
Wprowadzenie do teorii uczenia maszynowego i jej zastosowań: wizualny samouczek z przykładami
Opublikowany: 2022-03-11Uczenie maszynowe (ML) zaczyna działać samodzielnie, wraz z rosnącym przekonaniem, że ML może odgrywać kluczową rolę w wielu krytycznych zastosowaniach, takich jak eksploracja danych, przetwarzanie języka naturalnego, rozpoznawanie obrazów i systemy eksperckie. ML zapewnia potencjalne rozwiązania we wszystkich tych dziedzinach i nie tylko, i ma być filarem naszej przyszłej cywilizacji.
Podaż zdolnych projektantów ML jeszcze nie nadążyła za tym zapotrzebowaniem. Głównym tego powodem jest to, że ML jest po prostu podstępny. Ten samouczek dotyczący uczenia maszynowego przedstawia podstawy teorii uczenia maszynowego, określając wspólne motywy i koncepcje, ułatwiając śledzenie logiki i zapoznanie się z podstawami uczenia maszynowego.
Co to jest uczenie maszynowe?
Czym właściwie jest „uczenie maszynowe”? ML to właściwie wiele rzeczy. Dziedzina ta jest dość rozległa i szybko się rozwija, jest nieustannie dzielona i dzielona do znudzenia na różne podspecjalizacje i typy uczenia maszynowego.
Istnieje jednak kilka podstawowych wspólnych wątków, a nadrzędny temat najlepiej podsumowuje często cytowane stwierdzenie Arthura Samuela z 1959 roku: „[Uczenie maszynowe to] dziedzina nauki, która daje komputerom możliwość uczenia się bez są wyraźnie zaprogramowane”.
A ostatnio, w 1997 r., Tom Mitchell podał „dobrze sformułowaną” definicję, która okazała się bardziej użyteczna dla typów inżynierów: „Podobno program komputerowy uczy się na podstawie doświadczenia E w odniesieniu do pewnego zadania T i pewnej miary wydajności P, jeśli jego wydajność na T, mierzona przez P, poprawia się wraz z doświadczeniem E.”
Jeśli więc chcesz, aby Twój program przewidywał na przykład wzorce ruchu na ruchliwym skrzyżowaniu (zadanie T), możesz uruchomić go przez algorytm uczenia maszynowego z danymi o przeszłych wzorcach ruchu (doświadczenie E) i, jeśli pomyślnie „nauczył się”. ”, będzie wtedy lepiej radził sobie z przewidywaniem przyszłych wzorców ruchu (miara wydajności P).
Wysoce złożona natura wielu rzeczywistych problemów często oznacza jednak, że wymyślanie wyspecjalizowanych algorytmów, które za każdym razem doskonale je rozwiążą, jest niepraktyczne, jeśli nie niemożliwe. Przykłady problemów z uczeniem maszynowym to: „Czy to rak?”, „Jaka jest wartość rynkowa tego domu?”, „Który z tych ludzi jest ze sobą dobrymi przyjaciółmi?”, „Czy ten silnik rakietowy eksploduje podczas startu? ”, „Czy tej osobie spodoba się ten film?”, „Kto to jest?”, „Co powiedziałeś?” i „Jak się tym latasz?”. Wszystkie te problemy są doskonałymi celami dla projektu ML i faktycznie ML została zastosowana do każdego z nich z wielkim sukcesem.
Wśród różnych typów zadań ML wyróżnia się kluczowe rozróżnienie między uczeniem nadzorowanym i nienadzorowanym:
- Nadzorowane uczenie maszynowe: program jest „szkolony” na predefiniowanym zestawie „przykładów szkoleniowych”, które następnie ułatwiają mu wyciąganie dokładnych wniosków po otrzymaniu nowych danych.
- Nienadzorowane uczenie maszynowe: program otrzymuje mnóstwo danych i musi znaleźć w nich wzorce i zależności.
Skoncentrujemy się tutaj przede wszystkim na uczeniu nadzorowanym, ale na końcu artykułu znajduje się krótkie omówienie uczenia się bez nadzoru z kilkoma linkami dla tych, którzy są zainteresowani kontynuowaniem tego tematu.
