
Sortowanie w strukturze danych: kategorie i typy [z przykładami]
Opublikowany: 2020-05-28Uporządkowanie danych w preferowanej kolejności nazywamy sortowaniem w strukturze danych. Dzięki sortowaniu danych łatwiej jest je szybko i łatwo przeszukiwać. Najprostszym przykładem sortowania jest słownik. Przed erą Internetu, gdy chciałeś wyszukać słowo w słowniku, robiłeś to w kolejności alfabetycznej. To ułatwiło sprawę.
Wyobraź sobie panikę, gdybyś musiał przejrzeć dużą książkę ze wszystkimi angielskimi słowami ze świata w pomieszanej kolejności! To ta sama panika, przez którą przechodzi inżynier, jeśli ich dane nie są posortowane i ustrukturyzowane.
Krótko mówiąc, sortowanie ułatwia nam życie. Zapoznaj się z naszymi kursami nauki o danych, aby dowiedzieć się więcej o algorytmach nauki o danych.
W tym poście przeprowadzimy Cię przez różne struktury danych i algorytmy sortowania. Ale najpierw zrozummy, czym jest algorytm sortowania i sortowanie w strukturze danych.
Spis treści
Co to jest algorytm sortowania?
Algorytm sortowania to po prostu seria rozkazów lub instrukcji. W tym przypadku tablica jest wejściem, na którym algorytm sortujący wykonuje operacje w celu wydania posortowanej tablicy.
Wiele dzieci nauczyłoby się sortowania w strukturach danych na lekcjach informatyki. Jest wprowadzany na wczesnym etapie, aby pomóc zainteresowanym dzieciom zorientować się w głębszych tematach informatyki – metodach dziel i zwyciężaj, drzewach binarnych, stosach itp.
Oto przykład działania sortowania.
Załóżmy, że masz tablicę ciągów: [h,j,k,i,n,m,o,l]
Teraz sortowanie dałoby tablicę wyjściową w kolejności alfabetycznej.
Dane wyjściowe: [h,i,j,k,l,m,n,o]
Dowiedzmy się więcej o sortowaniu w strukturze danych.
Zamówienie: rodzaje drzewa binarnego
Sortowanie kategorii
W sortowaniu istnieją dwie różne kategorie:
- Sortowanie wewnętrzne : Jeśli dane wejściowe są takie, że można je od razu dostosować w pamięci głównej, nazywa się to sortowaniem wewnętrznym.
- Sortowanie zewnętrzne : Jeśli dane wejściowe są takie, że nie można ich całkowicie dostosować w pamięci od razu, należy je przechowywać na dysku twardym, dyskietce lub innym urządzeniu magazynującym. Nazywa się to sortowaniem zewnętrznym.
Przeczytaj: Ciekawe pomysły i tematy projektów dotyczących struktury danych
Rodzaje sortowania w strukturze danych
Oto kilka najpopularniejszych typów algorytmów sortowania.
1. Połącz Sortuj
Algorytm ten polega na podzieleniu tablicy na dwie połówki o porównywalnych rozmiarach. Każda połowa jest następnie sortowana i ponownie scalana za pomocą funkcji merge().
Oto jak działa algorytm:
Sortuj scalanie(arr[], l, r)
Jeśli r > l
- Podziel szyk na dwie równe połówki, lokalizując punkt środkowy:
środkowy m = (l+r)/2
- Użyj funkcji mergeSort, aby wywołać pierwszą połowę:
Połącz scal Sortuj(arr, l, m)
- Zadzwoń do scalenia Sortuj na drugą połowę:
Wywołaj scalajSortuj(arr, m+1, r)
- Użyj funkcji scalania (), aby połączyć dwie połówki posortowane w kroku 2 i 3:
Łączenie połączeń(arr, l, m, r)
Sprawdź poniższy obrazek, aby uzyskać jasny obraz tego, jak to działa.
