
Architecture CNN de base : explication des 5 couches du réseau neuronal convolutif
Publié: 2020-12-07Table des matières
introduction
Au cours des dernières années de l'industrie informatique, il y a eu une énorme demande pour un ensemble de compétences autrefois particulier connu sous le nom d'apprentissage en profondeur. Deep Learning un sous-ensemble de Machine Learning qui consiste en des algorithmes inspirés du fonctionnement du cerveau humain ou des réseaux de neurones.
Ces structures sont appelées réseaux de neurones. Il apprend à l'ordinateur à faire ce qui vient naturellement aux humains. Apprentissage profond, il existe plusieurs types de modèles tels que les réseaux de neurones artificiels (ANN), les auto-encodeurs, les réseaux de neurones récurrents (RNN) et l'apprentissage par renforcement. Mais il y a eu un modèle particulier qui a beaucoup contribué dans le domaine de la vision par ordinateur et de l'analyse d'images, à savoir les réseaux de neurones convolutifs (CNN) ou les ConvNets.
Les CNN sont une classe de réseaux de neurones profonds capables de reconnaître et de classer des caractéristiques particulières à partir d'images et sont largement utilisés pour analyser des images visuelles. Leurs applications vont de la reconnaissance d'images et de vidéos, à la classification d'images, à l'analyse d'images médicales, à la vision par ordinateur et au traitement du langage naturel.
Le terme "convolution" dans CNN désigne la fonction mathématique de convolution qui est un type spécial d'opération linéaire dans laquelle deux fonctions sont multipliées pour produire une troisième fonction qui exprime comment la forme d'une fonction est modifiée par l'autre. En termes simples, deux images qui peuvent être représentées sous forme de matrices sont multipliées pour donner une sortie qui est utilisée pour extraire des caractéristiques de l'image.
Apprenez l'apprentissage automatique en ligne dans les meilleures universités du monde - Masters, programmes de troisième cycle pour cadres et programme de certificat avancé en ML et IA pour accélérer votre carrière.
Apprendre : Introduction à l'apprentissage en profondeur et aux réseaux de neurones

Architecture de base
Il y a deux parties principales dans une architecture CNN
- Un outil de convolution qui sépare et identifie les différentes caractéristiques de l'image pour analyse dans un processus appelé Extraction de caractéristiques
- Une couche entièrement connectée qui utilise la sortie du processus de convolution et prédit la classe de l'image en fonction des caractéristiques extraites aux étapes précédentes.
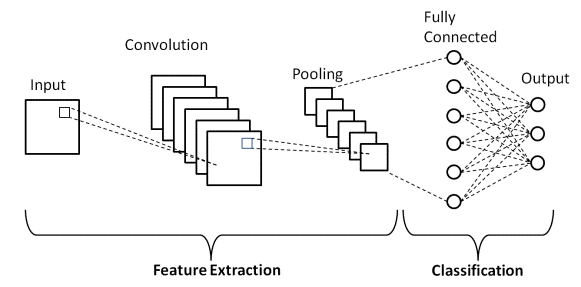
La source
Couches de convolution
Il existe trois types de couches qui composent le CNN, à savoir les couches convolutionnelles, les couches de regroupement et les couches entièrement connectées (FC). Lorsque ces couches sont empilées, une architecture CNN sera formée. En plus de ces trois couches, il existe deux paramètres plus importants qui sont la couche de décrochage et la fonction d'activation qui sont définis ci-dessous.
1. Couche convolutive
Cette couche est la première couche utilisée pour extraire les différentes caractéristiques des images d'entrée. Dans cette couche, l'opération mathématique de convolution est effectuée entre l'image d'entrée et un filtre d'une taille particulière MxM. En faisant glisser le filtre sur l'image d'entrée, le produit scalaire est pris entre le filtre et les parties de l'image d'entrée par rapport à la taille du filtre (MxM).
La sortie est appelée la carte des fonctionnalités qui nous donne des informations sur l'image telles que les coins et les bords. Plus tard, cette carte de caractéristiques est transmise à d'autres couches pour apprendre plusieurs autres caractéristiques de l'image d'entrée.
2. Couche de mise en commun
Dans la plupart des cas, une couche convolutive est suivie d'une couche de regroupement. L'objectif principal de cette couche est de réduire la taille de la carte d'entités convoluées afin de réduire les coûts de calcul. Ceci est effectué en diminuant les connexions entre les couches et fonctionne indépendamment sur chaque carte d'entités. Selon la méthode utilisée, il existe plusieurs types d'opérations de regroupement.
