
Un'introduzione alla teoria dell'apprendimento automatico e alle sue applicazioni: un tutorial visivo con esempi
Pubblicato: 2022-03-11L'apprendimento automatico (ML) sta prendendo piede, con un crescente riconoscimento che il ML può svolgere un ruolo chiave in un'ampia gamma di applicazioni critiche, come data mining, elaborazione del linguaggio naturale, riconoscimento di immagini e sistemi esperti. Il ML fornisce potenziali soluzioni in tutti questi domini e altro, ed è destinato a diventare un pilastro della nostra civiltà futura.
L'offerta di abili progettisti di ML non ha ancora raggiunto questa domanda. Una delle ragioni principali di ciò è che ML è semplicemente complicato. Questo tutorial sull'apprendimento automatico introduce le basi della teoria del machine learning, definendo i temi e i concetti comuni, semplificando il seguire la logica e acquisire familiarità con le basi dell'apprendimento automatico.
Che cos'è l'apprendimento automatico?
Quindi cos'è esattamente il "machine learning" comunque? ML è in realtà molte cose. Il campo è piuttosto vasto e si sta espandendo rapidamente, essendo continuamente suddiviso e sub-partizionato fino alla nausea in diverse sottospecialità e tipi di apprendimento automatico.
Ci sono alcuni fili comuni di base, tuttavia, e il tema generale è meglio riassunto da questa dichiarazione spesso citata da Arthur Samuel nel lontano 1959: "[Machine Learning è il] campo di studio che offre ai computer la capacità di apprendere senza programmato in modo esplicito”.
E più recentemente, nel 1997, Tom Mitchell ha fornito una definizione "ben posta" che si è dimostrata più utile ai tipi di ingegneria: "Si dice che un programma per computer impari dall'esperienza E rispetto a qualche compito T e a qualche misura di prestazione P, se le sue prestazioni su T, misurate da P, migliorano con l'esperienza E.
Quindi, se vuoi che il tuo programma preveda, ad esempio, i modelli di traffico in un incrocio trafficato (attività T), puoi eseguirlo attraverso un algoritmo di apprendimento automatico con dati sui modelli di traffico passati (esperienza E) e, se ha "appreso con successo ”, sarà quindi in grado di prevedere meglio i modelli di traffico futuri (misura delle prestazioni P).
La natura altamente complessa di molti problemi del mondo reale, tuttavia, spesso significa che inventare algoritmi specializzati che li risolvano perfettamente ogni volta è impraticabile, se non impossibile. Esempi di problemi di apprendimento automatico includono: "È un cancro?", "Qual è il valore di mercato di questa casa?", "Chi di queste persone è un buon amico?", "Questo motore a razzo esploderà al decollo? ”, “A questa persona piacerà questo film?”, “Chi è questo?”, “Cosa hai detto?” e “Come fai a pilotare questa cosa?”. Tutti questi problemi sono ottimi bersagli per un progetto ML, e infatti il ML è stato applicato a ciascuno di essi con grande successo.
Tra i diversi tipi di attività ML, viene tracciata una distinzione cruciale tra apprendimento supervisionato e non supervisionato:
- Apprendimento automatico supervisionato: il programma viene "addestrato" su una serie predefinita di "esempi di formazione", che quindi facilitano la sua capacità di raggiungere una conclusione accurata quando vengono forniti nuovi dati.
- Apprendimento automatico non supervisionato: il programma riceve una serie di dati e deve trovare schemi e relazioni in essi.
Ci concentreremo principalmente sull'apprendimento supervisionato qui, ma la fine dell'articolo include una breve discussione sull'apprendimento non supervisionato con alcuni collegamenti per coloro che sono interessati a approfondire l'argomento.
Apprendimento automatico supervisionato
Nella maggior parte delle applicazioni di apprendimento supervisionato, l'obiettivo finale è quello di sviluppare una funzione predittiva finemente sintonizzata h(x) (a volte chiamata "ipotesi"). "Apprendimento" consiste nell'utilizzare sofisticati algoritmi matematici per ottimizzare questa funzione in modo che, dati i dati di input x su un determinato dominio (ad esempio, la metratura di una casa), preveda con precisione un valore interessante h(x) (ad esempio, il prezzo di mercato per detta casa).
