
Întrebări și răspunsuri la interviu Data Science – 15 cele mai frecvente
Publicat: 2019-07-08Interviurile de angajare sunt întotdeauna dificile. Pentru a obține cu succes un interviu, trebuie să aveți nu numai cunoștințe aprofundate în materie, ci și încredere și o prezență puternică de spirit. Acest lucru este valabil mai ales dacă vă pregătiți pentru o știință a datelor - vă pune la încercare toate facultățile!
În timpul unui interviu pentru știința datelor, va trebui să vă confruntați cu o serie de întrebări care se întind de la diverse subiecte, de la întrebări de bază pentru știința datelor la statistici, analiza datelor, ML și învățare profundă. Dar asta nu este tot – abilitățile tale soft (comunicare, lucru în echipă și multe altele) vor fi și ele testate.
Pentru a vă ușura procesul de pregătire, am pregătit o listă cu 15 cele mai frecvente întrebări la interviu Data Science. Vom începe cu elementele fundamentale și apoi vom trece la subiectele și problemele mai avansate.
Așa că, fără alte prelungiri, să începem!
- Ce este Data Science? Cum diferă învățarea automată supravegheată și nesupravegheată?
În cuvinte simple, Data Science este studiul datelor. Implica colectarea de date din surse disparate, stocarea lor, curățarea și organizarea lor și analizarea lor pentru a descoperi informații semnificative din acestea. Știința datelor utilizează o combinație de matematică, statistică informatică, învățare automată, vizualizare a datelor, analiză în cluster și modelare a datelor. Acesta își propune să obțină informații valoroase din datele brute (atât structurate, cât și nestructurate) și să utilizeze aceste informații pentru a influența în mod pozitiv strategiile de afaceri și IT. Astfel de idei pot ajuta companiile să optimizeze procesele, să sporească productivitatea și veniturile, să eficientizeze strategiile de marketing, să sporească satisfacția clienților și multe altele.
ML supravegheat și nesupravegheat diferă unul de celălalt în următoarele aspecte:
- În ML supravegheat, datele de intrare sunt etichetate. În ML nesupravegheat, datele de intrare rămân neetichetate.
- În timp ce ML supravegheat folosește setul de date de antrenament, ML nesupravegheat folosește setul de date de intrare.
- ML supravegheat este utilizat în scopuri de predicție, în timp ce ML nesupravegheat este utilizat în scopuri de analiză.
- ML supravegheat permite clasificarea și regresia. Cu toate acestea, ML nesupravegheat permite clasificarea, estimarea densității și reducerea dimensiunilor.
- Python sau R – Care este mai bine pentru analiza textului?
Când vine vorba de analiza textului, Python pare a fi cea mai potrivită opțiune. Acest lucru se datorează faptului că vine cu biblioteca Pandas care include structuri de date ușor de utilizat și instrumente de analiză a datelor de înaltă performanță. De asemenea, Python este extrem de eficient și rapid pentru toate tipurile de sarcini de analiză a textului. În ceea ce privește R, este cel mai potrivit pentru aplicațiile Machine Learning.
- Care sunt tipurile de date acceptate în Python?
Python are o serie de tipuri de date încorporate, inclusiv:
- boolean
- Numeric (întregi, lung, flotant, complex)
- Secvențe (liste, șiruri de caractere, octeți, tuplu)
- seturi
- Mapări (dicționare)
- Fișier obiecte
- Care sunt diferiții algoritmi de clasificare?
Algoritmii pivotali de clasificare sunt clasificatori liniari (regresie logistică, clasificator Naive Bayes), arbori de decizie, arbori amplificați, pădure aleatoare, SVM, estimare a nucleului, rețele neuronale și cel mai apropiat vecin.
- Ce este distribuția normală?
De obicei, datele sunt distribuite în diferite moduri, fie cu o părtinire spre stânga sau spre dreapta sau, în câteva circumstanțe, pot deveni confundate. Cu toate acestea, ar putea exista cazuri în care datele sunt distribuite în jurul unei valori centrale fără nicio prejudecată spre stânga sau spre dreapta, obținând astfel o distribuție normală sub forma unei curbe în formă de clopot.
Sursă
Curba descrie distribuția variabilelor aleatoare sub forma unei curbe simetrice în formă de clopot.
- Care este importanța testării A/B?
Testarea A/B este o testare a ipotezelor statistice pentru experimentarea aleatorie care implică două variabile – A și B. Testarea A/B ajută la identificarea oricăror modificări sau modificări aduse paginii web pentru a maximiza rezultatul de interes. Este o metodă excelentă de a determina cele mai bune strategii de promovare și marketing online pentru afaceri.
- Ce este prejudecata de selecție?
