
Введение в теорию машинного обучения и ее приложения: наглядное пособие с примерами
Опубликовано: 2022-03-11Машинное обучение (ML) вступает в свои права по мере того, как растет признание того, что ML может играть ключевую роль в широком спектре критически важных приложений, таких как интеллектуальный анализ данных, обработка естественного языка, распознавание изображений и экспертные системы. Машинное обучение предоставляет потенциальные решения во всех этих и многих других областях и должно стать опорой нашей будущей цивилизации.
Предложение способных дизайнеров машинного обучения еще не удовлетворило этот спрос. Основная причина этого заключается в том, что ML просто сложна. В этом учебном пособии по машинному обучению представлены основы теории машинного обучения, изложены общие темы и концепции, что позволяет легко следовать логике и освоиться с основами машинного обучения.
Что такое машинное обучение?
Так что же такое «машинное обучение»? ML на самом деле много чего. Область довольно обширна и быстро расширяется, постоянно разделяясь и подразделяясь до тошноты на различные подспециальности и типы машинного обучения.
Однако есть некоторые основные общие черты, и всеобъемлющую тему лучше всего резюмирует это часто цитируемое заявление, сделанное Артуром Сэмюэлем еще в 1959 году: «[Машинное обучение — это] область исследования, которая дает компьютерам возможность учиться без быть явно запрограммированным».
А совсем недавно, в 1997 году, Том Митчелл дал «хорошо сформулированное» определение, которое оказалось более полезным для инженеров: «Говорят, что компьютерная программа учится на опыте E в отношении некоторой задачи T и некоторого показателя производительности P, если его производительность по T, измеряемая P, улучшается с опытом E».
Поэтому, если вы хотите, чтобы ваша программа предсказывала, например, модели движения на оживленном перекрестке (задача T), вы можете запустить ее через алгоритм машинного обучения с данными о прошлых схемах движения (опыт E) и, если она успешно «изучила », тогда он будет лучше прогнозировать будущие модели трафика (показатель производительности P).
Однако очень сложная природа многих реальных проблем часто означает, что изобретать специализированные алгоритмы, которые каждый раз будут решать их идеально, нецелесообразно, если не невозможно. Примеры задач машинного обучения: «Это рак?», «Какова рыночная стоимость этого дома?», «Кто из этих людей дружит друг с другом?», «Взорвется ли этот ракетный двигатель при взлете? », «Понравится ли этому человеку этот фильм?», «Кто это?», «Что вы сказали?» и «Как вы управляете этой штукой?». Все эти проблемы — отличные цели для проекта машинного обучения, и на самом деле машинное обучение применялось к каждой из них с большим успехом.
Среди различных типов задач машинного обучения проводится важное различие между контролируемым и неконтролируемым обучением:
- Контролируемое машинное обучение: программа «обучается» на предварительно определенном наборе «обучающих примеров», которые затем облегчают ее способность делать точные выводы при получении новых данных.
- Неконтролируемое машинное обучение: программе предоставляется набор данных, и она должна найти в них закономерности и взаимосвязи.
Здесь мы в первую очередь сосредоточимся на обучении с учителем, но в конце статьи содержится краткое обсуждение обучения без учителя с некоторыми ссылками для тех, кто заинтересован в дальнейшем изучении темы.
Контролируемое машинное обучение
В большинстве приложений для обучения с учителем конечной целью является разработка точно настроенной предсказательной функции h(x) (иногда называемой «гипотезой»). «Обучение» состоит в использовании сложных математических алгоритмов для оптимизации этой функции таким образом, чтобы при заданных входных данных x об определенной области (скажем, площади дома) она точно предсказывала некоторое интересное значение h(x) (скажем, рыночную цену). для указанного дома).
На практике x почти всегда представляет несколько точек данных. Так, например, предиктор цены на жилье может принимать не только квадратные метры ( x1 ), но также количество спален ( x2 ), количество ванных комнат ( x3 ), количество этажей ( x4) , год постройки ( x5 ), почтовый индекс. ( x6 ) и так далее. Определение того, какие входные данные использовать, является важной частью проектирования машинного обучения. Однако для пояснения проще всего предположить, что используется одно входное значение.
Допустим, наш простой предиктор имеет следующую форму:
куда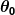 а также
а также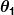 являются константами. Наша цель – найти идеальные значения а также чтобы наш предиктор работал как можно лучше.
