
機器學習理論及其應用簡介:帶有示例的可視化教程
已發表: 2022-03-11機器學習 (ML) 正在發揮作用,人們越來越認識到 ML 可以在廣泛的關鍵應用中發揮關鍵作用,例如數據挖掘、自然語言處理、圖像識別和專家系統。 ML 在所有這些領域以及更多領域提供潛在的解決方案,並將成為我們未來文明的支柱。
有能力的 ML 設計師的供應尚未趕上這一需求。 造成這種情況的一個主要原因是 ML 非常棘手。 本機器學習教程介紹了機器學習理論的基礎知識,闡述了共同的主題和概念,使其易於遵循邏輯並熟悉機器學習基礎知識。
什麼是機器學習?
那麼究竟什麼是“機器學習”呢? ML實際上是很多東西。 該領域非常廣闊並且正在迅速擴展,不斷地被劃分和子劃分為不同的子專業和機器學習類型。
然而,有一些基本的共同點,最重要的主題是 Arthur Samuel 在 1959 年經常引用的一句話: “[機器學習是] 讓計算機能夠在沒有被明確編程。”
最近,在 1997 年,Tom Mitchell 給出了一個“恰當的”定義,該定義已被證明對工程類型更有用: “一個計算機程序據說可以從經驗 E 中學習一些任務 T 和一些性能度量 P,如果它在 T 上的表現,以 P 衡量,隨著經驗 E 而提高。”
因此,如果您希望您的程序預測,例如,繁忙路口的交通模式(任務 T),您可以通過機器學習算法運行它,其中包含有關過去交通模式的數據(經驗 E),如果它成功“學習”,然後它將在預測未來的流量模式(性能測量 P)方面做得更好。
然而,許多現實世界問題的高度複雜性通常意味著發明專門的算法來每次都能完美地解決它們是不切實際的,如果不是不可能的話。 機器學習問題的例子包括,“這是癌症嗎?”,“這所房子的市場價值是多少?”,“這些人中誰是彼此的好朋友?”,“這台火箭發動機起飛時會爆炸嗎? ”、“這個人會喜歡這部電影嗎?”、“這是誰?”、“你說什麼?”和“你怎麼飛這個東西?”。 所有這些問題都是 ML 項目的優秀目標,事實上 ML 已經成功地應用於每個問題。
在不同類型的 ML 任務中,有監督學習和無監督學習之間存在重要區別:
- 監督機器學習:該程序在一組預定義的“訓練示例”上進行“訓練”,然後在給定新數據時促進其得出準確結論的能力。
- 無監督機器學習:給程序一堆數據,必須在其中找到模式和關係。
我們將在這裡主要關注監督學習,但文章的結尾包括對無監督學習的簡要討論,並為有興趣進一步研究該主題的人提供了一些鏈接。
監督機器學習
在大多數監督學習應用中,最終目標是開發一個微調的預測函數h(x) (有時稱為“假設”)。 “學習”包括使用複雜的數學算法來優化這個函數,這樣,給定關於某個領域的輸入數據x (比如,房子的平方英尺),它將準確地預測一些有趣的值h(x) (比如,市場價格對於所說的房子)。
在實踐中, x幾乎總是代表多個數據點。 因此,例如,房價預測器可能不僅需要平方英尺 ( x1 ),還需要臥室數量 ( x2 )、浴室數量 ( x3 )、樓層數 ( x4) 、建造年份 ( x5 )、郵政編碼( x6 ) 等等。 確定使用哪些輸入是 ML 設計的重要組成部分。 但是,為了便於解釋,最容易假設使用單個輸入值。
因此,假設我們的簡單預測器具有以下形式:
在哪裡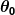 和
和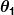 是常數。 我們的目標是找到完美的價值觀和使我們的預測器盡可能好地工作。
是常數。 我們的目標是找到完美的價值觀和使我們的預測器盡可能好地工作。
使用訓練示例優化預測器h(x) 。 對於每個訓練示例,我們都有一個輸入值x_train ,其對應的輸出y是事先已知的。 對於每個示例,我們找到已知的正確值y和我們的預測值h(x_train)之間的差異。 有了足夠多的訓練樣本,這些差異為我們提供了一種衡量h(x)的“錯誤”的有用方法。 然後我們可以通過調整h(x)的值來調整和使其“少錯”。 這個過程一遍又一遍地重複,直到系統收斂到最佳值和. 通過這種方式,預測器得到訓練,並準備好進行一些現實世界的預測。