Dans Max Pooling, le plus grand élément est extrait de la carte des fonctionnalités. La mise en commun moyenne calcule la moyenne des éléments dans une section d'image de taille prédéfinie. La somme totale des éléments de la section prédéfinie est calculée dans Sum Pooling. La couche de regroupement sert généralement de pont entre la couche convolutive et la couche FC
Doit lire : Idées de projets de réseau de neurones
3. Couche entièrement connectée
La couche entièrement connectée (FC) comprend les poids et les biais ainsi que les neurones et est utilisée pour connecter les neurones entre deux couches différentes. Ces couches sont généralement placées avant la couche de sortie et forment les dernières couches d'une architecture CNN.
Dans ce cas, l'image d'entrée des couches précédentes est aplatie et transmise à la couche FC. Le vecteur aplati subit ensuite quelques couches FC supplémentaires où les opérations des fonctions mathématiques ont généralement lieu. À ce stade, le processus de classification commence à avoir lieu.
4. Abandon
Habituellement, lorsque toutes les fonctionnalités sont connectées à la couche FC, cela peut entraîner un surajustement dans l'ensemble de données d'entraînement. Le surajustement se produit lorsqu'un modèle particulier fonctionne si bien sur les données d'apprentissage, ce qui a un impact négatif sur les performances du modèle lorsqu'il est utilisé sur de nouvelles données.
Pour surmonter ce problème, une couche de suppression est utilisée dans laquelle quelques neurones sont supprimés du réseau neuronal pendant le processus de formation, ce qui réduit la taille du modèle. Au passage d'un abandon de 0,3, 30 % des nœuds sont abandonnés au hasard du réseau de neurones.
5. Fonctions d'activation
Enfin, l'un des paramètres les plus importants du modèle CNN est la fonction d'activation. Ils sont utilisés pour apprendre et approximer tout type de relation continue et complexe entre les variables du réseau. En termes simples, il décide quelles informations du modèle doivent être déclenchées dans le sens direct et lesquelles ne doivent pas se déclencher à la fin du réseau.

Il ajoute de la non-linéarité au réseau. Il existe plusieurs fonctions d'activation couramment utilisées telles que les fonctions ReLU, Softmax, tanH et Sigmoid. Chacune de ces fonctions a un usage spécifique. Pour un modèle CNN de classification binaire, les fonctions sigmoïdes et softmax sont préférées et pour une classification multi-classes, nous utilisons généralement softmax.
Architecture CNN LeNet-5
En 1998, l'architecture LeNet-5 a été introduite dans un document de recherche intitulé "Apprentissage basé sur le gradient appliqué à la reconnaissance de documents" par Yann LeCun, Leon Bottou, Yoshua Bengio et Patrick Haffner. C'est l'une des architectures CNN les plus anciennes et les plus élémentaires.
Il se compose de 7 couches. La première couche est constituée d'une image d'entrée de dimensions 32×32. Il est convolué avec 6 filtres de taille 5×5 résultant en une dimension de 28x28x6. La deuxième couche est une opération de mise en commun qui filtre la taille 2 × 2 et la foulée de 2. Par conséquent, la dimension de l'image résultante sera de 14x14x6.
De même, la troisième couche implique également une opération de convolution avec 16 filtres de taille 5 × 5 suivis d'une quatrième couche de regroupement avec une taille de filtre similaire de 2 × 2 et une foulée de 2. Ainsi, la dimension de l'image résultante sera réduite à 5x5x16.
Une fois la dimension de l'image réduite, la cinquième couche est une couche convolutive entièrement connectée avec 120 filtres chacun de taille 5 × 5. Dans cette couche, chacune des 120 unités de cette couche sera connectée aux 400 (5x5x16) unités des couches précédentes. La sixième couche est également une couche entièrement connectée avec 84 unités.
La septième couche finale sera une couche de sortie softmax avec 'n' classes possibles en fonction du nombre de classes dans l'ensemble de données.
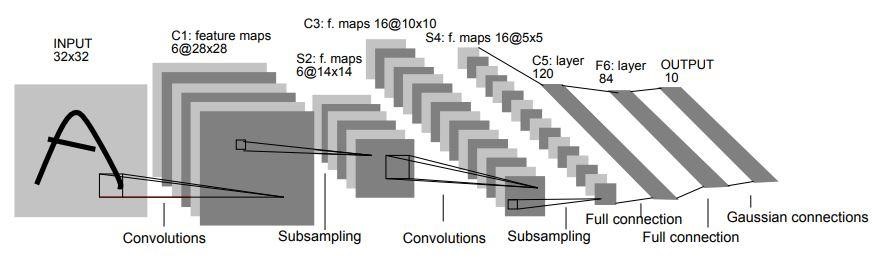
La source
Le diagramme ci-dessus est une représentation des 7 couches de l'architecture LeNet-5 CNN.
