
Data Science Interview Вопросы и ответы — 15 наиболее часто задаваемых вопросов
Опубликовано: 2019-07-08Собеседования при приеме на работу всегда сложны. Чтобы успешно пройти собеседование, вы должны обладать не только глубоким знанием предмета, но также уверенностью и сильным присутствием духа. Это особенно верно, если вы готовитесь к науке о данных — она проверяет все ваши способности!
Во время интервью по науке о данных вам придется ответить на множество вопросов, охватывающих самые разные темы, от базовых вопросов по науке о данных до статистики, анализа данных, машинного обучения и глубокого обучения. Но это еще не все — ваши социальные навыки (общение, работа в команде и т. д.) также будут проверены.
Чтобы облегчить вам процесс подготовки, мы составили список из 15 наиболее часто задаваемых вопросов на собеседованиях по науке о данных. Мы начнем с основ, а затем перейдем к более сложным темам и проблемам.
Итак, без лишних слов, приступим!
- Что такое наука о данных? Чем отличаются контролируемое и неконтролируемое машинное обучение?
Проще говоря, наука о данных — это изучение данных. Он включает в себя сбор данных из разрозненных источников, их хранение, очистку и организацию, а также их анализ для извлечения из них значимой информации. Наука о данных использует комбинацию математики, статистической информатики, машинного обучения, визуализации данных, кластерного анализа и моделирования данных. Он направлен на получение ценной информации из необработанных данных (как структурированных, так и неструктурированных) и использования этой информации для положительного влияния на бизнес и ИТ-стратегии. Такие идеи могут помочь предприятиям оптимизировать процессы, повысить производительность и доход, оптимизировать маркетинговые стратегии, повысить удовлетворенность клиентов и многое другое.
Контролируемое и неконтролируемое ОД отличаются друг от друга в следующих отношениях:
- В контролируемом ML входные данные помечены. В неконтролируемом ML входные данные остаются немаркированными.
- В то время как контролируемое ML использует обучающий набор данных, неконтролируемое ML использует набор входных данных.
- Контролируемое ML используется для целей прогнозирования, тогда как неконтролируемое ML используется для целей анализа.
- Контролируемое машинное обучение позволяет проводить классификацию и регрессию. Однако неконтролируемое машинное обучение позволяет классифицировать, оценивать плотность и уменьшать размеры.
- Python или R — что лучше для текстовой аналитики?
Когда дело доходит до текстовой аналитики, Python кажется наиболее подходящим вариантом. Это связано с тем, что он поставляется с библиотекой Pandas, которая включает в себя удобные для пользователя структуры данных и высокопроизводительные инструменты анализа данных. Кроме того, Python очень эффективен и быстр для всех видов задач текстовой аналитики. Что касается R, то он лучше всего подходит для приложений машинного обучения.
- Какие типы данных поддерживаются в Python?
Python имеет множество встроенных типов данных, в том числе:
- логический
- Числовые (целые, длинные, с плавающей запятой, комплексные)
- Последовательности (списки, строки, байты, кортежи)
- Наборы
- Отображения (словари)
- Файловые объекты
- Какие существуют алгоритмы классификации?
Алгоритмы основной классификации — это линейные классификаторы (логистическая регрессия, наивный байесовский классификатор), деревья решений, усиленные деревья, случайный лес, SVM, оценка ядра, нейронные сети и ближайший сосед.
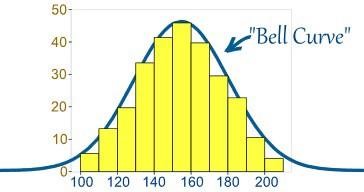
- Что такое нормальное распределение?
Обычно данные распределяются по-разному: либо с уклоном влево, либо вправо, либо в некоторых случаях они могут быть перемешаны. Однако могут быть случаи, когда данные распределяются вокруг центрального значения без какого-либо смещения влево или вправо, благодаря чему достигается нормальное распределение в виде колоколообразной кривой.
Источник
Кривая изображает распределение случайных величин в виде симметричной колоколообразной кривой.
- В чем важность A/B-тестирования?
A/B-тестирование — это проверка статистической гипотезы для случайных экспериментов с двумя переменными — A и B. A/B-тестирование помогает выявить любые изменения или изменения, внесенные в веб-страницу, чтобы максимизировать интересующий результат. Это отличный способ определить лучшие онлайн-рекламные и маркетинговые стратегии для бизнеса.
