
Preguntas y respuestas de entrevistas de ciencia de datos: las 15 preguntas más frecuentes
Publicado: 2019-07-08Las entrevistas de trabajo siempre son complicadas. Para descifrar con éxito una entrevista, debe poseer no solo un conocimiento profundo del tema, sino también confianza y una fuerte presencia de ánimo. Esto es especialmente cierto si se está preparando para una ciencia de datos: ¡pone a prueba todas sus facultades!
Durante una entrevista de ciencia de datos, tendrá que enfrentarse a una serie de preguntas que abarcan diversos temas que van desde preguntas básicas de ciencia de datos hasta estadísticas, análisis de datos, aprendizaje automático y aprendizaje profundo. Pero eso no es todo: también se pondrán a prueba sus habilidades blandas (comunicación, trabajo en equipo y más).
Para facilitarle el proceso de preparación, hemos seleccionado una lista de las 15 preguntas más frecuentes de las entrevistas de ciencia de datos. Comenzaremos con los fundamentos y luego pasaremos a los temas y problemas más avanzados.
Así que, sin más preámbulos, ¡comencemos!
- ¿Qué es la ciencia de datos? ¿En qué se diferencian el aprendizaje automático supervisado y no supervisado?
En palabras simples, Data Science es el estudio de los datos. Implica la recopilación de datos de fuentes dispares, almacenarlos, limpiarlos y organizarlos, y analizarlos para descubrir información significativa a partir de ellos. La ciencia de datos utiliza una combinación de matemáticas, informática estadística, aprendizaje automático, visualización de datos, análisis de conglomerados y modelado de datos. Su objetivo es obtener información valiosa a partir de datos sin procesar (tanto estructurados como no estructurados) y utilizar esa información para influir positivamente en las estrategias comerciales y de TI. Estas ideas pueden ayudar a las empresas a optimizar los procesos, aumentar la productividad y los ingresos, optimizar las estrategias de marketing, mejorar la satisfacción del cliente y mucho más.
El LA supervisado y no supervisado se diferencian entre sí en los siguientes aspectos:
- En el aprendizaje automático supervisado, los datos de entrada están etiquetados. En ML no supervisado, los datos de entrada permanecen sin etiquetar.
- Mientras que ML supervisado usa un conjunto de datos de entrenamiento, ML no supervisado usa el conjunto de datos de entrada.
- El ML supervisado se usa con fines de predicción, mientras que el ML no supervisado se usa con fines de análisis.
- El aprendizaje automático supervisado permite la clasificación y la regresión. Sin embargo, el aprendizaje automático no supervisado permite la clasificación, la estimación de densidad y la reducción de dimensiones.
- Python o R: ¿cuál es mejor para el análisis de texto?
Cuando se trata de análisis de texto, Python parece ser la opción más adecuada. Esto se debe a que viene con la biblioteca Pandas que incluye estructuras de datos fáciles de usar y herramientas de análisis de datos de alto rendimiento. Además, Python es muy eficiente y rápido para todo tipo de tareas de análisis de texto. En cuanto a R, es más adecuado para aplicaciones de aprendizaje automático.
- ¿Cuáles son los tipos de datos admitidos en Python?
Python tiene una variedad de tipos de datos incorporados, que incluyen:
- booleano
- Numérico (enteros, largo, flotante, complejo)
- Secuencias (Listas, Cadenas, Byte, Tupla)
- Conjuntos
- Asignaciones (Diccionarios)
- Objetos de archivo
- ¿Cuáles son los diferentes algoritmos de clasificación?
Los algoritmos de clasificación fundamentales son clasificadores lineales (regresión logística, clasificador Naive Bayes), árboles de decisión, árboles potenciados, bosque aleatorio, SVM, estimación del núcleo, redes neuronales y vecino más cercano.
- ¿Qué es la distribución normal?
Por lo general, los datos se distribuyen de varias maneras, ya sea con un sesgo hacia la izquierda o hacia la derecha o, en algunas circunstancias, pueden mezclarse. Sin embargo, puede haber casos en los que los datos se distribuyan alrededor de un valor central sin ningún sesgo hacia la izquierda o hacia la derecha, logrando así una distribución normal en forma de curva en forma de campana.
Fuente
La curva representa la distribución de variables aleatorias en forma de una curva simétrica en forma de campana.
- ¿Cuál es la importancia de las pruebas A/B?
La prueba A/B es una prueba de hipótesis estadística para la experimentación aleatoria que involucra dos variables: A y B. La prueba A/B ayuda a identificar cualquier cambio o alteración realizada en la página web para maximizar el resultado de interés. Es un método excelente para determinar las mejores estrategias de promoción y marketing en línea para las empresas.
