
Pytania i odpowiedzi na wywiad z nauką o danych — 15 najczęściej zadawanych pytań
Opublikowany: 2019-07-08Rozmowy kwalifikacyjne są zawsze trudne. Aby skutecznie złamać rozmowę kwalifikacyjną, musisz posiadać nie tylko dogłębną wiedzę przedmiotową, ale także pewność siebie i silną przytomność umysłu. Jest to szczególnie ważne, jeśli przygotowujesz się do nauki o danych — wystawia ona wszystkie twoje zdolności na próbę!
Podczas rozmowy kwalifikacyjnej z dziedziny nauki o danych będziesz musiał stawić czoła wielu pytaniom obejmującym różne tematy, od podstawowych pytań z dziedziny nauki o danych po statystyki, analizę danych, uczenie maszynowe i głębokie uczenie. Ale to nie wszystko – Twoje umiejętności miękkie (komunikacja, praca zespołowa i inne) również zostaną przetestowane.
Aby ułatwić Ci proces przygotowania, przygotowaliśmy listę 15 najczęściej zadawanych pytań do wywiadów Data Science. Zaczniemy od podstaw, a następnie przejdziemy do bardziej zaawansowanych tematów i zagadnień.
Więc bez zbędnych ceregieli zacznijmy!
- Co to jest nauka o danych? Czym różnią się nadzorowane i nienadzorowane uczenie maszynowe?
Mówiąc prościej, Data Science to badanie danych. Obejmuje zbieranie danych z różnych źródeł, przechowywanie ich, czyszczenie i porządkowanie oraz analizowanie w celu wydobycia z nich znaczących informacji. Nauka o danych wykorzystuje połączenie matematyki, informatyki statystycznej, uczenia maszynowego, wizualizacji danych, analizy klastrów i modelowania danych. Jego celem jest uzyskanie cennych informacji z surowych danych (zarówno ustrukturyzowanych, jak i nieustrukturyzowanych) oraz wykorzystanie tych spostrzeżeń do pozytywnego wpływania na strategie biznesowe i informatyczne. Takie pomysły mogą pomóc firmom zoptymalizować procesy, zwiększyć produktywność i przychody, usprawnić strategie marketingowe, zwiększyć satysfakcję klientów i wiele więcej.
Nadzorowana i nienadzorowana ML różnią się między sobą pod następującymi względami:
- W nadzorowanej ML dane wejściowe są oznaczone. W nienadzorowanej ML dane wejściowe pozostają nieoznakowane.
- Podczas gdy nadzorowana ML używa uczącego zestawu danych, nienadzorowana ML używa zestawu danych wejściowych.
- Nadzorowana ML jest używana do celów predykcyjnych, podczas gdy nienadzorowana ML jest używana do celów analitycznych.
- Nadzorowana ML umożliwia klasyfikację i regresję. Jednak nienadzorowana ML umożliwia klasyfikację, szacowanie gęstości i redukcję wymiarów.
- Python czy R – co jest lepsze do analizy tekstu?
Jeśli chodzi o analizę tekstu, najbardziej odpowiednią opcją wydaje się Python. Dzieje się tak, ponieważ zawiera bibliotekę Pandas, która zawiera przyjazne dla użytkownika struktury danych i wysokowydajne narzędzia do analizy danych. Ponadto Python jest bardzo wydajny i szybki w przypadku wszelkiego rodzaju zadań związanych z analizą tekstu. Jeśli chodzi o R, najlepiej nadaje się do aplikacji uczenia maszynowego.
- Jakie są obsługiwane typy danych w Pythonie?
Python ma szereg wbudowanych typów danych, w tym:
- Boole'a
- Numeryczne (liczby całkowite, długie, zmiennoprzecinkowe, zespolone)
- Sekwencje (Listy, Ciągi, Bajt, Krotka)
- Zestawy
- Mapowania (słowniki)
- Obiekty plików
- Jakie są różne algorytmy klasyfikacji?
Kluczowymi algorytmami klasyfikacji są klasyfikatory liniowe (regresja logistyczna, klasyfikator Naive Bayes), drzewa decyzyjne, drzewa wzmocnione, las losowy, SVM, estymacja jądra, sieci neuronowe i najbliższy sąsiad.
