
คำถามและคำตอบสัมภาษณ์วิทยาศาสตร์ข้อมูล – 15 คำถามที่พบบ่อยที่สุด
เผยแพร่แล้ว: 2019-07-08การสัมภาษณ์งานมักจะยุ่งยาก เพื่อที่จะประสบความสำเร็จในการสัมภาษณ์ คุณต้องไม่เพียงมีความรู้เชิงลึกในเชิงลึกเท่านั้น แต่ยังต้องมีความมั่นใจและมีจิตใจที่แข็งแกร่งด้วย โดยเฉพาะอย่างยิ่งหากคุณกำลังเตรียมตัวสำหรับ Data Science – ทำให้ทุกคณะของคุณต้องทดสอบ!
ในระหว่างการสัมภาษณ์ Data Science คุณจะต้องเผชิญหน้ากับคำถามมากมายที่ครอบคลุมหัวข้อที่หลากหลาย ตั้งแต่คำถามวิทยาศาสตร์ข้อมูลพื้นฐานไปจนถึงสถิติ การวิเคราะห์ข้อมูล ML และการเรียนรู้เชิงลึก แต่นั่นไม่ใช่ทั้งหมด – ทักษะที่อ่อนนุ่มของคุณ (การสื่อสาร การทำงานเป็นทีม และอื่นๆ) จะได้รับการทดสอบด้วย
เพื่อความสะดวกในกระบวนการเตรียมการสำหรับคุณ เราได้รวบรวมรายการคำถามสัมภาษณ์ Data Science ที่พบบ่อย 15 ข้อ เราจะเริ่มต้นด้วยพื้นฐานแล้วไปยังหัวข้อและปัญหาขั้นสูง
ดังนั้นโดยไม่ต้องกังวลใจต่อไป มาเริ่มกันเลย!
- Data Science คืออะไร? แมชชีนเลิร์นนิงภายใต้การดูแลและไม่ได้รับการดูแลแตกต่างกันอย่างไร
กล่าวง่ายๆ Data Science คือการศึกษาข้อมูล มันเกี่ยวข้องกับการรวบรวมข้อมูลจากแหล่งที่แตกต่างกัน จัดเก็บ ทำความสะอาด และจัดระเบียบ และวิเคราะห์เพื่อค้นหาข้อมูลที่มีความหมายจากมัน Data Science ใช้การผสมผสานระหว่างคณิตศาสตร์ สถิติศาสตร์คอมพิวเตอร์ การเรียนรู้ของเครื่อง การแสดงข้อมูล การวิเคราะห์คลัสเตอร์ และการสร้างแบบจำลองข้อมูล มีจุดมุ่งหมายเพื่อรับข้อมูลเชิงลึกอันมีค่าจากข้อมูลดิบ (ทั้งที่มีโครงสร้างและไม่มีโครงสร้าง) และใช้ข้อมูลเชิงลึกเหล่านั้นเพื่อโน้มน้าวกลยุทธ์ทางธุรกิจและไอทีในเชิงบวก แนวคิดดังกล่าวสามารถช่วยให้ธุรกิจปรับกระบวนการให้เหมาะสม เพิ่มประสิทธิภาพและรายได้ เพิ่มความคล่องตัวให้กับกลยุทธ์ทางการตลาด เพิ่มความพึงพอใจของลูกค้า และอื่นๆ อีกมากมาย
ML ภายใต้การดูแลและไม่ได้รับการดูแล ML แตกต่างกันในด้านต่อไปนี้:
- ใน ML ภายใต้การดูแล ข้อมูลที่ป้อนจะมีป้ายกำกับ ใน ML ที่ไม่มีผู้ดูแล ข้อมูลที่ป้อนจะไม่มีป้ายกำกับ
- ในขณะที่ ML ภายใต้การดูแลใช้ชุดข้อมูลการฝึก ML ที่ไม่ได้รับการดูแลจะใช้ชุดข้อมูลที่ป้อนเข้า
- ML ที่อยู่ภายใต้การดูแลจะใช้เพื่อวัตถุประสงค์ในการคาดการณ์ ในขณะที่ ML ที่ไม่ได้รับการดูแลจะถูกใช้เพื่อวัตถุประสงค์ในการวิเคราะห์
- ML ภายใต้การดูแลช่วยให้สามารถจำแนกประเภทและการถดถอยได้ อย่างไรก็ตาม ML ที่ไม่มีผู้ดูแลช่วยให้สามารถจำแนกประเภท การประมาณความหนาแน่น และการลดขนาดได้
- Python หรือ R – ไหนดีกว่าสำหรับการวิเคราะห์ข้อความ?