In pratica, x rappresenta quasi sempre più punti dati. Quindi, ad esempio, un predittore del prezzo delle abitazioni potrebbe richiedere non solo il metro quadrato ( x1 ) ma anche il numero di camere da letto ( x2 ), il numero di bagni ( x3 ), il numero di piani ( x4) , l'anno di costruzione ( x5 ), il codice postale ( x6 ) e così via. La determinazione degli input da utilizzare è una parte importante della progettazione ML. Tuttavia, per motivi di spiegazione, è più semplice presumere che venga utilizzato un unico valore di input.
Quindi supponiamo che il nostro semplice predittore abbia questa forma:
dove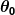 e
e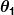 sono costanti. Il nostro obiettivo è trovare i valori perfetti di e per far funzionare il nostro predittore nel miglior modo possibile.
sono costanti. Il nostro obiettivo è trovare i valori perfetti di e per far funzionare il nostro predittore nel miglior modo possibile.
L'ottimizzazione del predittore h(x) viene eseguita utilizzando esempi di addestramento . Per ogni esempio di addestramento, abbiamo un valore di input x_train , per il quale è noto in anticipo un output corrispondente, y . Per ogni esempio, troviamo la differenza tra il valore noto e corretto y e il nostro valore previsto h(x_train) . Con un numero sufficiente di esempi di addestramento, queste differenze ci forniscono un modo utile per misurare l'"errore" di h(x) . Possiamo quindi modificare h(x) modificando i valori di e per renderlo “meno sbagliato”. Questo processo viene ripetuto più e più volte fino a quando il sistema non è convergente sui valori migliori per e . In questo modo, il predittore viene addestrato ed è pronto per eseguire alcune previsioni del mondo reale.
Esempi di apprendimento automatico
Ci atteniamo a problemi semplici in questo post per motivi illustrativi, ma il motivo per cui esiste ML è perché, nel mondo reale, i problemi sono molto più complessi. Su questo schermo piatto possiamo tracciare un'immagine di, al massimo, un set di dati tridimensionale, ma i problemi di ML riguardano comunemente dati con milioni di dimensioni e funzioni predittive molto complesse. ML risolve problemi che non possono essere risolti solo con mezzi numerici.
Con questo in mente, diamo un'occhiata a un semplice esempio. Supponiamo di avere i seguenti dati sulla formazione, in cui i dipendenti dell'azienda hanno valutato la loro soddisfazione su una scala da 1 a 100:
Innanzitutto, nota che i dati sono un po' rumorosi. Cioè, mentre possiamo vedere che c'è uno schema (cioè la soddisfazione dei dipendenti tende ad aumentare all'aumentare dello stipendio), non tutto si adatta perfettamente su una linea retta. Questo sarà sempre il caso dei dati del mondo reale (e vogliamo assolutamente addestrare la nostra macchina utilizzando i dati del mondo reale!). Allora come possiamo addestrare una macchina per prevedere perfettamente il livello di soddisfazione di un dipendente? La risposta, ovviamente, è che non possiamo. L'obiettivo del ML non è mai fare ipotesi "perfette", perché il ML si occupa di domini in cui non esiste una cosa del genere. L'obiettivo è fare ipotesi che siano abbastanza buone da essere utili.
Ricorda in qualche modo la famosa affermazione del matematico e professore di statistica britannico George EP Box secondo cui "tutti i modelli sono sbagliati, ma alcuni sono utili".
Machine Learning si basa molto sulle statistiche. Ad esempio, quando alleniamo la nostra macchina per l'apprendimento, dobbiamo fornirle un campione casuale statisticamente significativo come dati di addestramento. Se il set di addestramento non è casuale, corriamo il rischio che i modelli di apprendimento automatico non siano effettivamente presenti. E se il training set è troppo piccolo (vedi legge dei grandi numeri), non impareremo abbastanza e potremmo arrivare anche a conclusioni imprecise. Ad esempio, il tentativo di prevedere i modelli di soddisfazione dell'intera azienda sulla base dei dati dei soli vertici aziendali sarebbe probabilmente soggetto a errori.
Con questa comprensione, diamo alla nostra macchina i dati che ci sono stati forniti sopra e facciamo in modo che li impari. Per prima cosa dobbiamo inizializzare il nostro predittore h(x) con alcuni valori ragionevoli di e . Ora il nostro predittore appare così quando posizionato sopra il nostro set di allenamento:
Se chiediamo a questo predittore la soddisfazione di un dipendente che guadagna $ 60.000, prevediamo un punteggio di 27:
È ovvio che questa è stata un'ipotesi terribile e che questa macchina non sa molto.
