
데이터 구조의 정렬: 범주 및 유형 [예제 포함]
게시 됨: 2020-05-28데이터를 선호하는 순서로 배열하는 것을 데이터 구조에서 정렬이라고 합니다. 데이터를 정렬하여 쉽고 빠르게 검색할 수 있습니다. 정렬의 가장 간단한 예는 사전입니다. 인터넷 시대 이전에는 사전에서 단어를 검색할 때 알파벳 순서로 검색했습니다. 이것은 쉽게 만들었습니다.
세계의 모든 영어 단어가 뒤죽박죽인 큰 책을 읽어야 하는 경우의 공포를 상상해 보십시오! 데이터가 정렬 및 구조화되지 않은 경우 엔지니어가 겪는 것과 동일한 패닉입니다.
간단히 말해서 정렬은 우리의 삶을 더 쉽게 만듭니다. 데이터 과학 알고리즘에 대해 자세히 알아보려면 데이터 과학 과정을 확인하십시오.
이 게시물에서는 다양한 데이터 구조 및 정렬 알고리즘을 살펴보겠습니다. 그러나 먼저 정렬 알고리즘이 무엇이며 데이터 구조에서 정렬하는지 이해합시다.
목차
정렬 알고리즘이란 무엇입니까?
정렬 알고리즘은 일련의 명령 또는 지침일 뿐입니다. 여기에서 배열은 정렬 알고리즘이 정렬된 배열을 제공하는 작업을 수행하는 입력입니다.
많은 아이들은 컴퓨터 과학 수업에서 데이터 구조 정렬을 배웠을 것입니다. 관심 있는 어린이가 분할 정복 방법, 이진 트리, 힙 등과 같은 더 깊은 컴퓨터 과학 주제에 대한 아이디어를 얻을 수 있도록 초기 단계에 도입되었습니다.
다음은 정렬이 수행하는 작업의 예입니다.
문자열 배열이 있다고 가정해 보겠습니다. [h,j,k,i,n,m,o,l]
이제 정렬하면 알파벳순으로 출력 배열이 생성됩니다.
출력: [h,i,j,k,l,m,n,o]
데이터 구조에서 정렬에 대해 자세히 알아보겠습니다.
확인: 이진 트리의 유형
분류 분류
정렬에는 두 가지 범주가 있습니다.
- 내부정렬 : 입력된 데이터가 주메모리에서 한번에 조정될 수 있는 정도인 경우를 내부정렬이라고 한다.
- 외부 정렬 : 입력 데이터가 메모리에서 한번에 완전히 조정될 수 없는 경우에는 하드 디스크, 플로피 디스크 또는 기타 저장 장치에 저장해야 합니다. 이것을 외부 정렬이라고 합니다.
읽기: 흥미로운 데이터 구조 프로젝트 아이디어 및 주제
데이터 구조의 정렬 유형
다음은 정렬 알고리즘의 가장 일반적인 유형 중 몇 가지입니다.
1. 병합 정렬
이 알고리즘은 배열을 비슷한 크기의 반으로 분할하는 데 사용됩니다. 그런 다음 merge() 함수를 사용하여 각 절반을 정렬하고 다시 병합합니다.
알고리즘 작동 방식은 다음과 같습니다.
병합 정렬(arr[], l, r)
만약 r > l
- 중간 지점을 찾아 배열을 두 개의 동일한 반으로 나눕니다.
중간 m = (l+r)/2
- mergeSort 함수를 사용하여 전반부를 호출합니다.
mergeSort(arr, l, m) 호출
- 후반부에 대해 mergeSort를 호출합니다.
mergeSort(arr, m+1, r) 호출
- merge() 함수를 사용하여 2단계와 3단계에서 정렬된 두 개의 반쪽을 병합합니다.
병합 호출(arr, l, m, r)
이것이 어떻게 작동하는지 명확하게 이해하려면 아래 이미지를 확인하십시오.
