
Fragen und Antworten zu Data Science-Interviews – 15 der am häufigsten gestellten Fragen
Veröffentlicht: 2019-07-08Vorstellungsgespräche sind immer schwierig. Um ein Vorstellungsgespräch erfolgreich zu meistern, müssen Sie nicht nur fundiertes Fachwissen, sondern auch Selbstvertrauen und eine starke Geistesgegenwart besitzen. Dies gilt insbesondere, wenn Sie sich auf ein Data Science vorbereiten – es stellt alle Ihre Fähigkeiten auf die Probe!
Während eines Data-Science-Interviews müssen Sie sich einer Vielzahl von Fragen stellen, die sich über verschiedene Themen erstrecken, von grundlegenden Data-Science-Fragen bis hin zu Statistik, Datenanalyse, ML und Deep Learning. Aber das ist noch nicht alles – auch deine Soft Skills (Kommunikation, Teamfähigkeit, etc.) werden getestet.
Um Ihnen den Vorbereitungsprozess zu erleichtern, haben wir eine Liste mit den 15 am häufigsten gestellten Interviewfragen zu Data Science zusammengestellt. Wir beginnen mit den Grundlagen und gehen dann zu den fortgeschritteneren Themen und Problemen über.
Also, ohne weitere Umschweife, fangen wir an!
- Was ist Datenwissenschaft? Wie unterscheiden sich überwachtes und unüberwachtes maschinelles Lernen?
Im Klartext ist Data Science das Studium von Daten. Es beinhaltet das Sammeln von Daten aus unterschiedlichen Quellen, deren Speicherung, Bereinigung und Organisation sowie deren Analyse, um aussagekräftige Informationen daraus zu gewinnen. Data Science verwendet eine Kombination aus Mathematik, Statistikinformatik, maschinellem Lernen, Datenvisualisierung, Clusteranalyse und Datenmodellierung. Es zielt darauf ab, wertvolle Erkenntnisse aus Rohdaten (sowohl strukturiert als auch unstrukturiert) zu gewinnen und diese Erkenntnisse zu nutzen, um Geschäfts- und IT-Strategien positiv zu beeinflussen. Solche Ideen können Unternehmen dabei helfen, Prozesse zu optimieren, Produktivität und Umsatz zu steigern, Marketingstrategien zu rationalisieren, die Kundenzufriedenheit zu steigern und vieles mehr.
Überwachtes und unüberwachtes ML unterscheiden sich in folgenden Punkten:
- In überwachtem ML werden die Eingabedaten gekennzeichnet. Beim unüberwachten ML bleiben die Eingabedaten unbeschriftet.
- Während überwachtes ML den Trainingsdatensatz verwendet, verwendet nicht überwachtes ML den Eingabedatensatz.
- Überwachtes ML wird zu Vorhersagezwecken verwendet, während nicht überwachtes ML zu Analysezwecken verwendet wird.
- Supervised ML ermöglicht Klassifizierung und Regression. Unüberwachtes ML ermöglicht jedoch die Klassifizierung, Dichteschätzung und Dimensionsreduktion.
- Python oder R – Was ist besser für die Textanalyse?
Wenn es um Textanalyse geht, scheint Python die am besten geeignete Option zu sein. Dies liegt daran, dass es mit der Pandas-Bibliothek geliefert wird, die benutzerfreundliche Datenstrukturen und leistungsstarke Datenanalysetools enthält. Außerdem ist Python für alle Arten von Textanalyseaufgaben hocheffizient und schnell. R eignet sich am besten für Anwendungen des maschinellen Lernens.
- Was sind die unterstützten Datentypen in Python?
Python verfügt über eine Reihe integrierter Datentypen, darunter:
- Boolesch
- Numerisch (Integer, Long, Float, Complex)
- Sequenzen (Listen, Strings, Byte, Tupel)
- Sets
- Zuordnungen (Wörterbücher)
- Dateiobjekte
- Welche unterschiedlichen Klassifizierungsalgorithmen gibt es?
Die zentralen Klassifizierungsalgorithmen sind lineare Klassifikatoren (logistische Regression, Naive-Bayes-Klassifikator), Entscheidungsbäume, verstärkte Bäume, Random Forest, SVM, Kernel-Schätzung, neuronale Netze und nächster Nachbar.
