
Clasificación en estructura de datos: categorías y tipos [con ejemplos]
Publicado: 2020-05-28La disposición de los datos en un orden preferido se denomina clasificación en la estructura de datos. Al ordenar los datos, es más fácil buscarlos rápida y fácilmente. El ejemplo más simple de clasificación es un diccionario. Antes de la era de Internet, cuando querías buscar una palabra en un diccionario, lo hacías en orden alfabético. Esto lo hizo fácil.
¡Imagínate el pánico si tuvieras que pasar por un libro grande con todas las palabras en inglés del mundo en un orden desordenado! Es el mismo pánico por el que pasará un ingeniero si sus datos no están ordenados y estructurados.
Entonces, en resumen, la clasificación nos hace la vida más fácil. Consulte nuestros cursos de ciencia de datos para aprender en profundidad sobre los algoritmos de ciencia de datos.
En esta publicación, lo guiaremos a través de las diferentes estructuras de datos y algoritmos de clasificación. Pero primero, comprendamos qué es un algoritmo de clasificación y clasificación en la estructura de datos.
Tabla de contenido
¿Qué es un algoritmo de clasificación?
Un algoritmo de clasificación es solo una serie de órdenes o instrucciones. En esto, una matriz es una entrada en la que el algoritmo de clasificación realiza operaciones para dar una matriz ordenada.
Muchos niños habrían aprendido a clasificar estructuras de datos en sus clases de informática. Se presenta en una etapa temprana para ayudar a los niños interesados a tener una idea de temas informáticos más profundos: métodos de divide y vencerás, árboles binarios, montones, etc.
He aquí un ejemplo de lo que hace la clasificación.
Supongamos que tiene una matriz de cadenas: [h,j,k,i,n,m,o,l]
Ahora, la clasificación produciría una matriz de salida en orden alfabético.
Salida: [h,i,j,k,l,m,n,o]
Aprendamos más sobre la clasificación en la estructura de datos.
Pago: Tipos de árbol binario
Clasificación de categorías
Hay dos categorías diferentes en la clasificación:
- Clasificación interna : si los datos de entrada son tales que se pueden ajustar en la memoria principal a la vez, se denomina clasificación interna.
- Clasificación externa : si los datos de entrada son tales que no se pueden ajustar en la memoria por completo a la vez, es necesario almacenarlos en un disco duro, disquete o cualquier otro dispositivo de almacenamiento. Esto se llama clasificación externa.
Leer: Temas e ideas de proyectos de estructura de datos interesantes
Tipos de clasificación en la estructura de datos
Estos son algunos de los tipos más comunes de algoritmos de clasificación.
1. Clasificación por fusión
Este algoritmo funciona al dividir una matriz en dos mitades de tamaños comparables. Luego, cada mitad se ordena y se fusiona nuevamente utilizando la función merge ().
Así es como funciona el algoritmo:
MergeSort(arr[], l, r)
Si r > l
- Divida la matriz en dos mitades iguales ubicando el punto medio:
medio m = (l+r)/2
- Use la función mergeSort para llamar a la primera mitad:
Llame a mergeSort(arr, l, m)
- Llame a mergeSort para la segunda mitad:
Llame a mergeSort(arr, m+1, r)
- Use la función merge () para fusionar las dos mitades ordenadas en los pasos 2 y 3:
Combinar llamadas (arr, l, m, r)
Echa un vistazo a la imagen de abajo para tener una idea clara de cómo funciona esto.