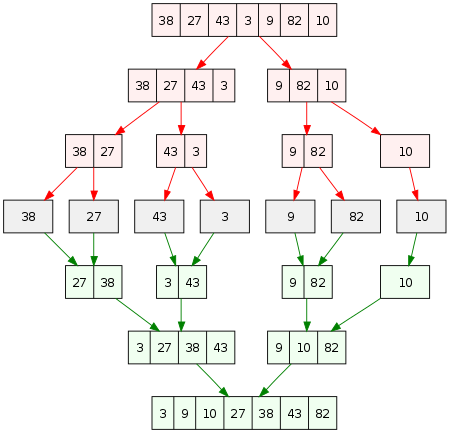
원천
병합 정렬 구현을 위한 Python 프로그램
def mergeSort(a):
len(a) >1인 경우:
중간 = len(a)//2
A = a[:중간]
B = a[중간:]
병합 정렬(A)
병합 정렬(B)
나는 = j = k = 0
i < len(A) 및 j < len(B):
A[i] < B[j]인 경우:
a[k] = A[i]
나는+=1
또 다른:
a[k] = B[j]
j+=1
k+=1
동안 나는 < len(A):
a[k] = A[i]
나는+=1
k+=1
j < len(R):
a[k] = B[j]
j+=1
k+=1
def printList(a):
범위(len(a))의 i에 대해:
print(a[i],end=" ")
인쇄()
__name__ == '__main__'인 경우:
a = [12, 11, 13, 5, 6, 7]
병합 정렬(a)
print("정렬된 배열은 ", end="\n")
인쇄 목록(a)
자세히 알아보기: 데이터 구조의 재귀: 작동 방식, 유형 및 사용 시기
2. 선택 정렬
이 경우 처음에는 가장 작은 요소가 첫 번째 위치로 전송됩니다.
그런 다음 나머지 배열에서 다음으로 작은 요소를 검색하여 두 번째 위치에 배치합니다. 이것은 알고리즘이 최종 요소에 도달하여 올바른 위치에 배치할 때까지 계속됩니다.
아래 그림을 보시면 더 잘 이해가 됩니다.
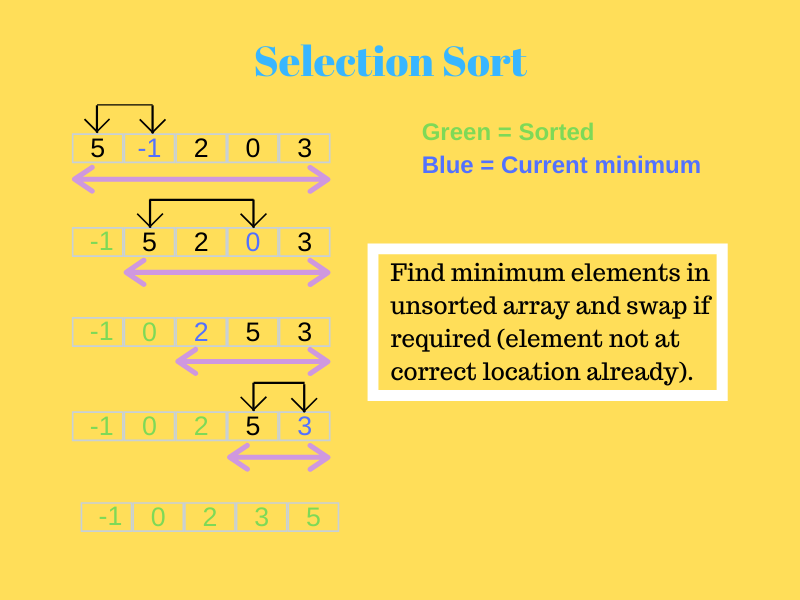 원천
원천
선택 정렬 구현을 위한 Python 프로그램
수입 시스템
X = [6, 25, 10, 28, 11]
범위(len(X))의 i에 대해:
min_idx = 나
범위(i+1, len(X))의 j에 대해:
X[min_idx] > X[j]인 경우:
min_idx = j
X[i], X[min_idx] = X[min_idx], X[i]
print("정렬된 배열은")
범위(len(X))의 i에 대해:
인쇄("%d" %X[i]),
데이터 과학 고급 인증, 250명 이상의 고용 파트너, 300시간 이상의 학습, 0% EMI

3. 버블 정렬
모든 정렬 알고리즘 중에서 가장 쉽고 간단합니다. 인접한 요소가 올바른 순서가 아닌 경우 반복적으로 교환하는 원칙에 따라 작동합니다.
간단히 말해서 입력이 오름차순으로 정렬되는 경우 버블 정렬은 먼저 배열의 처음 두 요소를 비교합니다. 두 번째 항목이 첫 번째 항목보다 작은 경우 두 항목을 교환하고 다음 요소로 이동하는 식으로 진행됩니다.
예 :
입력 : 637124
첫 번째 패스
63 7124 -> 36 7124 : 버블 정렬은 6과 3을 비교하고 3<6이므로 교체합니다.
3 67 124 -> 3 67 124 : 6<7부터 스와핑 없음
36 71 24 -> 36 17 24 : 7과 1을 7>1로 교체
361 72 4 -> 361 27 4 : 2<7로 2와 7을 바꿉니다.
3612 74 -> 3612 47 : 4<7로 4와 7을 바꿉니다.