機器學習示例
為了說明,我們在這篇文章中堅持簡單的問題,但 ML 存在的原因是因為在現實世界中,問題要復雜得多。 在這個平面屏幕上,我們最多可以為您繪製一張 3D 數據集的圖片,但 ML 問題通常處理數百萬維的數據和非常複雜的預測函數。 ML 解決了僅靠數值方法無法解決的問題。
考慮到這一點,讓我們看一個簡單的例子。 假設我們有以下培訓數據,其中公司員工對他們的滿意度評分為 1 到 100:
首先,請注意數據有點嘈雜。 也就是說,雖然我們可以看到它有一個規律(即員工的滿意度往往會隨著工資的上漲而上升),但它並不完全符合一條直線。 現實世界的數據總是如此(我們絕對希望使用現實世界的數據來訓練我們的機器!)。 那麼我們如何訓練機器完美預測員工的滿意度呢? 答案當然是我們不能。 ML 的目標絕不是做出“完美”的猜測,因為 ML 處理的領域是不存在這樣的事情的。 目標是做出足夠有用的猜測。
這有點讓人想起英國數學家和統計學教授 George EP Box 的名言“所有模型都是錯誤的,但有些是有用的”。
機器學習在很大程度上建立在統計數據之上。 例如,當我們訓練我們的機器進行學習時,我們必須給它一個統計上顯著的隨機樣本作為訓練數據。 如果訓練集不是隨機的,我們就會冒著機器學習模式實際上並不存在的風險。 如果訓練集太小(參見大數定律),我們將無法學習到足夠的知識,甚至可能得出不准確的結論。 例如,試圖僅根據來自高層管理人員的數據來預測公司範圍內的滿意度模式很可能容易出錯。
有了這種理解,讓我們給我們的機器上面給出的數據並讓它學習它。 首先,我們必須用一些合理的值初始化我們的預測器h(x) 和. 現在我們的預測器在我們的訓練集上看起來像這樣:
如果我們問這個預測器對收入 6 萬美元的員工的滿意度,它會預測評分為 27:
很明顯,這是一個可怕的猜測,而且這台機器知道的並不多。
所以現在,讓我們給這個預測器我們訓練集中的所有薪水,併計算得到的預測滿意度評分與相應員工的實際滿意度評分之間的差異。 如果我們執行一點數學魔法(我將很快描述),我們可以非常確定地計算出 13.12 的值和 0.61 將為我們提供更好的預測器。
如果我們重複這個過程,比如 1500 次,我們的預測器最終會看起來像這樣:
此時,如果我們重複這個過程,我們會發現和不會再有任何明顯的變化,因此我們看到系統已經收斂。 如果我們沒有犯任何錯誤,這意味著我們已經找到了最佳預測器。 因此,如果我們現在再次詢問機器對年收入 6 萬美元的員工的滿意度,它預測的滿意度大約為 60。
現在我們正在取得進展。
機器學習回歸:關於復雜性的說明
上面的例子在技術上是一個簡單的單變量線性回歸問題,實際上可以通過推導一個簡單的正規方程並完全跳過這個“調整”過程來解決。 但是,考慮一個如下所示的預測器:
該函數接受四個維度的輸入,並具有多種多項式項。 推導該函數的正規方程是一項重大挑戰。 許多現代機器學習問題需要數千甚至數百萬維數據來構建使用數百個係數的預測。 預測一個有機體的基因組將如何表達,或者五十年後的氣候會是什麼樣子,就是這類複雜問題的例子。
幸運的是,面對這種複雜性,ML 系統採用的迭代方法更具彈性。 機器學習系統不是使用蠻力,而是“摸索”到答案。 對於大問題,這會更好。 雖然這並不意味著 ML 可以解決所有任意複雜的問題(它不能),但它確實是一個非常靈活和強大的工具。
梯度下降——最小化“錯誤”
讓我們仔細看看這個迭代過程是如何工作的。 在上面的例子中,我們如何確保和每一步都在變得更好,而不是更糟? 答案在於我們前面提到的“錯誤的衡量”,以及一些微積分。
錯誤度量被稱為成本函數(又名損失函數),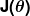 . 輸入
. 輸入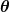 表示我們在預測器中使用的所有係數。 所以在我們的例子中, 真的是一對和.