- Co to jest rozkład normalny?
Zwykle dane są dystrybuowane na różne sposoby, z odchyleniem w lewo lub w prawo, lub w niektórych przypadkach mogą się pomieszać. Mogą jednak wystąpić sytuacje, w których dane są rozmieszczone wokół wartości centralnej bez odchylenia w lewo lub w prawo, uzyskując w ten sposób rozkład normalny w postaci krzywej w kształcie dzwonu.
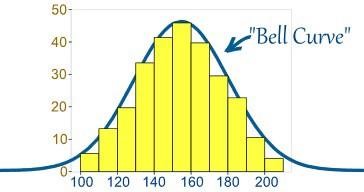
Źródło
Krzywa przedstawia rozkład zmiennych losowych w postaci symetrycznej krzywej w kształcie dzwonu.
- Jakie jest znaczenie testów A/B?
Testy A/B to statystyczna hipoteza testująca eksperymenty losowe z udziałem dwóch zmiennych – A i B. Testy A/B pomagają zidentyfikować wszelkie zmiany lub modyfikacje wprowadzone na stronie internetowej, aby zmaksymalizować wynik zainteresowania. To doskonały sposób na określenie najlepszych strategii promocyjnych i marketingowych online dla firm.
- Co to jest błąd selekcji?
Błąd selekcji to „aktywny” błąd, który pojawia się, gdy badacz decyduje o próbkach, które będą badane. W tym przypadku dane z próby są zbierane i przygotowywane do modelowania danych, ale noszą takie cechy, które nie są prawdziwym reprezentatywnym dla przyszłej populacji przypadków, które będzie brane pod uwagę przez model. Błąd selekcji ma miejsce, gdy podzbiór danych próbki jest systematycznie wybierany i włączany/wyłączany z analizy danych. Istnieją trzy różne rodzaje stronniczości wyboru:
- Błąd próbkowania: błąd systematyczny, który występuje, gdy nielosowa próba zbioru danych powoduje, że niektóre elementy zbioru danych są mniej prawdopodobne, że zostaną uwzględnione w badaniu, co prowadzi do próby stronniczej.
- Przedział czasu: Występuje, gdy próba analizy danych kończy się przedwcześnie przy wartości ekstremalnej. Jednak wartość ekstremalną może osiągnąć z większym prawdopodobieństwem zmienna o największej wariancji (nawet jeśli wszystkie zmienne mają zbliżoną średnią).
- Attrition: Występuje z powodu dyskontowania attrition lub utraty uczestników podczas próby, która została zakończona przed zakończeniem.
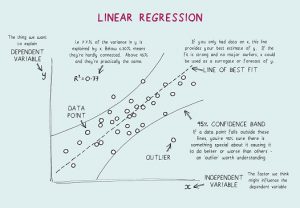
- Co to jest regresja liniowa? Jakie są założenia wymagane do regresji liniowej?
Regresja liniowa to narzędzie statystyczne używane do analizy predykcyjnej. W tej metodzie wynik zmiennej (powiedzmy Y) jest przewidywany na podstawie wyniku innej zmiennej (powiedzmy X). Tutaj Y jest zmienną kryterium, podczas gdy X jest zmienną predykcyjną.
W regresji liniowej istnieją cztery podstawowe założenia:
- Między zmiennymi zależnymi a regresorami istnieje zależność liniowa. Tak więc utworzony model danych będzie zsynchronizowany z danymi.
- Resztki danych są od siebie niezależne i podlegają dystrybucji.
- Między zmiennymi objaśniającymi występuje minimalna wielokolinearność.
- Istnieje „homoskedastyczność”, co oznacza, że wariancja wokół linii regresji jest taka sama dla wszystkich wartości zmiennej predykcyjnej.
- Co to jest walidacja krzyżowa?
Walidacja krzyżowa to procedura walidacji modelu stosowana do. Celem jest tutaj określenie zestawu danych walidacyjnych w celu przetestowania modelu w fazie uczenia, aby ograniczyć problemy, takie jak nadmierne dopasowanie, i oczywiście określić, w jaki sposób model uogólni się na niezależny zestaw danych.