두 번째 패스
36 1247 -> 36 1247
3 61 274 -> 3 16 274
31 62 74 -> 31 26 74
312 67 4 -> 312 67 4
3126 74 -> 3126 47
세 번째 패스
31 2647 -> 13 2647
1 32 647 -> 1 23 647
12 36 47 -> 12 36 47
123 64 7 -> 123 46 7
1234 67 -> 1234 67
보시다시피 세 번의 패스 후에 오름차순 결과를 얻습니다.
버블 정렬 구현을 위한 Python 프로그램
def bubbleSort(a):
n = 렌(a)
범위(n)의 i에 대해:
범위(0, ni-1)의 j에 대해:
a[j] > a[j+1]인 경우:
에이[j], 에이[j+1] = 에이[j+1], 에이[j]
a = [64, 34, 25, 12, 22, 11, 90]
버블정렬(a)
print("정렬된 배열은:")
범위(len(a))의 i에 대해:
인쇄("%d" %a[i]),
또한 읽기: Python의 데이터 프레임: Python 심층 자습서
결론
이것으로 데이터 구조의 정렬과 가장 일반적인 정렬 알고리즘을 마무리합니다. 다양한 유형의 정렬 알고리즘을 선택할 수 있습니다. 그러나 이들 중 일부는 프로그램을 작성하는 데 약간 지루할 수 있습니다. 그러나 빠른 결과를 얻으려면 유용할 수 있습니다. 반면에 큰 데이터 세트를 정렬하려면 버블 정렬을 선택해야 합니다. 정확한 결과를 얻을 뿐만 아니라 구현하기도 쉽습니다. 다시 말하지만, 다른 유형보다 느립니다. 데이터 구조 정렬에 대한 기사가 마음에 드셨기를 바랍니다.
정렬 작동 방식에 대한 더 많은 통찰력을 얻으려면 당사에 연락하십시오. 귀하의 요구에 가장 적합한 과정을 시작할 수 있도록 도와드리겠습니다!
데이터 과학에 대해 자세히 알아보려면 작업 전문가를 위해 만들어졌으며 10개 이상의 사례 연구 및 프로젝트, 실용적인 실습 워크샵, 업계 전문가와의 멘토링, 1 - 업계 멘토와 일대일, 400시간 이상의 학습 및 최고의 기업과의 취업 지원.
즐거운 코딩하세요!
힙 정렬과 퀵 정렬이란?
요구 사항에 따라 분류 절차를 수행하기 위해 다양한 분류 기술이 사용됩니다. 일반적으로 빠른 정렬이 더 빠르기 때문에 사용되지만 메모리 사용량이 문제인 경우에는 힙 정렬을 사용합니다.
힙 정렬은 완전히 이진 힙 데이터 구조를 기반으로 하는 비교 기반 정렬 알고리즘입니다. 이것이 힙 정렬이 힙의 속성을 이용할 수 있는 이유입니다. 빠른 정렬 알고리즘에서는 분할 정복 방식이 사용됩니다. 여기에서 전체 알고리즘은 3단계로 나뉩니다. 첫 번째는 피벗 요소로 작동하는 요소를 선택하는 것입니다. 다음으로, 피벗 요소의 왼쪽에 있는 요소는 더 작은 요소이고 오른쪽에 있는 요소는 값이 더 큰 요소입니다. 모든 파티션에서 이전 단계를 반복하여 전체 요소 배열을 정렬합니다.
가장 쉬운 정렬 알고리즘은 무엇입니까?
정렬 알고리즘을 다루고 있다면 버블 정렬이 다른 모든 것 중에서 가장 간단한 정렬이라는 것을 알 수 있을 것입니다. 이 알고리즘의 기본 아이디어는 요소의 전체 배열을 스캔하고 모든 인접 요소를 비교하는 것입니다. 이제 스와핑 동작은 요소가 정렬되지 않은 경우에만 발생합니다.
버블 정렬을 사용하면 인접한 요소를 비교하기만 하면 배열이 정렬됩니다. 이것이 이것이 가장 간단한 정렬 알고리즘으로 간주되는 이유입니다.
데이터 구조에서 가장 빠른 정렬 알고리즘은 무엇입니까?
Quicksort는 다른 모든 정렬 알고리즘 중에서 가장 빠른 것으로 간주됩니다. Quicksort의 시간 복잡도는 최상의 경우 O(n log n), 평균의 경우 O(n log n), 최악의 경우 O(n^2)입니다. Quicksort는 모든 평균 케이스 입력에서 최고의 성능을 발휘하기 때문에 가장 빠른 정렬 알고리즘으로 알려져 있습니다. 속도도 데이터의 양에 따라 많이 달라집니다. 모든 정렬 알고리즘 간의 비교에 따르면 Quicksort는 평균 케이스 입력 때문에 가장 빠릅니다.