เมื่อพูดถึงการวิเคราะห์ข้อความ Python ดูเหมือนจะเป็นตัวเลือกที่เหมาะสมที่สุด เนื่องจากมันมาพร้อมกับไลบรารี Pandas ที่มีโครงสร้างข้อมูลที่เป็นมิตรต่อผู้ใช้และเครื่องมือวิเคราะห์ข้อมูลที่มีประสิทธิภาพสูง นอกจากนี้ Python ยังมีประสิทธิภาพสูงและรวดเร็วสำหรับงานวิเคราะห์ข้อความทุกประเภท สำหรับ R จะเหมาะที่สุดสำหรับแอปพลิเคชันการเรียนรู้ของเครื่อง
- ประเภทข้อมูลที่รองรับใน Python มีอะไรบ้าง
Python มีอาร์เรย์ของประเภทข้อมูลในตัว ได้แก่ :
- บูลีน
- ตัวเลข (จำนวนเต็ม, ยาว, ทุ่น, เชิงซ้อน)
- ลำดับ (รายการ สตริง ไบต์ ทูเปิล)
- ชุด
- การทำแผนที่ (พจนานุกรม)
- ไฟล์วัตถุ
- อัลกอริธึมการจำแนกประเภทที่แตกต่างกันคืออะไร?
อัลกอริธึมการจำแนกที่สำคัญคือตัวแยกประเภทเชิงเส้น (การถดถอยโลจิสติก ตัวแยกประเภท Naive Bayes) แผนผังการตัดสินใจ ต้นไม้ที่ได้รับการส่งเสริม ฟอเรสต์สุ่ม SVM การประมาณเคอร์เนล โครงข่ายประสาทเทียม และเพื่อนบ้านที่ใกล้ที่สุด
- การกระจายแบบปกติคืออะไร?
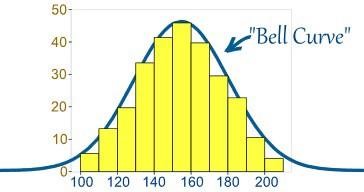
โดยปกติ ข้อมูลจะถูกแจกจ่ายในรูปแบบต่างๆ ทั้งโดยเอนเอียงไปทางซ้ายหรือทางขวา หรือในบางกรณี ข้อมูลก็อาจสับสนได้ อย่างไรก็ตาม อาจมีบางกรณีที่ข้อมูลถูกกระจายไปรอบๆ ค่าส่วนกลางโดยไม่มีอคติไปทางซ้ายหรือขวา ทำให้เกิดการกระจายแบบปกติในรูปของเส้นโค้งรูประฆัง
แหล่งที่มา
เส้นโค้งแสดงการกระจายตัวของตัวแปรสุ่มในรูปแบบของเส้นโค้งรูประฆังสมมาตร
- การทดสอบ A/B มีความสำคัญอย่างไร?
การทดสอบ A/B เป็นการทดสอบสมมติฐานทางสถิติสำหรับการทดลองแบบสุ่มที่เกี่ยวข้องกับสองตัวแปร – A และ B การทดสอบ A/B ช่วยระบุการเปลี่ยนแปลงหรือการเปลี่ยนแปลงใดๆ ที่ทำกับหน้าเว็บเพื่อเพิ่มผลลัพธ์ที่น่าสนใจสูงสุด เป็นวิธีที่ยอดเยี่ยมในการกำหนดกลยุทธ์การส่งเสริมการขายและการตลาดออนไลน์ที่ดีที่สุดสำหรับธุรกิจ
- Selection Bias คืออะไร?
