
أسئلة وأجوبة مقابلة علوم البيانات - 15 الأكثر شيوعًا
نشرت: 2019-07-08مقابلات العمل صعبة دائما. لإنجاز مقابلة بنجاح ، يجب ألا تمتلك معرفة عميقة بالموضوع فحسب ، بل يجب أن تمتلك أيضًا الثقة وحضورًا قويًا للعقل. هذا صحيح بشكل خاص إذا كنت تستعد لعلم البيانات - فهو يضع جميع كلياتك في الاختبار!
أثناء مقابلة علوم البيانات ، سيتعين عليك مواجهة مجموعة من الأسئلة التي تمتد من موضوعات متنوعة تتراوح من أسئلة علوم البيانات الأساسية إلى الإحصاء وتحليل البيانات و ML والتعلم العميق. ولكن هذا ليس كل شيء - سيتم أيضًا اختبار مهاراتك الشخصية (التواصل والعمل الجماعي وغير ذلك).
لتسهيل عملية التحضير بالنسبة لك ، قمنا برعاية قائمة تضم 15 سؤالًا من الأسئلة الأكثر شيوعًا في مقابلة علوم البيانات. سنبدأ بالأساسيات ثم ننتقل إلى الموضوعات والقضايا الأكثر تقدمًا.
لذلك ، دون مزيد من اللغط ، لنبدأ!
- ما هو علم البيانات؟ كيف يختلف التعلم الآلي الخاضع للإشراف وغير الخاضع للإشراف؟
بكلمات واضحة ، علم البيانات هو دراسة البيانات. يتضمن جمع البيانات من مصادر متباينة وتخزينها وتنظيفها وتنظيمها وتحليلها للكشف عن معلومات ذات مغزى منها. يستخدم علم البيانات مزيجًا من الرياضيات وعلوم الكمبيوتر الإحصائية والتعلم الآلي وتصور البيانات وتحليل الكتلة ونمذجة البيانات. ويهدف إلى اكتساب رؤى قيمة من البيانات الأولية (المنظمة وغير المهيكلة) واستخدام تلك الأفكار للتأثير على استراتيجيات الأعمال وتكنولوجيا المعلومات بشكل إيجابي. يمكن أن تساعد هذه الأفكار الشركات على تحسين العمليات وزيادة الإنتاجية والإيرادات وتبسيط استراتيجيات التسويق وتعزيز رضا العملاء وغير ذلك الكثير.
يختلف غسل الأموال الخاضع للإشراف وغير الخاضع للإشراف عن بعضهما البعض في النواحي التالية:
- في ML الخاضع للإشراف ، يتم تصنيف بيانات الإدخال. في ML غير الخاضع للإشراف ، تظل بيانات الإدخال غير مصنفة.
- بينما يستخدم ML الخاضع للإشراف مجموعة بيانات التدريب ، يستخدم ML غير الخاضع للإشراف مجموعة بيانات الإدخال.
- يستخدم ML الخاضع للإشراف لأغراض التنبؤ ، بينما يستخدم ML غير الخاضع للإشراف لأغراض التحليل.
- يسمح ML الخاضع للإشراف التصنيف والانحدار. ومع ذلك ، يتيح ML غير الخاضع للإشراف التصنيف وتقدير الكثافة وتقليل الأبعاد.
- Python أم R - أيهما أفضل لتحليلات النص؟
عندما يتعلق الأمر بتحليلات النص ، يبدو أن Python هو الخيار الأنسب. هذا لأنه يأتي مع مكتبة Pandas التي تتضمن هياكل بيانات سهلة الاستخدام وأدوات تحليل بيانات عالية الأداء. أيضًا ، تعد Python عالية الكفاءة وسريعة لجميع أنواع مهام تحليل النص. أما بالنسبة لـ R ، فهو الأنسب لتطبيقات التعلم الآلي.
- ما هي أنواع البيانات المدعومة في بايثون؟
تحتوي Python على مجموعة من أنواع البيانات المضمنة ، بما في ذلك:
- قيمة منطقية
- عدد (عدد صحيح ، طويل ، عائم ، مركب)
- التسلسلات (القوائم ، السلاسل ، البايت ، المجموعة الكاملة)
- مجموعات
- التعيينات (قواميس)
- كائنات الملف
- ما هي خوارزميات التصنيف المختلفة؟
خوارزميات التصنيف المحورية هي المصنفات الخطية (الانحدار اللوجستي ، مصنف بايز ساذج) ، أشجار القرار ، الأشجار المعززة ، الغابة العشوائية ، SVM ، تقدير النواة ، الشبكات العصبية ، والجيران الأقرب.
