
データサイエンスインタビューの質問と回答–15の最もよくある質問
公開: 2019-07-08就職の面接は常にトリッキーです。 面接を成功させるには、主題に関する深い知識だけでなく、自信と強い心の存在も必要です。 これは、データサイエンスの準備をしている場合に特に当てはまります。これにより、すべての学部がテストされます。
データサイエンスのインタビューでは、基本的なデータサイエンスの質問から統計、データ分析、ML、ディープラーニングに至るまで、さまざまなトピックにまたがる多数の質問に直面する必要があります。 しかし、それだけではありません。あなたのソフトスキル(コミュニケーション、チームワークなど)もテストされます。
準備プロセスを簡単にするために、データサイエンスの面接で最もよく聞かれる15の質問のリストを作成しました。 基本から始めて、より高度なトピックと問題に進みます。
それで、それ以上の苦労なしに、始めましょう!
- データサイエンスとは何ですか? 教師あり機械学習と教師なし機械学習はどのように異なりますか?
簡単に言えば、データサイエンスはデータの研究です。 これには、さまざまなソースからのデータの収集、保存、クリーニングと整理、および分析して意味のある情報を明らかにすることが含まれます。 データサイエンスは、数学、統計コンピュータサイエンス、機械学習、データ視覚化、クラスター分析、およびデータモデリングを組み合わせて使用します。 生データ(構造化および非構造化の両方)から貴重な洞察を得て、それらの洞察を使用してビジネスおよびIT戦略にプラスの影響を与えることを目的としています。 このようなアイデアは、企業がプロセスを最適化し、生産性と収益を高め、マーケティング戦略を合理化し、顧客満足度を高めるのに役立ちます。
監視ありMLと教師なしMLは、次の点で互いに異なります。
- 教師ありMLでは、入力データにラベルが付けられます。 教師なしMLでは、入力データはラベルなしのままです。
- 教師ありMLはトレーニングデータセットを使用しますが、教師なしMLは入力データセットを使用します。
- 教師ありMLは予測の目的で使用されますが、教師なしMLは分析の目的で使用されます。
- 教師ありMLにより、分類と回帰が可能になります。 ただし、教師なしMLは、分類、密度推定、および次元削減を可能にします。
- PythonまたはR–テキスト分析にはどちらが適していますか?
テキスト分析に関しては、Pythonが最も適切なオプションのようです。 これは、ユーザーフレンドリーなデータ構造と高性能のデータ分析ツールを含むPandasライブラリが付属しているためです。 また、Pythonは、あらゆる種類のテキスト分析タスクに対して非常に効率的で高速です。 Rに関しては、機械学習アプリケーションに最適です。
- Pythonでサポートされているデータ型は何ですか?
Pythonには、次のような一連の組み込みデータ型があります。
- ブール値
- 数値(整数、長整数、浮動小数点、複素数)
- シーケンス(リスト、文字列、バイト、タプル)
- セット
- マッピング(辞書)
- ファイルオブジェクト
- 異なる分類アルゴリズムは何ですか?
重要な分類アルゴリズムは、線形分類器(ロジスティック回帰、単純ベイズ分類器)、決定ツリー、ブーストツリー、ランダムフォレスト、SVM、カーネル推定、ニューラルネットワーク、および最近傍です。
- 正規分布とは何ですか?
通常、データは左または右に偏ってさまざまな方法で配布されるか、いくつかの状況では混乱する可能性があります。 ただし、データが中央の値の周りに左右に偏ることなく分布し、それによって釣鐘型の曲線の形で正規分布を達成する場合があります。
ソース
この曲線は、対称的な釣鐘型の曲線の形で確率変数の分布を示しています。
- A / Bテストの重要性は何ですか?
A / Bテストは、AとBの2つの変数を含むランダムな実験の統計的仮説検定です。A/ Bテストは、関心のある結果を最大化するためにWebページに加えられた変更または変更を特定するのに役立ちます。 これは、企業にとって最良のオンラインプロモーションおよびマーケティング戦略を決定するための優れた方法です。
- 選択バイアスとは何ですか?