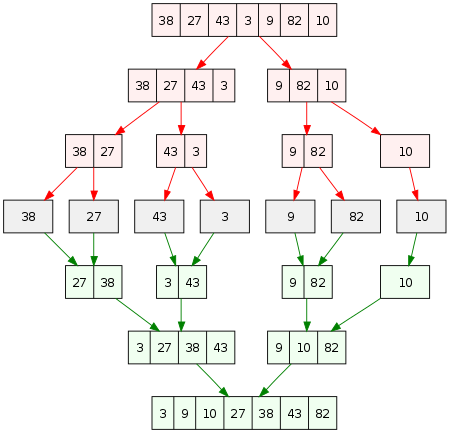
Źródło
Program w Pythonie do implementacji sortowania przez scalanie
def scalajSort(a):
jeśli len(a) >1:
środek = len(a)//2
A = a[:środek]
B = a[środek:]
połączSortuj(A)
połączSortuj(B)
i = j = k = 0
podczas gdy i < len(A) oraz j < len(B):
jeśli A[i] < B[j]:
a[k] = A[i]
ja+=1
w przeciwnym razie:
a[k] = B[j]
j+=1
k+=1
podczas gdy ja < len(A):
a[k] = A[i]
ja+=1
k+=1
podczas gdy j < len(R):
a[k] = B[j]
j+=1
k+=1
def printList(a):
dla i w zakresie(len(a)):
print(a[i],end=””)
wydrukować()
if __name__ == '__main__':
a = [12, 11, 13, 5, 6, 7]
połączSortuj(a)
print("Posortowana tablica to: ", end="\n")
DrukujLista(a)
Dowiedz się więcej: Rekurencja w strukturze danych: jak to działa, typy i kiedy są używane
2. Wybór Sortuj
W tym najpierw najmniejszy element jest wysyłany na pierwszą pozycję.
Następnie kolejny najmniejszy element jest przeszukiwany w pozostałej tablicy i umieszczany na drugiej pozycji. Trwa to, dopóki algorytm nie dotrze do ostatniego elementu i umieści go we właściwej pozycji.
Spójrz na poniższy obrazek, aby lepiej to zrozumieć.
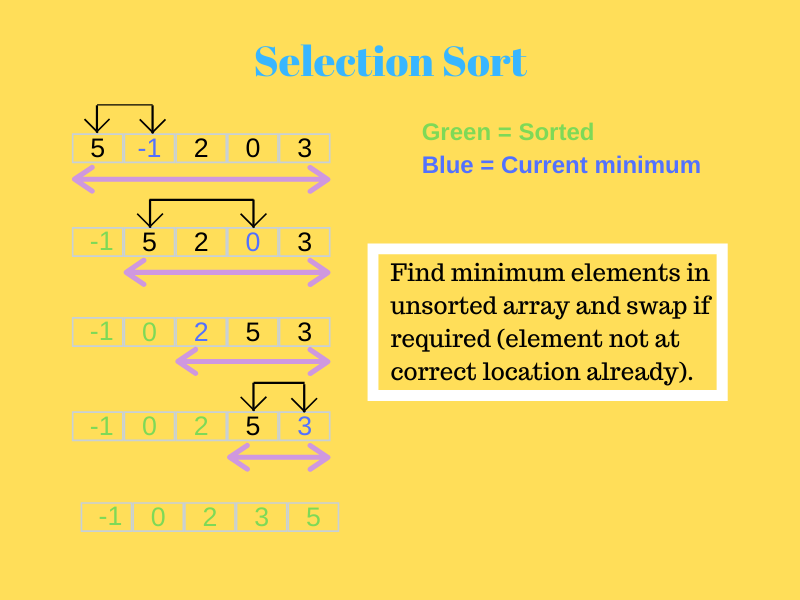 Źródło
Źródło
Program w Pythonie do implementacji sortowania przez wybór
system importu
X = [6, 25, 10, 28, 11]
dla i w zakresie(len(X)):
min_idx = i
dla j w zakresie(i+1, len(X)):
jeśli X[min_idx] > X[j]:
min_idx = j
X[i], X[min_idx] = X[min_idx], X[i]
print („Posortowana tablica to”)
dla i w zakresie(len(X)):
print(„%d” %X[i]),
Zaawansowana certyfikacja Data Science, ponad 250 partnerów rekrutacyjnych, ponad 300 godzin nauki, 0% EMI

3. Sortowanie bąbelków
Jest to najłatwiejszy i najprostszy ze wszystkich algorytmów sortowania. Działa na zasadzie wielokrotnej zamiany sąsiednich elementów w przypadku, gdy nie są one w odpowiedniej kolejności.
Mówiąc prościej, jeśli dane wejściowe mają być posortowane w kolejności rosnącej, sortowanie bąbelkowe najpierw porówna dwa pierwsze elementy tablicy. W przypadku, gdy drugi jest mniejszy niż pierwszy, zamieni dwa i przejdzie do następnego elementu i tak dalej.
Przykład :
Wejście : 637124
Pierwsze przejście
63 7124 -> 36 7124 : Sortowanie bąbelkowe porównuje 6 i 3 i zamienia je, ponieważ 3<6.
