
数据结构中的排序:类别和类型 [附示例]
已发表: 2020-05-28在数据结构中按优先顺序排列数据称为排序。 通过对数据进行排序,可以更轻松地快速轻松地搜索它。 最简单的排序示例是字典。 在互联网时代之前,当你想在字典中查找一个单词时,你会按照字母顺序进行。 这很容易。
想象一下,如果您必须阅读一本大书,其中包含来自世界各地的所有英语单词,顺序混乱! 如果他们的数据没有排序和结构化,工程师也会经历同样的恐慌。
所以,简而言之,分类让我们的生活更轻松。 查看我们的数据科学课程,深入了解数据科学算法。
在这篇文章中,我们将带您了解不同的数据结构和排序算法。 但首先,让我们了解什么是排序算法以及数据结构中的排序。
目录
什么是排序算法?
排序算法只是一系列命令或指令。 在这种情况下,数组是一个输入,排序算法在其上执行操作以给出一个排序后的数组。
许多孩子会在他们的计算机科学课上学会对数据结构进行排序。 它是在早期引入的,以帮助感兴趣的孩子了解更深层次的计算机科学主题——分而治之的方法、二叉树、堆等。
这是排序的一个示例。
假设您有一个字符串数组: [h,j,k,i,n,m,o,l]
现在,排序将产生一个按字母顺序排列的输出数组。
输出:[h,i,j,k,l,m,n,o]
让我们进一步了解数据结构中的排序。
结帐:二叉树的类型
排序类别
排序有两种不同的类别:
- 内部排序:如果输入的数据可以在主存中立即调整,则称为内部排序。
- 外部排序:如果输入的数据不能一次在内存中完全调整,则需要将其存储在硬盘、软盘或任何其他存储设备中。 这称为外部排序。
阅读:有趣的数据结构项目想法和主题
数据结构中的排序类型
以下是一些最常见的排序算法类型。
1.合并排序
该算法用于将数组拆分为大小相当的两半。 然后使用 merge() 函数对每一半进行排序和合并。
以下是该算法的工作原理:
合并排序(arr[],l,r)
如果 r > l
- 通过定位中点将数组分成相等的两半:
中间 m = (l+r)/2
- 使用 mergeSort 函数调用前半部分:
调用 mergeSort(arr, l, m)
- 后半部分调用mergeSort:
调用 mergeSort(arr, m+1, r)
- 使用 merge() 函数将第 2 步和第 3 步排序的两半合并:
调用合并(arr,l,m,r)
查看下面的图片以清楚地了解其工作原理。
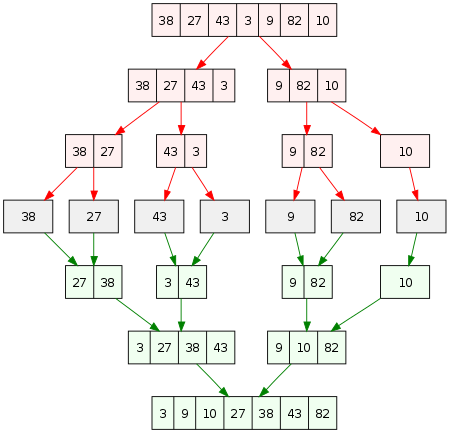
资源
用于合并排序实现的 Python 程序
定义合并排序(一):
如果 len(a) >1:
mid = len(a)//2
A = a[:mid]
B = a[中:]
合并排序(A)
合并排序(B)
我 = j = k = 0
当 i < len(A) 且 j < len(B) 时:
如果 A[i] < B[j]:
a[k] = A[i]
我+=1
别的:
a[k] = B[j]
j+=1
k+=1
当 i < len(A) 时:
a[k] = A[i]
我+=1
k+=1
当 j < len(R) 时:
a[k] = B[j]
j+=1
k+=1
定义打印列表(一):
对于我在范围内(len(a)):
打印(a[i],end="")
打印()
如果 __name__ == '__main__':
a = [12, 11, 13, 5, 6, 7]
合并排序(一)
print("排序后的数组是:", end="\n")
打印列表(一)
了解更多:数据结构中的递归:它的工作原理、类型和使用时间
2.选择排序
在此,首先,最小的元素被发送到第一个位置。
然后,在剩余的数组中搜索下一个最小元素,并将其放置在第二个位置。 这一直持续到算法到达最终元素并将其放置在正确的位置。
请看下面的图片以更好地理解它。
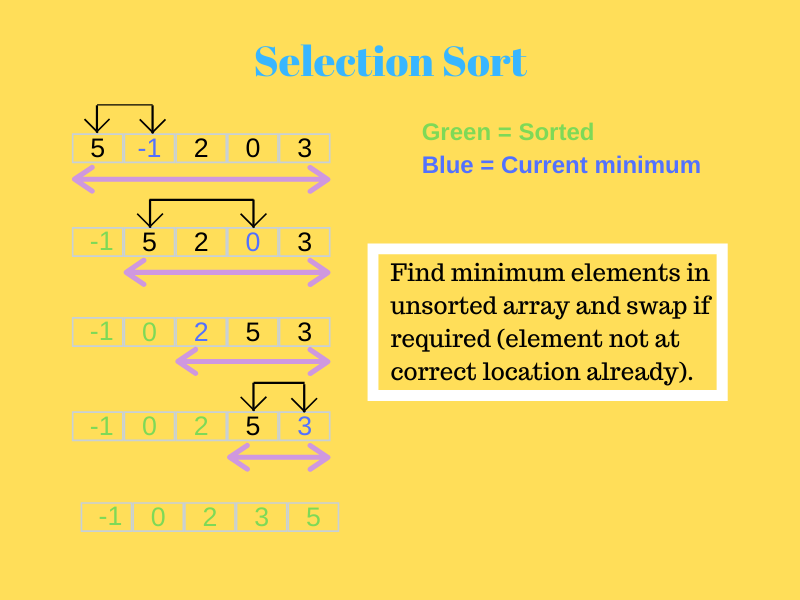 资源
资源
用于选择排序实现的 Python 程序
导入系统
X = [6, 25, 10, 28, 11]
对于我在范围内(len(X)):
min_idx = 我
对于范围内的 j (i+1, len(X)):
如果 X[min_idx] > X[j]:
min_idx = j
X[i], X[min_idx] = X[min_idx], X[i]