Selection Bias เป็นข้อผิดพลาด 'ที่ใช้งานอยู่' ซึ่งเกิดขึ้นเมื่อผู้วิจัยตัดสินใจเลือกตัวอย่างที่จะทำการศึกษา ในกรณีนี้ ข้อมูลตัวอย่างจะถูกรวบรวมและเตรียมสำหรับการสร้างแบบจำลองข้อมูล แต่มีลักษณะดังกล่าวซึ่งไม่ใช่ตัวแทนที่แท้จริงของประชากรในอนาคตของกรณีต่างๆ ที่แบบจำลองจะพิจารณา ความลำเอียงในการเลือกเกิดขึ้นเมื่อชุดย่อยของข้อมูลตัวอย่างถูกเลือกอย่างเป็นระบบและรวม/แยกออกจากการวิเคราะห์ข้อมูล Selection Bias มีสามประเภท:
- อคติการสุ่มตัวอย่าง: ข้อผิดพลาดอย่างเป็นระบบที่เกิดขึ้นเมื่อกลุ่มตัวอย่างที่ไม่ใช่แบบสุ่มของชุดข้อมูลทำให้สมาชิกของชุดข้อมูลมีโอกาสน้อยที่จะรวมอยู่ในการศึกษา ส่งผลให้กลุ่มตัวอย่างมีอคติ
- ช่วงเวลา: เกิดขึ้นเมื่อการทดลองวิเคราะห์ข้อมูลสิ้นสุดก่อนกำหนดด้วยค่าสุดขีด อย่างไรก็ตาม ตัวแปรที่มีค่าความแปรปรวนมากที่สุดสามารถบรรลุค่าสูงสุดได้ (แม้ว่าตัวแปรทั้งหมดจะมีค่าเฉลี่ยใกล้เคียงกัน)
- การขัดสี: เกิดขึ้นเนื่องจากการลดราคาการขัดสี หรือการสูญเสียผู้เข้าร่วมระหว่างการทดลองใช้ที่สิ้นสุดก่อนจะเสร็จสิ้น
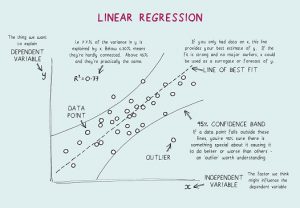
- การถดถอยเชิงเส้นคืออะไร? สมมติฐานที่จำเป็นสำหรับการถดถอยเชิงเส้นคืออะไร?
การถดถอยเชิงเส้นเป็นเครื่องมือทางสถิติที่ใช้สำหรับการวิเคราะห์เชิงคาดการณ์ ในวิธีนี้ คะแนนของตัวแปร (เช่น Y) จะถูกคาดการณ์จากคะแนนของตัวแปรอื่น (เช่น X) โดยที่ Y คือตัวแปรเกณฑ์ ในขณะที่ X คือตัวแปรตัวทำนาย
ในการถดถอยเชิงเส้น มีสมมติฐานพื้นฐานสี่ข้อ:
- มีความสัมพันธ์เชิงเส้นระหว่างตัวแปรตามและตัวถดถอย ดังนั้น โมเดลข้อมูลที่สร้างขึ้นจะซิงค์กับข้อมูล
- ส่วนที่เหลือของข้อมูลเป็นอิสระจากกันและจะแจกจ่าย
- มีความสัมพันธ์แบบพหุความสัมพันธ์น้อยที่สุดระหว่างตัวแปรอธิบาย
- มี 'homoscedasticity' ซึ่งหมายความว่าความแปรปรวนรอบเส้นการถดถอยจะเหมือนกันสำหรับค่าทั้งหมดของตัวแปรทำนาย
- การตรวจสอบข้ามคืออะไร?
