
Arquitectura básica de CNN: explicación de 5 capas de red neuronal convolucional
Publicado: 2020-12-07Tabla de contenido
Introducción
En los últimos años de la industria de TI, ha habido una gran demanda de un conjunto de habilidades que alguna vez fue particular, conocido como Aprendizaje Profundo. Deep Learning un subconjunto de Machine Learning que consiste en algoritmos inspirados en el funcionamiento del cerebro humano o las redes neuronales.
Estas estructuras se denominan Redes Neuronales. Le enseña a la computadora a hacer lo que le viene naturalmente a los humanos. Aprendizaje profundo, existen varios tipos de modelos, como las redes neuronales artificiales (ANN), los codificadores automáticos, las redes neuronales recurrentes (RNN) y el aprendizaje por refuerzo. Pero ha habido un modelo en particular que ha contribuido mucho en el campo de la visión artificial y el análisis de imágenes que son las Redes Neuronales Convolucionales (CNN) o ConvNets.
Las CNN son una clase de redes neuronales profundas que pueden reconocer y clasificar características particulares de las imágenes y se usan ampliamente para analizar imágenes visuales. Sus aplicaciones van desde el reconocimiento de imágenes y videos, la clasificación de imágenes, el análisis de imágenes médicas, la visión artificial y el procesamiento del lenguaje natural.
El término 'Convolución' en CNN denota la función matemática de convolución, que es un tipo especial de operación lineal en la que dos funciones se multiplican para producir una tercera función que expresa cómo la forma de una función es modificada por la otra. En términos simples, dos imágenes que se pueden representar como matrices se multiplican para dar una salida que se usa para extraer características de la imagen.
Aprenda Machine Learning en línea de las mejores universidades del mundo: maestrías, programas ejecutivos de posgrado y programa de certificado avanzado en ML e IA para acelerar su carrera.
Learn: Introducción al aprendizaje profundo y las redes neuronales

Arquitectura Básica
Hay dos partes principales en una arquitectura CNN
- Una herramienta de convolución que separa e identifica las diversas características de la imagen para su análisis en un proceso llamado Extracción de características
- Una capa completamente conectada que utiliza la salida del proceso de convolución y predice la clase de la imagen en función de las características extraídas en etapas anteriores.
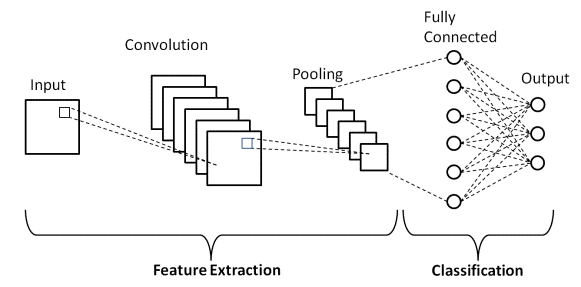
Fuente
Capas de convolución
Hay tres tipos de capas que componen la CNN, que son las capas convolucionales, las capas de agrupación y las capas totalmente conectadas (FC). Cuando estas capas se apilan, se formará una arquitectura CNN. Además de estas tres capas, hay dos parámetros más importantes que son la capa de abandono y la función de activación que se definen a continuación.
1. Capa convolucional
Esta capa es la primera capa que se utiliza para extraer las diversas características de las imágenes de entrada. En esta capa se realiza la operación matemática de convolución entre la imagen de entrada y un filtro de un tamaño particular MxM. Al deslizar el filtro sobre la imagen de entrada, se toma el producto escalar entre el filtro y las partes de la imagen de entrada con respecto al tamaño del filtro (MxM).
La salida se denomina mapa de características que nos brinda información sobre la imagen, como las esquinas y los bordes. Más tarde, este mapa de características se alimenta a otras capas para aprender otras características de la imagen de entrada.
2. Capa de agrupación
En la mayoría de los casos, una capa convolucional es seguida por una capa de agrupación. El objetivo principal de esta capa es disminuir el tamaño del mapa de características convolucionado para reducir los costos computacionales. Esto se realiza disminuyendo las conexiones entre capas y opera de forma independiente en cada mapa de características. Según el método utilizado, existen varios tipos de operaciones de agrupación.