Quindi ora, diamo a questo predittore tutti gli stipendi dal nostro set di formazione e prendiamo le differenze tra le valutazioni di soddisfazione previste risultanti e le valutazioni di soddisfazione effettive dei dipendenti corrispondenti. Se eseguiamo un piccolo mago matematico (che descriverò tra breve), possiamo calcolare, con altissima certezza, quel valore di 13,12 per e 0,61 per ci daranno un predittore migliore.
E se ripetiamo questo processo, diciamo 1500 volte, il nostro predittore finirà per assomigliare a questo:
A questo punto, se ripetiamo il processo, lo troveremo e non cambierà più di un importo apprezzabile e quindi vediamo che il sistema è convergente. Se non abbiamo commesso errori, significa che abbiamo trovato il predittore ottimale. Di conseguenza, se ora chiediamo nuovamente alla macchina la valutazione di soddisfazione del dipendente che guadagna $ 60.000, prevediamo una valutazione di circa 60.
Ora stiamo arrivando da qualche parte.
Regressione dell'apprendimento automatico: una nota sulla complessità
L'esempio sopra è tecnicamente un semplice problema di regressione lineare univariata, che in realtà può essere risolto derivando una semplice equazione normale e saltando del tutto questo processo di "ottimizzazione". Tuttavia, considera un predittore simile a questo:
Questa funzione riceve input in quattro dimensioni e ha una varietà di termini polinomiali. Derivare un'equazione normale per questa funzione è una sfida significativa. Molti moderni problemi di apprendimento automatico richiedono migliaia o addirittura milioni di dimensioni di dati per creare previsioni utilizzando centinaia di coefficienti. Prevedere come verrà espresso il genoma di un organismo, o come sarà il clima tra cinquant'anni, sono esempi di problemi così complessi.
Fortunatamente, l'approccio iterativo adottato dai sistemi ML è molto più resiliente di fronte a tale complessità. Invece di usare la forza bruta, un sistema di apprendimento automatico "si fa strada" verso la risposta. Per grossi problemi, funziona molto meglio. Anche se questo non significa che ML possa risolvere tutti i problemi arbitrariamente complessi (non può), rappresenta uno strumento incredibilmente flessibile e potente.
Discesa graduale - Ridurre al minimo "l'errore"
Diamo un'occhiata più da vicino a come funziona questo processo iterativo. Nell'esempio sopra, come possiamo assicurarci e stanno migliorando ad ogni passo e non peggio? La risposta sta nella nostra "misurazione dell'errore" a cui si è accennato in precedenza, insieme a un piccolo calcolo.

La misura dell'erroneità è nota come funzione di costo (aka, funzione di perdita ),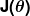 . L'ingresso
. L'ingresso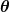 rappresenta tutti i coefficienti che stiamo usando nel nostro predittore. Quindi nel nostro caso è davvero la coppia e .
rappresenta tutti i coefficienti che stiamo usando nel nostro predittore. Quindi nel nostro caso è davvero la coppia e .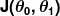 ci fornisce una misurazione matematica di quanto sia sbagliato il nostro predittore quando utilizza i valori dati di e .
ci fornisce una misurazione matematica di quanto sia sbagliato il nostro predittore quando utilizza i valori dati di e .
La scelta della funzione di costo è un altro elemento importante di un programma ML. In contesti diversi, essere "sbagliato" può significare cose molto diverse. Nel nostro esempio di soddisfazione dei dipendenti, lo standard consolidato è la funzione dei minimi quadrati lineari:
Con i minimi quadrati, la penalità per un'ipotesi errata aumenta quadraticamente con la differenza tra l'ipotesi e la risposta corretta, quindi agisce come una misurazione molto "rigorosa" dell'errore. La funzione di costo calcola una penalità media su tutti gli esempi di addestramento.
Quindi ora vediamo che il nostro obiettivo è trovare e per il nostro predittore h(x) tale che la nostra funzione di costo è il più piccolo possibile. Facciamo appello al potere del calcolo per raggiungere questo obiettivo.
Considera il grafico seguente di una funzione di costo per un particolare problema di Machine Learning:
Qui possiamo vedere il costo associato a diversi valori di e . Possiamo vedere che il grafico ha una leggera forma a scodella. Il fondo della ciotola rappresenta il costo più basso che il nostro predittore può darci in base ai dati di allenamento forniti. L'obiettivo è "rotolare giù per la collina" e trovare e corrispondente a questo punto.
