
Eine Einführung in die Theorie des maschinellen Lernens und ihre Anwendungen: Ein visuelles Tutorial mit Beispielen
Veröffentlicht: 2022-03-11Maschinelles Lernen (ML) kommt zur Geltung, wobei zunehmend erkannt wird, dass ML eine Schlüsselrolle in einer Vielzahl kritischer Anwendungen wie Data Mining, Verarbeitung natürlicher Sprache, Bilderkennung und Expertensystemen spielen kann. ML bietet potenzielle Lösungen in all diesen Bereichen und mehr und wird eine Säule unserer zukünftigen Zivilisation sein.
Das Angebot an fähigen ML-Designern muss diese Nachfrage noch einholen. Ein Hauptgrund dafür ist, dass ML einfach nur knifflig ist. Dieses Lernprogramm zum maschinellen Lernen führt in die Grundlagen der ML-Theorie ein, legt die gängigen Themen und Konzepte fest und macht es einfach, der Logik zu folgen und sich mit den Grundlagen des maschinellen Lernens vertraut zu machen.
Was ist maschinelles Lernen?
Was genau ist also „maschinelles Lernen“ überhaupt? ML ist eigentlich eine Menge Dinge. Das Feld ist ziemlich groß und wächst schnell, da es ständig bis zum Erbrechen in verschiedene Unterspezialitäten und Arten des maschinellen Lernens partitioniert und unterteilt wird.
Es gibt jedoch einige grundlegende Gemeinsamkeiten, und das übergeordnete Thema lässt sich am besten mit dieser oft zitierten Aussage von Arthur Samuel aus dem Jahr 1959 zusammenfassen: „[Maschinelles Lernen ist das] Studiengebiet, das Computern die Fähigkeit gibt, ohne zu lernen explizit programmiert.“
Und vor kurzem, im Jahr 1997, gab Tom Mitchell eine „gut formulierte“ Definition, die sich für Ingenieure als nützlicher erwiesen hat: „Ein Computerprogramm soll aus Erfahrung E in Bezug auf einige Aufgaben T und einige Leistungsmaße P lernen, wenn seine Leistung auf T, gemessen an P, verbessert sich mit der Erfahrung E.“
Wenn Sie also möchten, dass Ihr Programm beispielsweise Verkehrsmuster an einer stark befahrenen Kreuzung vorhersagt (Aufgabe T), können Sie es durch einen maschinellen Lernalgorithmus mit Daten über vergangene Verkehrsmuster führen (Erfahrung E) und, wenn es erfolgreich „gelernt“ hat “, wird es dann besser bei der Vorhersage zukünftiger Verkehrsmuster (Leistungsmaß P).
Die hochkomplexe Natur vieler realer Probleme bedeutet jedoch oft, dass es unpraktisch, wenn nicht sogar unmöglich ist, spezialisierte Algorithmen zu erfinden, die sie jedes Mal perfekt lösen. Beispiele für maschinelles Lernen sind: „Ist das Krebs?“, „Was ist der Marktwert dieses Hauses?“, „Welche dieser Leute sind gut befreundet?“, „Wird dieses Raketentriebwerk beim Start explodieren? “, „Wird dieser Person dieser Film gefallen?“, „Wer ist das?“, „Was hast du gesagt?“ und „Wie fliegst du dieses Ding?“. All diese Probleme sind ausgezeichnete Ziele für ein ML-Projekt, und tatsächlich wurde ML mit großem Erfolg auf jedes von ihnen angewendet.
Bei den verschiedenen Arten von ML-Aufgaben wird zwischen überwachtem und unüberwachtem Lernen unterschieden:
- Überwachtes maschinelles Lernen: Das Programm wird anhand eines vordefinierten Satzes von „Trainingsbeispielen“ „trainiert“, die es dann erleichtern, bei neuen Daten zu einer genauen Schlussfolgerung zu gelangen.
- Unüberwachtes maschinelles Lernen: Das Programm erhält einen Haufen Daten und muss darin Muster und Beziehungen finden.
Wir werden uns hier hauptsächlich auf überwachtes Lernen konzentrieren, aber das Ende des Artikels enthält eine kurze Diskussion über unüberwachtes Lernen mit einigen Links für diejenigen, die daran interessiert sind, das Thema weiter zu verfolgen.