являются константами. Наша цель – найти идеальные значения а также чтобы наш предиктор работал как можно лучше.
Оптимизация предиктора h(x) выполняется с использованием обучающих примеров . Для каждого обучающего примера у нас есть входное значение x_train , для которого заранее известен соответствующий выход y . Для каждого примера мы находим разницу между известным правильным значением y и нашим предсказанным значением h(x_train) . При достаточном количестве обучающих примеров эти различия дают нам полезный способ измерить «неправильность» h(x) . Затем мы можем настроить h(x) , изменив значения а также сделать его «менее неправильным». Этот процесс повторяется снова и снова, пока система не сойдется к лучшим значениям для а также . Таким образом, предсказатель обучается и готов делать реальные предсказания.
Примеры машинного обучения
Мы придерживаемся простых задач в этом посте для иллюстрации, но причина существования ML заключается в том, что в реальном мире проблемы намного сложнее. На этом плоском экране мы можем нарисовать не более чем трехмерный набор данных, но задачи машинного обучения обычно имеют дело с данными с миллионами измерений и очень сложными предикторными функциями. ML решает проблемы, которые невозможно решить только численными средствами.
Имея это в виду, давайте рассмотрим простой пример. Скажем, у нас есть следующие данные обучения, в которых сотрудники компании оценили свою удовлетворенность по шкале от 1 до 100:
Во-первых, обратите внимание, что данные немного зашумлены. То есть, хотя мы видим, что в этом есть закономерность (т. е. удовлетворенность сотрудников имеет тенденцию расти по мере роста заработной платы), она не все четко укладывается в прямую линию. Это всегда будет иметь место с реальными данными (и мы абсолютно хотим обучить нашу машину, используя реальные данные!). Так как же тогда мы можем научить машину точно предсказывать уровень удовлетворенности сотрудников? Ответ, конечно же, что мы не можем. Цель ML никогда не состоит в том, чтобы делать «идеальные» предположения, потому что ML имеет дело с областями, где таких вещей нет. Цель состоит в том, чтобы делать предположения, которые достаточно хороши, чтобы быть полезными.
Это чем-то напоминает известное высказывание британского математика и профессора статистики Джорджа Э.П. Бокса о том, что «все модели ошибочны, но некоторые из них полезны».
Машинное обучение в значительной степени основано на статистике. Например, когда мы обучаем нашу машину обучению, мы должны предоставить ей статистически значимую случайную выборку в качестве обучающих данных. Если обучающий набор не является случайным, мы рискуем получить шаблоны машинного обучения, которых на самом деле нет. И если обучающая выборка слишком мала (см. закон больших чисел), мы не узнаем достаточно и можем даже прийти к неточным выводам. Например, попытка предсказать модели удовлетворенности в масштабах всей компании на основе данных только от высшего руководства, скорее всего, будет подвержена ошибкам.
С этим пониманием давайте дадим нашей машине данные, которые мы дали выше, и пусть она их изучит. Сначала мы должны инициализировать наш предиктор h(x) некоторыми разумными значениями а также . Теперь наш предиктор выглядит так, если его поместить над нашим тренировочным набором:
Если мы спросим этот предиктор об удовлетворенности сотрудника, зарабатывающего 60 тысяч долларов, он предскажет рейтинг 27:
Очевидно, что это была ужасная догадка и что эта машина знает не так уж много.
Итак, теперь давайте дадим этому предсказателю все зарплаты из нашего обучающего набора и возьмем разницу между полученными прогнозируемыми рейтингами удовлетворенности и фактическими рейтингами удовлетворенности соответствующих сотрудников. Если мы проделаем небольшое математическое волшебство (которое я вскоре опишу), мы сможем вычислить с очень высокой степенью уверенности, что значения 13,12 для и 0,61 для собираются дать нам лучший предсказатель.
И если мы повторим этот процесс, скажем, 1500 раз, наш предиктор в конечном итоге будет выглядеть так:
В этот момент, если мы повторим процесс, мы обнаружим, что а также больше не изменится на сколько-нибудь заметную величину, и, таким образом, мы видим, что система сошлась. Если мы не допустили ошибок, значит, мы нашли оптимальный предиктор. Соответственно, если теперь мы снова спросим у машины рейтинг удовлетворенности сотрудника, который зарабатывает 60 000 долларов, он предскажет оценку примерно 60.
Теперь мы получаем где-то.
