
機械学習理論とその応用の紹介:例を含むビジュアルチュートリアル
公開: 2022-03-11機械学習(ML)は、データマイニング、自然言語処理、画像認識、エキスパートシステムなど、さまざまな重要なアプリケーションでMLが重要な役割を果たすことができるという認識が高まっており、独自のものになりつつあります。 MLは、これらすべてのドメインなどで潜在的なソリューションを提供し、将来の文明の柱となる予定です。
有能なMLデザイナーの供給はまだこの需要に追いついていない。 これの主な理由は、MLが単純にトリッキーであるということです。 この機械学習チュートリアルでは、ML理論の基本を紹介し、共通のテーマと概念を定めて、論理を簡単に理解し、機械学習の基本に慣れるようにします。
機械学習とは何ですか?
では、とにかく「機械学習」とは正確には何ですか? MLは実際にはたくさんのものです。 この分野は非常に広大であり、急速に拡大しており、さまざまなサブスペシャリティとタイプの機械学習に継続的に分割およびサブパーティション化されています。
ただし、いくつかの基本的な共通のスレッドがありますが、包括的なテーマは、1959年にアーサーサミュエルが行ったこの頻繁に引用される声明によって最もよく要約されます。明示的にプログラムされています。」
さらに最近では、1997年に、トムミッチェルは、エンジニアリングタイプにとってより有用であることが証明された「適切な」定義を示しました。 Pで測定したTでのパフォーマンスは、経験Eで向上します。」
したがって、たとえば混雑した交差点での交通パターン(タスクT)をプログラムで予測する場合は、過去の交通パターンに関するデータ(エクスペリエンスE)を使用して機械学習アルゴリズムを実行し、正常に「学習」した場合は、プログラムを実行できます。 」の場合、将来のトラフィックパターンをより適切に予測できます(パフォーマンス測定値P)。
しかし、多くの現実世界の問題の非常に複雑な性質は、多くの場合、毎回完全にそれらを解決する特殊なアルゴリズムを発明することは、不可能ではないにしても、非現実的であることを意味します。 機械学習の問題の例としては、「この癌ですか?」、「この家の市場価値は?」、「これらの人々のどれがお互いに良い友達ですか?」、「このロケットエンジンは離陸時に爆発しますか?」などがあります。 」、「この人はこの映画を好きになりますか?」、「これは誰ですか?」、「何と言いましたか?」、「このことをどのように飛ばしますか?」 これらの問題はすべてMLプロジェクトの優れたターゲットであり、実際、MLはそれぞれに適用されて大きな成功を収めています。
さまざまなタイプのMLタスクの中で、教師あり学習と教師なし学習の間に決定的な違いがあります。
- 教師あり機械学習:プログラムは、事前定義された一連の「トレーニング例」で「トレーニング」され、新しいデータが与えられたときに正確な結論に到達する能力を促進します。
- 教師なし機械学習:プログラムには大量のデータが与えられ、その中のパターンと関係を見つける必要があります。
ここでは主に教師あり学習に焦点を当てますが、記事の最後には、このトピックをさらに追求することに関心のある人のためのいくつかのリンクを含む、教師なし学習の簡単な説明が含まれています。
教師あり機械学習
教師あり学習アプリケーションの大部分では、最終的な目標は、微調整された予測関数h(x) (「仮説」と呼ばれることもあります)を開発することです。 「学習」は、高度な数学的アルゴリズムを使用してこの関数を最適化することで構成され、特定のドメイン(たとえば、家の正方形の映像)に関する入力データxが与えられると、いくつかの興味深い値h(x) (たとえば、市場価格)を正確に予測します。上記の家のために)。
実際には、 xはほとんどの場合複数のデータポイントを表します。 したがって、たとえば、住宅価格予測子は、平方フィート( x1 )だけでなく、寝室の数( x2 )、浴室の数( x3 )、階数( x4) 、建設年( x5 )、郵便番号も取得する可能性があります。 ( x6 )など。 使用する入力を決定することは、ML設計の重要な部分です。 ただし、説明のために、単一の入力値が使用されていると想定するのが最も簡単です。
したがって、単純な予測子が次の形式であるとしましょう。
どこ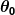 と
と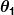 定数です。 私たちの目標は、 と予測子を可能な限り機能させるため。
定数です。 私たちの目標は、 と予測子を可能な限り機能させるため。
予測子h(x)の最適化は、トレーニング例を使用して行われます。 トレーニングの例ごとに、入力値x_trainがあり、対応する出力yが事前にわかっています。 それぞれの例について、既知の正しい値yと予測値h(x_train)の違いを見つけます。 十分なトレーニング例があれば、これらの違いは、 h(x)の「誤り」を測定するための便利な方法を提供します。 次に、の値を微調整することにより、 h(x)を微調整できます。 とそれを「間違いを少なく」するために。 このプロセスは、システムが次の最適値に収束するまで何度も繰り返されます。 と。 このようにして、予測子はトレーニングされ、実際の予測を行う準備が整います。
