
Grundlegende CNN-Architektur: Erläuterung von 5 Schichten eines Convolutional Neural Network
Veröffentlicht: 2020-12-07Inhaltsverzeichnis
Einführung
In den letzten Jahren gab es in der IT-Branche eine enorme Nachfrage nach einst bestimmten Fähigkeiten, die als Deep Learning bekannt sind. Deep Learning ist eine Teilmenge des maschinellen Lernens, das aus Algorithmen besteht, die von der Funktionsweise des menschlichen Gehirns oder der neuronalen Netze inspiriert sind.
Diese Strukturen werden als neuronale Netze bezeichnet. Es bringt dem Computer bei, das zu tun, was dem Menschen von Natur aus zukommt. Deep Learning, es gibt verschiedene Arten von Modellen wie künstliche neuronale Netze (ANN), Autoencoder, rekurrente neuronale Netze (RNN) und Reinforcement Learning. Aber es gab ein bestimmtes Modell, das viel auf dem Gebiet der Computer Vision und Bildanalyse beigetragen hat, nämlich die Convolutional Neural Networks (CNN) oder die ConvNets.
CNNs sind eine Klasse von Deep Neural Networks, die bestimmte Merkmale von Bildern erkennen und klassifizieren können und häufig zur Analyse visueller Bilder verwendet werden. Ihre Anwendungen reichen von der Bild- und Videoerkennung, Bildklassifizierung, medizinischen Bildanalyse, Computer Vision bis hin zur Verarbeitung natürlicher Sprache.
Der Begriff „Faltung“ bezeichnet in CNN die mathematische Funktion der Faltung, bei der es sich um eine spezielle Art linearer Operation handelt, bei der zwei Funktionen multipliziert werden, um eine dritte Funktion zu erzeugen, die ausdrückt, wie die Form einer Funktion durch die andere modifiziert wird. Einfach ausgedrückt werden zwei Bilder, die als Matrizen dargestellt werden können, multipliziert, um eine Ausgabe zu erhalten, die zum Extrahieren von Merkmalen aus dem Bild verwendet wird.
Lernen Sie maschinelles Lernen online von den besten Universitäten der Welt – Master, Executive Post Graduate Programs und Advanced Certificate Program in ML & AI, um Ihre Karriere zu beschleunigen.
Lernen: Einführung in Deep Learning und neuronale Netze

Grundlegende Architektur
Eine CNN-Architektur besteht aus zwei Hauptteilen
- Ein Faltungswerkzeug, das die verschiedenen Merkmale des Bildes zur Analyse in einem als Merkmalsextraktion bezeichneten Prozess trennt und identifiziert
- Eine vollständig verbundene Schicht, die die Ausgabe des Faltungsprozesses nutzt und die Klasse des Bildes auf der Grundlage der in früheren Phasen extrahierten Merkmale vorhersagt.
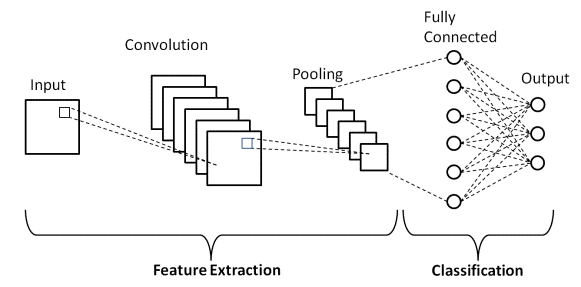
Quelle
Faltungsschichten
Es gibt drei Arten von Schichten, aus denen das CNN besteht, nämlich die Faltungsschichten, die Pooling-Schichten und die vollständig verbundenen (FC) Schichten. Wenn diese Schichten gestapelt werden, wird eine CNN-Architektur gebildet. Zusätzlich zu diesen drei Schichten gibt es zwei weitere wichtige Parameter, nämlich die Dropout-Schicht und die Aktivierungsfunktion, die unten definiert werden.