Nadzorowane uczenie maszynowe
W większości zastosowań uczenia nadzorowanego ostatecznym celem jest opracowanie precyzyjnie dostrojonej funkcji predykcyjnej h(x) (czasami nazywanej „hipotezą”). „Uczenie się” polega na użyciu wyrafinowanych algorytmów matematycznych do optymalizacji tej funkcji, tak aby przy danych wejściowych x dotyczących określonej domeny (powiedzmy, kwadratowy obraz domu) dokładnie przewidziała interesującą wartość h(x) (powiedzmy cenę rynkową dla wspomnianego domu).
W praktyce x prawie zawsze reprezentuje wiele punktów danych. Na przykład predyktor cen mieszkań może uwzględniać nie tylko powierzchnię ( x1 ) , ale także liczbę sypialni ( x2 ), liczbę łazienek ( x3 ), liczbę pięter ( x4) , rok budowy ( x5 ), kod pocztowy ( x6 ) i tak dalej. Ważną częścią projektowania ML jest określenie, których danych wejściowych użyć. Jednak dla wyjaśnienia najprościej jest założyć, że używana jest pojedyncza wartość wejściowa.
Powiedzmy, że nasz prosty predyktor ma postać:
gdzie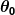 oraz
oraz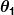 są stałymi. Naszym celem jest znalezienie idealnych wartości oraz aby nasz predyktor działał jak najlepiej.
są stałymi. Naszym celem jest znalezienie idealnych wartości oraz aby nasz predyktor działał jak najlepiej.
Optymalizacja predyktora h(x) odbywa się za pomocą przykładów uczących . Dla każdego przykładu uczącego mamy wartość wejściową x_train , dla której odpowiedni wynik, y , jest z góry znany. Dla każdego przykładu znajdujemy różnicę między znaną, poprawną wartością y , a naszą przewidywaną wartością h(x_train) . Przy wystarczającej liczbie przykładów uczących różnice te dają nam użyteczny sposób mierzenia „nieprawidłowości” h(x) . Następnie możemy dostosować h(x) , dostosowując wartości oraz aby to było „mniej złe”. Ten proces jest powtarzany w kółko, aż system osiągnie najlepsze wartości dla oraz . W ten sposób predyktor zostaje wyszkolony i gotowy do przewidywania w świecie rzeczywistym.
Przykłady uczenia maszynowego
W tym poście trzymamy się prostych problemów dla ilustracji, ale powodem istnienia ML jest to, że w prawdziwym świecie problemy są znacznie bardziej złożone. Na tym płaskim ekranie możemy narysować obraz najwyżej trójwymiarowego zestawu danych, ale problemy z ML zwykle dotyczą danych o milionach wymiarów i bardzo złożonych funkcjach predykcyjnych. ML rozwiązuje problemy, których nie można rozwiązać wyłącznie za pomocą środków numerycznych.
Mając to na uwadze, spójrzmy na prosty przykład. Załóżmy, że mamy następujące dane szkoleniowe, w których pracownicy firmy ocenili swoje zadowolenie w skali od 1 do 100:
Po pierwsze, zauważ, że dane są trochę zaszumione. Oznacza to, że chociaż widzimy, że jest w tym pewien wzór (tj. satysfakcja pracowników rośnie wraz ze wzrostem wynagrodzenia), nie wszystko to pasuje do prostej linii. Tak będzie zawsze w przypadku danych ze świata rzeczywistego (i absolutnie chcemy wyszkolić naszą maszynę przy użyciu danych ze świata rzeczywistego!). Jak zatem wyszkolić maszynę, aby perfekcyjnie przewidywała poziom zadowolenia pracownika? Oczywiście odpowiedź brzmi, że nie możemy. Celem ML nigdy nie jest dokonywanie „doskonałych” domysłów, ponieważ ML zajmuje się domenami, w których czegoś takiego nie ma. Celem jest zgadywanie, które jest wystarczająco dobre, aby było użyteczne.