- Was ist Normalverteilung?
Normalerweise werden Daten auf verschiedene Weise verteilt, entweder mit einer Neigung nach links oder rechts, oder unter einigen Umständen können sie durcheinander geraten. Es kann jedoch Fälle geben, in denen die Daten ohne Links- oder Rechtsverzerrung um einen zentralen Wert herum verteilt sind, wodurch eine Normalverteilung in Form einer Glockenkurve erreicht wird.
Quelle
Die Kurve zeigt die Verteilung von Zufallsvariablen in Form einer symmetrischen Glockenkurve.
- Welche Bedeutung haben A/B-Tests?
A/B-Tests sind statistische Hypothesentests für zufällige Experimente mit zwei Variablen – A und B. A/B-Tests helfen dabei, Änderungen oder Änderungen zu identifizieren, die an der Webseite vorgenommen wurden, um das gewünschte Ergebnis zu maximieren. Es ist eine ausgezeichnete Methode, um die besten Online-Werbe- und Marketingstrategien für Unternehmen zu ermitteln.
- Was ist Selektionsbias?
Auswahlverzerrung ist ein „aktiver“ Fehler, der auftritt, wenn der Forscher entscheidet, welche Proben untersucht werden sollen. In diesem Fall werden die Stichprobendaten gesammelt und für die Datenmodellierung aufbereitet, aber sie weisen solche Merkmale auf, die nicht der wahre Repräsentant der zukünftigen Fallpopulation sind, die das Modell berücksichtigen wird. Selektionsverzerrung tritt auf, wenn eine Teilmenge der Stichprobendaten systematisch ausgewählt und in die Datenanalyse eingeschlossen/ausgeschlossen wird. Es gibt drei verschiedene Arten von Selektionsverzerrungen:
- Stichprobenverzerrung: Ein systematischer Fehler, der auftritt, wenn eine nicht zufällige Stichprobe eines Datensatzes dazu führt, dass einige Mitglieder des Datensatzes weniger wahrscheinlich in die Studie einbezogen werden, was zu einer verzerrten Stichprobe führt.
- Zeitintervall: Es tritt auf, wenn ein Datenanalyseversuch bei einem Extremwert vorzeitig beendet wird. Allerdings kann der Extremwert eher von der Variable mit der größten Varianz erreicht werden (selbst wenn alle Variablen einen ähnlichen Mittelwert besitzen).
- Fluktuation: Tritt aufgrund von Fluktuationsrabatten oder dem Verlust von Teilnehmern während einer Studie auf, die vor Abschluss beendet wurde.
- Was ist eine lineare Regression? Welche Annahmen sind für die lineare Regression erforderlich?
Die lineare Regression ist ein statistisches Tool, das für die Vorhersageanalyse verwendet wird. Bei dieser Methode wird der Wert einer Variablen (z. B. Y) anhand des Werts einer anderen Variablen (z. B. X) vorhergesagt. Hier ist Y die Kriteriumsvariable, während X die Prädiktorvariable ist.
Bei der linearen Regression gibt es vier grundlegende Annahmen:
- Zwischen den abhängigen Variablen und den Regressoren besteht eine lineare Beziehung. Das erstellte Datenmodell wird also mit den Daten synchronisiert.
- Die Residuen der Daten sind voneinander unabhängig und zu verteilen.
- Es besteht eine minimale Multikollinearität zwischen erklärenden Variablen.
- Es liegt „Homoskedastizität“ vor, was bedeutet, dass die Varianz um die Regressionslinie herum für alle Werte der Prädiktorvariablen gleich ist.
- Was ist Kreuzvalidierung?
Die Kreuzvalidierung ist ein Modellvalidierungsverfahren, das für verwendet wird. Das Ziel hier ist, den Validierungsdatensatz zu benennen, um das Modell in der Trainingsphase zu testen, um Probleme wie Overfitting zu begrenzen und natürlich zu bestimmen, wie das Modell auf einen unabhängigen Datensatz generalisiert wird.
Kreuzvalidierung (CV) ist eine Modellvalidierungstechnik, die zum Testen der Effektivität von Modellen für maschinelles Lernen eingesetzt wird. Es ist auch eine Resampling-Methode, die verwendet wird, um ein Modell bei begrenzten Daten zu evaluieren. Bei der Kreuzvalidierungsmethode wird ein Teil der Daten für Tests und Validierungen reserviert und verwendet, um zu bestimmen, wie die Ergebnisse der statistischen Analyse zu einem unabhängigen Datensatz verallgemeinert werden.