1. Faltungsschicht
Diese Schicht ist die erste Schicht, die verwendet wird, um die verschiedenen Merkmale aus den Eingabebildern zu extrahieren. In dieser Schicht wird die mathematische Operation der Faltung zwischen dem Eingangsbild und einem Filter einer bestimmten Größe MxM durchgeführt. Durch Schieben des Filters über das Eingabebild wird das Skalarprodukt zwischen dem Filter und den Teilen des Eingabebilds in Bezug auf die Größe des Filters (MxM) gebildet.
Die Ausgabe wird als Feature Map bezeichnet, die uns Informationen über das Bild wie Ecken und Kanten gibt. Später wird diese Merkmalskarte anderen Schichten zugeführt, um mehrere andere Merkmale des Eingabebilds zu lernen.
2. Pooling-Schicht
In den meisten Fällen folgt auf einen Convolutional Layer ein Pooling Layer. Das Hauptziel dieser Schicht ist es, die Größe der gefalteten Feature-Karte zu verringern, um die Rechenkosten zu reduzieren. Dies wird durch Verringern der Verbindungen zwischen Schichten durchgeführt und arbeitet unabhängig auf jeder Merkmalskarte. Je nach verwendeter Methode gibt es mehrere Arten von Pooling-Operationen.
Bei Max Pooling wird das größte Element aus der Feature-Map entnommen. Average Pooling berechnet den Durchschnitt der Elemente in einem vordefinierten Bildausschnitt. Beim Sum Pooling wird die Gesamtsumme der Elemente im vordefinierten Abschnitt berechnet. Der Pooling Layer dient normalerweise als Brücke zwischen dem Convolutional Layer und dem FC Layer
Muss gelesen werden: Projektideen für neuronale Netzwerke
3. Vollständig verbundene Schicht
Die Fully Connected (FC)-Schicht besteht aus den Gewichtungen und Vorspannungen zusammen mit den Neuronen und wird verwendet, um die Neuronen zwischen zwei verschiedenen Schichten zu verbinden. Diese Schichten werden normalerweise vor der Ausgabeschicht platziert und bilden die letzten paar Schichten einer CNN-Architektur.
Dabei wird das Eingangsbild der vorherigen Schichten geglättet und der FC-Schicht zugeführt. Der abgeflachte Vektor wird dann einigen weiteren FC-Schichten unterzogen, wo normalerweise die mathematischen Funktionsoperationen stattfinden. In dieser Phase beginnt der Klassifizierungsprozess.
4. Ausfall
Wenn alle Features mit der FC-Schicht verbunden sind, kann dies normalerweise zu einer Überanpassung im Trainingsdatensatz führen. Overfitting tritt auf, wenn ein bestimmtes Modell so gut mit den Trainingsdaten funktioniert, dass es negative Auswirkungen auf die Leistung des Modells hat, wenn es mit neuen Daten verwendet wird.
Um dieses Problem zu überwinden, wird eine Dropout-Schicht verwendet, bei der einige Neuronen während des Trainingsprozesses aus dem neuronalen Netzwerk entfernt werden, was zu einer reduzierten Größe des Modells führt. Beim Passieren eines Ausfalls von 0,3 werden 30 % der Knoten zufällig aus dem neuronalen Netz ausgeworfen.
5. Aktivierungsfunktionen
Schließlich ist einer der wichtigsten Parameter des CNN-Modells die Aktivierungsfunktion. Sie werden verwendet, um jede Art von kontinuierlicher und komplexer Beziehung zwischen Variablen des Netzwerks zu lernen und zu approximieren. Vereinfacht gesagt entscheidet es, welche Informationen des Modells in Vorwärtsrichtung feuern sollen und welche nicht am Ende des Netzwerks.

Es fügt dem Netzwerk Nichtlinearität hinzu. Es gibt mehrere häufig verwendete Aktivierungsfunktionen wie die ReLU-, Softmax-, tanH- und die Sigmoid-Funktionen. Jede dieser Funktionen hat eine bestimmte Verwendung. Für ein CNN-Modell mit binärer Klassifikation werden Sigmoid- und Softmax-Funktionen bevorzugt und für eine Mehrklassenklassifikation wird im Allgemeinen Softmax verwendet.