選択バイアスは、研究者が調査対象のサンプルを決定するときに発生する「アクティブな」エラーです。 この場合、サンプルデータは収集され、データモデリング用に準備されますが、モデルが検討する将来のケースの母集団を真に表すものではないような特性を備えています。 選択バイアスは、サンプルデータのサブセットが体系的に選択され、データ分析に含まれる/除外されるときに発生します。 選択バイアスには3つの異なるタイプがあります。
- サンプリングバイアス:データセットの非ランダムサンプルが原因でデータセットの一部のメンバーが調査に含まれる可能性が低くなり、それによってサンプルにバイアスがかかる場合に発生する系統的エラー。
- 時間間隔:データ分析の試行が極値で早期に終了したときに発生します。 ただし、(すべての変数が同様の平均を持っている場合でも)最大の分散を持つ変数によって極値が達成される可能性が高くなります。
- 離職:離職割引、または完了前に終了したトライアル中の参加者の喪失が原因で発生します。
- 線形回帰とは何ですか? 線形回帰に必要な仮定は何ですか?
線形回帰は、予測分析に使用される統計ツールです。 この方法では、変数(たとえば、Y)のスコアは、別の変数(たとえば、X)のスコアから予測されます。 ここで、Yは基準変数であり、Xは予測変数です。
線形回帰では、4つの基本的な仮定があります。
- 従属変数と回帰変数の間には線形関係が存在します。 したがって、作成されたデータモデルはデータと同期します。
- データの残差は互いに独立しており、分散されます。
- 説明変数間には最小限の多重共線性があります。
- 「等分散性」があります。これは、回帰直線の周りの分散が予測変数のすべての値で同じであることを意味します。
- 相互検証とは何ですか?
交差検定は、に使用されるモデル検証手順です。 ここでの目的は、検証データセットを用語にして、トレーニングフェーズでモデルをテストし、過剰適合などの問題を制限し、もちろん、モデルが独立したデータセットにどのように一般化されるかを決定することです。
相互検証(CV)は、機械学習モデルの有効性をテストするために使用されるモデル検証手法です。 また、データが限られている場合にモデルを評価するために使用される再サンプリング方法でもあります。 交差検定法では、データの一部がテストと検証のために確保され、統計分析の結果が独立したデータセットにどのように一般化されるかを決定するために使用されます。

- 二項確率式とは何ですか?
二項確率分布は、それぞれがπ(pi)の発生確率を持つ、独立したイベントのN回の試行のうちの成功の可能性のある数のそれぞれの確率を考慮に入れます。 二項確率分布の式は次のとおりです。
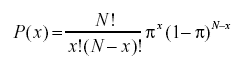
- 単変量、二変量、および多変量解析の違いは何ですか?
単変量分析とは、特定の時点で関係する変数の数に基づいて区別できる記述統計分析手法を指します(たとえば、特定の地域での製品の売上を表す円グラフ)。 これとは対照的に、二変量解析は、散布図のように一度に2つの変数の違いを理解して決定することを目的としています(たとえば、販売量と支出の関係)。
多変量解析には、応答/結果に対する変数の影響を理解するための3つ以上の変数の調査が含まれます。
- 人工ニューラルネットワークとは何ですか?
簡単に言うと、人工ニューラルネットワーク(ANN)は、人間の脳を基に設計されたコンピューティングシステムを指します。 人間の脳と同じように、ANNは、人工ニューロンと呼ばれる多数の単純な処理要素で構成されており、その機能は動物種のニューロンに触発されています。 ANNは経験を通じて学習し、変化する入力に適応できるため、ネットワークは出力基準を再設計することなく、可能な限り最高の結果を生成できます。
- リカレントニューラルネットワーク(RNN)とは何ですか?