Walidacja krzyżowa (CV) to technika walidacji modeli wykorzystywana do testowania skuteczności modeli uczenia maszynowego. Jest to również metoda ponownego próbkowania stosowana do oceny modelu w przypadku ograniczonych danych. W metodzie walidacji krzyżowej część danych jest odkładana na bok do testowania i walidacji i służy do określenia, w jaki sposób wyniki analizy statystycznej uogólnią się na niezależny zbiór danych.

- Co to jest dwumianowy wzór prawdopodobieństwa?
Dwumianowy rozkład prawdopodobieństwa uwzględnia prawdopodobieństwa każdej z możliwych liczb sukcesów z N liczby prób dla niezależnych zdarzeń, z których każda ma prawdopodobieństwo wystąpienia π (pi). Wzór na dwumianowy rozkład prawdopodobieństwa to:
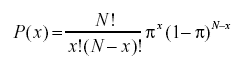
- Jaka jest różnica w analizie jednowymiarowej, dwuwymiarowej i wielowymiarowej?
Analiza jednowymiarowa odnosi się do opisowej techniki analizy statystycznej, którą można zróżnicować na podstawie liczby zmiennych zaangażowanych w danym momencie (na przykład wykresy kołowe przedstawiające sprzedaż produktu na określonym terytorium). W przeciwieństwie do tego, analiza dwuwymiarowa ma na celu zrozumienie i określenie różnicy między dwiema zmiennymi jednocześnie, jak na wykresie rozrzutu (na przykład związek między wielkością sprzedaży a wydatkami).
Analiza wielowymiarowa obejmuje badanie więcej niż dwóch zmiennych w celu zrozumienia wpływu zmiennych na odpowiedzi/wyniki.
- Czym są sztuczne sieci neuronowe?
Mówiąc prościej, sztuczne sieci neuronowe (ANN) odnoszą się do systemu komputerowego zaprojektowanego na podstawie ludzkiego mózgu. Podobnie jak ludzki mózg, SSN składają się z wielu prostych elementów przetwarzających, znanych jako sztuczne neurony, których funkcjonalność jest inspirowana neuronami gatunków zwierząt. Sieci SSN mogą uczyć się poprzez doświadczenie i dostosowywać się do zmieniających się danych wejściowych, dzięki czemu sieć może generować najlepsze możliwe wyniki bez konieczności przeprojektowywania kryteriów wyjściowych.
- Co to są rekurencyjne sieci neuronowe (RNN)?
Rekurencyjna sieć neuronowa (RNN) to rodzaj sztucznej sieci neuronowej, w której połączenia węzłowe tworzą skierowany graf wzdłuż sekwencji czasowej, tym samym wykazując dynamiczne zachowanie czasowe. Aby zrozumieć RNN, musisz najpierw zrozumieć działanie sieci ze sprzężeniem do przodu. Podczas gdy sieci ze sprzężeniem do przodu kierują informacje w linii prostej (bez dwukrotnego dotykania tego samego węzła), rekurencyjne sieci neuronowe przetwarzają informacje w sposób przypominający pętlę. W przeciwieństwie do sieci neuronowych ze sprzężeniem do przodu, RNN mogą wykorzystywać swoją pamięć wewnętrzną do przetwarzania sekwencji danych wejściowych. Dlatego RNN najlepiej nadają się do zadań, które są niesegmentowane lub połączone, takich jak rozpoznawanie pisma ręcznego i rozpoznawanie mowy.
Top 17 pytań i odpowiedzi podczas wywiadu z analitykiem danych
- Co to jest propagacja wsteczna?
Propagacja wsteczna odnosi się do nadzorowanego algorytmu uczenia, który jest używany do uczenia wielowarstwowych sieci neuronowych. Poprzez wsteczną propagację błędu można przenieść błąd z końca sieci na wszystkie wagi w sieci, umożliwiając w ten sposób wydajne obliczenie gradientu. Poszukuje minimalnej wartości funkcji błędu w przestrzeni wagowej przy użyciu techniki gradientu. Wagi, które minimalizują funkcję błędu, są uważane za rozwiązanie problemu uczenia się.