- Что такое предвзятость выбора?
Смещение выбора — это «активная» ошибка, возникающая, когда исследователь выбирает образцы для изучения. В этом случае данные выборки собираются и подготавливаются для моделирования данных, но они обладают такими характеристиками, которые не являются истинным представителем будущей совокупности случаев, которые будет рассматривать модель. Систематическая ошибка отбора имеет место, когда подмножество выборочных данных систематически выбирается и включается/исключается из анализа данных. Существует три различных типа смещения выбора:
- Смещение выборки: Систематическая ошибка, возникающая, когда неслучайная выборка набора данных приводит к тому, что некоторые члены набора данных менее вероятно будут включены в исследование, что приводит к смещенной выборке.
- Временной интервал: это происходит, когда испытание по анализу данных прекращается досрочно при экстремальном значении. Однако экстремальное значение с большей вероятностью может быть достигнуто переменной с наибольшей дисперсией (даже если все переменные имеют одинаковое среднее значение).
- Истощение: это происходит из-за дисконтирования истощения или потери участников во время испытания, которое было прекращено до завершения.
- Что такое линейная регрессия? Какие допущения необходимы для линейной регрессии?
Линейная регрессия — это статистический инструмент, используемый для прогнозного анализа. В этом методе оценка переменной (скажем, Y) прогнозируется на основе оценки другой переменной (скажем, X). Здесь Y — переменная критерия, тогда как X — переменная-предиктор.
В линейной регрессии есть четыре основных предположения:
- Между зависимыми переменными и регрессорами существует линейная связь. Таким образом, созданная модель данных будет синхронизирована с данными.
- Остатки данных не зависят друг от друга и подлежат распределению.
- Существует минимальная мультиколлинеарность между независимыми переменными.
- Существует «гомоскедастичность», которая означает, что дисперсия вокруг линии регрессии одинакова для всех значений переменной-предиктора.
- Что такое перекрестная проверка?
Перекрестная проверка — это процедура проверки модели, используемая для. Цель здесь состоит в том, чтобы назвать набор проверочных данных для тестирования модели на этапе обучения, чтобы ограничить такие проблемы, как переоснащение, и, конечно же, определить, как модель будет обобщаться на независимый набор данных.

Перекрестная проверка (CV) — это метод проверки модели, используемый для проверки эффективности моделей машинного обучения. Это также метод повторной выборки, используемый для оценки модели в случае ограниченных данных. В методе перекрестной проверки часть данных отводится для тестирования и проверки и используется для определения того, как результаты статистического анализа будут обобщены на независимый набор данных.
- Что такое биномиальная формула вероятности?
Биномиальное распределение вероятностей учитывает вероятности каждого из возможных чисел успехов из числа N испытаний для независимых событий, каждое из которых имеет вероятность возникновения π (pi). Формула биномиального распределения вероятностей:
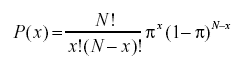
- В чем разница одномерного, двумерного и многомерного анализа?
Однофакторный анализ относится к методу описательного статистического анализа, который можно дифференцировать на основе количества переменных, задействованных в конкретный момент времени (например, круговые диаграммы, отображающие продажи продукта на определенной территории). В отличие от этого, двумерный анализ направлен на понимание и определение разницы между двумя переменными одновременно, как на диаграмме рассеяния (например, взаимосвязь между объемом продаж и расходами).
Многомерный анализ включает изучение более чем двух переменных, чтобы понять влияние переменных на ответы/результаты.
- Что такое искусственные нейронные сети?
Проще говоря, искусственные нейронные сети (ИНС) относятся к вычислительной системе, разработанной по образцу человеческого мозга. Как и человеческий мозг, ИНС состоят из множества простых обрабатывающих элементов, известных как искусственные нейроны, чья функциональность вдохновлена нейронами животных. ИНС могут учиться на опыте и могут адаптироваться к изменяющимся входным данным, чтобы сеть могла генерировать наилучший возможный результат без необходимости перепроектировать выходные критерии.
- Что такое рекуррентные нейронные сети (RNN)?
