
O introducere în teoria învățării automate și aplicațiile sale: un tutorial vizual cu exemple
Publicat: 2022-03-11Învățarea automată (ML) își asumă puterea, cu o recunoaștere tot mai mare a faptului că ML poate juca un rol cheie într-o gamă largă de aplicații critice, cum ar fi extragerea datelor, procesarea limbajului natural, recunoașterea imaginilor și sistemele expert. ML oferă soluții potențiale în toate aceste domenii și nu numai și este setat să fie un pilon al civilizației noastre viitoare.
Oferta de designeri ML capabili nu a ajuns încă la această cerere. Un motiv major pentru aceasta este că ML este pur și simplu complicat. Acest tutorial de învățare automată prezintă elementele de bază ale teoriei ML, stabilind temele și conceptele comune, facilitând urmărirea logicii și familiarizarea cu elementele de bază ale învățării automate.
Ce este Machine Learning?
Deci, ce este exact „învățarea automată”? ML este de fapt o mulțime de lucruri. Domeniul este destul de vast și se extinde rapid, fiind continuu partiționat și sub-partiționat ad nauseam în diferite subspecialități și tipuri de învățare automată.
Există totuși câteva fire comune de bază, iar tema generală este cel mai bine rezumată în această declarație des citată de Arthur Samuel încă din 1959: „[Învățarea automată este] domeniul de studiu care oferă computerelor capacitatea de a învăța fără fiind programat în mod explicit.”
Și mai recent, în 1997, Tom Mitchell a dat o definiție „bine pusă” care s-a dovedit mai utilă tipurilor de inginerie: „Se spune că un program de calculator învață din experiența E cu privire la o sarcină T și o măsură de performanță P, dacă performanța sa pe T, măsurată de P, se îmbunătățește cu experiența E.”
Deci, dacă doriți ca programul dvs. să prezică, de exemplu, modelele de trafic la o intersecție aglomerată (sarcina T), îl puteți rula printr-un algoritm de învățare automată cu date despre modelele de trafic din trecut (experiența E) și, dacă a „învățat cu succes ”, se va descurca mai bine la prezicerea viitoarelor modele de trafic (măsura de performanță P).
Cu toate acestea, natura extrem de complexă a multor probleme din lumea reală înseamnă adesea că inventarea de algoritmi specializați care să le rezolve perfect de fiecare dată este impracticabilă, dacă nu imposibilă. Exemple de probleme de învățare automată includ: „Este cancer?”, „Care este valoarea de piață a acestei case?”, „Care dintre acești oameni sunt prieteni buni între ei?”, „Va exploda acest motor de rachetă la decolare? ”, „Îi va plăcea acestei persoane acest film?”, „Cine este acesta?”, „Ce ai spus?” și „Cum zbori cu chestia asta?”. Toate aceste probleme sunt ținte excelente pentru un proiect ML și, de fapt, ML a fost aplicat fiecăruia dintre ele cu mare succes.
Printre diferitele tipuri de sarcini ML, se face o distincție crucială între învățarea supravegheată și nesupravegheată:
- Învățare automată supravegheată: programul este „antrenat” pe un set predefinit de „exemple de antrenament”, care apoi îi facilitează capacitatea de a ajunge la o concluzie precisă atunci când i se oferă date noi.
- Învățare automată nesupravegheată: programului i se oferă o mulțime de date și trebuie să găsească modele și relații în ele.
Ne vom concentra în primul rând pe învățarea supravegheată aici, dar sfârșitul articolului include o scurtă discuție despre învățarea nesupervizată, cu câteva link-uri pentru cei care sunt interesați să continue subiectul.
Învățare automată supravegheată
În majoritatea aplicațiilor de învățare supravegheată, scopul final este de a dezvolta o funcție de predicție fin reglată h(x) (uneori numită „ipoteză”). „Învățarea” constă în utilizarea unor algoritmi matematici sofisticați pentru a optimiza această funcție, astfel încât, având în vedere datele de intrare x despre un anumit domeniu (să zicem, metru pătrat al unei case), să prezică cu exactitate o valoare interesantă h(x) (să zicem, prețul pieței). pentru casa respectivă).