- Propagacja wsteczna obejmowała następujące kroki:
- Propagacja danych treningowych do przodu.
- Oblicz pochodne na podstawie wyników i celu.
- Wstecz Propaguj do obliczania pochodnej błędu.
- Użyj wcześniej obliczonych pochodnych do wyjścia.
- Obliczanie zaktualizowanej wartości wagi i aktualizowanie wag.
- Wyjaśnij opadanie gradientowe.
Aby zrozumieć opadanie gradientowe, musisz najpierw zrozumieć, czym jest gradient. Gradient jest miarą tego, jak bardzo zmienia się wyjście danej funkcji w stosunku do niewielkiej zmiany wejść. Mierzy zmianę wszystkich wag w odpowiedzi na zmianę błędu. Innymi słowy, gradient jest nachyleniem funkcji.
Gradient descent to algorytm optymalizacji, który pomaga znaleźć wartości parametrów (współczynników) funkcji (f) minimalizującej funkcję kosztu (koszt). Najlepiej sprawdza się w przypadkach, gdy parametrów nie można obliczyć analitycznie.
Wniosek
Podsumowując, musisz wiedzieć, że nie ma jednego ani najlepszego sposobu przygotowania się do rozmowy kwalifikacyjnej. Wszystko zależy od Twojej bazy wiedzy, pewności siebie i podejścia oraz odrobiny szczęścia. Chociaż jest to tylko garstka pytań dotyczących Data Science, mamy nadzieję, że daje to ogólne pojęcie o rodzaju pytań, które można zadać podczas wywiadu Data Science. To powiedziawszy, przygotuj się dobrze i wszystkiego najlepszego dla swoich przedsięwzięć!
Ucz się kursów nauki o danych z najlepszych światowych uniwersytetów. Zdobywaj programy Executive PG, Advanced Certificate Programs lub Masters Programs, aby przyspieszyć swoją karierę.
Ile rund jest w wywiadzie dotyczącym nauki o danych?
Może być wymagana jedna lub dwie tury rozmów kwalifikacyjnych z zakresu programowania, ale jest to całkowicie zależne od firmy, do której aplikujesz. Niektóre firmy sprawiają, że rozmowa kwalifikacyjna trwa do sześciu rund. Możesz przygotować swoje odpowiedzi na każde pytanie, badając najczęściej zadawane pytania, sporządzając listę najczęstszych i najtrudniejszych pytań, a następnie analizując je przed rozmową kwalifikacyjną.
Jakich cech poszukują ankieterzy zajmujący się badaniem danych?
Aby odnieść sukces w rozmowie kwalifikacyjnej na temat analizy danych, musisz dużo wiedzieć o arytmetyce, statystyce, językach programowania, podstawach analizy biznesowej i, oczywiście, technikach uczenia maszynowego. Z pewnością zostaniesz poproszony o zademonstrowanie, w jaki sposób Twoje umiejętności związane z danymi odnoszą się do wyborów i strategii firmy. Na dzisiejszym rynku prawie każda praca związana z analityką danych wymaga rozmowy o programowaniu. Rola naukowców zajmujących się danymi obejmuje udostępnianie kodu produkcyjnego, takiego jak potoki danych i modele uczenia maszynowego, w wielu firmach. W przypadku projektów tego rodzaju wymagane są również silne umiejętności programistyczne, więc podczas rozmowy możesz spodziewać się również pytań dotyczących SQL i Pythona.
Czy mogę otrzymać pracę naukowca danych za pośrednictwem LinkedIn?
Nie należy zapominać o sile LinkedIn w dzisiejszych czasach. LinkedIn to w zasadzie Twoje cyfrowe CV. Firmy i rekruterzy wciąż szukają zasłużonych kandydatów na LinkedIn, dlatego ważne jest, abyś zbudował imponujący profil na LinkedIn, nadal szukał pracy i aplikował na oferty pracy na LinkedIn. Dodaj odpowiednie umiejętności do swojego profilu i kontynuuj dodawanie wszystkich swoich osiągnięć zawodowych. W ten sposób masz wysokie szanse na znalezienie zasłużonej pracy w dziedzinie analityki danych na LinkedIn.