リカレントニューラルネットワーク(RNN)は、ノード接続が時間シーケンスに沿った有向グラフを生成し、それによって時間的な動的動作を示す一種の人工ニューラルネットワークです。 RNNを理解するには、最初にフィードフォワードネットの動作を理解する必要があります。 フィードフォワードネットワークは情報を直線的に(同じノードに2回触れることなく)チャネルしますが、リカレントニューラルネットワークは情報をループのようなプロセスで循環させます。 フィードフォワードニューラルネットとは異なり、RNNは内部メモリを使用して入力のシーケンスを処理できます。 したがって、RNNは、手書き認識や音声認識など、セグメント化されていない、または接続されているタスクに最適です。
トップ17データアナリストインタビューの質問と回答
- バックプロパゲーションとは何ですか?
バックプロパゲーションは、多層ニューラルネットワークのトレーニングに使用される教師あり学習アルゴリズムを指します。 バックプロパゲーションにより、エラーをネットワークの端からネットワーク内のすべての重みに移動できるため、勾配を効率的に計算できます。 最急降下法を使用して、重み空間の誤差関数の最小値を探します。 誤差関数を最小化する重みは、学習問題の解決策と見なされます。
- バックプロパゲーションには、次の手順が含まれます。
- トレーニングデータの順方向伝播。
- 出力とターゲットを使用して導関数を計算します。
- エラーの導関数を計算するための逆伝播。
- 以前に計算された導関数を出力に使用します。
- 更新された重み値を計算し、重みを更新します。
- 最急降下法について説明します。
最急降下法を理解するには、最初に最急降下法とは何かを理解する必要があります。 勾配は、入力の小さな変化に関連して、特定の関数の出力がどれだけ変化するかを示す尺度です。 エラーの変化に応じて、すべての重みの変化を測定します。 つまり、勾配は関数の傾きです。
最急降下法は、コスト関数(コスト)を最小化する関数(f)のパラメーター(係数)の値を見つけるのに役立つ最適化アルゴリズムです。 パラメータを分析的に計算できない場合に最適です。
結論
結論として、面接の準備をするための単一または最善の方法はないことを知っておく必要があります。 それはすべてあなたの知識ベース、あなたの自信とアプローチ、そして少しの運についてです。 これらはほんの一握りのデータサイエンスの質問ですが、これにより、データサイエンスのインタビューで尋ねることができる質問の種類について大まかなアイデアが得られることを願っています。 そうは言っても、よく準備して、あなたの努力のために最善を尽くしてください!
世界のトップ大学からデータサイエンスコースを学びましょう。 エグゼクティブPGプログラム、高度な証明書プログラム、または修士プログラムを取得して、キャリアを早急に進めましょう。
データサイエンスのインタビューでは、何ラウンドありますか?
1〜2回のプログラミング面接が必要になる場合がありますが、これは申請する会社によって異なります。 一部の企業は、面接プロセスを最大6ラウンド継続させています。 よくある質問を調べ、最も一般的で難しい質問のリストを作成し、面接の前にそれらの質問を分析することで、各質問に対する回答を準備できます。
データサイエンスのインタビュアーが求める資質は何ですか?
データサイエンスのインタビューに答えるには、算術、統計、プログラミング言語、ビジネスインテリジェンスの基礎、そしてもちろん機械学習の手法について多くのことを知る必要があります。 データ能力が会社の選択や戦略にどのように関連しているかを示すように求められることは間違いありません。 今日の市場では、ほとんどすべてのデータサイエンスの仕事にコーディングインタビューが必要です。 データサイエンティストの役割には、多くの企業でデータパイプラインや機械学習モデルなどの本番コードをリリースすることが含まれます。 この種のプロジェクトでは、強力なプログラミング能力も必要となるため、インタビューではSQLとPythonに関するいくつかの質問も期待できます。
LinkedInを通じてデータサイエンティストの仕事を得ることができますか?
最近のLinkedInの力を見落としてはなりません。 LinkedInは基本的にあなたのデジタル履歴書です。 企業や採用担当者はLinkedInでふさわしい候補者を探し続けているため、印象的なLinkedInプロフィールを作成し、仕事を探し続け、LinkedInで求人に応募することが重要です。 プロファイルに関連するスキルを追加し、すべての専門的な成果を追加し続けます。 このように、LinkedInから価値のあるデータサイエンスの仕事に着手する可能性が高くなります。