En Max Pooling, el elemento más grande se toma del mapa de características. La agrupación promedio calcula el promedio de los elementos en una sección de imagen de tamaño predefinido. La suma total de los elementos en la sección predefinida se calcula en Sum Pooling. La capa de agrupación generalmente sirve como puente entre la capa convolucional y la capa FC
Debe leer: Ideas de proyectos de redes neuronales
3. Capa completamente conectada
La capa totalmente conectada (FC) consta de los pesos y sesgos junto con las neuronas y se utiliza para conectar las neuronas entre dos capas diferentes. Estas capas generalmente se colocan antes de la capa de salida y forman las últimas capas de una arquitectura CNN.
En esto, la imagen de entrada de las capas anteriores se aplana y se alimenta a la capa FC. Luego, el vector aplanado pasa por unas pocas capas FC más donde normalmente tienen lugar las operaciones de las funciones matemáticas. En esta etapa comienza el proceso de clasificación.
4. Abandono
Por lo general, cuando todas las características están conectadas a la capa FC, puede provocar un sobreajuste en el conjunto de datos de entrenamiento. El sobreajuste ocurre cuando un modelo en particular funciona tan bien en los datos de entrenamiento que causa un impacto negativo en el rendimiento del modelo cuando se usa en datos nuevos.
Para superar este problema, se utiliza una capa de eliminación en la que se eliminan algunas neuronas de la red neuronal durante el proceso de entrenamiento, lo que reduce el tamaño del modelo. Al pasar un abandono de 0,3, el 30 % de los nodos se eliminan aleatoriamente de la red neuronal.
5. Funciones de activación
Finalmente, uno de los parámetros más importantes del modelo CNN es la función de activación. Se utilizan para aprender y aproximar cualquier tipo de relación continua y compleja entre variables de la red. En palabras simples, decide qué información del modelo debe dispararse hacia adelante y cuál no al final de la red.

Agrega no linealidad a la red. Hay varias funciones de activación de uso común, como las funciones ReLU, Softmax, tanH y Sigmoid. Cada una de estas funciones tiene un uso específico. Para un modelo CNN de clasificación binaria, se prefieren las funciones sigmoide y softmax y para una clasificación multiclase, generalmente se usa softmax.
Arquitectura CNN LeNet-5
En 1998, Yann LeCun, Leon Bottou, Yoshua Bengio y Patrick Haffner presentaron la arquitectura LeNet-5 en un artículo de investigación titulado “Aprendizaje basado en gradientes aplicado al reconocimiento de documentos”. Es una de las arquitecturas CNN más antiguas y básicas.
Consta de 7 capas. La primera capa consiste en una imagen de entrada con dimensiones de 32×32. Está convolucionado con 6 filtros de tamaño 5×5 que dan como resultado una dimensión de 28x28x6. La segunda capa es una operación de agrupación que filtra el tamaño de 2 × 2 y la zancada de 2. Por lo tanto, la dimensión de la imagen resultante será 14x14x6.
De manera similar, la tercera capa también implica una operación de convolución con 16 filtros de tamaño 5×5 seguida de una cuarta capa de agrupación con un tamaño de filtro similar de 2×2 y zancada de 2. Por lo tanto, la dimensión de la imagen resultante se reducirá a 5x5x16.
Una vez que se reduce la dimensión de la imagen, la quinta capa es una capa convolucional completamente conectada con 120 filtros cada uno de tamaño 5×5. En esta capa, cada una de las 120 unidades de esta capa se conectará a las 400 (5x5x16) unidades de las capas anteriores. La sexta capa también es una capa completamente conectada con 84 unidades.
La séptima capa final será una capa de salida softmax con 'n' clases posibles según la cantidad de clases en el conjunto de datos.
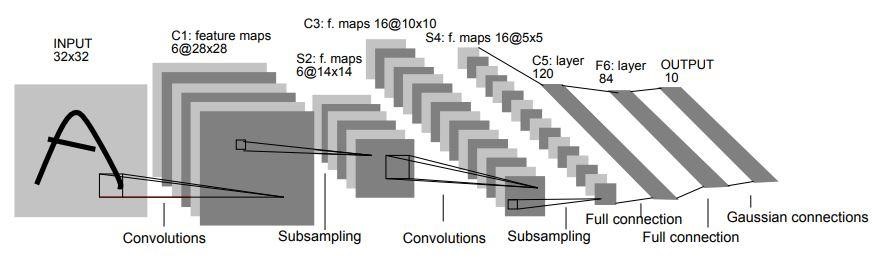
Fuente
El diagrama anterior es una representación de las 7 capas de la arquitectura CNN LeNet-5.
