
الفرز في بنية البيانات: الفئات والأنواع [مع أمثلة]
نشرت: 2020-05-28يسمى ترتيب البيانات بالترتيب المفضل الفرز في بنية البيانات. من خلال فرز البيانات ، يسهل البحث فيها بسرعة وسهولة. أبسط مثال على الفرز هو القاموس. قبل عصر الإنترنت ، عندما كنت تريد البحث عن كلمة في قاموس ، كنت تفعل ذلك بترتيب أبجدي. هذا جعل الأمر سهلاً.
تخيل حالة الذعر إذا كان عليك أن تقرأ كتابًا كبيرًا يحتوي على كل الكلمات الإنجليزية من العالم بترتيب مختلط! إنه نفس الذعر الذي يمر به المهندس إذا لم يتم فرز بياناتهم وتنظيمها.
لذا ، باختصار ، الفرز يجعل حياتنا أسهل. تحقق من دورات علوم البيانات الخاصة بنا للتعرف بشكل متعمق على خوارزميات علوم البيانات.
في هذا المنشور ، سنأخذك عبر هياكل البيانات المختلفة وخوارزميات الفرز. لكن أولاً ، دعنا نفهم ما هي خوارزمية الفرز والفرز في بنية البيانات.
جدول المحتويات
ما هي خوارزمية الفرز؟
خوارزمية الفرز هي مجرد سلسلة من الأوامر أو التعليمات. في هذا ، المصفوفة عبارة عن إدخال ، تقوم خوارزمية الفرز على أساسه بتنفيذ عمليات لإعطاء مصفوفة مرتبة.
كان العديد من الأطفال قد تعلموا الفرز في هياكل البيانات في فصول علوم الكمبيوتر الخاصة بهم. يتم تقديمه في مرحلة مبكرة لمساعدة الأطفال المهتمين في الحصول على فكرة عن موضوعات علوم الكمبيوتر الأعمق - أساليب فرق تسد ، والأشجار الثنائية ، والأكوام ، وما إلى ذلك.
فيما يلي مثال على ما يفعله الفرز.
لنفترض أن لديك مجموعة من السلاسل: [h، j، k، i، n، m، o، l]
الآن ، سينتج عن الفرز مصفوفة إخراج بترتيب أبجدي.
الإخراج: [h ، i ، j ، k ، l ، m ، n ، o]
دعنا نتعلم المزيد عن الفرز في بنية البيانات.
الخروج: أنواع الشجرة الثنائية
تصنيف الفئات
هناك فئتان مختلفتان في الفرز:
- الفرز الداخلي : إذا كانت بيانات الإدخال على هذا النحو بحيث يمكن ضبطها في الذاكرة الرئيسية في وقت واحد ، يطلق عليه الفرز الداخلي.
- الفرز الخارجي : إذا كانت بيانات الإدخال لا يمكن ضبطها في الذاكرة بالكامل مرة واحدة ، فيجب تخزينها في قرص ثابت أو قرص مرن أو أي جهاز تخزين آخر. وهذا ما يسمى بالفرز الخارجي.
قراءة: أفكار وموضوعات مثيرة للاهتمام لمشروع هيكل البيانات
أنواع الفرز في بنية البيانات
فيما يلي بعض الأنواع الأكثر شيوعًا من خوارزميات الفرز.
1. دمج الفرز
تعمل هذه الخوارزمية على تقسيم المصفوفة إلى نصفين بأحجام متشابهة. ثم يتم فرز كل نصف ودمجه معًا مرة أخرى باستخدام وظيفة الدمج ().