Przypomina to nieco słynne stwierdzenie brytyjskiego matematyka i profesora statystyki George'a EP Boxa, że „wszystkie modele są złe, ale niektóre są przydatne”.
Uczenie maszynowe opiera się w dużej mierze na statystykach. Na przykład, kiedy trenujemy naszą maszynę do uczenia się, musimy dać jej statystycznie istotną próbkę losową jako dane treningowe. Jeśli zestaw szkoleniowy nie jest losowy, narażamy się na ryzyko wystąpienia wzorców uczenia maszynowego, których w rzeczywistości nie ma. A jeśli zbiór uczący jest zbyt mały (patrz prawo dużych liczb), nie nauczymy się wystarczająco i możemy nawet dojść do nieprecyzyjnych wniosków. Na przykład próba przewidzenia wzorców satysfakcji w całej firmie na podstawie danych z samego kierownictwa wyższego szczebla byłaby prawdopodobnie podatna na błędy.
Mając to zrozumienie, przekażmy naszej maszynie dane, które otrzymaliśmy powyżej, i niech się ich nauczyła. Najpierw musimy zainicjować nasz predyktor h(x) pewnymi rozsądnymi wartościami oraz . Teraz nasz predyktor wygląda tak po umieszczeniu na naszym zestawie treningowym:
Jeśli zapytamy ten predyktor o satysfakcję pracownika zarabiającego 60 tys.
Widać, że to było straszne przypuszczenie i że ta maszyna niewiele wie.
Więc teraz podajmy temu predyktorowi wszystkie pensje z naszego zestawu szkoleniowego i weźmy różnice między wynikającymi z tego przewidywanymi ocenami satysfakcji a rzeczywistymi ocenami satysfakcji odpowiadających im pracowników. Jeśli wykonamy małe matematyczne czary (które opiszę krótko), możemy obliczyć z bardzo dużą pewnością, że wartości 13,12 dla i 0,61 za da nam lepszy predyktor.
A jeśli powtórzymy ten proces, powiedzmy 1500 razy, nasz predyktor będzie wyglądał tak:
W tym momencie, jeśli powtórzymy proces, stwierdzimy, że oraz nie zmieni się już o żadną znaczącą kwotę, a zatem widzimy, że system osiągnął konwergencję. Jeśli nie popełniliśmy żadnych błędów, oznacza to, że znaleźliśmy optymalny predyktor. W związku z tym, jeśli teraz ponownie zapytamy maszynę o ocenę satysfakcji pracownika, który zarabia 60 tys. USD, poda ona ocenę około 60.
Teraz dokądś zmierzamy.
Regresja uczenia maszynowego: uwaga na temat złożoności
Powyższy przykład jest technicznie prostym problemem jednowymiarowej regresji liniowej, który w rzeczywistości można rozwiązać, wyprowadzając proste równanie normalne i całkowicie pomijając ten proces „dostrajania”. Rozważ jednak predyktor, który wygląda tak:
Ta funkcja przyjmuje dane wejściowe w czterech wymiarach i zawiera różne wyrażenia wielomianowe. Wyprowadzenie normalnego równania dla tej funkcji jest poważnym wyzwaniem. Wiele współczesnych problemów z uczeniem maszynowym wymaga tysięcy, a nawet milionów wymiarów danych, aby zbudować prognozy przy użyciu setek współczynników. Przewidywanie, w jaki sposób zostanie wyrażony genom organizmu lub jaki będzie klimat za pięćdziesiąt lat, to przykłady tak złożonych problemów.
Na szczęście podejście iteracyjne stosowane przez systemy ML jest znacznie bardziej odporne na taką złożoność. Zamiast używać brutalnej siły, system uczenia maszynowego „namierza” odpowiedź. W przypadku dużych problemów działa to znacznie lepiej. Chociaż nie oznacza to, że ML może rozwiązać wszystkie dowolnie złożone problemy (nie może), to jest niezwykle elastycznym i potężnym narzędziem.