การตรวจสอบข้ามเป็นขั้นตอนการตรวจสอบความถูกต้องของแบบจำลองที่ใช้สำหรับ จุดมุ่งหมายในที่นี้คือการกำหนดชุดข้อมูลการตรวจสอบความถูกต้องเพื่อทดสอบแบบจำลองในขั้นตอนการฝึกอบรมเพื่อจำกัดปัญหาต่างๆ เช่น การใส่มากเกินไป และแน่นอน กำหนดว่าแบบจำลองจะสรุปเป็นชุดข้อมูลอิสระอย่างไร
การตรวจสอบข้าม (CV) เป็นเทคนิคการตรวจสอบแบบจำลองที่ใช้ในการทดสอบประสิทธิภาพของแบบจำลองการเรียนรู้ของเครื่อง นอกจากนี้ยังเป็นวิธีการสุ่มตัวอย่างซ้ำที่ใช้ในการประเมินแบบจำลองในกรณีที่มีข้อมูลจำกัด ในวิธีตรวจสอบไขว้ ส่วนหนึ่งของข้อมูลจะถูกจัดสรรไว้สำหรับการทดสอบและการตรวจสอบ และใช้เพื่อกำหนดว่าผลลัพธ์ของการวิเคราะห์ทางสถิติจะสรุปเป็นชุดข้อมูลอิสระได้อย่างไร

- สูตรความน่าจะเป็นทวินามคืออะไร?
การแจกแจงความน่าจะเป็นแบบทวินามพิจารณาความน่าจะเป็นของแต่ละจำนวนที่เป็นไปได้ของความสำเร็จจากจำนวนการทดลอง N สำหรับเหตุการณ์อิสระ โดยแต่ละครั้งมีความน่าจะเป็นที่จะเกิดขึ้นของ π (pi) สูตรสำหรับการแจกแจงความน่าจะเป็นทวินามคือ:
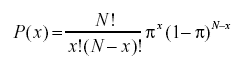
- การวิเคราะห์แบบ Univariate, Bivariate และ Multivariate แตกต่างกันอย่างไร
การวิเคราะห์แบบตัวแปรเดียวหมายถึงเทคนิคการวิเคราะห์เชิงสถิติเชิงพรรณนาที่สามารถแยกความแตกต่างได้ตามจำนวนตัวแปรที่เกี่ยวข้อง ณ จุดใดเวลาหนึ่ง (เช่น แผนภูมิวงกลมที่แสดงยอดขายของผลิตภัณฑ์ในพื้นที่เฉพาะ) ตรงกันข้ามกับสิ่งนี้ การวิเคราะห์แบบสองตัวแปรมีวัตถุประสงค์เพื่อทำความเข้าใจและกำหนดความแตกต่างระหว่างสองตัวแปรในแต่ละครั้งเช่นเดียวกับในแผนภาพแบบกระจาย (เช่น ความสัมพันธ์ระหว่างปริมาณการขายและการใช้จ่าย)
การวิเคราะห์หลายตัวแปรเกี่ยวข้องกับการศึกษาตัวแปรมากกว่าสองตัวเพื่อทำความเข้าใจผลกระทบของตัวแปรที่มีต่อการตอบสนอง/ผลลัพธ์
- โครงข่ายประสาทเทียมคืออะไร?
พูด ง่ายๆ คือ โครงข่ายประสาทเทียม (ANN) หมายถึงระบบคอมพิวเตอร์ที่ออกแบบตามสมองของมนุษย์ เช่นเดียวกับสมองของมนุษย์ ANNs ประกอบด้วยองค์ประกอบการประมวลผลง่ายๆ มากมาย เรียกว่าเซลล์ประสาทเทียม ซึ่งการทำงานได้รับแรงบันดาลใจจากเซลล์ประสาทในสายพันธุ์สัตว์ ANN สามารถเรียนรู้ผ่านประสบการณ์และสามารถปรับให้เข้ากับอินพุตที่เปลี่ยนแปลง เพื่อให้เครือข่ายสามารถสร้างผลลัพธ์ที่ดีที่สุดโดยไม่ต้องออกแบบเกณฑ์ผลลัพธ์ใหม่
- Recurrent Neural Networks (RNN) คืออะไร?