În practică, x reprezintă aproape întotdeauna mai multe puncte de date. Deci, de exemplu, un predictor al prețului locuinței ar putea avea nu numai metri pătrați ( x1 ), ci și numărul de dormitoare ( x2 ), numărul de băi ( x3 ), numărul de etaje ( x4) , anul de construcție ( x5 ), codul poștal ( x6 ) și așa mai departe. Determinarea ce intrări să utilizați este o parte importantă a designului ML. Cu toate acestea, de dragul explicației, este cel mai ușor să presupunem că se folosește o singură valoare de intrare.
Deci, să presupunem că predictorul nostru simplu are această formă:
Unde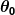 și
și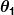 sunt constante. Scopul nostru este să găsim valorile perfecte ale și pentru ca predictorul nostru să funcționeze cât mai bine posibil.
sunt constante. Scopul nostru este să găsim valorile perfecte ale și pentru ca predictorul nostru să funcționeze cât mai bine posibil.
Optimizarea predictorului h(x) se face folosind exemple de antrenament . Pentru fiecare exemplu de antrenament, avem o valoare de intrare x_train , pentru care o ieșire corespunzătoare, y , este cunoscută în prealabil. Pentru fiecare exemplu, găsim diferența dintre valoarea cunoscută, corectă y și valoarea noastră prezisă h(x_train) . Cu suficiente exemple de antrenament, aceste diferențe ne oferă o modalitate utilă de a măsura „greșeala” lui h(x) . Apoi putem ajusta h(x) ajustând valorile lui și pentru a face „mai puțin greșit”. Acest proces se repetă de nenumărate ori până când sistemul converge către cele mai bune valori pentru și . În acest fel, predictorul devine antrenat și este gata să facă predicții din lumea reală.
Exemple de învățare automată
Ne rămânem la probleme simple în această postare de dragul ilustrației, dar motivul pentru care există ML este pentru că, în lumea reală, problemele sunt mult mai complexe. Pe acest ecran plat vă putem face o imagine a, cel mult, un set de date tridimensionale, dar problemele ML se ocupă de obicei cu date cu milioane de dimensiuni și cu funcții de predicție foarte complexe. ML rezolvă probleme care nu pot fi rezolvate numai prin mijloace numerice.
Având în vedere acest lucru, să ne uităm la un exemplu simplu. Să presupunem că avem următoarele date de instruire, în care angajații companiei și-au evaluat satisfacția pe o scară de la 1 la 100:
În primul rând, observați că datele sunt puțin zgomotoase. Adică, deși putem vedea că există un model (adică, satisfacția angajaților tinde să crească pe măsură ce salariul crește), nu totul se potrivește perfect pe o linie dreaptă. Acesta va fi întotdeauna cazul datelor din lumea reală (și dorim absolut să ne antrenăm mașina folosind date din lumea reală!). Deci, cum putem antrena o mașină pentru a prezice perfect nivelul de satisfacție al unui angajat? Răspunsul, desigur, este că nu putem. Scopul ML nu este niciodată să facă presupuneri „perfecte”, deoarece ML se ocupă de domenii în care nu există așa ceva. Scopul este de a face presupuneri care sunt suficient de bune pentru a fi utile.
Amintește oarecum de celebra afirmație a matematicianului și profesorului de statistică britanic George EP Box că „toate modelele sunt greșite, dar unele sunt utile”.
Învățarea automată se bazează în mare măsură pe statistici. De exemplu, atunci când ne antrenăm mașina să învețe, trebuie să îi oferim un eșantion aleator semnificativ statistic ca date de antrenament. Dacă setul de antrenament nu este aleatoriu, riscăm ca modelele de învățare automată care de fapt nu există. Și dacă setul de antrenament este prea mic (vezi legea numerelor mari), nu vom învăța suficient și s-ar putea chiar să ajungem la concluzii inexacte. De exemplu, încercarea de a prezice modele de satisfacție la nivel de companie pe baza datelor de la conducerea superioară ar fi probabil predispusă la erori.
Cu această înțelegere, să dăm mașinii noastre datele care ni s-au dat mai sus și să o învețe. Mai întâi trebuie să inițializam predictorul nostru h(x) cu niște valori rezonabile ale și . Acum, predictorul nostru arată astfel când este plasat peste setul nostru de antrenament:
Dacă întrebăm acest predictor pentru satisfacția unui angajat care câștigă 60.000 USD, ar prezice un rating de 27:
Este evident că aceasta a fost o presupunere îngrozitoare și că această mașină nu știe prea multe.