إليك كيفية عمل الخوارزمية:
MergeSort (arr []، l، r)
إذا ص> ل
- قسّم المصفوفة إلى نصفين متساويين عن طريق تحديد النقطة الوسطى:
وسط م = (ل + ص) / 2
- استخدم الدالة mergeSort لاستدعاء النصف الأول:
استدعاء mergeSort (arr، l، m)
- استدعاء mergeSort للنصف الثاني:
استدعاء mergeSort (arr، m + 1، r)
- استخدم الدالة merge () لدمج النصفين اللذين تم فرزهما في الخطوة 2 و 3:
دمج المكالمات (arr، l، m، r)
تحقق من الصورة أدناه للحصول على صورة واضحة لكيفية عمل ذلك.
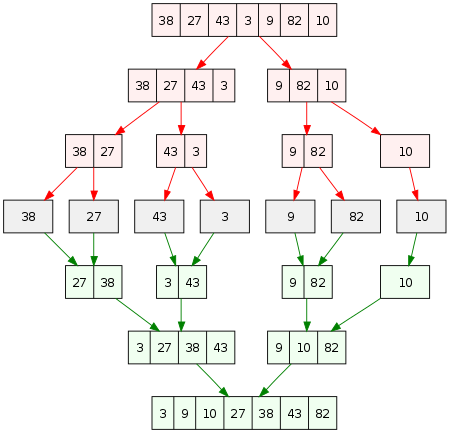
مصدر
برنامج Python لتنفيذ دمج الفرز
def mergeSort (أ):
إذا كان len (a)> 1:
mid = len (a) // 2
أ = أ [: منتصف]
ب = أ [منتصف:]
mergeSort (أ)
mergeSort (ب)
أنا = ي = ك = 0
بينما i <len (A) و j <len (B):
إذا كان A [i] <B [j]:
أ [ك] = أ [i]
أنا + = 1
آخر:
أ [ك] = ب [ي]
ي + = 1
ك + = 1
بينما أنا <لين (أ):
أ [ك] = أ [i]
أنا + = 1
ك + = 1
بينما j <len (R):
أ [ك] = ب [ي]
ي + = 1
ك + = 1
def printList (أ):
بالنسبة لـ i في النطاق (len (a)):
طباعة (a [i] ، end = "")
مطبعة()
إذا كان __name__ == '__main__':
أ = [12 ، 11 ، 13 ، 5 ، 6 ، 7]
mergeSort (أ)
طباعة ("الصفيف المصنف هو:" ، النهاية = "\ n")
قائمة الطباعة (أ)
تعرف على المزيد: العودية في بنية البيانات: كيف تعمل ، أنواعها وعندما تستخدم
2. فرز التحديد
في هذا ، في البداية ، يتم إرسال أصغر عنصر إلى الموضع الأول.
بعد ذلك ، يتم البحث عن العنصر الأصغر التالي في المصفوفة المتبقية ويتم وضعه في الموضع الثاني. يستمر هذا حتى تصل الخوارزمية إلى العنصر النهائي وتضعه في الموضع الصحيح.
انظر إلى الصورة أدناه لفهمها بشكل أفضل.