Рекуррентная нейронная сеть (RNN) — это тип искусственной нейронной сети, в которой узловые соединения приводят к ориентированному графу вдоль временной последовательности, тем самым демонстрируя временное динамическое поведение. Чтобы понять RNN, вы должны сначала понять, как работают сети прямого распространения. В то время как сети с прямой связью передают информацию по прямой линии (не касаясь дважды одного и того же узла), рекуррентные нейронные сети циклически передают информацию через петлевой процесс. В отличие от нейронных сетей с прямой связью, RNN могут использовать свою внутреннюю память для обработки последовательностей входных данных. Следовательно, RNN лучше всего подходят для несегментированных или связанных задач, таких как распознавание рукописного ввода и распознавание речи.
17 главных вопросов и ответов на интервью с аналитиком данных
- Что такое обратное распространение?
Обратное распространение относится к алгоритму обучения с учителем, который используется для обучения многослойных нейронных сетей. Благодаря обратному распространению ошибка может быть перемещена с конца сети на все веса внутри сети, что позволяет эффективно вычислять градиент. Он ищет минимальное значение функции ошибки в весовом пространстве, используя метод градиентного спуска. Веса, минимизирующие функцию ошибок, рассматриваются как решение задачи обучения.
- Обратное распространение включало следующие шаги:
- Прямое распространение обучающих данных.
- Вычислите производные, используя выходные данные и цель.
- Back Propagate для вычисления производной ошибки.
- Используйте ранее рассчитанные производные для вывода.
- Расчет обновленного значения веса и обновление весов.
- Объясните градиентный спуск.
Чтобы понять градиентный спуск, вы должны сначала понять, что такое градиент. Градиент — это мера того, насколько выходные данные конкретной функции изменяются по отношению к незначительным изменениям входных данных. Он измеряет изменение всех весов в ответ на изменение ошибки. Другими словами, градиент — это наклон функции.
Градиентный спуск — алгоритм оптимизации, помогающий найти значения параметров (коэффициентов) функции (f), минимизирующей функцию стоимости (стоимость). Он лучше всего подходит для случаев, когда параметры не могут быть рассчитаны аналитически.
Заключение
В заключение вы должны знать, что не существует единственного и лучшего способа подготовиться к собеседованию. Все зависит от вашей базы знаний, вашей уверенности и подхода, и немного удачи. Хотя это всего лишь несколько вопросов по науке о данных, мы надеемся, что они дадут вам общее представление о том, какие вопросы вам могут задавать на собеседовании по науке о данных. Тем не менее, готовьтесь хорошо, и всего наилучшего в ваших начинаниях!
Изучите курсы по науке о данных в лучших университетах мира. Участвуйте в программах Executive PG, Advanced Certificate Programs или Master Programs, чтобы ускорить свою карьеру.
Сколько раундов в интервью по науке о данных?
Может потребоваться один или два раунда собеседований по программированию, но это полностью зависит от компании, в которую вы подаете заявку. В некоторых фирмах собеседование длится до шести раундов. Вы можете подготовить свои ответы на каждый вопрос, изучив наиболее часто задаваемые вопросы, составив список наиболее распространенных и сложных вопросов, а затем проанализировав эти вопросы перед собеседованием.
На какие качества обращают внимание интервьюеры по науке о данных?
Чтобы пройти собеседование по науке о данных, вам нужно много знать об арифметике, статистике, языках программирования, основах бизнес-аналитики и, конечно же, о методах машинного обучения. Вас наверняка попросят продемонстрировать, как ваши возможности работы с данными связаны с выбором и стратегией компании. На современном рынке почти каждая работа в области науки о данных требует собеседования по программированию. Роль специалистов по данным включает выпуск производственного кода, такого как конвейеры данных и модели машинного обучения, во многих фирмах. Для проектов такого рода также требуются сильные навыки программирования, поэтому вы также можете ожидать некоторые вопросы по SQL и Python на собеседовании.
Могу ли я получить работу специалиста по данным через LinkedIn?
В наши дни нельзя недооценивать силу LinkedIn. LinkedIn — это, по сути, ваше цифровое резюме. Компании и рекрутеры продолжают искать достойных кандидатов в LinkedIn, поэтому для вас важно создать впечатляющий профиль LinkedIn, продолжать искать работу и подавать заявки на вакансии в LinkedIn. Добавьте соответствующие навыки в свой профиль и продолжайте добавлять все свои профессиональные достижения. Таким образом, ваши шансы получить достойную работу по науке о данных в LinkedIn высоки.