- ما هو التوزيع الطبيعي؟
عادة ، يتم توزيع البيانات بطرق مختلفة إما مع وجود انحياز إلى اليسار أو اليمين أو في حالات قليلة ، قد تصبح مختلطة. ومع ذلك ، قد تكون هناك حالات يتم فيها توزيع البيانات حول قيمة مركزية دون أي تحيز إلى اليسار أو اليمين ، وبالتالي تحقيق توزيع طبيعي في شكل منحنى على شكل جرس.
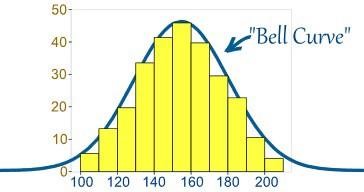
مصدر
يصور المنحنى توزيع المتغيرات العشوائية على شكل منحنى متماثل على شكل جرس.
- ما هي أهمية اختبار A / B؟
اختبار A / B هو اختبار فرضية إحصائية للتجارب العشوائية التي تتضمن متغيرين - A و B. يساعد اختبار A / B على تحديد أي تغييرات أو تعديلات يتم إجراؤها على صفحة الويب لتعظيم نتيجة الاهتمام. إنها طريقة ممتازة لتحديد أفضل استراتيجيات الترويج والتسويق عبر الإنترنت للشركات.
- ما هو الانحياز في الاختيار؟
التحيز في الاختيار هو خطأ "نشط" يحدث عندما يقرر الباحث العينات التي سيتم دراستها. في هذه الحالة ، يتم جمع بيانات العينة وإعدادها لنمذجة البيانات ، ولكنها تحمل خصائص لا تمثل الممثل الحقيقي للسكان المستقبليين للحالات التي سينظر فيها النموذج. يحدث التحيز في الاختيار عندما يتم اختيار مجموعة فرعية من بيانات العينة بشكل منهجي وتضمينها / استبعادها من تحليل البيانات. هناك ثلاثة أنواع مختلفة من تحيز التحديد:
- تحيز أخذ العينات: خطأ منهجي يحدث عندما تتسبب عينة غير عشوائية من مجموعة البيانات في أن يكون بعض أعضاء مجموعة البيانات أقل احتمالاً في الدراسة ، مما يؤدي إلى عينة متحيزة.
- الفاصل الزمني: يحدث عندما يتم إنهاء تجربة تحليل البيانات مبكرًا بقيمة قصوى. ومع ذلك ، يمكن تحقيق القيمة القصوى على الأرجح من خلال المتغير الذي يحمل التباين الأكبر (حتى لو كانت جميع المتغيرات تمتلك متوسطًا مشابهًا).
- الاستنزاف: يحدث بسبب خصم التناقص ، أو فقدان المشاركين أثناء التجربة التي تم إنهاؤها قبل الانتهاء.
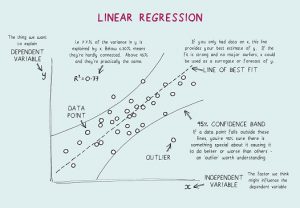
- ما هو الانحدار الخطي؟ ما هي الافتراضات المطلوبة للانحدار الخطي؟
الانحدار الخطي هو أداة إحصائية تستخدم للتحليل التنبئي. في هذه الطريقة ، يتم توقع درجة المتغير (على سبيل المثال Y) من درجة متغير آخر (على سبيل المثال X). هنا ، Y هو متغير المعيار ، بينما X هو متغير التوقع.
في الانحدار الخطي ، هناك أربعة افتراضات أساسية:
- توجد علاقة خطية بين المتغيرات التابعة وعوامل الانحدار. لذلك ، سيكون نموذج البيانات الذي تم إنشاؤه متزامنًا مع البيانات.
- بقايا البيانات مستقلة عن بعضها البعض ويتم توزيعها.
- هناك حد أدنى من العلاقة الخطية المتعددة بين المتغيرات التوضيحية.
- هناك "مثلي" مما يعني أن التباين حول خط الانحدار هو نفسه لجميع قيم متغير التوقع.
- ما هو التحقق المتبادل؟
عبر التحقق من الصحة هو إجراء التحقق من صحة النموذج المستخدمة ل. الهدف هنا هو تسمية مجموعة بيانات التحقق من الصحة لاختبار النموذج في مرحلة التدريب للحد من المشكلات مثل التجهيز الزائد وبالطبع تحديد كيفية تعميم النموذج على مجموعة بيانات مستقلة.