- Was ist die binomiale Wahrscheinlichkeitsformel?
Die binomiale Wahrscheinlichkeitsverteilung berücksichtigt die Wahrscheinlichkeiten jeder der möglichen Anzahlen von Erfolgen aus einer Anzahl von N Versuchen für unabhängige Ereignisse, die jeweils die Eintrittswahrscheinlichkeit von π (pi) haben. Die Formel für eine binomiale Wahrscheinlichkeitsverteilung lautet:
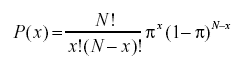
- Was ist der Unterschied zwischen univariater, bivariater und multivariater Analyse?
Univariate Analyse bezieht sich auf die deskriptive statistische Analysetechnik, die basierend auf der Anzahl der beteiligten Variablen zu einem bestimmten Zeitpunkt differenziert werden kann (z. B. Tortendiagramme, die die Verkäufe eines Produkts in einem bestimmten Gebiet darstellen). Im Gegensatz dazu zielt die bivariate Analyse darauf ab, den Unterschied zwischen zwei Variablen gleichzeitig wie in einem Streudiagramm zu verstehen und zu bestimmen (z. B. die Beziehung zwischen dem Verkaufsvolumen und den Ausgaben).
Die multivariate Analyse umfasst die Untersuchung von mehr als zwei Variablen, um die Wirkung der Variablen auf die Antworten/Ergebnisse zu verstehen.
- Was sind künstliche neuronale Netze?
Im Klartext bezieht sich Artificial Neural Networks (ANN) auf ein Computersystem, das dem menschlichen Gehirn nachempfunden ist. Genau wie das menschliche Gehirn bestehen ANNs aus zahlreichen einfachen Verarbeitungselementen, sogenannten künstlichen Neuronen, deren Funktionalität von den Neuronen in Tierarten inspiriert ist. KNNs können durch Erfahrung lernen und sich an den sich ändernden Input anpassen, sodass das Netzwerk das bestmögliche Ergebnis erzielen kann, ohne die Output-Kriterien neu gestalten zu müssen.
- Was sind Recurrent Neural Networks (RNNs)?
Ein rekurrentes neuronales Netzwerk (RNN) ist eine Art künstliches neuronales Netzwerk, in dem Knotenverbindungen zu einem gerichteten Graphen entlang einer zeitlichen Sequenz führen, wodurch ein zeitlich dynamisches Verhalten gezeigt wird. Um RNN zu verstehen, müssen Sie zunächst die Funktionsweise von Feedforward-Netzen verstehen. Während Feedforward-Netzwerke Informationen in einer geraden Linie kanalisieren (ohne denselben Knoten zweimal zu berühren), durchlaufen rekurrente neuronale Netzwerke Informationen durch einen schleifenartigen Prozess. Im Gegensatz zu neuronalen Feedforward-Netzen können RNNs ihren internen Speicher verwenden, um Sequenzen von Eingaben zu verarbeiten. Daher eignen sich RNNs am besten für Aufgaben, die nicht segmentiert oder verbunden sind, wie z. B. Handschrifterkennung und Spracherkennung.
Die 17 wichtigsten Fragen und Antworten zu Interviews mit Datenanalysten
- Was ist Backpropagation?
Backpropagation bezieht sich auf einen überwachten Lernalgorithmus, der zum Trainieren mehrschichtiger neuronaler Netze verwendet wird. Durch Backpropagation kann ein Fehler von einem Ende des Netzwerks zu allen Gewichtungen innerhalb des Netzwerks verschoben werden, wodurch eine effiziente Berechnung des Gradienten ermöglicht wird. Es sucht den Minimalwert der Fehlerfunktion im Gewichtsraum unter Verwendung der Gradientenabstiegstechnik. Als Lösung des Lernproblems werden die Gewichte angesehen, die die Fehlerfunktion minimieren.
- Die Backpropagation umfasste die folgenden Schritte:
- Vorwärtsausbreitung von Trainingsdaten.
- Berechnen Sie Ableitungen unter Verwendung von Ausgabe und Ziel.