Überwachtes maschinelles Lernen
Bei den meisten überwachten Lernanwendungen besteht das ultimative Ziel darin, eine fein abgestimmte Prädiktorfunktion h(x) (manchmal auch als „Hypothese“ bezeichnet) zu entwickeln. „Lernen“ besteht darin, ausgeklügelte mathematische Algorithmen zu verwenden, um diese Funktion so zu optimieren, dass bei gegebenen Eingabedaten x über eine bestimmte Domäne (z. B. die Quadratmeterzahl eines Hauses) ein interessanter Wert h(x) (z. B. Marktpreis) genau vorhergesagt wird für besagtes Haus).
In der Praxis repräsentiert x fast immer mehrere Datenpunkte. So könnte beispielsweise ein Immobilienpreis-Prädiktor nicht nur die Quadratmeterzahl ( x1 ), sondern auch die Anzahl der Schlafzimmer ( x2 ), die Anzahl der Badezimmer ( x3 ), die Anzahl der Stockwerke ( x4) , das Baujahr ( x5 ) und die Postleitzahl berücksichtigen ( x6 ) und so weiter. Die Bestimmung der zu verwendenden Eingaben ist ein wichtiger Bestandteil des ML-Designs. Aus Gründen der Erläuterung ist es jedoch am einfachsten anzunehmen, dass ein einziger Eingabewert verwendet wird.
Nehmen wir also an, unser einfacher Prädiktor hat diese Form:
wo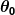 und
und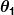 sind Konstanten. Unser Ziel ist es, die perfekten Werte zu finden und damit unser Prädiktor so gut wie möglich funktioniert.
sind Konstanten. Unser Ziel ist es, die perfekten Werte zu finden und damit unser Prädiktor so gut wie möglich funktioniert.
Die Optimierung des Prädiktors h(x) erfolgt anhand von Trainingsbeispielen . Für jedes Trainingsbeispiel haben wir einen Eingangswert x_train , für den ein entsprechender Ausgang y im Voraus bekannt ist. Für jedes Beispiel finden wir die Differenz zwischen dem bekannten, korrekten Wert y und unserem vorhergesagten Wert h(x_train) . Mit genügend Trainingsbeispielen geben uns diese Unterschiede eine nützliche Möglichkeit, die „Falschheit“ von h(x) zu messen. Wir können dann h(x) optimieren, indem wir die Werte von optimieren und um es „weniger falsch“ zu machen. Dieser Vorgang wird immer wieder wiederholt, bis das System auf die besten Werte für konvergiert hat und . Auf diese Weise wird der Prädiktor trainiert und ist bereit, Vorhersagen in der realen Welt durchzuführen.
Beispiele für maschinelles Lernen
Wir beschränken uns in diesem Beitrag zur Veranschaulichung auf einfache Probleme, aber der Grund, warum ML existiert, liegt darin, dass die Probleme in der realen Welt viel komplexer sind. Auf diesem Flachbildschirm können wir Ihnen höchstens ein Bild eines dreidimensionalen Datensatzes zeichnen, aber ML-Probleme befassen sich üblicherweise mit Daten mit Millionen von Dimensionen und sehr komplexen Prädiktorfunktionen. ML löst Probleme, die mit numerischen Mitteln allein nicht gelöst werden können.
Sehen wir uns dazu ein einfaches Beispiel an. Angenommen, wir haben die folgenden Trainingsdaten, wobei die Mitarbeiter des Unternehmens ihre Zufriedenheit auf einer Skala von 1 bis 100 bewertet haben:
Beachten Sie zunächst, dass die Daten etwas verrauscht sind. Das heißt, obwohl wir sehen können, dass es ein Muster gibt (dh die Mitarbeiterzufriedenheit steigt tendenziell mit steigendem Gehalt), passt nicht alles genau auf eine gerade Linie. Dies wird bei realen Daten immer der Fall sein (und wir wollen unsere Maschine unbedingt mit realen Daten trainieren!). Wie können wir also eine Maschine so trainieren, dass sie die Zufriedenheit eines Mitarbeiters perfekt vorhersagt? Die Antwort ist natürlich, dass wir das nicht können. Das Ziel von ML ist es nie, „perfekte“ Vermutungen anzustellen, da ML in Bereichen tätig ist, in denen es so etwas nicht gibt. Das Ziel ist es, Vermutungen anzustellen, die gut genug sind, um nützlich zu sein.
Es erinnert ein wenig an die berühmte Aussage des britischen Mathematikers und Statistikprofessors George EP Box, dass „alle Modelle falsch sind, aber einige nützlich sind“.