Spadek gradientu — minimalizacja „błędu”
Przyjrzyjmy się bliżej, jak działa ten iteracyjny proces. W powyższym przykładzie, jak się upewniamy? oraz z każdym krokiem są coraz lepsze, a nie gorsze? Odpowiedź tkwi w naszym „pomiarze niesłuszności”, o którym wspomnieliśmy wcześniej, wraz z odrobiną rachunku różniczkowego.

Miara nieprawidłowości jest znana jako funkcja kosztu (inaczej funkcja straty ),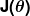 . Wejście
. Wejście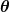 reprezentuje wszystkie współczynniki, których używamy w naszym predyktorze. Więc w naszym przypadku to naprawdę para? oraz .
reprezentuje wszystkie współczynniki, których używamy w naszym predyktorze. Więc w naszym przypadku to naprawdę para? oraz .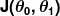 daje nam matematyczny pomiar tego, jak błędny jest nasz predyktor, gdy używa danych wartości oraz .
daje nam matematyczny pomiar tego, jak błędny jest nasz predyktor, gdy używa danych wartości oraz .
Kolejnym ważnym elementem programu ML jest wybór funkcji kosztu. W różnych kontekstach bycie „w błędzie” może oznaczać bardzo różne rzeczy. W naszym przykładzie zadowolenia pracowników uznanym standardem jest liniowa funkcja najmniejszych kwadratów:
Przy najmniejszej liczbie kwadratów kara za błędne odgadnięcie rośnie kwadratowo wraz z różnicą między domysłem a poprawną odpowiedzią, więc działa to jak bardzo „ścisła” miara błędu. Funkcja kosztu oblicza średnią karę we wszystkich przykładach szkoleniowych.
Więc teraz widzimy, że naszym celem jest znalezienie oraz dla naszego predyktora h(x) tak, że nasza funkcja kosztu jest tak mały, jak to tylko możliwe. Wzywamy do tego moc rachunku różniczkowego.
Rozważmy następujący wykres funkcji kosztu dla konkretnego problemu z uczeniem maszynowym:
Tutaj widzimy koszt związany z różnymi wartościami oraz . Widzimy, że wykres ma niewielką miskę w swoim kształcie. Dno miski reprezentuje najniższy koszt, jaki może nam dać nasz predyktor na podstawie danych treningowych. Celem jest „toczenie się ze wzgórza” i odnalezienie oraz odpowiadające temu punktowi.
W tym samouczku dotyczącym uczenia maszynowego pojawia się rachunek różniczkowy. Aby to wyjaśnienie było możliwe do opanowania, nie będę tutaj pisał równań, ale zasadniczo to, co robimy, to bierzemy gradient , która jest parą pochodnych (jeden ponad i jeden ponad ). Gradient będzie inny dla każdej innej wartości oraz i mówi nam, jakie jest „nachylenie wzgórza”, a w szczególności „która droga jest w dół”, dla tych konkretnych s. Na przykład, gdy podłączymy nasze obecne wartości do gradientu, może nam to powiedzieć, że dodanie trochę do i odejmuję trochę od zaprowadzi nas w stronę funkcji kosztowo-dolnej podłogi. Dlatego dodajemy trochę do i odejmij trochę od i voila! Zakończyliśmy jedną rundę naszego algorytmu uczenia. Nasz zaktualizowany predyktor, h(x) = + x, zwróci lepsze przewidywania niż wcześniej. Nasza maszyna jest teraz trochę inteligentniejsza.
Ten proces naprzemiennego obliczania bieżącego gradientu i aktualizowania Na podstawie wyników określa się mianem opadania gradientowego.
Obejmuje to podstawową teorię leżącą u podstaw większości nadzorowanych systemów uczenia maszynowego. Jednak podstawowe koncepcje można zastosować na wiele różnych sposobów, w zależności od problemu.
Problemy z klasyfikacją w uczeniu maszynowym
W ramach nadzorowanego ML istnieją dwie główne podkategorie:
- Systemy uczenia maszynowego regresji: Systemy, w których przewidywana wartość spada gdzieś w ciągłym spektrum. Te systemy pomagają nam w pytaniach „Ile?” lub „Ile?”.