- ¿Qué es el sesgo de selección?
El sesgo de selección es un error 'activo' que ocurre cuando el investigador decide las muestras que se van a estudiar. En este caso, los datos de la muestra se recopilan y preparan para el modelado de datos, pero tienen características tales que no son el verdadero representante de la futura población de casos que considerará el modelo. El sesgo de selección se produce cuando un subconjunto de los datos de la muestra se elige sistemáticamente y se incluye/excluye del análisis de datos. Hay tres tipos diferentes de sesgo de selección:
- Sesgo de muestreo: un error sistemático que ocurre cuando una muestra no aleatoria de un conjunto de datos hace que sea menos probable que algunos miembros del conjunto de datos se incluyan en el estudio, lo que conduce a una muestra sesgada.
- Intervalo de tiempo: Ocurre cuando una prueba de análisis de datos se termina antes de tiempo en un valor extremo. Sin embargo, es más probable que la variable que tenga la varianza más grande alcance el valor extremo (incluso si todas las variables poseen una media similar).
- Deserción: Ocurre debido al descuento por deserción, o la pérdida de participantes durante una prueba que finalizó antes de su finalización.
- ¿Qué es una regresión lineal? ¿Cuáles son los supuestos necesarios para la regresión lineal?
La regresión lineal es una herramienta estadística utilizada para el análisis predictivo. En este método, la puntuación de una variable (por ejemplo, Y) se predice a partir de la puntuación de otra variable (por ejemplo, X). Aquí, Y es la variable criterio, mientras que X es la variable predictora.
En la regresión lineal, hay cuatro supuestos fundamentales:
- Existe una relación lineal entre las variables dependientes y los regresores. Entonces, el modelo de datos creado estará sincronizado con los datos.
- Los residuos de los datos son independientes entre sí y deben distribuirse.
- Existe una multicolinealidad mínima entre las variables explicativas.
- Hay 'homocedasticidad', lo que significa que la varianza alrededor de la línea de regresión es la misma para todos los valores de la variable predictora.
- ¿Qué es la validación cruzada?
La validación cruzada es un procedimiento de validación de modelos utilizado para. El objetivo aquí es denominar el conjunto de datos de validación para probar el modelo en la fase de entrenamiento para limitar problemas como el sobreajuste y, por supuesto, determinar cómo se generalizará el modelo a un conjunto de datos independiente.
La validación cruzada (CV) es una técnica de validación de modelos empleada para probar la efectividad de los modelos de aprendizaje automático. También es un método de remuestreo utilizado para evaluar un modelo en caso de datos limitados. En el método de validación cruzada, una parte de los datos se reserva para pruebas y validación y se utiliza para determinar cómo se generalizarán los resultados del análisis estadístico a un conjunto de datos independiente.

- ¿Qué es la fórmula de probabilidad binomial?
La distribución de probabilidad binomial toma en consideración las probabilidades de cada uno de los posibles números de éxitos de N número de intentos para eventos independientes, cada uno con la probabilidad de ocurrencia de π (pi). La fórmula para una distribución de probabilidad binomial es:
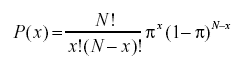
- ¿Cuál es la diferencia entre el análisis univariado, bivariado y multivariado?
El análisis univariante se refiere a la técnica de análisis estadístico descriptivo que se puede diferenciar según la cantidad de variables involucradas en un momento determinado (por ejemplo, gráficos circulares que representan las ventas de un producto en un territorio específico). Contrariamente a esto, el análisis bivariado tiene como objetivo comprender y determinar la diferencia entre dos variables a la vez como en un diagrama de dispersión (por ejemplo, la relación entre el volumen de ventas y el gasto).
El análisis multivariante implica el estudio de más de dos variables para comprender el efecto de las variables en las respuestas/resultados.
- ¿Qué son las Redes Neuronales Artificiales?
En términos sencillos, las redes neuronales artificiales (ANN) se refieren a un sistema informático diseñado a partir del cerebro humano. Al igual que el cerebro humano, las ANN están compuestas por numerosos elementos de procesamiento simples, conocidos como neuronas artificiales, cuya funcionalidad está inspirada en las neuronas de las especies animales. Las ANN pueden aprender a través de la experiencia y pueden adaptarse a la entrada cambiante para que la red pueda generar el mejor resultado posible sin tener que rediseñar los criterios de salida.
- ¿Qué son las redes neuronales recurrentes (RNN)?