È qui che entra in gioco il calcolo in questo tutorial di apprendimento automatico. Per mantenere questa spiegazione gestibile, non scriverò le equazioni qui, ma essenzialmente quello che facciamo è prendere il gradiente di , che è la coppia di derivate di (uno sopra e uno sopra ). Il gradiente sarà diverso per ogni diverso valore di e , e ci dice qual è il “pendio della collina” e, in particolare, “da che parte è in discesa”, per questi particolari S. Ad esempio, quando colleghiamo i nostri valori attuali di nel gradiente, potrebbe dirci che aggiungendo un po 'a e sottraendo un po' da ci porterà nella direzione della funzione di costo-piano valle. Pertanto, aggiungiamo un po ' , e sottrai un po' da , e voilà! Abbiamo completato un round del nostro algoritmo di apprendimento. Il nostro predittore aggiornato, h(x) = + x, restituirà previsioni migliori rispetto a prima. La nostra macchina ora è un po' più intelligente.
Questo processo di alternanza tra il calcolo del gradiente attuale e l'aggiornamento del s dai risultati, è noto come discesa del gradiente.
Ciò copre la teoria di base alla base della maggior parte dei sistemi di Machine Learning supervisionati. Ma i concetti di base possono essere applicati in una varietà di modi diversi, a seconda del problema in questione.
Problemi di classificazione nell'apprendimento automatico
Sotto il riciclaggio controllato, due principali sottocategorie sono:
- Sistemi di apprendimento automatico di regressione: sistemi in cui il valore previsto cade da qualche parte su uno spettro continuo. Questi sistemi ci aiutano con domande di "Quanto?" o "Quanti?".
- Sistemi di apprendimento automatico di classificazione: sistemi in cui cerchiamo una previsione sì o no, ad esempio "Questo tumer è canceroso?", "Questo cookie soddisfa i nostri standard di qualità?" e così via.
A quanto pare, la teoria sottostante dell'apprendimento automatico è più o meno la stessa. Le principali differenze sono la progettazione del predittore h(x) e la progettazione della funzione di costo .
I nostri esempi finora si sono concentrati sui problemi di regressione, quindi diamo ora un'occhiata anche a un esempio di classificazione.
Ecco i risultati di uno studio di test sulla qualità dei cookie, in cui gli esempi di formazione sono stati tutti etichettati come "biscotto buono" ( y = 1 ) in blu o "cattivo cookie" ( y = 0 ) in rosso.
Nella classificazione, un predittore di regressione non è molto utile. Quello che di solito vogliamo è un predittore che faccia un'ipotesi tra 0 e 1. In un classificatore di qualità del cookie, una previsione di 1 rappresenterebbe un'ipotesi molto sicura che il biscotto sia perfetto e assolutamente appetitoso. Una previsione di 0 rappresenta un'elevata sicurezza che il cookie sia fonte di imbarazzo per l'industria dei cookie. I valori che rientrano in questo intervallo rappresentano meno fiducia, quindi potremmo progettare il nostro sistema in modo tale che la previsione di 0,6 significhi "Amico, è una chiamata difficile, ma andrò con sì, puoi vendere quel cookie", mentre un valore esattamente in la metà, a 0,5, potrebbe rappresentare una completa incertezza. Questo non è sempre il modo in cui la fiducia viene distribuita in un classificatore, ma è un design molto comune e funziona ai fini della nostra illustrazione.
Si scopre che c'è una bella funzione che cattura bene questo comportamento. Si chiama funzione sigmoide, g(z) , e ha un aspetto simile a questo:
z è una rappresentazione dei nostri input e coefficienti, come ad esempio:
in modo che il nostro predittore diventi:
Si noti che la funzione sigmoide trasforma il nostro output nell'intervallo compreso tra 0 e 1.
Anche la logica alla base della progettazione della funzione di costo è diversa nella classificazione. Ancora una volta chiediamo "cosa significa che un'ipotesi è sbagliata?" e questa volta un'ottima regola pratica è che se l'ipotesi corretta era 0 e noi indovinavamo 1, allora ci sbagliavamo completamente e totalmente, e viceversa. Dal momento che non puoi essere più sbagliato che assolutamente sbagliato, la sanzione in questo caso è enorme. In alternativa, se l'ipotesi corretta era 0 e abbiamo ipotizzato 0, la nostra funzione di costo non dovrebbe aggiungere alcun costo per ogni volta che ciò accade. Se l'ipotesi era corretta, ma non eravamo completamente sicuri (ad es. y = 1 , ma h(x) = 0.8 ), questo dovrebbe avere un piccolo costo e se la nostra ipotesi era sbagliata ma non eravamo completamente sicuri ( ad esempio y = 1 ma h(x) = 0.3 ), questo dovrebbe comportare un costo significativo, ma non tanto quanto se ci sbagliassimo completamente.