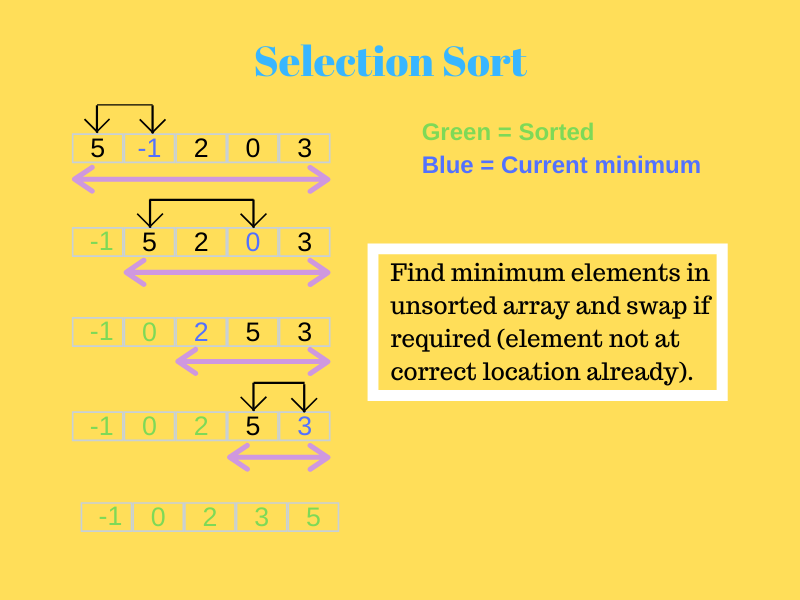 مصدر
مصدر
برنامج Python لتنفيذ فرز التحديد
استيراد النظم
س = [6 ، 25 ، 10 ، 28 ، 11]
بالنسبة لـ i في النطاق (len (X)):
min_idx = أنا
لـ j في النطاق (i + 1 ، len (X)):
إذا كان X [min_idx]> X [j]:
min_idx = j
X [i] ، X [min_idx] = X [min_idx] ، X [i]
طباعة ("المصفوفة المرتبة")
بالنسبة لـ i في النطاق (len (X)):

طباعة ("٪ d"٪ X [i]) ،
شهادة متقدمة في علوم البيانات ، أكثر من 250 شريك توظيف ، أكثر من 300 ساعة من التعلم ، 0٪ EMI
3. فرز الفقاعات
إنها أسهل وأبسط خوارزميات الفرز. إنه يعمل على مبدأ التبديل المتكرر للعناصر المتجاورة في حال لم تكن بالترتيب الصحيح.
بعبارات أبسط ، إذا كان سيتم فرز المدخلات بترتيب تصاعدي ، فإن فرز الفقاعة سيقارن أولاً أول عنصرين في المصفوفة. إذا كان العنصر الثاني أصغر من الأول ، فسيتم تبديل الاثنين ، والانتقال إلى العنصر التالي ، وهكذا.
مثال :
المدخلات : ٦٣٧١٢٤
أول إجتياز
63 7124 -> 36 7124: يقارن الفرز الفقاعي 6 و 3 ويتبادل بينهما لأن 3 <6.
3 67 124 -> 3 67 124: منذ 6 <7 ، لا مقايضة
36 71 24 -> 36 17 24: تبديل 7 و 1 ، مثل 7> 1
361 72 4 -> 361 27 4: تم التبديل 2 و 7 ، كـ 2 <7
3612 74 -> 3612 47 : تبديل 4 و 7 ، 4 <7
التمريرة الثانية
36 1247 -> 36 1247
3 61274 -> 3 16274
74 62 31 -> 31 26 74
4 - 312 67 -> 312 674
3126 74 -> 312647
التمريرة الثالثة
31 2647 -> 13 2647
1 32647 -> 1 23647
12 36 47 -> 12 3647
123 64 7 -> 123 467
1234 67 -> 1234 67
كما ترى ، نحصل على نتيجة ترتيب تصاعدي بعد ثلاث تمريرات.
برنامج Python لتنفيذ فرز الفقاعات
تصنيف (أ):
ن = لين (أ)
لأني في النطاق (ن):
لـ j في النطاق (0 ، ni-1):
إذا كانت a [j]> a [j + 1]:
أ [j] ، أ [j + 1] = أ [j + 1] ، أ [ي]
أ = [64 ، 34 ، 25 ، 12 ، 22 ، 11 ، 90]
BubbleSort (أ)
طباعة ("المصفوفة التي تم فرزها هي:")
بالنسبة لـ i في النطاق (len (a)):
طباعة ("٪ d"٪ a [i]) ،
اقرأ أيضًا: إطارات البيانات في بايثون: دروس بايثون التفصيلية
خاتمة
يختتم هذا الفرز في بنية البيانات وخوارزميات الفرز الأكثر شيوعًا. يمكنك اختيار أي نوع من أنواع خوارزميات الفرز المختلفة. ومع ذلك ، تذكر أن بعضًا منها قد يكون مضجرًا بعض الشيء في كتابة البرنامج. ولكن بعد ذلك ، قد تكون مفيدة للحصول على نتائج سريعة. من ناحية أخرى ، إذا كنت تريد فرز مجموعات البيانات الكبيرة ، فيجب عليك اختيار فرز الفقاعة. فهي لا تؤدي إلى نتائج دقيقة فحسب ، بل إنها سهلة التنفيذ أيضًا. ثم مرة أخرى ، فهو أبطأ من الأنواع الأخرى. آمل أن تكون قد أحببت المقالة حول الفرز في بنية البيانات.