表示我們在預測器中使用的所有係數。 所以在我們的例子中, 真的是一對和.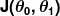 給我們一個數學測量,當它使用給定的值時,我們的預測器是多麼錯誤和.
給我們一個數學測量,當它使用給定的值時,我們的預測器是多麼錯誤和.

成本函數的選擇是 ML 程序的另一個重要部分。 在不同的情況下,“錯誤”可能意味著非常不同的事情。 在我們的員工滿意度示例中,公認的標準是線性最小二乘函數:
使用最小二乘法,錯誤猜測的懲罰隨著猜測和正確答案之間的差異呈二次方上升,因此它可以作為一種非常“嚴格”的錯誤度量。 成本函數計算所有訓練示例的平均懲罰。
所以現在我們看到我們的目標是找到和對於我們的預測器h(x)使得我們的成本函數盡可能小。 我們呼籲微積分的力量來實現這一點。
考慮以下某些特定機器學習問題的成本函數圖:
在這裡,我們可以看到與不同值相關的成本和. 我們可以看到該圖的形狀有一個輕微的碗狀。 碗的底部代表我們的預測器根據給定的訓練數據可以給我們的最低成本。 目標是“滾下山”,找到和對應於這一點。
這就是微積分進入本機器學習教程的地方。 為了使這個解釋易於理解,我不會在這裡寫出方程式,但基本上我們所做的是取梯度,它是的導數對(一個以上還有一個)。 對於每個不同的值,梯度會有所不同和,並告訴我們“山坡是什麼”,尤其是“哪條路向下”,因為這些特殊的s。 例如,當我們插入我們的當前值時進入漸變,它可能會告訴我們,添加一點並從中減去一點將把我們帶到成本函數谷底的方向。 因此,我們加一點, 並減去一點,瞧! 我們已經完成了一輪學習算法。 我們更新的預測器,h(x) = + x,將返回比以前更好的預測。 我們的機器現在更智能了。
這個在計算當前梯度和更新梯度之間交替的過程結果中的 s 稱為梯度下降。
這涵蓋了大多數監督機器學習系統的基本理論。 但是,根據手頭的問題,可以以多種不同的方式應用基本概念。
機器學習中的分類問題
在有監督的 ML 下,兩個主要的子類別是:
- 回歸機器學習系統:被預測的值落在連續範圍內某處的系統。 這些系統幫助我們解決“多少錢?”的問題。 或“有多少?”。
- 分類機器學習系統:我們尋求是或否預測的系統,例如“這個腫瘤是否癌變?”、“這個 cookie 符合我們的質量標準嗎?”等等。
事實證明,基本的機器學習理論或多或少是相同的。 主要區別在於預測器h(x)的設計和成本函數的設計.