機械学習の例
説明のためにこの投稿では単純な問題に固執しますが、MLが存在する理由は、現実の世界では問題がはるかに複雑であるためです。 このフラットスクリーンでは、最大で3次元のデータセットの画像を描画できますが、MLの問題は通常、数百万の次元のデータと非常に複雑な予測関数を扱います。 MLは、数値的な手段だけでは解決できない問題を解決します。
それを念頭に置いて、簡単な例を見てみましょう。 次のトレーニングデータがあり、会社の従業員が1から100のスケールで満足度を評価したとします。
まず、データが少しうるさいことに注意してください。 つまり、パターンがあることはわかりますが(つまり、給与が上がると従業員満足度が上がる傾向があります)、すべてが直線にうまく収まるわけではありません。 これは常に実世界のデータに当てはまります(そして私たちは絶対に実世界のデータを使用してマシンをトレーニングしたいと思っています!)。 では、従業員の満足度を完全に予測するために、どのようにマシンをトレーニングできるでしょうか。 もちろん、答えはできません。 MLの目標は、「完璧な」推測を行うことではありません。MLは、そのようなことがないドメインを扱っているからです。 目標は、役立つのに十分な推測を行うことです。
これは、英国の数学者で統計学の教授であるジョージEPボックスによる「すべてのモデルは間違っているが、いくつかは有用である」という有名な声明をいくらか思い出させます。
機械学習は統計に大きく基づいています。 たとえば、学習するようにマシンをトレーニングする場合、トレーニングデータとして統計的に有意なランダムサンプルをマシンに与える必要があります。 トレーニングセットがランダムでない場合、実際には存在しない機械学習パターンのリスクがあります。 また、トレーニングセットが小さすぎると(大数の法則を参照)、十分な学習ができず、不正確な結論に達する可能性があります。 たとえば、上級管理職のみのデータに基づいて全社的な満足度パターンを予測しようとすると、エラーが発生しやすくなります。
このことを理解した上で、上記で与えられたデータをマシンに与えて、それを学習させましょう。 まず、予測子h(x)をいくつかの妥当な値で初期化する必要があります。 と。 これで、トレーニングセットの上に配置すると、予測子は次のようになります。
この予測子に6万ドルを稼ぐ従業員の満足度を尋ねると、27の評価が予測されます。
これがひどい推測であり、このマシンがあまり知らないことは明らかです。
それでは、この予測子にトレーニングセットからのすべての給与を与え、結果として得られる予測満足度評価と対応する従業員の実際の満足度評価の差を取りましょう。 少し数学的な魔法を実行すると(これについては後で説明します)、非常に高い確実性で、13.12の値を計算できます。 および0.61 より良い予測子を提供します。
そして、このプロセスをたとえば1500回繰り返すと、予測子は次のようになります。
この時点で、このプロセスを繰り返すと、次のことがわかります。 と感知できるほどの量の変化はもうないので、システムが収束していることがわかります。 間違いがなければ、これは最適な予測子が見つかったことを意味します。 したがって、6万ドルを稼ぐ従業員の満足度をもう一度マシンに要求すると、約60の評価が予測されます。
今、私たちはどこかに到達しています。
機械学習の回帰:複雑さに関する注記
上記の例は、技術的には単変量線形回帰の単純な問題であり、実際には、単純な正規方程式を導出し、この「調整」プロセスを完全にスキップすることで解決できます。 ただし、次のような予測子について考えてみます。
この関数は4次元で入力を受け取り、さまざまな多項式項を持ちます。 この関数の正規方程式を導出することは重要な課題です。 最近の機械学習の問題の多くは、数百の係数を使用して予測を構築するために、数千または数百万の次元のデータを必要とします。 生物のゲノムがどのように発現するか、あるいは50年後の気候がどのようになるかを予測することは、そのような複雑な問題の例です。
幸いなことに、MLシステムで採用されている反復アプローチは、このような複雑さに直面してもはるかに回復力があります。 ブルートフォースを使用する代わりに、機械学習システムは答えに「道を感じる」。 大きな問題の場合、これははるかにうまく機能します。 これは、MLが任意の複雑な問題をすべて解決できることを意味するわけではありませんが(不可能です)、信じられないほど柔軟で強力なツールになります。
最急降下法-「誤り」を最小限に抑える
この反復プロセスがどのように機能するかを詳しく見てみましょう。 上記の例では、どのように確認しますかと各ステップで良くなっていますが、悪くはありませんか? その答えは、以前にほのめかされた「不正の測定」と、小さな微積分にあります。