لاكتساب المزيد من الأفكار حول كيفية عمل الفرز ، تواصل معنا وسنساعدك على البدء في الدورة التدريبية التي تناسب احتياجاتك على أفضل وجه!
إذا كنت مهتمًا بالتعرف على علوم البيانات ، فراجع برنامج IIIT-B & upGrad التنفيذي PG في علوم البيانات الذي تم إنشاؤه للمهنيين العاملين ويقدم أكثر من 10 دراسات حالة ومشاريع ، وورش عمل عملية عملية ، وإرشاد مع خبراء الصناعة ، 1 - في 1 مع موجهين في الصناعة ، أكثر من 400 ساعة من التعلم والمساعدة في العمل مع الشركات الكبرى.
استمتع بالشفرة!
ما هي كومة الفرز والفرز السريع؟
يتم استخدام تقنيات الفرز المختلفة لتنفيذ إجراءات الفرز حسب المتطلبات. عادةً ما يتم استخدام "الفرز السريع" لأنه أسرع ، ولكن يمكن استخدام "الفرز السريع" عندما يكون استخدام الذاكرة هو مصدر القلق.
Heap Sort هي خوارزمية فرز قائمة على المقارنة تعتمد بالكامل على بنية بيانات كومة ثنائية. هذا هو السبب في أن فرز الكومة يمكن أن يستفيد من خصائص الكومة. في خوارزمية الفرز السريع ، يتم استخدام نهج فرق تسد. هنا ، الخوارزمية بأكملها مقسمة إلى 3 خطوات. الأول هو اختيار عنصر يعمل كعنصر محوري. بعد ذلك ، العناصر الموجودة على يسار العنصر المحوري أصغر منها والعناصر الموجودة على اليمين هي الأكبر في القيمة. في كل قسم ، يتم تكرار الخطوة السابقة لفرز مجموعة العناصر بأكملها.
ما هي أسهل خوارزمية الفرز؟
إذا كنت تتعامل مع خوارزميات الفرز ، فستلاحظ أن Bubble Sort هو الأبسط من بين جميع الخوارزميات الأخرى. الفكرة الأساسية وراء هذه الخوارزمية هي فحص مجموعة العناصر بالكامل ومقارنة كل عنصر مجاور. الآن ، يحدث إجراء التبديل فقط عندما لا يتم فرز العناصر.
باستخدام Bubble Sort ، عليك فقط مقارنة العناصر المجاورة ، ويتم فرز المصفوفة. هذا هو السبب في أنها تعتبر أبسط خوارزمية الفرز.
ما هي أسرع خوارزمية الفرز في هياكل البيانات؟
يعتبر Quicksort هو الأسرع بين جميع خوارزميات الفرز الأخرى. التعقيد الزمني لـ Quicksort هو O (n log n) في أفضل حالاته ، O (n log n) في حالته المتوسطة ، و O (n ^ 2) في أسوأ حالاته. يُعرف Quicksort بأنه أسرع خوارزمية فرز نظرًا لأدائه الأفضل في جميع مدخلات الحالة المتوسطة. ستعتمد السرعة كثيرًا على كمية البيانات أيضًا. وفقًا للمقارنة بين جميع خوارزميات الفرز ، فإن Quicksort هو الأسرع بسبب متوسط مدخلات الحالة.