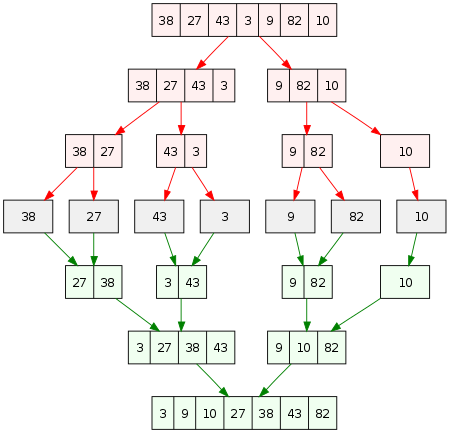
Fuente
Programa de Python para la implementación de clasificación por fusión
def mergeSort(a):
si len(a) >1:
medio = largo(a)//2
A = a[:medio]
B = un[medio:]
Combinar Ordenar (A)
Combinar Ordenar (B)
yo = j = k = 0
mientras que i < len(A) y j < len(B):
si A[i] < B[j]:
a[k] = A[i]
i+=1
demás:
a[k] = B[j]
j+=1
k+=1
mientras yo < len(A):
a[k] = A[i]
i+=1
k+=1
mientras que j < len(R):
a[k] = B[j]
j+=1
k+=1
def imprimirLista(a):
para i en el rango (len (a)):
imprimir(a[i],fin=” “)
imprimir()
si __nombre__ == '__principal__':
a = [12, 11, 13, 5, 6, 7]
mergeSort(a)
print(“La matriz ordenada es: “, end=”\n”)
imprimirLista(a)
Más información: Recursividad en la estructura de datos: cómo funciona, tipos y cuándo se usa
2. Clasificación de selección
En este, en un primer momento, el elemento más pequeño se envía a la primera posición.
Luego, el siguiente elemento más pequeño se busca en la matriz restante y se coloca en la segunda posición. Esto continúa hasta que el algoritmo llega al elemento final y lo coloca en la posición correcta.
Mira la imagen de abajo para entenderlo mejor.
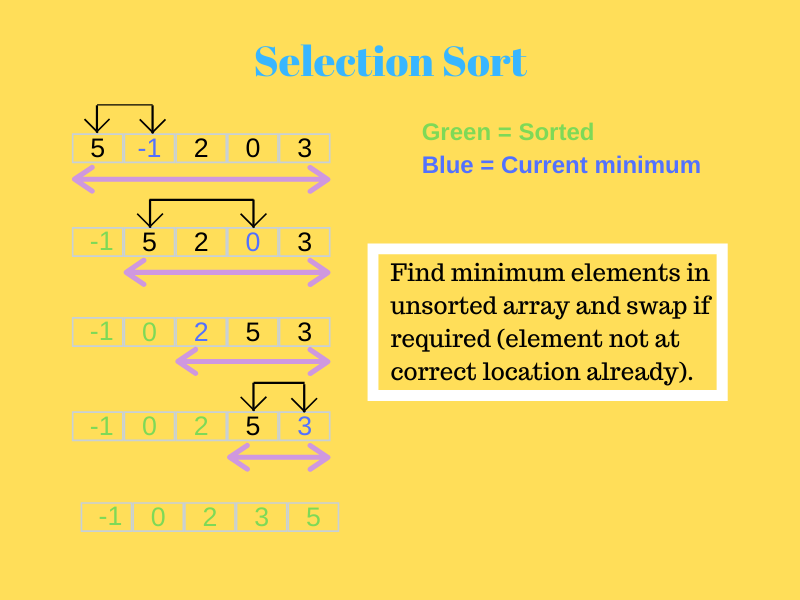 Fuente
Fuente
Programa de Python para la implementación del ordenamiento por selección
sistema de importación
X = [6, 25, 10, 28, 11]
para i en el rango (len (X)):
min_idx = yo
para j en rango(i+1, len(X)):
si X[min_idx] > X[j]:
min_idx = j
X[i], X[min_idx] = X[min_idx], X[i]
imprimir ("La matriz ordenada es")
para i en el rango (len (X)):
imprimir(“%d” %X[i]),
Certificación avanzada de ciencia de datos, más de 250 socios de contratación, más de 300 horas de aprendizaje, 0 % de EMI

3. Clasificación de burbujas
Es el más fácil y simple de todos los algoritmos de clasificación. Funciona según el principio de intercambiar repetidamente elementos adyacentes en caso de que no estén en el orden correcto.
En términos más simples, si la entrada se ordenará en orden ascendente, la ordenación de burbujas primero comparará los dos primeros elementos de la matriz. En caso de que el segundo sea más pequeño que el primero, intercambiará los dos y pasará al siguiente elemento, y así sucesivamente.
Ejemplo :
Entrada : 637124
Primer pase
63 7124 -> 36 7124 : Bubble sort compara 6 y 3 y los intercambia porque 3<6.