عبر التحقق من الصحة (CV) هو أسلوب التحقق من صحة النموذج المستخدمة لاختبار فعالية نماذج التعلم الآلي. إنها أيضًا طريقة إعادة أخذ العينات المستخدمة لتقييم نموذج في حالة البيانات المحدودة. في طريقة التحقق المتبادل ، يتم وضع جزء من البيانات جانبًا للاختبار والتحقق من الصحة ويتم استخدامه لتحديد كيفية تعميم نتائج التحليل الإحصائي على مجموعة بيانات مستقلة.
- ما هي صيغة الاحتمال ذي الحدين؟
يأخذ توزيع الاحتمالية ذات الحدين في الاعتبار احتمالات كل من الأرقام المحتملة للنجاح من عدد N من التجارب للأحداث المستقلة ، ولكل منها احتمال حدوث π (pi). صيغة التوزيع الاحتمالي ذي الحدين هي:
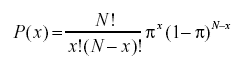
- ما هو الفرق في التحليل أحادي المتغير وثنائي المتغير ومتعدد المتغيرات؟
يشير التحليل أحادي المتغير إلى أسلوب التحليل الإحصائي الوصفي الذي يمكن تمييزه بناءً على عدد المتغيرات المعنية في وقت معين (على سبيل المثال ، المخططات الدائرية التي تصور مبيعات منتج في منطقة معينة). على عكس ذلك ، يهدف التحليل ثنائي المتغير إلى فهم وتحديد الفرق بين متغيرين في وقت واحد كما هو الحال في مخطط مبعثر (على سبيل المثال ، العلاقة بين حجم البيع والإنفاق).
يتضمن التحليل متعدد المتغيرات دراسة أكثر من متغيرين لفهم تأثير المتغيرات على الاستجابات / النتائج.
- ما هي الشبكات العصبية الاصطناعية؟
بعبارات واضحة ، تشير الشبكات العصبية الاصطناعية (ANN) إلى نظام حوسبي مصمم على غرار الدماغ البشري. تمامًا مثل الدماغ البشري ، تتكون الشبكات العصبية الاصطناعية من العديد من عناصر المعالجة البسيطة ، والمعروفة باسم الخلايا العصبية الاصطناعية التي تستلهم وظيفتها من الخلايا العصبية في الأنواع الحيوانية. يمكن لشبكات ANN التعلم من خلال التجربة ويمكنها التكيف مع المدخلات المتغيرة بحيث يمكن للشبكة تحقيق أفضل نتيجة ممكنة دون الحاجة إلى إعادة تصميم معايير الإخراج.
- ما هي الشبكات العصبية المتكررة (RNNs)؟
الشبكة العصبية المتكررة (RNN) هي نوع من الشبكات العصبية الاصطناعية التي تؤدي فيها الاتصالات العقدية إلى رسم بياني موجه على طول تسلسل زمني ، وبالتالي إظهار سلوك ديناميكي زمني. لفهم RNN ، يجب عليك أولاً فهم طريقة عمل شبكات التغذية الأمامية. بينما تقوم شبكات التغذية الأمامية بتوجيه المعلومات في خط مستقيم (دون لمس نفس العقدة مرتين) ، تقوم الشبكات العصبية المتكررة بتدوير المعلومات من خلال عملية تشبه الحلقة. على عكس الشبكات العصبية المغذية ، يمكن لشبكات RNN استخدام ذاكرتها الداخلية لمعالجة تسلسل المدخلات. ومن ثم ، فإن RNNs هي الأنسب للمهام غير المقسمة أو المتصلة ، مثل التعرف على خط اليد والتعرف على الكلام.
أعلى 17 أسئلة وأجوبة مقابلة محلل البيانات
- ما هو التكاثر العكسي؟
يشير Backpropagation إلى خوارزمية تعلم خاضعة للإشراف تُستخدم لتدريب الشبكات العصبية متعددة الطبقات. من خلال backpropagation ، يمكن نقل خطأ من نهاية الشبكة إلى جميع الأوزان داخل الشبكة ، مما يسمح بحساب التدرج اللوني بكفاءة. يبحث عن الحد الأدنى لقيمة دالة الخطأ في مساحة الوزن باستخدام تقنية النسب المتدرج. تعتبر الأوزان التي تقلل من وظيفة الخطأ حلاً لمشكلة التعلم.