Maschinelles Lernen baut stark auf Statistiken auf. Wenn wir beispielsweise unserer Maschine das Lernen beibringen, müssen wir ihr eine statistisch signifikante Zufallsstichprobe als Trainingsdaten geben. Wenn der Trainingssatz nicht zufällig ist, laufen wir Gefahr, maschinelle Lernmuster zu erhalten, die eigentlich nicht vorhanden sind. Und wenn das Trainingsset zu klein ist (siehe Gesetz der großen Zahlen), lernen wir nicht genug und kommen möglicherweise sogar zu ungenauen Schlussfolgerungen. Beispielsweise wäre der Versuch, unternehmensweite Zufriedenheitsmuster allein auf der Grundlage von Daten des oberen Managements vorherzusagen, wahrscheinlich fehleranfällig.
Lassen Sie uns mit diesem Verständnis unserer Maschine die Daten geben, die wir oben erhalten haben, und sie lernen lassen. Zuerst müssen wir unseren Prädiktor h(x) mit einigen vernünftigen Werten von initialisieren und . Jetzt sieht unser Prädiktor so aus, wenn er über unserem Trainingssatz platziert wird:
Wenn wir diesen Prädiktor nach der Zufriedenheit eines Mitarbeiters fragen, der 60.000 US-Dollar verdient, würde er eine Bewertung von 27 vorhersagen:
Es ist offensichtlich, dass dies eine schreckliche Vermutung war und dass diese Maschine nicht viel weiß.
Lassen Sie uns nun diesem Prädiktor alle Gehälter aus unserem Trainingsset geben und die Unterschiede zwischen den resultierenden vorhergesagten Zufriedenheitsbewertungen und den tatsächlichen Zufriedenheitsbewertungen der entsprechenden Mitarbeiter berechnen. Wenn wir ein wenig mathematische Zauberei aufführen (die ich gleich beschreiben werde), können wir mit sehr hoher Sicherheit Werte von 13,12 für berechnen und 0,61 für werden uns einen besseren Prädiktor geben.
Und wenn wir diesen Vorgang wiederholen, sagen wir 1500 Mal, sieht unser Prädiktor am Ende so aus:
An diesem Punkt, wenn wir den Vorgang wiederholen, werden wir das finden und sich nicht mehr nennenswert ändern und wir sehen, dass das System konvergiert hat. Wenn wir keine Fehler gemacht haben, bedeutet dies, dass wir den optimalen Prädiktor gefunden haben. Wenn wir die Maschine jetzt also erneut nach der Zufriedenheitsbewertung des Mitarbeiters fragen, der 60.000 $ verdient, sagt sie eine Bewertung von ungefähr 60 voraus.
Jetzt kommen wir irgendwo hin.
Machine Learning Regression: Ein Hinweis zur Komplexität
Das obige Beispiel ist technisch gesehen ein einfaches Problem der univariaten linearen Regression, das in Wirklichkeit gelöst werden kann, indem man eine einfache Normalgleichung herleitet und diesen „Tuning“-Prozess insgesamt überspringt. Betrachten Sie jedoch einen Prädiktor, der wie folgt aussieht:
Diese Funktion nimmt Eingaben in vier Dimensionen entgegen und hat eine Vielzahl polynomischer Terme. Die Ableitung einer Normalgleichung für diese Funktion ist eine große Herausforderung. Viele moderne maschinelle Lernprobleme erfordern Tausende oder sogar Millionen von Datendimensionen, um Vorhersagen mit Hunderten von Koeffizienten zu erstellen. Die Vorhersage, wie das Genom eines Organismus exprimiert wird oder wie das Klima in fünfzig Jahren aussehen wird, sind Beispiele für solch komplexe Probleme.
Glücklicherweise ist der iterative Ansatz von ML-Systemen angesichts dieser Komplexität viel widerstandsfähiger. Statt Brute-Force anzuwenden, „tastet“ sich ein maschinelles Lernsystem an die Antwort heran. Bei großen Problemen funktioniert das viel besser. Das bedeutet zwar nicht, dass ML alle beliebig komplexen Probleme lösen kann (das kann es nicht), aber es ist ein unglaublich flexibles und leistungsstarkes Werkzeug.
Gradientenabstieg - Minimierung von „Falschheit“
Schauen wir uns genauer an, wie dieser iterative Prozess funktioniert. Wie stellen wir im obigen Beispiel sicher und werden mit jedem Schritt besser und nicht schlechter? Die Antwort liegt in unserer „Messung der Falschheit“, auf die wir zuvor angespielt haben, zusammen mit ein wenig Kalkül.

