
數據結構中的排序:類別和類型 [附示例]
已發表: 2020-05-28在數據結構中按優先順序排列數據稱為排序。 通過對數據進行排序,可以更輕鬆地快速輕鬆地搜索它。 最簡單的排序示例是字典。 在互聯網時代之前,當你想在字典中查找一個單詞時,你會按照字母順序進行。 這很容易。
想像一下,如果您必須閱讀一本大書,其中包含來自世界各地的所有英語單詞,順序混亂! 如果他們的數據沒有排序和結構化,工程師也會經歷同樣的恐慌。
所以,簡而言之,分類讓我們的生活更輕鬆。 查看我們的數據科學課程,深入了解數據科學算法。
在這篇文章中,我們將帶您了解不同的數據結構和排序算法。 但首先,讓我們了解什麼是排序算法以及數據結構中的排序。
目錄
什麼是排序算法?
排序算法只是一系列命令或指令。 在這種情況下,數組是一個輸入,排序算法在其上執行操作以給出一個排序後的數組。
許多孩子會在他們的計算機科學課上學會對數據結構進行排序。 它是在早期引入的,以幫助感興趣的孩子了解更深層次的計算機科學主題——分而治之的方法、二叉樹、堆等。
這是排序的一個示例。
假設您有一個字符串數組: [h,j,k,i,n,m,o,l]
現在,排序將產生一個按字母順序排列的輸出數組。
輸出:[h,i,j,k,l,m,n,o]
讓我們進一步了解數據結構中的排序。
結帳:二叉樹的類型
排序類別
排序有兩種不同的類別:
- 內部排序:如果輸入的數據可以在主存中立即調整,則稱為內部排序。
- 外部排序:如果輸入的數據不能一次在內存中完全調整,則需要將其存儲在硬盤、軟盤或任何其他存儲設備中。 這稱為外部排序。
閱讀:有趣的數據結構項目想法和主題
數據結構中的排序類型
以下是一些最常見的排序算法類型。
1.合併排序
該算法用於將數組拆分為大小相當的兩半。 然後使用 merge() 函數對每一半進行排序和合併。
以下是該算法的工作原理:
合併排序(arr[],l,r)
如果 r > l
- 通過定位中點將數組分成相等的兩半:
中間 m = (l+r)/2
- 使用 mergeSort 函數調用前半部分:
調用 mergeSort(arr, l, m)
- 後半部分調用mergeSort:
調用 mergeSort(arr, m+1, r)
- 使用 merge() 函數將第 2 步和第 3 步排序的兩半合併:
調用合併(arr,l,m,r)
查看下面的圖片以清楚地了解其工作原理。
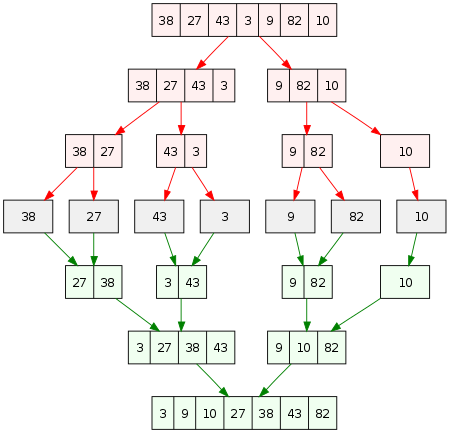
資源
用於合併排序實現的 Python 程序
定義合併排序(一):
如果 len(a) >1:
mid = len(a)//2
A = a[:mid]
B = a[中:]
合併排序(A)
合併排序(B)
我 = j = k = 0
當 i < len(A) 且 j < len(B) 時:
如果 A[i] < B[j]:
a[k] = A[i]
我+=1
別的:
a[k] = B[j]
j+=1
k+=1
當 i < len(A) 時:
a[k] = A[i]
我+=1
k+=1
當 j < len(R) 時:
a[k] = B[j]
j+=1
k+=1
定義打印列表(一):
對於我在範圍內(len(a)):
打印(a[i],end="")
打印()
如果 __name__ == '__main__':
a = [12, 11, 13, 5, 6, 7]
合併排序(一)
print("排序後的數組是:", end="\n")
打印列表(一)
了解更多:數據結構中的遞歸:它的工作原理、類型和使用時間
2.選擇排序
在此,首先,最小的元素被發送到第一個位置。
然後,在剩餘的數組中搜索下一個最小元素,並將其放置在第二個位置。 這一直持續到算法到達最終元素並將其放置在正確的位置。
請看下面的圖片以更好地理解它。
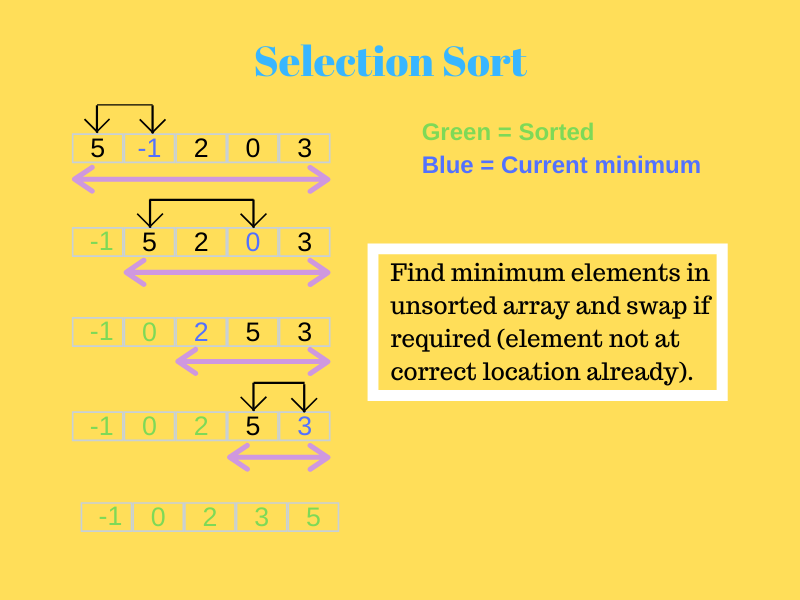 資源
資源
用於選擇排序實現的 Python 程序
導入系統
X = [6, 25, 10, 28, 11]
對於我在範圍內(len(X)):
min_idx = 我
對於範圍內的 j (i+1, len(X)):
如果 X[min_idx] > X[j]:
min_idx = j
X[i], X[min_idx] = X[min_idx], X[i]