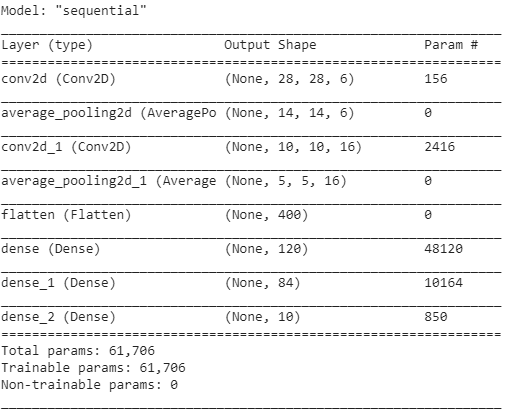
Vous trouverez ci-dessous les instantanés du code Python pour créer une architecture LeNet-5 CNN à l'aide de la bibliothèque keras avec le framework TensorFlow.

Dans la programmation Python, le type de modèle le plus couramment utilisé est le type séquentiel. C'est le moyen le plus simple de créer un modèle CNN en keras. Cela nous permet de construire un modèle couche par couche. La fonction 'add()' est utilisée pour ajouter des couches au modèle. Comme expliqué ci-dessus, pour l'architecture LeNet-5, il existe deux paires Convolution et Pooling suivies d'une couche Flatten qui est généralement utilisée comme connexion entre Convolution et les couches Dense.
Les couches denses sont celles qui sont principalement utilisées pour les couches de sortie. L'activation utilisée est le 'Softmax' qui donne une probabilité pour chaque classe et ils se résument totalement à 1. Le modèle fera sa prédiction en fonction de la classe avec la probabilité la plus élevée.
Le résumé du modèle est affiché comme ci-dessous.
Conclusion
Par conséquent, dans cet article, nous avons compris la structure de base de CNN, son architecture et les différentes couches qui composent le modèle CNN. De plus, nous avons vu un exemple architectural d'un modèle LeNet-5 très célèbre et traditionnel avec son programme Python.
Si vous souhaitez en savoir plus sur les cours d'apprentissage automatique, consultez le programme Executive PG d'IIIT-B & upGrad en apprentissage automatique et IA , conçu pour les professionnels en activité et offrant plus de 450 heures de formation rigoureuse, plus de 30 études de cas et missions, Statut d'ancien de l'IIIT-B, plus de 5 projets de synthèse pratiques et aide à l'emploi avec les meilleures entreprises.
Que sont les fonctions d'activation dans CNN ?
La fonction d'activation est l'un des composants les plus vitaux du modèle CNN. Ils sont utilisés pour apprendre et se rapprocher de toute forme d'association de variable à variable de réseau qui est à la fois continue et complexe. En termes simples, il détermine quelles informations de modèle doivent circuler dans le sens aller et lesquelles ne doivent pas circuler à l'extrémité du réseau. Cela donne au réseau une non-linéarité. Les fonctions ReLU, Softmax, tanH et Sigmoid sont parmi les fonctions d'activation les plus souvent utilisées. Toutes ces fonctions ont des utilisations distinctes. Pour un modèle CNN à 2 classes, les fonctions sigmoïdes et softmax sont privilégiées, tandis que softmax est généralement utilisé pour la classification multi-classes.
Quels sont les composants de base de l'architecture des réseaux de neurones convolutifs ?
Une couche d'entrée, une couche de sortie et plusieurs couches cachées constituent des réseaux convolutionnels. Les neurones des couches d'un réseau convolutif sont disposés en trois dimensions, contrairement à ceux d'un réseau de neurones standard (largeur, hauteur et profondeur). Cela permet au CNN de convertir un volume d'entrée tridimensionnel en un volume de sortie. Les couches de convolution, de regroupement, de normalisation et entièrement connectées constituent les couches cachées. Plusieurs couches de conversion sont utilisées dans les CNN pour filtrer les volumes d'entrée vers des niveaux d'abstraction plus élevés.
Quel est l'avantage des architectures CNN standard ?
Alors que les architectures de réseau traditionnelles se composaient uniquement de couches convolutives empilées, les architectures plus récentes étudient de nouvelles façons de construire des couches convolutives afin d'améliorer l'efficacité de l'apprentissage. Ces architectures fournissent des recommandations architecturales générales que les praticiens de l'apprentissage automatique peuvent adapter afin de gérer une variété de problèmes de vision par ordinateur. Ces architectures peuvent être utilisées comme extracteurs de fonctionnalités riches pour la classification d'images, l'identification d'objets, la segmentation d'images et une variété d'autres tâches avancées.