LeNet-5 CNN-Architektur
1998 wurde die LeNet-5-Architektur in einer Forschungsarbeit mit dem Titel „Gradient-Based Learning Applied to Document Recognition“ von Yann LeCun, Leon Bottou, Yoshua Bengio und Patrick Haffner vorgestellt. Es ist eine der frühesten und grundlegendsten CNN-Architekturen.
Es besteht aus 7 Schichten. Die erste Ebene besteht aus einem Eingangsbild mit den Abmessungen 32×32. Es ist mit 6 Filtern der Größe 5×5 gefaltet, was zu einer Abmessung von 28x28x6 führt. Die zweite Schicht ist eine Pooling-Operation, die die Größe 2×2 und die Schrittweite 2 filtert. Daher ist die resultierende Bilddimension 14x14x6.
In ähnlicher Weise umfasst die dritte Schicht auch eine Faltungsoperation mit 16 Filtern der Größe 5 × 5, gefolgt von einer vierten Pooling-Schicht mit einer ähnlichen Filtergröße von 2 × 2 und einer Schrittweite von 2. Somit wird die resultierende Bilddimension auf 5 × 5 × 16 reduziert.
Sobald die Bilddimension reduziert ist, ist die fünfte Schicht eine vollständig verbundene Faltungsschicht mit 120 Filtern mit jeweils einer Größe von 5 × 5. In dieser Schicht wird jede der 120 Einheiten in dieser Schicht mit den 400 (5x5x16) Einheiten der vorherigen Schichten verbunden. Die sechste Schicht ist ebenfalls eine vollständig verbundene Schicht mit 84 Einheiten.
Die letzte siebte Schicht ist eine Softmax-Ausgabeschicht mit „n“ möglichen Klassen, abhängig von der Anzahl der Klassen im Datensatz.
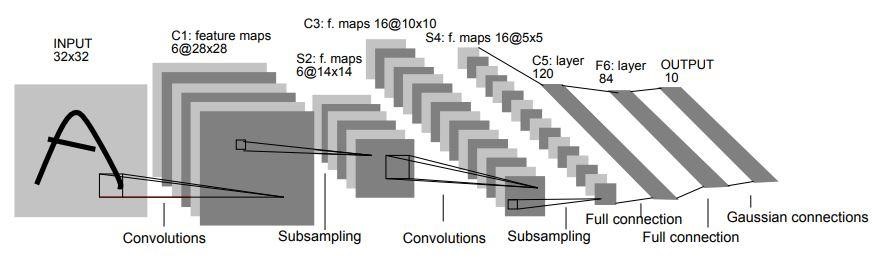
Quelle
Das obige Diagramm ist eine Darstellung der 7 Schichten der LeNet-5 CNN-Architektur.
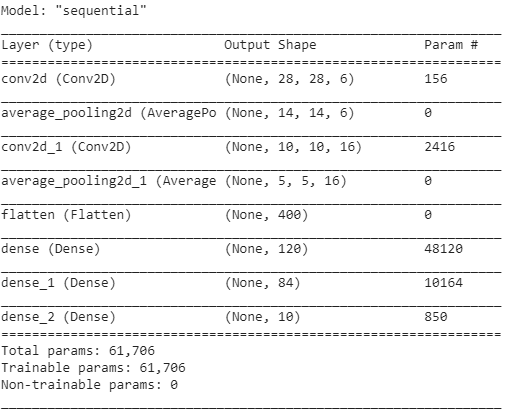
Unten sind die Snapshots des Python-Codes zum Erstellen einer LeNet-5-CNN-Architektur unter Verwendung der Keras-Bibliothek mit dem TensorFlow-Framework

In der Python-Programmierung ist der am häufigsten verwendete Modelltyp der sequenzielle Typ. Es ist der einfachste Weg, ein CNN-Modell in Keras zu erstellen. Es erlaubt uns, ein Modell Schicht für Schicht aufzubauen. Die Funktion 'add()' wird verwendet, um Schichten zum Modell hinzuzufügen. Wie oben erläutert, gibt es für die LeNet-5-Architektur zwei Convolution- und Pooling-Paare, gefolgt von einer Flatten-Schicht, die normalerweise als Verbindung zwischen Convolution und den Dense-Schichten verwendet wird.