Questo comportamento viene catturato dalla funzione di registro, in modo tale che:
Ancora una volta, la funzione di costo ci fornisce il costo medio su tutti i nostri esempi di formazione.
Quindi qui abbiamo descritto come il predittore h(x) e la funzione di costo differiscono tra regressione e classificazione, ma la discesa del gradiente funziona ancora bene.
Un predittore di classificazione può essere visualizzato tracciando la linea di confine; cioè, la barriera in cui la previsione cambia da un "sì" (una previsione maggiore di 0,5) a un "no" (una previsione inferiore a 0,5). Con un sistema ben progettato, i nostri dati sui cookie possono generare un confine di classificazione simile al seguente:
Questa è una macchina che sa una cosa o due sui biscotti!
Un'introduzione alle reti neurali
Nessuna discussione sull'apprendimento automatico sarebbe completa senza almeno menzionare le reti neurali. Non solo le reti neurali offrono uno strumento estremamente potente per risolvere problemi molto difficili, ma offrono anche affascinanti spunti sul funzionamento del nostro cervello e possibilità intriganti per creare un giorno macchine veramente intelligenti.
Le reti neurali si adattano bene ai modelli di apprendimento automatico in cui il numero di input è gigantesco. Il costo computazionale della gestione di un tale problema è semplicemente troppo schiacciante per i tipi di sistemi di cui abbiamo discusso sopra. A quanto pare, tuttavia, le reti neurali possono essere ottimizzate in modo efficace utilizzando tecniche sorprendentemente simili alla discesa del gradiente in linea di principio.
Una discussione approfondita delle reti neurali va oltre lo scopo di questo tutorial, ma consiglio di dare un'occhiata al nostro post precedente sull'argomento.
Apprendimento automatico senza supervisione
L'apprendimento automatico non supervisionato ha in genere il compito di trovare relazioni all'interno dei dati. Non ci sono esempi di formazione utilizzati in questo processo. Al sistema, invece, viene fornito un insieme di dati e il compito di trovare schemi e correlazioni al loro interno. Un buon esempio è l'identificazione di gruppi affiatati di amici nei dati dei social network.
Gli algoritmi di Machine Learning utilizzati per farlo sono molto diversi da quelli utilizzati per l'apprendimento supervisionato e l'argomento merita un post a parte. Tuttavia, per qualcosa su cui masticare nel frattempo, dai un'occhiata agli algoritmi di clustering come k-mean e guarda anche ai sistemi di riduzione della dimensionalità come l'analisi dei componenti principali. Il nostro precedente post sui big data discute anche una serie di questi argomenti in modo più dettagliato.
Conclusione
Abbiamo trattato gran parte della teoria di base alla base del campo dell'apprendimento automatico qui, ma ovviamente ne abbiamo appena scalfito la superficie.
Tieni presente che per applicare realmente le teorie contenute in questa introduzione a esempi di apprendimento automatico nella vita reale, è necessaria una comprensione molto più approfondita degli argomenti qui discussi. Ci sono molte sottigliezze e insidie nel ML e molti modi per essere fuorviati da quella che sembra essere una macchina pensante perfettamente sintonizzata. Quasi ogni parte della teoria di base può essere giocata e modificata all'infinito, ei risultati sono spesso affascinanti. Molti crescono in campi di studio completamente nuovi che sono più adatti a problemi particolari.
Chiaramente, il Machine Learning è uno strumento incredibilmente potente. Nei prossimi anni, promette di aiutare a risolvere alcuni dei nostri problemi più urgenti, oltre ad aprire nuovi mondi di opportunità per le aziende di scienza dei dati. La domanda di ingegneri di Machine Learning continuerà a crescere, offrendo incredibili possibilità di far parte di qualcosa di grande. Spero che prenderai in considerazione l'idea di entrare in azione!
Riconoscimento
Questo articolo attinge ampiamente dal materiale insegnato dal Professore di Stanford Dr. Andrew Ng nel suo corso gratuito e aperto di Machine Learning. Il corso copre tutto ciò che è discusso in questo articolo in modo molto approfondito e offre moltissimi consigli pratici per il professionista del ML. Non posso raccomandare abbastanza questo corso a coloro che sono interessati ad esplorare ulteriormente questo affascinante campo.
- Logica sonora e modelli di intelligenza artificiale monotona
- Schooling Flappy Bird: un tutorial per l'apprendimento del rinforzo