Deci, acum, să dăm acestui predictor toate salariile din setul nostru de formare și să luăm diferențele dintre cotele de satisfacție estimate rezultate și cotele de satisfacție reale ale angajaților corespunzători. Dacă facem puțină vrăjitorie matematică (pe care o voi descrie pe scurt), putem calcula, cu o certitudine foarte mare, că valorile de 13,12 pentru și 0,61 pentru ne vor oferi un predictor mai bun.
Și dacă repetăm acest proces, să zicem de 1500 de ori, predictorul nostru va arăta astfel:
În acest moment, dacă repetăm procesul, vom constata că și nu se va mai schimba cu o sumă apreciabilă și astfel vedem că sistemul a convergit. Dacă nu am făcut nicio greșeală, înseamnă că am găsit predictorul optim. În consecință, dacă întrebăm din nou aparatul pentru evaluarea de satisfacție a angajatului care câștigă 60.000 USD, acesta va prezice un rating de aproximativ 60.
Acum ajungem undeva.
Regresia învățării automate: o notă despre complexitate
Exemplul de mai sus este din punct de vedere tehnic o problemă simplă de regresie liniară univariată, care, în realitate, poate fi rezolvată prin derivarea unei ecuații normale simple și sărirea peste acest proces de „ajustare”. Cu toate acestea, luați în considerare un predictor care arată astfel:
Această funcție primește intrare în patru dimensiuni și are o varietate de termeni polinomi. Obținerea unei ecuații normale pentru această funcție este o provocare semnificativă. Multe probleme moderne de învățare automată necesită mii sau chiar milioane de dimensiuni de date pentru a construi predicții folosind sute de coeficienți. Prezicerea modului în care va fi exprimat genomul unui organism sau cum va fi clima în cincizeci de ani, sunt exemple de astfel de probleme complexe.
Din fericire, abordarea iterativă adoptată de sistemele ML este mult mai rezistentă în fața unei asemenea complexități. În loc să folosească forța brută, un sistem de învățare automată „își simte drumul” către răspuns. Pentru probleme mari, aceasta funcționează mult mai bine. Deși acest lucru nu înseamnă că ML poate rezolva toate problemele arbitrar complexe (nu poate), face un instrument incredibil de flexibil și puternic.
Coborâre în degrade - Minimizarea „greșelii”
Să aruncăm o privire mai atentă asupra modului în care funcționează acest proces iterativ. În exemplul de mai sus, cum ne asigurăm și sunt din ce în ce mai bine cu fiecare pas și nu mai rău? Răspunsul constă în „măsurarea greșelii” la care am făcut aluzie anterior, împreună cu puțin calcul.

Măsura greșelii este cunoscută sub numele de funcție de cost (alias, funcția de pierdere ),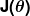 . Intrarea
. Intrarea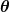 reprezintă toți coeficienții pe care îi folosim în predictorul nostru. Deci, în cazul nostru, este cu adevărat perechea și .
reprezintă toți coeficienții pe care îi folosim în predictorul nostru. Deci, în cazul nostru, este cu adevărat perechea și .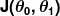 ne oferă o măsurare matematică a cât de greșit este predictorul nostru când folosește valorile date ale și .
ne oferă o măsurare matematică a cât de greșit este predictorul nostru când folosește valorile date ale și .
Alegerea funcției de cost este o altă piesă importantă a unui program ML. În diferite contexte, a fi „greșit” poate însemna lucruri foarte diferite. În exemplul nostru de satisfacție a angajaților, standardul bine stabilit este funcția liniară a celor mai mici pătrate:
Cu cele mai mici pătrate, penalizarea pentru o presupunere proastă crește în mod pătratic cu diferența dintre presupunerea și răspunsul corect, așa că acționează ca o măsură foarte „strictă” a greșelii. Funcția de cost calculează o penalizare medie pentru toate exemplele de antrenament.
Deci acum vedem că scopul nostru este să găsim și pentru predictorul nostru h(x) astfel încât funcția noastră de cost este cât se poate de mic. Facem apel la puterea calculului pentru a realiza acest lucru.
Luați în considerare următorul grafic al unei funcții de cost pentru o anumită problemă de învățare automată:
Aici putem vedea costul asociat cu diferite valori ale și . Putem vedea că graficul are un bol ușor la forma sa. Partea de jos a bolului reprezintă cel mai mic cost pe care ne-o poate oferi predictorul nostru pe baza datelor de antrenament date. Scopul este să „roboare pe deal” și să găsești și corespunzătoare acestui punct.