- Back Propagate zum Berechnen der Ableitung des Fehlers.
- Verwenden Sie zuvor berechnete Ableitungen für die Ausgabe.
- Berechnen des aktualisierten Gewichtswerts und Aktualisieren der Gewichte.
- Erklären Sie Gradientenabstieg.
Um Gradient Descent zu verstehen, müssen Sie zunächst verstehen, was ein Gradient ist. Ein Gradient ist ein Maß dafür, wie stark sich die Ausgabe einer bestimmten Funktion in Bezug auf eine geringfügige Änderung der Eingaben ändert. Es misst die Änderung aller Gewichte als Reaktion auf eine Fehleränderung. Mit anderen Worten, ein Gradient ist also die Steigung einer Funktion.
Der Gradientenabstieg ist ein Optimierungsalgorithmus, der hilft, die Werte von Parametern (Koeffizienten) einer Funktion (f) zu finden, die eine Kostenfunktion (Kosten) minimiert. Es eignet sich am besten für Fälle, in denen die Parameter nicht analytisch berechnet werden können.
Fazit
Abschließend müssen Sie wissen, dass es keinen einzigen oder besten Weg gibt, sich auf ein Vorstellungsgespräch vorzubereiten. Es dreht sich alles um Ihre Wissensbasis, Ihr Selbstvertrauen und Ihren Ansatz und ein wenig Glück. Obwohl dies nur eine Handvoll Data-Science-Fragen sind, hoffen wir, dass Ihnen dies eine ungefähre Vorstellung davon gibt, welche Art von Fragen Ihnen in einem Data-Science-Interview gestellt werden können. Das heißt, bereiten Sie sich gut vor und alles Gute für Ihre Bemühungen!
Lernen Sie Datenwissenschaftskurse von den besten Universitäten der Welt. Verdienen Sie Executive PG-Programme, Advanced Certificate-Programme oder Master-Programme, um Ihre Karriere zu beschleunigen.
Wie viele Runden gibt es in einem Data-Science-Interview?
Möglicherweise sind ein oder zwei Programmiergesprächsrunden erforderlich, dies hängt jedoch vollständig von dem Unternehmen ab, für das Sie sich bewerben. Einige Unternehmen lassen den Interviewprozess bis zu sechs Runden dauern. Sie können Ihre Antworten auf jede Frage vorbereiten, indem Sie die am häufigsten gestellten Fragen recherchieren, eine Liste der häufigsten und schwierigsten Fragen erstellen und diese Fragen dann vor Ihrem Vorstellungsgespräch analysieren.
Auf welche Qualitäten achten Data-Science-Interviewer?
Um ein Data-Science-Interview zu bestehen, müssen Sie viel über Arithmetik, Statistik, Programmiersprachen, Business-Intelligence-Grundlagen und natürlich Techniken des maschinellen Lernens wissen. Sie werden höchstwahrscheinlich gebeten, zu demonstrieren, wie Ihre Datenfähigkeiten mit Unternehmensentscheidungen und -strategien zusammenhängen. Auf dem heutigen Markt erfordert fast jeder Data-Science-Job ein Programmierinterview. Die Rolle von Datenwissenschaftlern umfasst in vielen Unternehmen die Freigabe von Produktionscode wie Datenpipelines und Modellen für maschinelles Lernen. Für Projekte dieser Art sind auch starke Programmierkenntnisse erforderlich, sodass Sie im Vorstellungsgespräch auch mit einigen SQL- und Python-Fragen rechnen können.
Kann ich über LinkedIn einen Data Scientist-Job bekommen?
Man sollte die Macht von LinkedIn heutzutage nicht übersehen. LinkedIn ist im Grunde Ihr digitaler Lebenslauf. Unternehmen und Personalvermittler suchen weiterhin nach verdienstvollen Kandidaten auf LinkedIn, daher ist es wichtig, dass Sie ein beeindruckendes LinkedIn-Profil erstellen, weiterhin nach Arbeit suchen und sich auf Stellenangebote auf LinkedIn bewerben. Fügen Sie Ihrem Profil relevante Fähigkeiten hinzu und fügen Sie weiterhin alle Ihre beruflichen Erfolge hinzu. Auf diese Weise sind Ihre Chancen auf einen verdienstvollen Data-Science-Job von LinkedIn hoch.