- Klasyfikacja systemów uczenia maszynowego: Systemy, w których szukamy prognozy typu „tak lub nie”, na przykład „Czy ten guz jest rakowy?”, „Czy ten plik cookie spełnia nasze standardy jakości?” i tak dalej.
Jak się okazuje, podstawowa teoria uczenia maszynowego jest mniej więcej taka sama. Główne różnice to projekt predyktora h(x) i projekt funkcji kosztu .
Nasze dotychczasowe przykłady koncentrowały się na problemach regresji, więc przyjrzyjmy się teraz również przykładowi klasyfikacji.
Oto wyniki badania jakości ciasteczek, w których wszystkie przykłady szkoleniowe zostały oznaczone jako „dobre ciastko” ( y = 1 ) na niebiesko lub „złe ciastko” ( y = 0 ) na czerwono.
W klasyfikacji predyktor regresji nie jest zbyt przydatny. To, czego zwykle potrzebujemy, to predyktor, który odgadnie gdzieś między 0 a 1. W klasyfikatorze jakości ciasteczek predykcja 1 oznaczałaby bardzo pewne przypuszczenie, że ciasteczko jest idealne i całkowicie apetyczne. Przewidywana wartość 0 oznacza dużą pewność, że ciasteczko wprawia branżę ciasteczek w zakłopotanie. Wartości mieszczące się w tym zakresie oznaczają mniejszą pewność, więc możemy zaprojektować nasz system w taki sposób, aby przewidywanie 0,6 oznaczało „Człowieku, to trudne wezwanie, ale pójdę z tak, możesz sprzedać to ciasteczko”, podczas gdy wartość dokładnie w środek, na poziomie 0,5, może oznaczać całkowitą niepewność. Nie zawsze tak rozkłada się zaufanie w klasyfikatorze, ale jest to bardzo powszechny projekt i działa na potrzeby naszej ilustracji.
Okazuje się, że istnieje fajna funkcja, która dobrze oddaje to zachowanie. Nazywa się to funkcją sigmoid, g(z) i wygląda mniej więcej tak:
z jest pewną reprezentacją naszych danych wejściowych i współczynników, takich jak:
aby nasz predyktor stał się:
Zauważ, że funkcja sigmoid przekształca nasze wyjście w zakres od 0 do 1.
Logika stojąca za projektem funkcji kosztu jest również inna pod względem klasyfikacji. Ponownie pytamy „co to znaczy, że odgadnięcie jest błędne?” i tym razem bardzo dobrą praktyczną zasadą jest to, że jeśli poprawnym domysłem było 0, a my 1, to całkowicie i całkowicie się myliliśmy i vice versa. Ponieważ nie można się mylić bardziej niż całkowicie się mylić, kara w tym przypadku jest ogromna. Alternatywnie, jeśli poprawnym przypuszczeniem było 0, a my zgadliśmy 0, nasza funkcja kosztu nie powinna dodawać żadnych kosztów za każdym razem, gdy to się dzieje. Jeśli przypuszczenie było prawidłowe, ale nie byliśmy całkowicie pewni (np. y = 1 , ale h(x) = 0.8 ), powinno to mieć niewielki koszt, a jeśli nasze przypuszczenie było błędne, ale nie byliśmy całkowicie pewni ( np. y = 1 , ale h(x) = 0.3 ), powinno to wiązać się z pewnymi znaczącymi kosztami, ale nie tak dużymi, jakbyśmy byli całkowicie w błędzie.
To zachowanie jest wychwytywane przez funkcję dziennika, w taki sposób, że:
Znowu funkcja kosztów daje nam średni koszt we wszystkich naszych przykładach szkoleniowych.
Więc tutaj opisaliśmy, jak predyktor h(x) i funkcja kosztu różnią się między regresją a klasyfikacją, ale zejście gradientowe nadal działa dobrze.
Predyktor klasyfikacji można zwizualizować, rysując linię graniczną; tj. bariera, w której prognoza zmienia się z „tak” (prognoza większa niż 0,5) na „nie” (prognoza mniejsza niż 0,5). W dobrze zaprojektowanym systemie nasze dane z plików cookie mogą generować granicę klasyfikacji, która wygląda następująco:
Teraz to maszyna, która wie coś o ciasteczkach!