Aici intervine calculul în acest tutorial de învățare automată. De dragul de a menține această explicație gestionabilă, nu voi scrie ecuațiile aici, dar în esență ceea ce facem este să luăm gradientul de , care este perechea de derivate ale (unul peste si unul peste ). Gradientul va fi diferit pentru fiecare valoare diferită a și , și ne spune care este „panta dealului” și, în special, „care este în jos”, pentru aceste s. De exemplu, când conectăm valorile noastre actuale ale în gradient, ne poate spune că adăugând puțin la și scăzând puțin din ne va duce în direcția funcției de cost-fund. Prin urmare, adăugăm puțin la , și scădeți puțin din , și voila! Am finalizat o rundă a algoritmului nostru de învățare. Predictorul nostru actualizat, h(x) = + x, va returna predicții mai bune decât înainte. Mașina noastră este acum puțin mai inteligentă.
Acest proces de alternare între calcularea gradientului curent și actualizarea s din rezultate, este cunoscut sub numele de coborâre în gradient.
Aceasta acoperă teoria de bază care stă la baza majorității sistemelor de învățare automată supravegheate. Dar conceptele de bază pot fi aplicate într-o varietate de moduri diferite, în funcție de problema în cauză.
Probleme de clasificare în învățarea automată
Sub ML supravegheat, două subcategorii majore sunt:
- Sisteme de învățare automată de regresie: sisteme în care valoarea estimată se încadrează undeva pe un spectru continuu. Aceste sisteme ne ajută cu întrebările „Cât?” sau „Câți?”.
- Sisteme de învățare automată de clasificare: sisteme în care căutăm o predicție da sau nu, cum ar fi „Este tumer canceros?”, „Acest cookie îndeplinește standardele noastre de calitate?” și așa mai departe.
După cum se dovedește, teoria de bază a învățării automate este mai mult sau mai puțin aceeași. Diferențele majore sunt proiectarea predictorului h(x) și proiectarea funcției de cost .
Exemplele noastre de până acum s-au concentrat pe probleme de regresie, așa că acum să aruncăm o privire și la un exemplu de clasificare.
Iată rezultatele unui studiu de testare a calității cookie-urilor, în care exemplele de instruire au fost toate etichetate fie „cookie bun” ( y = 1 ) în albastru, fie „cookie rău” ( y = 0 ) în roșu.
În clasificare, un predictor de regresie nu este foarte util. Ceea ce ne dorim de obicei este un predictor care să facă o ghicire undeva între 0 și 1. Într-un clasificator de calitate a cookie-urilor, o predicție de 1 ar reprezenta o presupunere foarte sigură că cookie-ul este perfect și absolut delicios. O predicție de 0 reprezintă o încredere ridicată că cookie-ul este o jenă pentru industria cookie-urilor. Valorile care se încadrează în acest interval reprezintă mai puțină încredere, așa că ne-am putea proiecta sistemul astfel încât predicția de 0,6 să însemne „Omule, este o problemă grea, dar voi merge cu da, poți vinde acel cookie”, în timp ce o valoare exact în mijlocul, la 0,5, ar putea reprezenta incertitudine completă. Nu așa este întotdeauna distribuită încrederea într-un clasificator, dar este un design foarte comun și funcționează în scopurile ilustrației noastre.
Se pare că există o funcție drăguță care surprinde bine acest comportament. Se numește funcție sigmoidă, g(z) și arată cam așa:
z este o reprezentare a intrărilor și coeficienților noștri, cum ar fi:
astfel încât predictorul nostru devine:
Observați că funcția sigmoidă transformă producția noastră în intervalul cuprins între 0 și 1.
Logica din spatele proiectării funcției de cost este, de asemenea, diferită în clasificare. Din nou ne întrebăm „ce înseamnă că o presupunere este greșită?” și de data aceasta o regulă generală foarte bună este că, dacă estimarea corectă a fost 0 și am ghicit 1, atunci am greșit complet și total și invers. Deoarece nu poți greși mai mult decât absolut greșit, penalizarea în acest caz este enormă. Alternativ, dacă estimarea corectă a fost 0 și noi am ghicit 0, funcția noastră de cost nu ar trebui să adauge niciun cost pentru fiecare dată când se întâmplă acest lucru. Dacă presupunerea a fost corectă, dar nu eram complet încrezători (de exemplu, y = 1 , dar h(x) = 0.8 ), aceasta ar trebui să aibă un cost mic, iar dacă presupunerea noastră a fost greșită, dar nu eram complet încrezători ( de exemplu, y = 1 dar h(x) = 0.3 ), acest lucru ar trebui să aibă un cost semnificativ, dar nu atât de mult ca și cum am greși complet.