- تضمنت Backpropagation الخطوات التالية:
- الانتشار الأمامي لبيانات التدريب.
- حساب المشتقات باستخدام المخرجات والهدف.
- رجوع نشر لحساب مشتق الخطأ.
- استخدم المشتقات المحسوبة مسبقًا للإخراج.
- حساب قيمة الوزن المحدث وتحديث الأوزان.
- اشرح الانحدار المتدرج.
لفهم الانحدار ، عليك أولاً أن تفهم ما هو التدرج. التدرج اللوني هو مقياس لمدى تغير ناتج وظيفة معينة فيما يتعلق بتغيير طفيف في المدخلات. يقيس التغيير في جميع الأوزان استجابة لتغير في الخطأ. بعبارة أخرى ، التدرج اللوني هو ميل الدالة.
نزول التدرج هو خوارزمية تحسين تساعد في العثور على قيم المعلمات (المعاملات) للوظيفة (و) التي تقلل دالة التكلفة (التكلفة). هو الأنسب للحالات التي لا يمكن فيها حساب المعلمات تحليليًا.
خاتمة
في ملاحظة ختامية ، يجب أن تعلم أنه لا توجد طريقة واحدة أو أفضل طريقة للتحضير للمقابلة. الأمر كله يتعلق بقاعدة معرفتك وثقتك ونهجك وقليل من الحظ. في حين أن هذه ليست سوى عدد قليل من أسئلة علوم البيانات ، فإننا نأمل أن يمنحك هذا فكرة تقريبية حول نوع الأسئلة التي يمكن طرحها في مقابلة علوم البيانات. بعد قولي هذا ، استعد جيدًا ، وكل التوفيق لمساعيك!
تعلم دورات علوم البيانات من أفضل الجامعات في العالم. اربح برامج PG التنفيذية أو برامج الشهادات المتقدمة أو برامج الماجستير لتتبع حياتك المهنية بشكل سريع.
في مقابلة علم البيانات ، كم عدد الجولات؟
قد تكون هناك حاجة إلى جولة أو جولتين من مقابلات البرمجة ، لكن هذا يعتمد كليًا على الشركة التي تقدم لها. بعض الشركات تجعل عملية المقابلة تستمر حتى ست جولات. يمكنك إعداد إجاباتك لكل سؤال من خلال البحث عن الأسئلة الأكثر شيوعًا ، وعمل قائمة بالأسئلة الأكثر شيوعًا وصعوبة ، ثم تحليل هذه الأسئلة قبل المقابلة.
ما هي الصفات التي يبحث عنها القائمون بمقابلات علوم البيانات؟
للحصول على مقابلة في علم البيانات ، ستحتاج إلى معرفة الكثير عن الحساب والإحصاء ولغات البرمجة وأساسيات ذكاء الأعمال ، وبالطبع تقنيات التعلم الآلي. سيُطلب منك بالتأكيد توضيح كيفية ارتباط قدرات البيانات الخاصة بك بخيارات الشركة واستراتيجيتها. في سوق اليوم ، تتطلب كل وظيفة في علم البيانات تقريبًا مقابلة ترميز. يشمل دور علماء البيانات إصدار كود الإنتاج ، مثل خطوط أنابيب البيانات ونماذج التعلم الآلي ، في العديد من الشركات. بالنسبة للمشاريع من هذا النوع ، فإن قدرات البرمجة القوية مطلوبة أيضًا ، لذلك يمكنك توقع بعض أسئلة SQL و Python أيضًا في المقابلة.
هل يمكنني الحصول على وظيفة عالم بيانات من خلال LinkedIn؟
لا ينبغي لأحد أن يتجاهل قوة LinkedIn هذه الأيام. LinkedIn هو أساسًا سيرتك الذاتية الرقمية. تستمر الشركات والقائمين بالتوظيف في البحث عن المرشحين المستحقين على LinkedIn ، لذلك من المهم بالنسبة لك إنشاء ملف تعريف LinkedIn مثير للإعجاب ، ومواصلة البحث عن عمل والتقدم للوظائف الشاغرة على LinkedIn. أضف المهارات ذات الصلة إلى ملفك الشخصي واستمر في إضافة جميع إنجازاتك المهنية. بهذه الطريقة ، تكون فرصك في الحصول على وظيفة تستحقها في علم البيانات من LinkedIn مرتفعة.