不正度の尺度は、コスト関数(別名、損失関数)として知られています。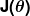 。 入力
。 入力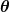 予測子で使用しているすべての係数を表します。 したがって、私たちの場合、 本当にペアですと。
予測子で使用しているすべての係数を表します。 したがって、私たちの場合、 本当にペアですと。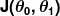 与えられた値を使用するときに予測子がどれほど間違っているかを数学的に測定しますと。
与えられた値を使用するときに予測子がどれほど間違っているかを数学的に測定しますと。

コスト関数の選択は、MLプログラムのもう1つの重要な部分です。 さまざまな状況で、「間違っている」ということは非常に異なることを意味する可能性があります。 従業員満足度の例では、確立された標準は線形最小二乗関数です。
最小二乗法では、誤った推測に対するペナルティは、推測と正解の差に応じて2乗的に増加するため、不正の非常に「厳密な」測定として機能します。 コスト関数は、すべてのトレーニング例の平均ペナルティを計算します。
だから今、私たちの目標は見つけることであることがわかりますと予測子h(x)に対して、コスト関数が可能な限り小さいです。 これを達成するために微積分の力を求めます。
特定の機械学習問題のコスト関数の次のプロットを検討してください。
ここでは、さまざまな値に関連するコストを確認できます。 と。 グラフの形にわずかなボウルがあることがわかります。 ボウルの底は、与えられたトレーニングデータに基づいて予測子が私たちに与えることができる最低のコストを表しています。 目標は「丘を転がり落ちる」ことであり、 とこの点に対応します。
ここで、微積分がこの機械学習チュートリアルに登場します。 この説明を扱いやすくするために、ここでは方程式を書きませんが、基本的に私たちが行うことは、 、の派生物のペアです(1つ以上と1つ以上)。 グラデーションは、の値が異なるごとに異なります。 と、そして、これらの特定の場合、「丘の斜面」、特に「どちらの方向が下がっているのか」を教えてくれますs。 たとえば、現在の値をプラグインするとグラデーションに少し追加すると、 から少し引くコスト関数の方向に私たちを連れて行きます-谷の床。 したがって、少し追加します、から少し減算します、そして出来上がり! 学習アルゴリズムの1ラウンドを完了しました。 更新された予測子h(x)= + xは、以前よりも優れた予測を返します。 私たちのマシンは少しスマートになりました。
現在の勾配の計算と更新を交互に行うこのプロセス結果から、最急降下法として知られています。
これは、教師あり機械学習システムの大部分の基礎となる基本理論をカバーしています。 しかし、基本的な概念は、目前の問題に応じて、さまざまな方法で適用できます。
機械学習における分類の問題
教師ありMLでは、2つの主要なサブカテゴリは次のとおりです。
- 回帰機械学習システム:予測される値が連続スペクトルのどこかにあるシステム。 これらのシステムは、「いくらですか」という質問に役立ちます。 または「いくつですか?」
- 分類機械学習システム: 「このタマーは癌性ですか?」、「このCookieは品質基準を満たしていますか?」など、「はい」または「いいえ」の予測を求めるシステム。
結局のところ、基礎となる機械学習理論はほぼ同じです。 主な違いは、予測子h(x)の設計とコスト関数の設計です。 。
これまでの例では回帰問題に焦点を当ててきたので、分類の例も見てみましょう。
これは、Cookieの品質テスト調査の結果です。ここでは、トレーニングの例はすべて、青の「良いCookie」( y = 1 )または赤の「悪いCookie」( y = 0 )のいずれかとしてラベル付けされています。
分類では、回帰予測子はあまり役に立ちません。 私たちが通常必要としているのは、0から1の間のどこかで推測を行う予測子です。Cookie品質分類子では、1の予測は、Cookieが完璧で完全に食欲をそそるという非常に自信のある推測を表します。 0の予測は、CookieがCookie業界にとって困惑しているという高い信頼性を表しています。 この範囲内の値は信頼性が低いことを表すため、0.6の予測が「男、それは難しい呼び出しですが、はい、あなたはそのCookieを販売できます」を意味するようにシステムを設計する可能性がありますが、値は正確に真ん中の0.5は、完全な不確実性を表している可能性があります。 これは、分類器で信頼がどのように分散されるかを常に示すわけではありませんが、非常に一般的な設計であり、説明の目的で機能します。
この振る舞いをうまく捉える素晴らしい関数があることがわかりました。 これはシグモイド関数g(z)と呼ばれ、次のようになります。