3 67 124 -> 3 67 124 : Od 6<7, bez zamiany
36 71 24 -> 36 17 24 : Zamieniono 7 i 1, jako 7> 1
361 72 4 -> 361 27 4 : Zamieniono 2 i 7, jako 2<7
3612 74 -> 3612 47 : Zamieniono 4 i 7, jako 4<7
Drugie przejście
36 1247 -> 36 1247
3 61 274 -> 3 16 274
31 62 74 -> 31 26 74
312 67 4 -> 312 67 4
3126 74 -> 3126 47
Trzeci przejazd
31 2647 -> 13 2647
1 32 647 -> 1 23 647
12 36 47 -> 12 36 47
123 64 7 -> 123 46 7
1234 67 -> 1234 67
Jak widać, po trzech przejściach otrzymujemy wynik w kolejności rosnącej.
Program w Pythonie do implementacji sortowania bąbelkowego
def bubbleSort(a):
n = len(a)
dla i w zakresie (n):
dla j w zakresie (0, ni-1):
jeśli a[j] > a[j+1] :
a[j], a[j+1] = a[j+1], a[j]
a = [64, 34, 25, 12, 22, 11, 90]
BańkaSort(a)
print („Posortowana tablica to:”)
dla i w zakresie(len(a)):
drukuj („%d” %a[i]),
Przeczytaj także: Ramki danych w Pythonie: Szczegółowy samouczek Pythona
Wniosek
To zamyka sortowanie w strukturze danych i najczęstszych algorytmach sortowania. Możesz wybrać dowolny z różnych typów algorytmów sortowania. Pamiętaj jednak, że pisanie programu dla niektórych z nich może być trochę żmudne. Ale wtedy mogą się przydać, aby uzyskać szybkie rezultaty. Z drugiej strony, jeśli chcesz posortować duże zestawy danych, musisz wybrać sortowanie bąbelkowe. Nie tylko daje dokładne wyniki, ale jest również łatwy do wdrożenia. Z drugiej strony jest wolniejszy niż inne typy. Mam nadzieję, że spodobał Ci się artykuł o sortowaniu w strukturze danych.
Aby uzyskać więcej informacji o tym, jak działa sortowanie, skontaktuj się z nami, a pomożemy Ci rozpocząć kurs, który najlepiej odpowiada Twoim potrzebom!
Jeśli jesteś zainteresowany nauką o danych, sprawdź program IIIT-B i upGrad Executive PG w dziedzinie Data Science, który jest stworzony dla pracujących profesjonalistów i oferuje ponad 10 studiów przypadków i projektów, praktyczne warsztaty praktyczne, mentoring z ekspertami z branży, 1 -on-1 z mentorami branżowymi, ponad 400 godzin nauki i pomocy w pracy z najlepszymi firmami.
Miłego kodowania!
Co to są sortowanie sterty i szybkie sortowanie?
Do wykonywania procedur sortowania zgodnie z wymaganiami wykorzystywane są różne techniki sortowania. Zwykle używane jest szybkie sortowanie, ponieważ jest szybsze, ale sortowania sterty używa się, gdy problemem jest użycie pamięci.
Heap Sort to algorytm sortowania oparty na porównaniach, całkowicie oparty na binarnej strukturze danych sterty. Dlatego sortowanie na stercie może wykorzystywać właściwości sterty. W algorytmie szybkiego sortowania wykorzystywane jest podejście „dziel i zwyciężaj”. Tutaj cały algorytm podzielony jest na 3 kroki. Pierwszym z nich jest wybranie elementu, który działa jako element obrotowy. Następnie elementy po lewej stronie elementu obrotowego są mniejsze, a po prawej mają większą wartość. Na każdej partycji poprzedni krok jest powtarzany, aby posortować całą tablicę elementów.
Jaki jest najłatwiejszy algorytm sortowania?
Jeśli masz do czynienia z algorytmami sortowania, zauważysz, że Sortowanie bąbelkowe jest najprostszym spośród wszystkich. Podstawową ideą tego algorytmu jest skanowanie całej tablicy elementów i porównywanie każdego sąsiedniego elementu. Teraz akcja zamiany następuje tylko wtedy, gdy elementy nie są posortowane.
W przypadku sortowania bąbelkowego wystarczy porównać sąsiednie elementy, a tablica zostanie posortowana. Dlatego uważany jest za najprostszy algorytm sortowania.
Jaki jest najszybszy algorytm sortowania w strukturach danych?
Quicksort jest uważany za najszybszy spośród wszystkich innych algorytmów sortowania. Złożoność czasowa Quicksort wynosi O(n log n) w najlepszym przypadku, O(n log n) w przeciętnym przypadku i O(n^2) w najgorszym przypadku. Quicksort jest znany jako najszybszy algorytm sortowania ze względu na jego najlepszą wydajność we wszystkich danych wejściowych o średniej wielkości. Szybkość będzie również w dużej mierze zależeć od ilości danych. Zgodnie z porównaniem wszystkich algorytmów sortowania, Quicksort jest najszybszy ze względu na średnie dane wejściowe.