Die dichten Schichten werden hauptsächlich für die Ausgabeschichten verwendet. Die verwendete Aktivierung ist der 'Softmax', der eine Wahrscheinlichkeit für jede Klasse angibt, und sie summieren sich insgesamt zu 1. Das Modell trifft seine Vorhersage basierend auf der Klasse mit der höchsten Wahrscheinlichkeit.
Die Zusammenfassung des Modells wird wie folgt angezeigt.
Fazit
Daher haben wir in diesem Artikel die grundlegende CNN-Struktur, ihre Architektur und die verschiedenen Schichten verstanden, aus denen das CNN-Modell besteht. Außerdem haben wir ein architektonisches Beispiel eines sehr berühmten und traditionellen LeNet-5-Modells mit seinem Python-Programm gesehen.
Wenn Sie mehr über Kurse zum maschinellen Lernen erfahren möchten, besuchen Sie das Executive PG-Programm von IIIT-B & upGrad für maschinelles Lernen und KI , das für Berufstätige konzipiert ist und mehr als 450 Stunden strenge Schulungen, mehr als 30 Fallstudien und Aufgaben bietet. IIIT-B Alumni-Status, mehr als 5 praktische Schlusssteinprojekte und Arbeitsunterstützung bei Top-Unternehmen.
Was sind Aktivierungsfunktionen in CNN?
Die Aktivierungsfunktion ist eine der wichtigsten Komponenten im CNN-Modell. Sie werden verwendet, um jede Form von Netzwerkvariablen-zu-Variablen-Assoziationen zu lernen und zu approximieren, die sowohl kontinuierlich als auch komplex sind. Vereinfacht gesagt legt es fest, welche Modellinformationen in Vorwärtsrichtung fließen sollen und welche nicht am Ende des Netzwerks. Es verleiht dem Netzwerk Nichtlinearität. Die ReLU-, Softmax-, tanH- und Sigmoid-Funktionen sind einige der am häufigsten verwendeten Aktivierungsfunktionen. Alle diese Funktionen haben unterschiedliche Verwendungszwecke. Für ein 2-Klassen-CNN-Modell werden Sigmoid- und Softmax-Funktionen bevorzugt, während Softmax typischerweise für die Mehrklassenklassifizierung verwendet wird.
Was sind die grundlegenden Komponenten der Convolutional Neural Network Architecture?
Eine Eingabeschicht, eine Ausgabeschicht und mehrere verborgene Schichten bilden Faltungsnetzwerke. Die Neuronen in den Schichten eines Faltungsnetzwerks sind im Gegensatz zu denen in einem standardmäßigen neuronalen Netzwerk (Breite, Höhe und Tiefe) dreidimensional angeordnet. Dadurch kann das CNN ein dreidimensionales Eingangsvolumen in ein Ausgangsvolumen umwandeln. Faltungs-, Pooling-, Normalisierungs- und vollständig verbundene Schichten bilden die verborgenen Schichten. In CNNs werden mehrere Conv-Layer verwendet, um Eingabevolumina auf höhere Abstraktionsebenen zu filtern.
Was ist der Vorteil von Standard-CNN-Architekturen?
Während traditionelle Netzwerkarchitekturen ausschließlich aus gestapelten Faltungsschichten bestanden, untersuchen neuere Architekturen neue und neuartige Wege zum Aufbau von Faltungsschichten, um die Lerneffizienz zu verbessern. Diese Architekturen bieten allgemeine Architekturempfehlungen für Praktiker des maschinellen Lernens zur Anpassung, um eine Vielzahl von Computer-Vision-Problemen zu bewältigen. Diese Architekturen können als Rich-Feature-Extraktoren für die Bildklassifizierung, Objektidentifikation, Bildsegmentierung und eine Vielzahl anderer fortgeschrittener Aufgaben verwendet werden.