print ("排序後的數組是")
對於我在範圍內(len(X)):
打印(“%d” %X[i]),
數據科學高級認證、250 多個招聘合作夥伴、300 多個學習小時、0% EMI

3.冒泡排序
它是所有排序算法中最簡單、最簡單的。 它的工作原理是重複交換相鄰元素,以防它們的順序不正確。
簡單來說,如果要對輸入進行升序排序,冒泡排序會首先比較數組中的前兩個元素。 如果第二個小於第一個,它將交換兩個,然後移動到下一個元素,依此類推。
示例:
輸入:637124
第一關
63 7124 -> 36 7124 :冒泡排序比較 6 和 3 並交換它們,因為 3<6。
3 67 124 -> 3 67 124 :由於 6<7,沒有交換
36 71 24 -> 36 17 24:交換 7 和 1,如 7>1
361 72 4 -> 361 27 4:交換 2 和 7,如 2<7
3612 74 -> 3612 47 :交換 4 和 7,如 4<7
第二遍
36 1247 -> 36 1247
3 61 274 -> 3 16 274
31 62 74 -> 31 26 74
312 67 4 -> 312 67 4
3126 74 -> 3126 47
第三關
31 2647 -> 13 2647
1 32 647 -> 1 23 647
12 36 47 -> 12 36 47
123 64 7 -> 123 46 7
1234 67 -> 1234 67
如您所見,我們在三遍後得到升序結果。
用於冒泡排序實現的 Python 程序
定義氣泡排序(a):
n = 長度(一)
對於範圍內的 i (n):
對於範圍內的 j (0, ni-1):
如果 a[j] > a[j+1] :
a[j], a[j+1] = a[j+1], a[j]
a = [64, 34, 25, 12, 22, 11, 90]
冒泡排序(一)
print (“排序後的數組是:”)
對於我在範圍內(len(a)):
打印(“%d”%a[i]),
另請閱讀: Python 中的數據幀:Python 深入教程
結論
這包含了數據結構中的排序和最常見的排序算法。 您可以選擇任何不同類型的排序算法。 但是,請記住,其中一些在編寫程序時可能有點乏味。 但是,它們可能會派上用場以獲得快速的結果。 另一方面,如果要對大型數據集進行排序,則必須選擇冒泡排序。 它不僅產生準確的結果,而且易於實施。 再說一次,它比其他類型慢。 我希望你喜歡這篇關於數據結構排序的文章。
要深入了解分類的工作原理,請聯繫我們,我們將幫助您開始學習最適合您需求的課程!
如果您想了解數據科學,請查看 IIIT-B 和 upGrad 的數據科學執行 PG 計劃,該計劃是為在職專業人士創建的,提供 10 多個案例研究和項目、實用的實踐研討會、與行業專家的指導、1與行業導師一對一,400 多個小時的學習和頂級公司的工作協助。
玩得開心編碼!
什麼是堆排序和快速排序?
根據要求使用不同的分揀技術來執行分揀程序。 通常,使用快速排序是因為它更快,但是當關注內存使用時,人們會使用堆排序。
堆排序是一種完全基於二進制堆數據結構的比較排序算法。 這就是為什麼堆排序可以利用堆的屬性。 在快速排序算法中,使用了分治法。 在這裡,整個算法分為3個步驟。 第一個是選擇一個元素作為樞軸元素。 接下來,樞軸元素左側的元素是較小的元素,右側是值較大的元素。 在每個分區上,重複上一步以對整個元素數組進行排序。
哪個是最簡單的排序算法?
如果您正在處理排序算法,那麼您會注意到冒泡排序是所有其他算法中最簡單的一種。 該算法背後的基本思想是掃描整個元素數組並比較每個相鄰元素。 現在,交換動作僅在元素未排序時發生。
使用冒泡排序,您只需要比較相鄰的元素,數組就會被排序。 這就是為什麼它被認為是最簡單的排序算法。
數據結構中最快的排序算法是什麼?
快速排序被認為是所有其他排序算法中最快的一種。 快速排序的時間複雜度在最佳情況下為 O(n log n),在平均情況下為 O(n log n),在最壞情況下為 O(n^2)。 眾所周知,快速排序是最快的排序算法,因為它在所有平均案例輸入中的性能最佳。 速度也很大程度上取決於數據量。 根據所有排序算法之間的比較,快速排序是最快的,因為它的平均案例輸入。