Das Maß der Unrichtigkeit ist als Kostenfunktion (auch bekannt als Verlustfunktion ) bekannt.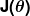 . Die Eingabe
. Die Eingabe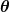 stellt alle Koeffizienten dar, die wir in unserem Prädiktor verwenden. Also in unserem Fall ist wirklich das Paar und .
stellt alle Koeffizienten dar, die wir in unserem Prädiktor verwenden. Also in unserem Fall ist wirklich das Paar und .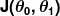 gibt uns ein mathematisches Maß dafür, wie falsch unser Prädiktor ist, wenn er die gegebenen Werte von verwendet und .
gibt uns ein mathematisches Maß dafür, wie falsch unser Prädiktor ist, wenn er die gegebenen Werte von verwendet und .
Die Wahl der Kostenfunktion ist ein weiterer wichtiger Teil eines ML-Programms. In verschiedenen Zusammenhängen kann „falsch“ sein sehr unterschiedliche Bedeutungen haben. In unserem Beispiel der Mitarbeiterzufriedenheit ist der etablierte Standard die lineare Funktion der kleinsten Quadrate:
Bei der Methode der kleinsten Quadrate steigt die Strafe für einen schlechten Tipp quadratisch mit der Differenz zwischen dem Tipp und der richtigen Antwort, sodass sie als sehr „strenges“ Maß für die Falschheit dient. Die Kostenfunktion berechnet eine durchschnittliche Strafe über alle Trainingsbeispiele.
Jetzt sehen wir also, dass unser Ziel darin besteht, zu finden und für unseren Prädiktor h(x) so dass unsere Kostenfunktion ist so klein wie möglich. Wir berufen uns auf die Kraft des Kalküls, um dies zu erreichen.
Betrachten Sie das folgende Diagramm einer Kostenfunktion für ein bestimmtes Problem des maschinellen Lernens:
Hier können wir die Kosten sehen, die mit verschiedenen Werten von verbunden sind und . Wir können sehen, dass der Graph eine leichte Schale in seiner Form hat. Der Boden der Schüssel stellt die niedrigsten Kosten dar, die uns unser Vorhersager basierend auf den gegebenen Trainingsdaten geben kann. Das Ziel ist es, „den Hügel hinunterzurollen“ und zu finden und diesem Punkt entsprechend.
Hier kommt die Infinitesimalrechnung in dieses Tutorial zum maschinellen Lernen ins Spiel. Um diese Erklärung überschaubar zu halten, werde ich die Gleichungen hier nicht aufschreiben, aber im Wesentlichen nehmen wir den Gradienten von , welches das Ableitungspaar von ist (eins drüber und eins drüber ). Der Gradient ist für jeden unterschiedlichen Wert von unterschiedlich und , und sagt uns, was die „Steigung des Hügels“ ist und insbesondere „welcher Weg nach unten führt“, für diese Speziellen S. Zum Beispiel, wenn wir unsere aktuellen Werte von einstecken in den Gradienten, kann es uns sagen, dass wir ein wenig hinzufügen und subtrahieren ein wenig von führt uns in Richtung des Kostenfunktions-Talbodens. Deshalb fügen wir ein wenig hinzu , und subtrahiere ein wenig von , und voila! Wir haben eine Runde unseres Lernalgorithmus abgeschlossen. Unser aktualisierter Prädiktor, h(x) = + x, liefert bessere Vorhersagen als zuvor. Unsere Maschine ist jetzt ein bisschen intelligenter.
Dieser Prozess des Wechselns zwischen dem Berechnen des aktuellen Gradienten und dem Aktualisieren des s aus den Ergebnissen, wird als Gradientenabstieg bezeichnet.
Das deckt die grundlegende Theorie ab, die den meisten überwachten maschinellen Lernsystemen zugrunde liegt. Aber die Grundkonzepte können je nach Problemstellung auf unterschiedliche Weise angewendet werden.
Klassifizierungsprobleme beim maschinellen Lernen
Unter überwachtem ML gibt es zwei große Unterkategorien:
- Regressionssysteme für maschinelles Lernen: Systeme, bei denen der vorhergesagte Wert irgendwo in ein kontinuierliches Spektrum fällt. Diese Systeme helfen uns bei der Frage „Wie viel?“. oder "Wie viele?".