A continuación se muestran las instantáneas del código Python para construir una arquitectura CNN LeNet-5 utilizando la biblioteca keras con el marco TensorFlow

En la programación de Python, el tipo de modelo que se usa más comúnmente es el tipo secuencial. Es la forma más fácil de construir un modelo CNN en keras. Nos permite construir un modelo capa por capa. La función 'add()' se usa para agregar capas al modelo. Como se explicó anteriormente, para la arquitectura LeNet-5, hay dos pares de convolución y agrupación seguidos de una capa Flatten que generalmente se usa como una conexión entre las capas de convolución y densa.
Las capas densas son las que se utilizan principalmente para las capas de salida. La activación utilizada es el 'Softmax' que da una probabilidad para cada clase y suman 1 en total. El modelo hará su predicción basándose en la clase con mayor probabilidad.
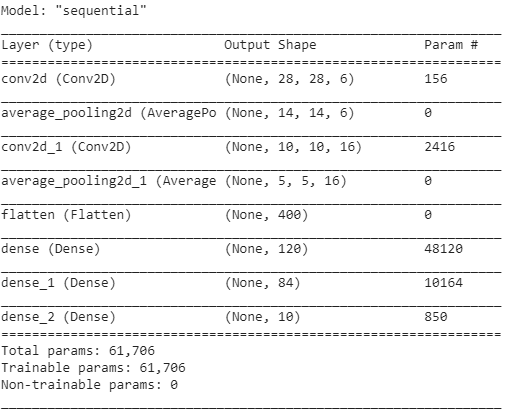
El resumen del modelo se muestra a continuación.
Conclusión
Por lo tanto, en este artículo hemos entendido la estructura básica de CNN, su arquitectura y las diversas capas que componen el modelo de CNN. Además, hemos visto un ejemplo arquitectónico de un modelo LeNet-5 muy famoso y tradicional con su programa Python.
Si está interesado en obtener más información sobre los cursos de aprendizaje automático, consulte el Programa PG Ejecutivo en Aprendizaje Automático e IA de IIIT-B y upGrad, que está diseñado para profesionales que trabajan y ofrece más de 450 horas de capacitación rigurosa, más de 30 estudios de casos y asignaciones, Estado de ex alumnos de IIIT-B, más de 5 proyectos prácticos finales y asistencia laboral con las mejores empresas.
¿Qué son las funciones de activación en CNN?
La función de activación es uno de los componentes más vitales del modelo CNN. Se utilizan para aprender y aproximar cualquier forma de asociación de variable a variable de red que sea tanto continua como compleja. En términos simples, determina qué modelo de información debe fluir hacia adelante y cuál no al final de la red. Le da a la red no linealidad. Las funciones ReLU, Softmax, tanH y Sigmoid son algunas de las funciones de activación más utilizadas. Todas estas funciones tienen usos distintos. Para un modelo CNN de 2 clases, se prefieren las funciones sigmoideas y softmax, mientras que softmax se emplea típicamente para la clasificación de clases múltiples.
¿Cuáles son los componentes básicos de la arquitectura de red neuronal convolucional?
Una capa de entrada, una capa de salida y varias capas ocultas forman redes convolucionales. Las neuronas en las capas de una red convolucional están dispuestas en tres dimensiones, a diferencia de las de una red neuronal estándar (dimensiones de ancho, alto y profundidad). Esto permite que la CNN convierta un volumen de entrada tridimensional en un volumen de salida. Las capas de convolución, agrupación, normalización y totalmente conectadas forman las capas ocultas. En las CNN se utilizan múltiples capas de conversión para filtrar los volúmenes de entrada a niveles más altos de abstracción.
¿Cuál es el beneficio de las arquitecturas CNN estándar?
Mientras que las arquitecturas de red tradicionales consistían únicamente en capas convolucionales apiladas, las arquitecturas más nuevas buscan formas nuevas y novedosas de construir capas convolucionales para mejorar la eficiencia del aprendizaje. Estas arquitecturas proporcionan recomendaciones arquitectónicas generales para que los profesionales del aprendizaje automático se adapten a fin de manejar una variedad de problemas de visión por computadora. Estas arquitecturas se pueden utilizar como extractores de características ricas para la clasificación de imágenes, la identificación de objetos, la segmentación de imágenes y una variedad de otras tareas avanzadas.