โครงข่ายประสาทเทียมแบบกำเริบ (RNN) เป็นโครงข่ายประสาทเทียมชนิดหนึ่ง ซึ่งการเชื่อมต่อของปมประสาทส่งผลให้เกิดกราฟที่กำกับตามลำดับชั่วขณะ ดังนั้นจึงแสดงพฤติกรรมไดนามิกชั่วคราว เพื่อให้เข้าใจ RNN คุณต้องเข้าใจการทำงานของตาข่าย feedforward ก่อน ในขณะที่ข้อมูลช่องสัญญาณเครือข่าย feedforward เป็นเส้นตรง (โดยไม่ต้องสัมผัสโหนดเดียวกันสองครั้ง) เครือข่ายประสาทที่เกิดซ้ำจะหมุนเวียนข้อมูลผ่านกระบวนการที่เหมือนวนซ้ำ ตรงกันข้ามกับโครงข่ายประสาทฟีดฟอร์เวิร์ด RNN สามารถใช้หน่วยความจำภายในเพื่อประมวลผลลำดับของอินพุตได้ ดังนั้น RNN จึงเหมาะที่สุดสำหรับงานที่ไม่ได้แบ่งกลุ่มหรือเชื่อมต่อ เช่น การรู้จำลายมือและการรู้จำคำพูด
คำถามและคำตอบในการสัมภาษณ์นักวิเคราะห์ข้อมูล 17 อันดับแรก
- Back Propagation คืออะไร?
Backpropagation หมายถึงอัลกอริธึมการเรียนรู้ภายใต้การดูแลที่ใช้สำหรับการฝึกอบรมโครงข่ายประสาทเทียมแบบหลายชั้น backpropagation สามารถย้ายข้อผิดพลาดจากจุดสิ้นสุดของเครือข่ายไปยังน้ำหนักทั้งหมดภายในเครือข่าย ซึ่งช่วยให้คำนวณการไล่ระดับสีได้อย่างมีประสิทธิภาพ ค้นหาค่าต่ำสุดของฟังก์ชันข้อผิดพลาดในพื้นที่น้ำหนักโดยใช้เทคนิคการลาดลงระดับ น้ำหนักที่ลดฟังก์ชันข้อผิดพลาดถือเป็นวิธีแก้ปัญหาการเรียนรู้
- Backpropagation เกี่ยวข้องกับขั้นตอนต่อไปนี้:
- ส่งต่อข้อมูลการฝึกอบรม
- คำนวณอนุพันธ์โดยใช้เอาต์พุตและเป้าหมาย
- Back Propagate สำหรับการคำนวณอนุพันธ์ของข้อผิดพลาด
- ใช้อนุพันธ์ที่คำนวณไว้ก่อนหน้านี้สำหรับเอาต์พุต
- กำลังคำนวณมูลค่าน้ำหนักที่อัปเดตและอัปเดตน้ำหนัก
- อธิบาย Gradient Descent
ในการทำความเข้าใจ Gradient Descent คุณต้องเข้าใจก่อนว่าการไล่ระดับสีคืออะไร การไล่ระดับสีคือการวัดว่าเอาต์พุตของฟังก์ชันเฉพาะเปลี่ยนแปลงไปมากเพียงใดเมื่อเทียบกับการเปลี่ยนแปลงเล็กน้อยในอินพุต มันวัดการเปลี่ยนแปลงในน้ำหนักทั้งหมดเพื่อตอบสนองต่อการเปลี่ยนแปลงในข้อผิดพลาด ดังนั้น เกรเดียนท์คือความชันของฟังก์ชัน
การไล่ระดับสีแบบไล่ระดับเป็นอัลกอริธึมการปรับให้เหมาะสมที่ช่วยค้นหาค่าของพารามิเตอร์ (สัมประสิทธิ์) ของฟังก์ชัน (f) ที่ลดฟังก์ชันต้นทุน (ต้นทุน) เหมาะที่สุดสำหรับกรณีที่ไม่สามารถคำนวณพารามิเตอร์แบบวิเคราะห์ได้
บทสรุป
ในบันทึกสรุป คุณต้องรู้ว่าไม่มีวิธีเดียวหรือวิธีที่ดีที่สุดในการเตรียมตัวสำหรับการสัมภาษณ์ มันคือทั้งหมดที่เกี่ยวกับฐานความรู้ของคุณ ความมั่นใจและวิธีการของคุณ และโชคเล็กๆ น้อยๆ แม้ว่าคำถามเหล่านี้เป็นเพียงคำถามเล็กๆ น้อยๆ ของ Data Science เราหวังว่าสิ่งนี้จะช่วยให้คุณมีแนวคิดคร่าวๆ เกี่ยวกับประเภทของคำถามที่คุณสามารถถามได้ในการสัมภาษณ์ Data Science ที่กล่าวว่าเตรียมตัวให้ดีและดีที่สุดสำหรับความพยายามของคุณ!