到目前為止,我們的示例都集中在回歸問題上,所以現在讓我們來看看一個分類示例。
這是 cookie 質量測試研究的結果,其中所有訓練示例都被標記為藍色的“好 cookie”( y = 1 )或紅色的“壞 cookie”( y = 0 )。
在分類中,回歸預測器不是很有用。 我們通常想要的是一個在 0 和 1 之間進行猜測的預測器。在 cookie 質量分類器中,預測為 1 表示非常有把握地猜測 cookie 是完美的並且完全令人垂涎。 預測值為 0 表示高度相信 cookie 對 cookie 行業來說是一種尷尬。 落在這個範圍內的值代表較低的信心,所以我們可以設計我們的系統,使 0.6 的預測意味著“伙計,這是一個艱難的決定,但我會同意,你可以賣掉那個 cookie”,而一個值正好在中間的 0.5 可能代表完全的不確定性。 這並不總是分類器中置信度的分佈方式,但它是一種非常常見的設計,並且可以用於我們的說明。
事實證明,有一個很好的函數可以很好地捕捉到這種行為。 它被稱為 sigmoid 函數g(z) ,它看起來像這樣:
z是我們的輸入和係數的一些表示,例如:
這樣我們的預測器就變成了:
請注意,sigmoid 函數將我們的輸出轉換為 0 到 1 之間的範圍。
成本函數設計背後的邏輯在分類上也有所不同。 我們再次問“猜測錯誤是什麼意思?” 這一次,一個非常好的經驗法則是,如果正確的猜測是 0 而我們猜測的是 1,那麼我們就完全完全錯誤,反之亦然。 既然你錯得比絕對錯還大,那麼在這種情況下的懲罰是巨大的。 或者,如果正確的猜測是 0 而我們猜測的是 0,那麼我們的成本函數不應該為每次發生這種情況添加任何成本。 如果猜測是正確的,但我們並不完全有信心(例如y = 1 ,但h(x) = 0.8 ),這應該會帶來很小的成本,如果我們的猜測是錯誤的,但我們並不完全有信心(例如y = 1但h(x) = 0.3 ),這應該會帶來一些顯著的成本,但不會像我們完全錯誤的那樣多。
此行為由 log 函數捕獲,例如:
再次,成本函數為我們提供了所有訓練示例的平均成本。
所以在這裡我們已經描述了預測器h(x)和成本函數回歸和分類之間有所不同,但梯度下降仍然可以正常工作。
可以通過繪製邊界線來可視化分類預測器; 即,預測從“是”(預測大於 0.5)變為“否”(預測小於 0.5)的障礙。 通過精心設計的系統,我們的 cookie 數據可以生成如下所示的分類邊界:
現在這是一台對 cookie 了解一兩件事的機器!
神經網絡簡介
如果不至少提及神經網絡,對機器學習的討論是不完整的。 神經網絡不僅為解決非常棘手的問題提供了一種極其強大的工具,而且還為我們自己大腦的運作提供了引人入勝的提示,以及有朝一日創造真正智能機器的有趣可能性。
神經網絡非常適合輸入數量巨大的機器學習模型。 對於我們上面討論的系統類型來說,處理這樣一個問題的計算成本太高了。 然而,事實證明,可以使用原則上與梯度下降非常相似的技術來有效地調整神經網絡。
對神經網絡的全面討論超出了本教程的範圍,但我建議您查看我們之前關於該主題的帖子。
無監督機器學習
無監督機器學習的任務通常是尋找數據中的關係。 此過程中沒有使用任何訓練示例。 取而代之的是,系統被賦予一組數據,並負責尋找其中的模式和相關性。 一個很好的例子是識別社交網絡數據中關係密切的朋友群體。
用於執行此操作的機器學習算法與用於監督學習的算法非常不同,該主題值得單獨發表。 但是,與此同時,如果想了解一些東西,請查看聚類算法,例如 k-means,並查看降維繫統,例如主成分分析。 我們之前關於大數據的文章也更詳細地討論了其中一些主題。
結論
我們已經在這裡介紹了機器學習領域的大部分基本理論,但當然,我們只觸及了皮毛。
請記住,要將本簡介中包含的理論真正應用於現實生活中的機器學習示例,需要對本文討論的主題有更深入的理解。 ML 中存在許多微妙之處和陷阱,並且有許多方式會被看似完美調整的思維機器引入歧途。 基本理論的幾乎每個部分都可以無休止地玩弄和修改,結果往往令人著迷。 許多人成長為更適合特定問題的全新研究領域。
顯然,機器學習是一個非常強大的工具。 在未來幾年,它有望幫助解決我們最緊迫的一些問題,並為數據科學公司開闢全新的機會世界。 對機器學習工程師的需求只會繼續增長,為成為大事的一部分提供了難以置信的機會。 我希望你會考慮加入行動!
致謝
本文大量借鑒了斯坦福教授吳恩達博士在他的免費開放機器學習課程中教授的材料。 該課程深入涵蓋了本文中討論的所有內容,並為 ML 從業者提供了大量實用建議。 對於那些有興趣進一步探索這個迷人領域的人,我不能高度推薦這門課程。
- 健全的邏輯和單調的 AI 模型
- Schooling Flappy Bird:強化學習教程