Una red neuronal recurrente (RNN) es un tipo de red neuronal artificial en la que las conexiones nodales dan como resultado un gráfico dirigido a lo largo de una secuencia temporal, exhibiendo así un comportamiento dinámico temporal. Para comprender RNN, primero debe comprender el funcionamiento de las redes feedforward. Mientras que las redes feedforward canalizan la información en línea recta (sin tocar el mismo nodo dos veces), las redes neuronales recurrentes ciclan la información a través de un proceso similar a un bucle. A diferencia de las redes neuronales feedforward, las RNN pueden usar su memoria interna para procesar secuencias de entradas. Por lo tanto, los RNN son más adecuados para tareas no segmentadas o conectadas, como el reconocimiento de escritura a mano y el reconocimiento de voz.
Las 17 preguntas y respuestas principales de la entrevista del analista de datos
- ¿Qué es la retropropagación?
Backpropagation se refiere a un algoritmo de aprendizaje supervisado que se utiliza para entrenar redes neuronales multicapa. A través de la retropropagación, un error se puede mover desde un extremo de la red a todos los pesos dentro de la red, lo que permite un cálculo eficiente del gradiente. Busca el valor mínimo de la función de error en peso-espacio utilizando la técnica de descenso de gradiente. Los pesos que minimizan la función de error se consideran la solución al problema de aprendizaje.
- La retropropagación implicó los siguientes pasos:
- Propagación directa de datos de entrenamiento.
- Calcular derivados utilizando la salida y el objetivo.
- Atrás Propagar para calcular la derivada del error.
- Utilice derivadas previamente calculadas para la salida.
- Cálculo del valor de peso actualizado y actualización de los pesos.
- Explicar el descenso de gradiente.
Para comprender el descenso de gradiente, primero debe comprender qué es un gradiente. Un gradiente es una medida de cuánto cambia la salida de una función particular en relación con un cambio menor en las entradas. Mide el cambio en todos los pesos en respuesta a un cambio en el error. Entonces, en otras palabras, un gradiente es la pendiente de una función.
El descenso de gradiente es un algoritmo de optimización que ayuda a encontrar los valores de los parámetros (coeficientes) de una función (f) que minimiza una función de costo (costo). Es más adecuado para casos en los que los parámetros no se pueden calcular analíticamente.
Conclusión
En una nota final, debe saber que no existe una forma única o mejor de prepararse para una entrevista. Se trata de su base de conocimientos, su confianza y enfoque, y un poco de suerte. Si bien estas son solo algunas preguntas de ciencia de datos, esperamos que esto le dé una idea aproximada sobre el tipo de preguntas que se le pueden hacer en una entrevista de ciencia de datos. Dicho esto, ¡prepárate bien y todo lo mejor para tus esfuerzos!
Aprenda cursos de ciencia de datos de las mejores universidades del mundo. Obtenga programas Executive PG, programas de certificados avanzados o programas de maestría para acelerar su carrera.
En una entrevista de ciencia de datos, ¿cuántas rondas hay?
Es posible que se requieran una o dos rondas de entrevistas de programación, pero esto depende completamente de la empresa para la que se postule. Algunas empresas hacen que el proceso de entrevista dure hasta seis rondas. Puede preparar sus respuestas para cada pregunta investigando las preguntas más frecuentes, haciendo una lista de las preguntas más comunes y difíciles, y luego analizándolas antes de su entrevista.
¿Cuáles son las cualidades que buscan los entrevistadores de ciencia de datos?
Para obtener una entrevista de ciencia de datos, deberá saber mucho sobre aritmética, estadística, lenguajes de programación, fundamentos de inteligencia comercial y, por supuesto, técnicas de aprendizaje automático. Seguramente se le pedirá que demuestre cómo sus habilidades de datos se relacionan con las opciones y la estrategia de la empresa. En el mercado actual, casi todos los trabajos de ciencia de datos requieren una entrevista de codificación. El papel de los científicos de datos incluye la publicación de código de producción, como canalizaciones de datos y modelos de aprendizaje automático, en muchas empresas. Para proyectos de esta naturaleza, también se requieren sólidas habilidades de programación, por lo que también puede esperar algunas preguntas de SQL y Python en la entrevista.
¿Puedo conseguir un trabajo de científico de datos a través de LinkedIn?
No se debe pasar por alto el poder de LinkedIn en estos días. LinkedIn es básicamente tu currículum digital. Las empresas y los reclutadores siguen buscando candidatos que lo merezcan en LinkedIn, por lo que es importante que construyas un perfil impresionante en LinkedIn, sigas buscando trabajo y postules a vacantes en LinkedIn. Agregue habilidades relevantes a su perfil y continúe agregando todos sus logros profesionales. De esta manera, sus posibilidades de conseguir un trabajo de ciencia de datos de LinkedIn son altas.