Wprowadzenie do sieci neuronowych
Żadna dyskusja na temat uczenia maszynowego nie byłaby kompletna, gdyby nie wspomnieć choćby o sieciach neuronowych. Sieci neuronowe są nie tylko niezwykle potężnym narzędziem do rozwiązywania bardzo trudnych problemów, ale także oferują fascynujące wskazówki dotyczące pracy naszych własnych mózgów i intrygujące możliwości stworzenia prawdziwie inteligentnych maszyn.
Sieci neuronowe doskonale nadają się do modeli uczenia maszynowego, w których liczba wejść jest gigantyczna. Koszt obliczeniowy rozwiązania takiego problemu jest zbyt przytłaczający dla typów systemów, które omówiliśmy powyżej. Jak się jednak okazuje, sieci neuronowe można skutecznie dostroić za pomocą technik, które są w zasadzie uderzająco podobne do opadania gradientowego.
Dokładne omówienie sieci neuronowych wykracza poza zakres tego samouczka, ale polecam sprawdzić nasz poprzedni post na ten temat.
Nienadzorowane uczenie maszynowe
Zadaniem nienadzorowanego uczenia maszynowego jest zazwyczaj znajdowanie relacji w danych. W tym procesie nie są używane żadne przykłady szkoleniowe. Zamiast tego system otrzymuje zestaw danych i ma za zadanie znaleźć w nich wzorce i korelacje. Dobrym przykładem jest identyfikacja blisko powiązanych grup znajomych w danych z sieci społecznościowych.
Wykorzystywane do tego algorytmy uczenia maszynowego bardzo różnią się od tych używanych do uczenia nadzorowanego, a temat zasługuje na własny post. Jednak, aby w międzyczasie coś przegryźć, spójrz na algorytmy grupowania, takie jak k-średnie, a także przyjrzyj się systemom redukcji wymiarowości, takim jak analiza głównych komponentów. W naszym poprzednim poście dotyczącym dużych zbiorów danych omówiono również wiele z tych tematów bardziej szczegółowo.
Wniosek
Omówiliśmy tutaj wiele podstawowych teorii leżących u podstaw uczenia maszynowego, ale oczywiście tylko ledwo zarysowaliśmy powierzchnię.
Należy pamiętać, że aby naprawdę zastosować teorie zawarte w tym wprowadzeniu do rzeczywistych przykładów uczenia maszynowego, konieczne jest znacznie głębsze zrozumienie omawianych tu tematów. Istnieje wiele subtelności i pułapek w ML, a także wiele sposobów na sprowadzenie na manowce czegoś, co wydaje się być doskonale dostrojoną maszyną myślącą. Prawie każdą częścią podstawowej teorii można bawić się i zmieniać w nieskończoność, a wyniki są często fascynujące. Wiele z nich wyrasta na zupełnie nowe kierunki studiów, lepiej dostosowane do konkretnych problemów.
Oczywiście uczenie maszynowe jest niesamowicie potężnym narzędziem. W nadchodzących latach obiecuje pomóc rozwiązać niektóre z naszych najbardziej palących problemów, a także otworzyć zupełnie nowe światy możliwości dla firm zajmujących się analizą danych. Zapotrzebowanie na inżynierów uczenia maszynowego będzie nadal rosło, oferując niesamowite szanse na bycie częścią czegoś dużego. Mam nadzieję, że rozważysz udział w akcji!
Potwierdzenie
Ten artykuł w dużej mierze opiera się na materiałach nauczanych przez profesora Stanford dr Andrew Ng podczas jego bezpłatnego i otwartego kursu uczenia maszynowego. Kurs szczegółowo omawia wszystko, co omówiono w tym artykule, i daje mnóstwo praktycznych porad dla praktyka ML. Nie mogę wystarczająco polecić tego kursu osobom zainteresowanym dalszym zgłębianiem tej fascynującej dziedziny.
- Modele logiki dźwiękowej i monotonicznej sztucznej inteligencji
- Szkolenie Flappy Bird: samouczek do nauki wzmacniania