3 67 124 -> 3 67 124 : Desde 6<7, sin intercambio
36 71 24 -> 36 17 24 : Intercambiado 7 y 1, como 7>1
361 72 4 -> 361 27 4 : Intercambiado 2 y 7, como 2<7
3612 74 -> 3612 47 : 4 y 7 intercambiados, como 4<7
Segundo pase
36 1247 -> 36 1247
3 61 274 -> 3 16 274
31 62 74 -> 31 26 74
312 67 4 -> 312 67 4
3126 74 -> 3126 47
Tercer pase
31 2647 -> 13 2647
1 32 647 -> 1 23 647
12 36 47 -> 12 36 47
123 64 7 -> 123 46 7
1234 67 -> 1234 67
Como puede ver, obtenemos el resultado en orden ascendente después de tres pasadas.
Programa de Python para la implementación de clasificación de burbujas
def bubbleSort(a):
n = largo(a)
para i en el rango (n):
para j en el rango (0, ni-1):
si a[j] > a[j+1] :
a[j], a[j+1] = a[j+1], a[j]
a = [64, 34, 25, 12, 22, 11, 90]
clasificación de burbujas(a)
imprimir ("La matriz ordenada es:")
para i en el rango (len (a)):
imprimir (“%d” %a[i]),
Lea también: Marcos de datos en Python: Tutorial detallado de Python
Conclusión
Eso concluye la clasificación en la estructura de datos y los algoritmos de clasificación más comunes. Puede elegir cualquiera de los diferentes tipos de algoritmos de clasificación. Sin embargo, recuerde que algunos de estos pueden ser un poco tediosos para escribir el programa. Pero entonces, pueden ser útiles para obtener resultados rápidos. Por otro lado, si desea ordenar grandes conjuntos de datos, debe elegir el ordenamiento por burbuja. No solo produce resultados precisos, sino que también es fácil de implementar. Por otra parte, es más lento que los otros tipos. Espero que les haya gustado el artículo sobre la clasificación en la estructura de datos.
Para obtener más información sobre cómo funciona la clasificación, comuníquese con nosotros y lo ayudaremos a comenzar con el curso que mejor se adapte a sus necesidades.
Si tiene curiosidad por aprender sobre ciencia de datos, consulte el Programa ejecutivo PG en ciencia de datos de IIIT-B y upGrad, creado para profesionales que trabajan y ofrece más de 10 estudios de casos y proyectos, talleres prácticos, tutoría con expertos de la industria, 1 -on-1 con mentores de la industria, más de 400 horas de aprendizaje y asistencia laboral con las mejores empresas.
¡Diviértete codificando!
¿Qué son Heap Sort y Quick Sort?
Se utilizan diferentes técnicas de clasificación para realizar los procedimientos de clasificación según los requisitos. Por lo general, Quick Sort se usa porque es más rápido, pero uno usaría Heap Sort cuando el uso de la memoria es una preocupación.
Heap Sort es un algoritmo de clasificación basado en la comparación completamente basado en la estructura de datos del montón binario. Esta es la razón por la cual la ordenación del montón puede aprovechar las propiedades del montón. En el algoritmo de clasificación rápida, se utiliza el enfoque Divide-and-Conquer. Aquí, todo el algoritmo se divide en 3 pasos. El primero es elegir un elemento que actúe como elemento pivote. A continuación, los elementos a la izquierda del elemento pivote son los más pequeños y los de la derecha son los más grandes en valor. En cada partición, se repite el paso anterior para ordenar toda la matriz de elementos.
¿Cuál es el algoritmo de clasificación más fácil?
Si está tratando con algoritmos de clasificación, habrá notado que Bubble Sort es el más simple entre todos los demás. La idea básica detrás de este algoritmo es escanear toda la matriz de elementos y comparar cada elemento adyacente. Ahora, la acción de intercambio ocurre solo cuando los elementos no están ordenados.
Con Bubble Sort, solo tiene que comparar los elementos adyacentes y la matriz se ordena. Esta es la razón por la que se considera que es el algoritmo de clasificación más simple.
¿Cuál es el algoritmo de clasificación más rápido en estructuras de datos?
Quicksort se considera el más rápido entre todos los demás algoritmos de clasificación. La complejidad temporal de Quicksort es O(n log n) en el mejor de los casos, O(n log n) en el caso promedio y O(n^2) en el peor de los casos. Se sabe que Quicksort es el algoritmo de clasificación más rápido debido a su mejor rendimiento en todas las entradas de casos promedio. La velocidad también dependerá mucho de la cantidad de datos. Según la comparación entre todos los algoritmos de clasificación, Quicksort es el más rápido debido a sus entradas de casos promedio.