เรียนรู้ หลักสูตรวิทยาศาสตร์ข้อมูล จากมหาวิทยาลัยชั้นนำของโลก รับโปรแกรม PG สำหรับผู้บริหาร โปรแกรมประกาศนียบัตรขั้นสูง หรือโปรแกรมปริญญาโท เพื่อติดตามอาชีพของคุณอย่างรวดเร็ว
ในการสัมภาษณ์ Data Science มีกี่รอบ?
อาจจำเป็นต้องมีการสัมภาษณ์การเขียนโปรแกรมหนึ่งหรือสองรอบ แต่ทั้งนี้ขึ้นอยู่กับบริษัทที่คุณสมัครทั้งหมด บางบริษัททำให้กระบวนการสัมภาษณ์นานถึงหกรอบ คุณสามารถเตรียมคำตอบสำหรับคำถามแต่ละข้อได้โดยการค้นหาคำถามที่พบบ่อย จัดทำรายการคำถามที่พบบ่อยและยากที่สุด จากนั้นวิเคราะห์คำถามเหล่านั้นก่อนการสัมภาษณ์
อะไรคือคุณสมบัติที่ผู้สัมภาษณ์ด้านวิทยาศาสตร์ข้อมูลมองหา?
ในการสัมภาษณ์ด้านวิทยาศาสตร์ข้อมูล คุณจะต้องรู้มากเกี่ยวกับเลขคณิต สถิติ ภาษาโปรแกรม พื้นฐานข่าวกรองธุรกิจ และแน่นอน เทคนิคการเรียนรู้ของเครื่อง คุณจะถูกขอให้แสดงให้เห็นว่าความสามารถด้านข้อมูลของคุณเกี่ยวข้องกับทางเลือกและกลยุทธ์ของบริษัทอย่างไร ในตลาดปัจจุบัน งานวิทยาศาสตร์ข้อมูลเกือบทุกงานต้องมีการสัมภาษณ์เขียนโค้ด บทบาทของนักวิทยาศาสตร์ด้านข้อมูลรวมถึงการเปิดตัวรหัสการผลิต เช่น ท่อข้อมูลและโมเดลการเรียนรู้ของเครื่อง ในหลายบริษัท สำหรับโครงการในลักษณะนี้ จำเป็นต้องมีความสามารถในการเขียนโปรแกรมที่แข็งแกร่ง ดังนั้นคุณสามารถคาดหวังคำถามเกี่ยวกับ SQL และ Python ในการสัมภาษณ์ได้เช่นกัน
ฉันสามารถรับงานนักวิทยาศาสตร์ข้อมูลผ่าน LinkedIn ได้หรือไม่
เราไม่ควรมองข้ามพลังของ LinkedIn ในทุกวันนี้ LinkedIn เป็นประวัติย่อดิจิทัลของคุณ บริษัทและนายหน้ามองหาผู้สมัครที่สมควรได้รับบน LinkedIn อยู่เสมอ ดังนั้น การสร้างโปรไฟล์ LinkedIn ที่น่าประทับใจ จึงเป็นสิ่งสำคัญสำหรับคุณ มองหางานและสมัครงานใน LinkedIn เพิ่มทักษะที่เกี่ยวข้องให้กับโปรไฟล์ของคุณและเพิ่มความสำเร็จในอาชีพของคุณต่อไป ด้วยวิธีนี้ โอกาสที่คุณจะได้งานด้านวิทยาศาสตร์ข้อมูลที่สมควรได้รับจาก LinkedIn มีสูง