- Klassifikationssysteme für maschinelles Lernen: Systeme, bei denen wir eine Ja-oder-Nein-Vorhersage suchen, z. B. „Ist dieser Tumor krebsartig?“, „Erfüllt dieser Keks unsere Qualitätsstandards?“ und so weiter.
Wie sich herausstellt, ist die zugrunde liegende Theorie des maschinellen Lernens mehr oder weniger dieselbe. Die Hauptunterschiede sind das Design des Prädiktors h(x) und das Design der Kostenfunktion .
Unsere bisherigen Beispiele haben sich auf Regressionsprobleme konzentriert, also schauen wir uns jetzt auch ein Klassifikationsbeispiel an.
Hier sind die Ergebnisse einer Cookie-Qualitätsteststudie, bei der die Trainingsbeispiele alle entweder als „guter Cookie“ ( y = 1 ) in Blau oder „schlechter Cookie“ ( y = 0 ) in Rot gekennzeichnet wurden.
Bei der Klassifizierung ist ein Regressionsprädiktor nicht sehr nützlich. Was wir normalerweise wollen, ist ein Prädiktor, der eine Vermutung zwischen 0 und 1 anstellt. In einem Keksqualitätsklassifizierer würde eine Vorhersage von 1 eine sehr sichere Vermutung darstellen, dass der Keks perfekt und absolut köstlich ist. Eine Vorhersage von 0 steht für hohes Vertrauen, dass der Keks eine Peinlichkeit für die Keksindustrie darstellt. Werte, die in diesen Bereich fallen, stellen weniger Vertrauen dar, daher könnten wir unser System so gestalten, dass die Vorhersage von 0,6 bedeutet: „Mann, das ist eine schwierige Entscheidung, aber ich werde mit Ja, Sie können diesen Keks verkaufen“, während ein Wert genau darin liegt die Mitte, bei 0,5, könnte völlige Unsicherheit darstellen. So wird das Vertrauen in einem Klassifikator nicht immer verteilt, aber es ist ein sehr verbreitetes Design und funktioniert für unsere Veranschaulichung.
Es stellt sich heraus, dass es eine nette Funktion gibt, die dieses Verhalten gut erfasst. Sie heißt Sigmoid-Funktion g(z) und sieht ungefähr so aus:
z ist eine Darstellung unserer Eingaben und Koeffizienten, wie zum Beispiel:
so dass unser Prädiktor wird:
Beachten Sie, dass die Sigmoid-Funktion unsere Ausgabe in den Bereich zwischen 0 und 1 transformiert.
Die Logik hinter dem Design der Kostenfunktion unterscheidet sich auch in der Klassifizierung. Wieder fragen wir: „Was bedeutet es, wenn eine Vermutung falsch ist?“ und dieses Mal ist eine sehr gute Faustregel, dass, wenn die richtige Schätzung 0 war und wir 1 getippt haben, wir uns völlig und vollständig geirrt haben und umgekehrt. Da man nicht mehr falsch als absolut falsch liegen kann, ist die Strafe in diesem Fall enorm. Wenn die richtige Schätzung 0 war und wir 0 erraten haben, sollte unsere Kostenfunktion alternativ keine Kosten für jedes Mal hinzufügen, wenn dies geschieht. Wenn die Vermutung richtig war, wir uns aber nicht ganz sicher waren (z. B. y = 1 , aber h(x) = 0.8 ), sollte dies mit geringen Kosten verbunden sein, und wenn unsere Vermutung falsch war, wir uns aber nicht ganz sicher waren ( B. y = 1 , aber h(x) = 0.3 ), sollte dies mit einigen erheblichen Kosten einhergehen, aber nicht so viel, als ob wir völlig falsch lägen.
Dieses Verhalten wird von der Protokollfunktion erfasst, sodass:
Wieder die Kostenfunktion gibt uns die durchschnittlichen Kosten für alle unsere Schulungsbeispiele an.
Hier haben wir also beschrieben, wie der Prädiktor h(x) und die Kosten funktionieren unterscheiden sich zwischen Regression und Klassifizierung, aber der Gradientenabstieg funktioniert immer noch gut.
Ein Klassifizierungsprädiktor kann durch Zeichnen der Grenzlinie visualisiert werden; dh die Barriere, bei der sich die Vorhersage von „Ja“ (eine Vorhersage größer als 0,5) zu einem „Nein“ (eine Vorhersage kleiner als 0,5) ändert. Mit einem gut konzipierten System können unsere Cookie-Daten eine Klassifizierungsgrenze generieren, die wie folgt aussieht:
Das ist eine Maschine, die ein oder zwei Dinge über Cookies weiß!