Acest comportament este capturat de funcția jurnal, astfel încât:
Din nou, funcția de cost ne oferă costul mediu pentru toate exemplele noastre de instruire.
Deci aici am descris cum predictorul h(x) și funcția de cost diferă între regresie și clasificare, dar coborârea în gradient încă funcționează bine.
Un predictor de clasificare poate fi vizualizat prin trasarea liniei de delimitare; adică, bariera în care predicția se schimbă de la un „da” (o predicție mai mare de 0,5) la un „nu” (o predicție mai mică de 0,5). Cu un sistem bine conceput, datele noastre cookie pot genera o limită de clasificare care arată astfel:
Acum, aceasta este o mașină care știe ceva despre cookie-uri!
O introducere în rețelele neuronale
Nicio discuție despre învățarea automată nu ar fi completă fără a menționa cel puțin rețelele neuronale. Nu numai că rețelele neuronale oferă un instrument extrem de puternic pentru a rezolva probleme foarte dificile, dar oferă și indicii fascinante despre funcționarea propriului nostru creier și posibilități interesante pentru a crea într-o zi mașini cu adevărat inteligente.
Rețelele neuronale sunt potrivite pentru modelele de învățare automată în care numărul de intrări este gigantic. Costul de calcul al gestionării unei astfel de probleme este prea copleșitor pentru tipurile de sisteme pe care le-am discutat mai sus. După cum se dovedește, totuși, rețelele neuronale pot fi reglate eficient folosind tehnici care sunt izbitor de similare cu coborârea gradientului în principiu.
O discuție amănunțită despre rețelele neuronale depășește scopul acestui tutorial, dar vă recomand să consultați postarea noastră anterioară pe acest subiect.
Învățare automată nesupravegheată
Învățarea automată nesupravegheată are de obicei sarcina de a găsi relații în cadrul datelor. Nu există exemple de antrenament utilizate în acest proces. În schimb, sistemului i se oferă un set de date și este însărcinat să găsească modele și corelații în acestea. Un bun exemplu este identificarea unor grupuri strânse de prieteni în datele rețelelor sociale.
Algoritmii de învățare automată utilizați pentru a face acest lucru sunt foarte diferiți de cei utilizați pentru învățarea supravegheată, iar subiectul merită propria postare. Cu toate acestea, pentru ceva de mestecat între timp, aruncați o privire la algoritmii de grupare precum k-means și, de asemenea, analizați sistemele de reducere a dimensionalității, cum ar fi analiza componentelor principale. Postarea noastră anterioară despre big data discută și mai detaliat o serie dintre aceste subiecte.
Concluzie
Am acoperit aici o mare parte din teoria de bază care stă la baza domeniului învățării automate, dar, desigur, abia am zgâriat suprafața.
Rețineți că pentru a aplica cu adevărat teoriile conținute în această introducere la exemplele de învățare automată din viața reală, este necesară o înțelegere mult mai profundă a subiectelor discutate aici. Există multe subtilități și capcane în ML și multe modalități de a fi dus în rătăcire de ceea ce pare a fi o mașină de gândire perfect bine reglată. Aproape fiecare parte a teoriei de bază poate fi jucată și modificată la nesfârșit, iar rezultatele sunt adesea fascinante. Mulți cresc în domenii de studiu complet noi, care sunt mai potrivite pentru anumite probleme.
În mod clar, Machine Learning este un instrument incredibil de puternic. În următorii ani, promite să ajute la rezolvarea unora dintre cele mai presante probleme ale noastre, precum și să deschidă lumi cu totul noi de oportunități pentru firmele din știința datelor. Cererea de ingineri de învățare automată va continua să crească, oferind șanse incredibile de a face parte din ceva mare. Sper că te vei gândi să intri în acțiune!
Confirmare
Acest articol se bazează în mare măsură pe materialul predat de profesorul de la Stanford, Dr. Andrew Ng, în cursul său gratuit și deschis de învățare automată. Cursul acoperă tot ce este discutat în acest articol în mare profunzime și oferă o mulțime de sfaturi practice pentru practicianul ML. Nu pot recomanda acest curs suficient de mult celor interesați să exploreze în continuare acest domeniu fascinant.
- Sunet logic și modele AI monotone
- Învățare Flappy Bird: Un tutorial de învățare de întărire