zは、次のような入力と係数の表現です。
そのため、予測子は次のようになります。
シグモイド関数が出力を0から1の範囲に変換することに注意してください。
コスト関数の設計の背後にあるロジックも分類が異なります。 もう一度、「推測が間違っているとはどういう意味ですか?」と尋ねます。 今回の非常に良い経験則は、正しい推測が0で1を推測した場合、完全に完全に間違っていたということです。逆もまた同様です。 あなたは絶対に間違っているよりも間違っていることはできないので、この場合のペナルティは莫大です。 あるいは、正しい推測が0で、0を推測した場合、コスト関数はこれが発生するたびにコストを追加するべきではありません。 推測が正しかったが、完全に自信がなかった場合(たとえば、 y = 1 、ただしh(x) = 0.8 )、これには少額のコストがかかるはずです。推測が間違っていたが、完全に自信がなかった場合(たとえば、 y = 1ですがh(x) = 0.3 )の場合、これにはかなりのコストがかかるはずですが、完全に間違っている場合ほどではありません。
この動作は、次のようにlog関数によってキャプチャされます。
繰り返しますが、コスト関数すべてのトレーニング例の平均コストを示します。
そこで、ここでは、予測子h(x)とコスト関数がどのように機能するかを説明しました。 回帰と分類は異なりますが、最急降下法は引き続き正常に機能します。
分類予測子は、境界線を引くことで視覚化できます。 つまり、予測が「はい」(0.5より大きい予測)から「いいえ」(0.5未満の予測)に変化するバリア。 適切に設計されたシステムを使用すると、Cookieデータは次のような分類境界を生成できます。
これで、Cookieについて1つか2つのことを知っているマシンになりました。
ニューラルネットワーク入門
少なくともニューラルネットワークについて言及しなければ、機械学習の議論は完結しません。 ニューラルネットは、非常に困難な問題を解決するための非常に強力なツールを提供するだけでなく、私たち自身の脳の働きに関する魅力的なヒントを提供し、真にインテリジェントなマシンを作成するための興味深い可能性を提供します。
ニューラルネットワークは、入力の数が膨大な機械学習モデルに適しています。 このような問題を処理するための計算コストは、上記で説明したタイプのシステムには圧倒的すぎます。 ただし、結局のところ、ニューラルネットワークは、原則として最急降下法と非常によく似た手法を使用して効果的に調整できます。
ニューラルネットワークの詳細な説明はこのチュートリアルの範囲を超えていますが、このテーマに関する以前の投稿を確認することをお勧めします。
教師なし機械学習
教師なし機械学習は通常、データ内の関係を見つけることを目的としています。 このプロセスで使用されるトレーニング例はありません。 代わりに、システムにセットデータが与えられ、その中のパターンと相関関係を見つけるタスクが実行されます。 良い例は、ソーシャルネットワークデータで親密な友人のグループを特定することです。
これを行うために使用される機械学習アルゴリズムは、教師あり学習に使用されるものとは大きく異なり、トピックは独自の投稿に値します。 ただし、その間に何かを噛み砕くには、k-meansなどのクラスタリングアルゴリズムを調べ、主成分分析などの次元削減システムも調べてください。 ビッグデータに関する以前の投稿では、これらのトピックの多くについても詳しく説明しています。
結論
ここでは、機械学習の分野の基礎となる基本理論の多くを取り上げましたが、もちろん、表面をかろうじてかじっただけです。
この紹介に含まれている理論を実際の機械学習の例に実際に適用するには、ここで説明するトピックをより深く理解する必要があることに注意してください。 MLには多くの微妙な点と落とし穴があり、完全に調整された思考マシンのように見えるものに惑わされる多くの方法があります。 基本理論のほとんどすべての部分は、無限に遊んだり変更したりすることができ、その結果はしばしば魅力的です。 多くは、特定の問題により適したまったく新しい研究分野に成長します。
明らかに、機械学習は非常に強力なツールです。 今後数年間で、それは私たちの最も差し迫った問題のいくつかを解決するのに役立つだけでなく、データサイエンス企業にまったく新しい機会の世界を開くことを約束します。 機械学習エンジニアの需要は今後も増え続け、大きな何かの一部となる素晴らしいチャンスを提供します。 アクションに参加することを検討していただければ幸いです。
了承
この記事は、スタンフォード大学のAndrewNg教授が無料でオープンな機械学習コースで教えた資料を大いに利用しています。 このコースでは、この記事で説明されているすべてのことを深くカバーし、MLの実践者に多くの実践的なアドバイスを提供します。 この魅力的な分野をさらに探求することに興味のある人には、このコースを十分に推薦することはできません。
- サウンドロジックと単調なAIモデル
- ゆるい鳥の教育:強化学習チュートリアル