Selection Bias este o eroare „activă” care apare atunci când cercetătorul decide probele care urmează să fie studiate. În acest caz, eșantionul de date este colectat și pregătit pentru modelarea datelor, dar prezintă astfel de caracteristici care nu sunt adevăratul reprezentant al populației viitoare de cazuri pe care modelul le va lua în considerare. Deviația de selecție are loc atunci când un subset al datelor eșantionului este ales sistematic și inclus/exclus din analiza datelor. Există trei tipuri diferite de prejudecăți de selecție:
- Prejudecata de eșantionare: O eroare sistematică care apare atunci când un eșantion nealeatoriu dintr-un set de date face ca unii membri ai setului de date să fie mai puțin probabil incluși în studiu, conducând astfel la un eșantion părtinitor.
- Interval de timp: apare atunci când un proces de analiză a datelor este încheiat devreme la o valoare extremă. Cu toate acestea, valoarea extremă poate fi atinsă mai probabil de variabila care poartă cea mai mare varianță (chiar dacă toate variabilele posedă o medie similară).
- Uzura: apare din cauza reducerii prin uzură sau a pierderii participanților în timpul unui proces care a fost încheiat înainte de finalizare.
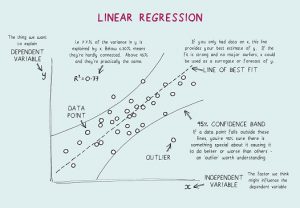
- Ce este o regresie liniară? Care sunt ipotezele necesare pentru regresia liniară?
Regresia liniară este un instrument statistic utilizat pentru analiza predictivă. În această metodă, scorul unei variabile (să spunem Y) este prezis din scorul unei alte variabile (să spunem X). Aici, Y este variabila criteriu, în timp ce X este variabila predictor.
În regresia liniară, există patru ipoteze fundamentale:
- Există o relație liniară între variabilele dependente și regresori. Deci, modelul de date creat va fi sincronizat cu datele.
- Reziduurile datelor sunt independente unele de altele și trebuie distribuite.
- Există o multi-coliniaritate minimă între variabilele explicative.
- Există „homoscedasticitate”, ceea ce înseamnă că varianța în jurul liniei de regresie este aceeași pentru toate valorile variabilei predictoare.
- Ce este validarea încrucișată?
Validarea încrucișată este o procedură de validare a modelului utilizată pentru. Scopul aici este de a numi setul de date de validare pentru a testa modelul în faza de antrenament pentru a limita probleme precum supraajustarea și, desigur, pentru a determina modul în care modelul se va generaliza la un set de date independent.
Validarea încrucișată (CV) este o tehnică de validare a modelului folosită pentru a testa eficacitatea modelelor de învățare automată. Este, de asemenea, o metodă de reeșantionare utilizată pentru a evalua un model în cazul unor date limitate. În metoda de validare încrucișată, o parte a datelor este pusă deoparte pentru testare și validare și este utilizată pentru a determina modul în care rezultatele analizei statistice se vor generaliza la un set de date independent.

- Care este formula probabilității binomiale?
Distribuția de probabilitate binomială ia în considerare probabilitățile fiecăruia dintre numărul posibil de succese din N număr de încercări pentru evenimente independente, fiecare având probabilitatea de apariție a lui π (pi). Formula pentru o distribuție de probabilitate binomială este:
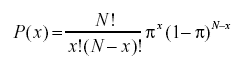
- Care este diferența Analiza univariată, bivariată și multivariată?
Analiza univariată se referă la tehnica de analiză statistică descriptivă care poate fi diferențiată în funcție de numărul de variabile implicate la un anumit moment de timp (de exemplu, diagrame circulare care prezintă vânzările unui produs într-un anumit teritoriu). Spre deosebire de aceasta, analiza bivariată își propune să înțeleagă și să determine diferența dintre două variabile la un moment dat, ca într-un scatterplot (de exemplu, relația dintre volumul vânzărilor și cheltuieli).
Analiza multivariată implică studiul a mai mult de două variabile pentru a înțelege efectul variabilelor asupra răspunsurilor/rezultatelor.
- Ce sunt rețelele neuronale artificiale?
În termeni simpli, rețelele neuronale artificiale (ANN) se referă la un sistem de calcul proiectat după creierul uman. La fel ca și creierul uman, ANN-urile sunt compuse din numeroase elemente simple de procesare, cunoscute sub numele de neuroni artificiali a căror funcționalitate este inspirată de neuronii din speciile de animale. ANN-urile pot învăța prin experiență și se pot adapta la intrarea în schimbare, astfel încât rețeaua să poată genera cel mai bun rezultat posibil fără a fi nevoie să reproiecteze criteriile de ieșire.
- Ce sunt rețelele neuronale recurente (RNN)?