Eine Einführung in neuronale Netze
Keine Diskussion über maschinelles Lernen wäre vollständig, ohne zumindest neuronale Netze zu erwähnen. Neuronale Netze bieten nicht nur ein äußerst leistungsfähiges Werkzeug zur Lösung sehr schwieriger Probleme, sondern bieten auch faszinierende Hinweise auf die Funktionsweise unseres eigenen Gehirns und faszinierende Möglichkeiten, eines Tages wirklich intelligente Maschinen zu erschaffen.
Neuronale Netze eignen sich gut für maschinelle Lernmodelle, bei denen die Anzahl der Eingaben gigantisch ist. Der Rechenaufwand für die Behandlung eines solchen Problems ist einfach zu überwältigend für die Arten von Systemen, die wir oben besprochen haben. Wie sich jedoch herausstellt, können neuronale Netze effektiv mit Techniken abgestimmt werden, die dem Gradientenabstieg im Prinzip auffallend ähnlich sind.
Eine gründliche Erörterung neuronaler Netze würde den Rahmen dieses Tutorials sprengen, aber ich empfehle, unseren vorherigen Beitrag zu diesem Thema zu lesen.
Unüberwachtes maschinelles Lernen
Unüberwachtes maschinelles Lernen hat typischerweise die Aufgabe, Beziehungen innerhalb von Daten zu finden. In diesem Prozess werden keine Trainingsbeispiele verwendet. Stattdessen erhält das System einen Satz Daten und wird damit beauftragt, Muster und Korrelationen darin zu finden. Ein gutes Beispiel ist die Identifizierung eng verbundener Gruppen von Freunden in Daten sozialer Netzwerke.
Die dafür verwendeten Algorithmen des maschinellen Lernens unterscheiden sich stark von denen, die für das überwachte Lernen verwendet werden, und das Thema verdient einen eigenen Beitrag. Um jedoch in der Zwischenzeit etwas zum Kauen zu haben, werfen Sie einen Blick auf Clustering-Algorithmen wie k-means und schauen Sie sich auch Dimensionsreduktionssysteme wie die Hauptkomponentenanalyse an. Unser vorheriger Beitrag zu Big Data behandelt eine Reihe dieser Themen ebenfalls ausführlicher.
Fazit
Wir haben hier einen Großteil der grundlegenden Theorie behandelt, die dem Bereich des maschinellen Lernens zugrunde liegt, aber natürlich haben wir nur knapp an der Oberfläche gekratzt.
Denken Sie daran, dass ein viel tieferes Verständnis der hier behandelten Themen erforderlich ist, um die in dieser Einführung enthaltenen Theorien wirklich auf reale Beispiele für maschinelles Lernen anzuwenden. Es gibt viele Feinheiten und Fallstricke in ML und viele Möglichkeiten, von einer scheinbar perfekt abgestimmten Denkmaschine in die Irre geführt zu werden. Fast jeder Teil der grundlegenden Theorie kann endlos gespielt und verändert werden, und die Ergebnisse sind oft faszinierend. Viele entwickeln sich zu ganz neuen Studienbereichen, die für bestimmte Probleme besser geeignet sind.
Maschinelles Lernen ist eindeutig ein unglaublich leistungsfähiges Werkzeug. In den kommenden Jahren verspricht es, zur Lösung einiger unserer dringendsten Probleme beizutragen und Datenwissenschaftsunternehmen ganz neue Möglichkeiten zu eröffnen. Die Nachfrage nach Ingenieuren für maschinelles Lernen wird weiter steigen und bietet unglaubliche Chancen, Teil von etwas Großem zu sein. Ich hoffe, Sie erwägen, an der Aktion teilzunehmen!
Wissen
Dieser Artikel stützt sich stark auf Material, das von Stanford-Professor Dr. Andrew Ng in seinem kostenlosen und offenen Kurs zum maschinellen Lernen gelehrt wird. Der Kurs behandelt alles, was in diesem Artikel besprochen wird, in großer Tiefe und gibt unzählige praktische Ratschläge für den ML-Anwender. Ich kann diesen Kurs nicht genug für diejenigen empfehlen, die daran interessiert sind, dieses faszinierende Gebiet weiter zu erforschen.
- Soundlogik und monotone KI-Modelle
- Flappy Bird schulen: Ein Tutorial zum verstärkenden Lernen