print ("排序后的数组是")
对于我在范围内(len(X)):
打印(“%d” %X[i]),
数据科学高级认证、250 多个招聘合作伙伴、300 多个学习小时、0% EMI

3.冒泡排序
它是所有排序算法中最简单、最简单的。 它的工作原理是重复交换相邻元素,以防它们的顺序不正确。
简单来说,如果要对输入进行升序排序,冒泡排序会首先比较数组中的前两个元素。 如果第二个小于第一个,它将交换两个,然后移动到下一个元素,依此类推。
示例:
输入:637124
第一关
63 7124 -> 36 7124 :冒泡排序比较 6 和 3 并交换它们,因为 3<6。
3 67 124 -> 3 67 124 :由于 6<7,没有交换
36 71 24 -> 36 17 24:交换 7 和 1,如 7>1
361 72 4 -> 361 27 4:交换 2 和 7,如 2<7
3612 74 -> 3612 47 :交换 4 和 7,如 4<7
第二遍
36 1247 -> 36 1247
3 61 274 -> 3 16 274
31 62 74 -> 31 26 74
312 67 4 -> 312 67 4
3126 74 -> 3126 47
第三关
31 2647 -> 13 2647
1 32 647 -> 1 23 647
12 36 47 -> 12 36 47
123 64 7 -> 123 46 7
1234 67 -> 1234 67
如您所见,我们在三遍后得到升序结果。
用于冒泡排序实现的 Python 程序
定义气泡排序(a):
n = 长度(一)
对于范围内的 i (n):
对于范围内的 j (0, ni-1):
如果 a[j] > a[j+1] :
a[j], a[j+1] = a[j+1], a[j]
a = [64, 34, 25, 12, 22, 11, 90]
冒泡排序(一)
print (“排序后的数组是:”)
对于我在范围内(len(a)):
打印(“%d”%a[i]),
另请阅读: Python 中的数据帧:Python 深入教程
结论
这包含了数据结构中的排序和最常见的排序算法。 您可以选择任何不同类型的排序算法。 但是,请记住,其中一些在编写程序时可能有点乏味。 但是,它们可能会派上用场以获得快速的结果。 另一方面,如果要对大型数据集进行排序,则必须选择冒泡排序。 它不仅产生准确的结果,而且易于实施。 再说一次,它比其他类型慢。 我希望你喜欢这篇关于数据结构排序的文章。
要深入了解分类的工作原理,请联系我们,我们将帮助您开始学习最适合您需求的课程!
如果您想了解数据科学,请查看 IIIT-B 和 upGrad 的数据科学执行 PG 计划,该计划是为在职专业人士创建的,提供 10 多个案例研究和项目、实用的实践研讨会、行业专家的指导、1与行业导师一对一,400 多个小时的学习和顶级公司的工作协助。
玩得开心编码!
什么是堆排序和快速排序?
根据要求使用不同的分拣技术来执行分拣程序。 通常,使用快速排序是因为它更快,但是当关注内存使用时,人们会使用堆排序。
堆排序是一种完全基于二进制堆数据结构的比较排序算法。 这就是为什么堆排序可以利用堆的属性。 在快速排序算法中,使用了分治法。 在这里,整个算法分为3个步骤。 第一个是选择一个元素作为枢轴元素。 接下来,枢轴元素左侧的元素是较小的元素,右侧是值较大的元素。 在每个分区上,重复上一步以对整个元素数组进行排序。
哪个是最简单的排序算法?
如果您正在处理排序算法,那么您会注意到冒泡排序是所有其他算法中最简单的一种。 该算法背后的基本思想是扫描整个元素数组并比较每个相邻元素。 现在,交换动作仅在元素未排序时发生。
使用冒泡排序,您只需要比较相邻的元素,数组就会被排序。 这就是为什么它被认为是最简单的排序算法。
数据结构中最快的排序算法是什么?
快速排序被认为是所有其他排序算法中最快的一种。 快速排序的时间复杂度在最佳情况下为 O(n log n),在平均情况下为 O(n log n),在最坏情况下为 O(n^2)。 众所周知,快速排序是最快的排序算法,因为它在所有平均案例输入中的性能最佳。 速度也很大程度上取决于数据量。 根据所有排序算法之间的比较,快速排序是最快的,因为它的平均案例输入。