O rețea neuronală recurentă (RNN) este un tip de rețea neuronală artificială în care conexiunile nodale au ca rezultat un grafic direcționat de-a lungul unei secvențe temporale, prezentând astfel un comportament dinamic temporal. Pentru a înțelege RNN, trebuie mai întâi să înțelegeți funcționarea rețelelor feedforward. În timp ce rețelele feedforward canalizează informațiile într-o linie dreaptă (fără a atinge același nod de două ori), rețelele neuronale recurente circulă informațiile printr-un proces asemănător buclei. Spre deosebire de rețelele neuronale feedforward, RNN-urile își pot folosi memoria internă pentru a procesa secvențe de intrări. Prin urmare, RNN-urile sunt cele mai potrivite pentru sarcini care sunt nesegmentate sau conectate, cum ar fi recunoașterea scrisului de mână și recunoașterea vorbirii.
Top 17 întrebări și răspunsuri la interviu cu analist de date
- Ce este propagarea înapoi?
Backpropagarea se referă la un algoritm de învățare supravegheat care este utilizat pentru antrenarea rețelelor neuronale multistrat. Prin retropropagare, o eroare poate fi mutată de la un capăt al rețelei la toate greutățile din interiorul rețelei, permițând astfel calcularea eficientă a gradientului. Acesta caută valoarea minimă a funcției de eroare în spațiul greutate folosind tehnica de coborâre a gradientului. Greutățile care minimizează funcția de eroare sunt considerate ca soluție la problema de învățare.
- Propagarea inversă a implicat următorii pași:
- Propagarea înainte a datelor de antrenament.
- Calculați derivate folosind output și target.
- Înapoi Propagați pentru calcularea derivatei erorii.
- Utilizați derivate calculate anterior pentru producție.
- Calcularea valorii actualizate a greutății și actualizarea greutăților.
- Explicați Coborârea Gradientului.
Pentru a înțelege Gradient Descent, trebuie mai întâi să înțelegeți ce este un gradient. Un gradient este o măsură a cât de mult se modifică ieșirea unei anumite funcții în raport cu o modificare minoră a intrărilor. Măsoară modificarea tuturor ponderilor ca răspuns la o modificare a erorii. Deci, cu alte cuvinte, un gradient este panta unei funcții.
Coborârea gradientului este un algoritm de optimizare care ajută la găsirea valorilor parametrilor (coeficienților) unei funcții (f) care minimizează o funcție de cost (cost). Este cel mai potrivit pentru cazurile în care parametrii nu pot fi calculați analitic.
Concluzie
În concluzie, trebuie să știți că nu există o modalitate unică sau cea mai bună de a vă pregăti pentru un interviu. Totul este despre baza ta de cunoștințe, încredere și abordare și puțin noroc. Deși acestea sunt doar câteva întrebări despre Data Science, sperăm că acest lucru vă va oferi o idee aproximativă despre tipul de întrebări care vi se pot pune într-un interviu Data Science. Acestea fiind spuse, pregătiți-vă bine și toate cele bune pentru eforturile voastre!
Învață cursuri de știință a datelor de la cele mai bune universități din lume. Câștigă programe Executive PG, programe avansate de certificat sau programe de master pentru a-ți accelera cariera.
Într-un interviu pentru știința datelor, câte runde sunt?
Pot fi necesare una sau două runde de interviuri de programare, dar acest lucru depinde în întregime de compania pentru care aplicați. Unele firme fac ca procesul de interviu să dureze până la șase runde. Vă puteți pregăti răspunsurile pentru fiecare întrebare cercetând cele mai frecvente întrebări, făcând o listă cu cele mai comune și dificile întrebări și apoi analizând acele întrebări înainte de interviu.
Care sunt calitățile pe care le caută intervievatorii din știința datelor?
Pentru a obține un interviu în domeniul științei datelor, va trebui să știți multe despre aritmetică, statistică, limbaje de programare, elementele fundamentale ale inteligenței de afaceri și, desigur, tehnici de învățare automată. Cu siguranță vi se va cere să demonstrați modul în care abilitățile dvs. de date sunt legate de alegerile și strategia companiei. Pe piața actuală, aproape fiecare job de știință a datelor necesită un interviu de codificare. Rolul oamenilor de știință a datelor include eliberarea de coduri de producție, cum ar fi conductele de date și modelele de învățare automată, la multe firme. Pentru proiecte de această natură, sunt necesare și abilități puternice de programare, așa că vă puteți aștepta și la câteva întrebări SQL și Python în interviu.
Pot obține un loc de muncă de data scientist prin LinkedIn?
Nu trebuie să trecem cu vederea puterea LinkedIn în aceste zile. LinkedIn este practic CV-ul tău digital. Companiile și recrutorii continuă să caute candidați merituoși pe LinkedIn, așa că este important pentru tine să-ți construiești un profil LinkedIn impresionant, să continui să cauți de lucru și să aplici pentru locuri de muncă disponibile pe LinkedIn. Adaugă abilități relevante profilului tău și continuă să adaugi toate realizările tale profesionale. În acest fel, șansele tale de a obține un job demn de știință a datelor de la LinkedIn sunt mari.