RNA sont composés de nombreux éléments de traitement simples, connus sous le nom de neurones artificiels dont la fonctionnalité est inspirée des neurones des espèces animales. Les RNA peuvent apprendre par l'expérience et peuvent s'adapter aux changements d'entrée afin que le réseau puisse générer le meilleur résultat possible sans avoir à reconcevoir les critères de sortie.
- Que sont les réseaux de neurones récurrents (RNN) ?
Un réseau neuronal récurrent (RNN) est un type de réseau neuronal artificiel dans lequel les connexions nodales aboutissent à un graphe orienté le long d'une séquence temporelle, présentant ainsi un comportement dynamique temporel. Pour comprendre RNN, vous devez d'abord comprendre le fonctionnement des réseaux à anticipation. Alors que les réseaux à anticipation canalisent les informations en ligne droite (sans toucher deux fois le même nœud), les réseaux de neurones récurrents font passer les informations par un processus en boucle. Contrairement aux réseaux de neurones à anticipation, les RNN peuvent utiliser leur mémoire interne pour traiter des séquences d'entrées. Par conséquent, les RNN sont mieux adaptés aux tâches non segmentées ou connectées, telles que la reconnaissance de l'écriture manuscrite et la reconnaissance vocale.
Top 17 des questions et réponses des entretiens avec les analystes de données
- Qu'est-ce que la rétropropagation ?
La rétropropagation fait référence à un algorithme d'apprentissage supervisé utilisé pour former des réseaux de neurones multicouches. Grâce à la rétropropagation, une erreur peut être déplacée d'une extrémité du réseau vers tous les poids à l'intérieur du réseau, permettant ainsi un calcul efficace du gradient. Il recherche la valeur minimale de la fonction d'erreur dans l'espace des poids en utilisant la technique de descente de gradient. Les poids qui minimisent la fonction d'erreur sont considérés comme la solution au problème d'apprentissage.
- La rétropropagation impliquait les étapes suivantes :
- Propagation vers l'avant des données d'entraînement.
- Calculez les dérivées en utilisant la sortie et la cible.
- Retour Propager pour calculer la dérivée de l'erreur.
- Utilisez les dérivées précédemment calculées pour la sortie.
- Calcul de la valeur de poids mise à jour et mise à jour des poids.
- Expliquer la descente de gradient.
Pour comprendre Gradient Descent, vous devez d'abord comprendre ce qu'est un dégradé. Un gradient est une mesure de combien la sortie d'une fonction particulière change par rapport à un changement mineur dans les entrées. Il mesure le changement de tous les poids en réponse à un changement d'erreur. Donc, en d'autres termes, un gradient est la pente d'une fonction.
La descente de gradient est un algorithme d'optimisation qui aide à trouver les valeurs des paramètres (coefficients) d'une fonction (f) qui minimise une fonction de coût (cost). Il convient mieux aux cas où les paramètres ne peuvent pas être calculés analytiquement.
Conclusion
Pour conclure, vous devez savoir qu'il n'y a pas de façon unique ou meilleure de se préparer à une entrevue. Tout dépend de votre base de connaissances, de votre confiance et de votre approche, et d'un peu de chance. Bien qu'il ne s'agisse que de quelques questions sur la science des données, nous espérons que cela vous donnera une idée approximative du type de questions qui peuvent vous être posées lors d'un entretien sur la science des données. Cela dit, préparez-vous bien et bonne chance pour vos efforts !
Apprenez des cours de science des données dans les meilleures universités du monde. Gagnez des programmes Executive PG, des programmes de certificat avancés ou des programmes de maîtrise pour accélérer votre carrière.
Dans un entretien de science des données, combien de tours y a-t-il ?
Une ou deux séries d'entretiens de programmation peuvent être nécessaires, mais cela dépend entièrement de l'entreprise pour laquelle vous postulez. Certaines entreprises font en sorte que le processus d'entrevue dure jusqu'à six tours. Vous pouvez préparer vos réponses pour chaque question en recherchant les questions les plus fréquemment posées, en dressant une liste des questions les plus courantes et les plus difficiles, puis en analysant ces questions avant votre entretien.
Quelles sont les qualités recherchées par les enquêteurs en science des données ?
Pour réussir un entretien en science des données, vous devez en savoir beaucoup sur l'arithmétique, les statistiques, les langages de programmation, les principes fondamentaux de l'informatique décisionnelle et, bien sûr, les techniques d'apprentissage automatique. Il vous sera très certainement demandé de démontrer comment vos capacités en matière de données sont liées aux choix et à la stratégie de l'entreprise. Dans le marché actuel, presque tous les emplois en science des données nécessitent un entretien de codage. Le rôle des scientifiques des données comprend la publication de codes de production, tels que des pipelines de données et des modèles d'apprentissage automatique, dans de nombreuses entreprises. Pour les projets de cette nature, de solides capacités de programmation sont également requises, vous pouvez donc vous attendre à des questions SQL et Python également lors de l'entretien.
Puis-je obtenir un emploi de data scientist via LinkedIn ?
Il ne faut pas négliger la puissance de LinkedIn ces jours-ci. LinkedIn est essentiellement votre CV numérique. Les entreprises et les recruteurs continuent de rechercher des candidats méritants sur LinkedIn, il est donc important pour vous de créer un profil LinkedIn impressionnant, de continuer à chercher du travail et de postuler à des offres d'emploi sur LinkedIn. Ajoutez des compétences pertinentes à votre profil et continuez à ajouter toutes vos réalisations professionnelles. De cette façon, vos chances de décrocher un emploi méritant en science des données sur LinkedIn sont élevées.