Регрессия машинного обучения: примечание о сложности
Вышеприведенный пример технически представляет собой простую задачу одномерной линейной регрессии, которую на самом деле можно решить, выведя простое нормальное уравнение и полностью пропустив этот процесс «настройки». Однако рассмотрим предиктор, который выглядит следующим образом:
Эта функция принимает входные данные в четырех измерениях и имеет множество полиномиальных членов. Вывод нормального уравнения для этой функции является серьезной проблемой. Многие современные задачи машинного обучения требуют тысяч или даже миллионов измерений данных для построения прогнозов с использованием сотен коэффициентов. Прогнозирование того, как будет выражен геном организма или каким будет климат через пятьдесят лет, — примеры таких сложных задач.
К счастью, итеративный подход, используемый системами машинного обучения, гораздо более устойчив к такой сложности. Вместо грубой силы система машинного обучения «нащупывает путь» к ответу. Для больших задач это работает намного лучше. Хотя это не означает, что машинное обучение может решить все сколь угодно сложные проблемы (на самом деле не может), оно делает его невероятно гибким и мощным инструментом.
Градиентный спуск — минимизация «неправильности»
Давайте подробнее рассмотрим, как работает этот итеративный процесс. В приведенном выше примере, как мы можем убедиться, а также с каждым шагом становятся лучше, а не хуже? Ответ заключается в нашем «измерении неправильности», о котором упоминалось ранее, а также в небольшом расчете.

Мера неправильности известна как функция стоимости (также известная как функция потерь ).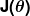 . Вход
. Вход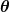 представляет все коэффициенты, которые мы используем в нашем предсказателе. Итак, в нашем случае это действительно пара а также .
представляет все коэффициенты, которые мы используем в нашем предсказателе. Итак, в нашем случае это действительно пара а также .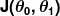 дает нам математическое измерение того, насколько неверен наш предиктор, когда он использует заданные значения а также .
дает нам математическое измерение того, насколько неверен наш предиктор, когда он использует заданные значения а также .
Выбор функции стоимости — еще одна важная часть программы машинного обучения. В разных контекстах быть «неправильным» может означать очень разные вещи. В нашем примере с удовлетворенностью сотрудников хорошо зарекомендовавшим себя стандартом является линейная функция наименьших квадратов:
В методе наименьших квадратов штраф за неверное предположение увеличивается квадратично с разницей между предположением и правильным ответом, поэтому он действует как очень «строгая» мера неправильности. Функция стоимости вычисляет средний штраф по всем обучающим примерам.
Итак, теперь мы видим, что наша цель — найти а также для нашего предиктора h(x) такого, что наша функция стоимости как можно меньше. Для этого мы призываем силу исчисления.
Рассмотрим следующий график функции стоимости для некоторой конкретной задачи машинного обучения:
Здесь мы можем видеть стоимость, связанную с различными значениями а также . Мы видим, что форма графика имеет небольшую чашу. Дно чаши представляет собой наименьшую стоимость, которую наш предиктор может дать нам на основе данных обучения. Цель состоит в том, чтобы «скатиться с горки» и найти а также соответствующий этому пункту.
Вот где исчисление входит в этот учебник по машинному обучению. Чтобы не усложнять это объяснение, я не буду приводить здесь уравнения, но, по сути, мы берем градиент , которая является парой производных от (один больше и еще один ). Градиент будет другим для каждого другого значения а также , и говорит нам, что такое «наклон холма» и, в частности, «какой путь вниз», для этих конкретных с. Например, когда мы подставляем наши текущие значения в градиент, это может сказать нам, что добавление немного к и немного отнять от приведет нас в направлении дна долины функции стоимости. Поэтому добавим немного , и вычесть немного из , и вуаля! Мы завершили один раунд нашего алгоритма обучения. Наш обновленный предиктор, h(x) = + x, будет возвращать лучшие прогнозы, чем раньше. Наша машина стала немного умнее.
Этот процесс чередования между вычислением текущего градиента и обновлением s из результатов, известен как градиентный спуск.
Это охватывает базовую теорию, лежащую в основе большинства контролируемых систем машинного обучения. Но базовые концепции можно применять по-разному, в зависимости от решаемой проблемы.
Проблемы классификации в машинном обучении
Под контролируемым отмыванием денег выделяют две основные подкатегории:
- Системы регрессионного машинного обучения: системы, в которых прогнозируемое значение находится где-то в непрерывном спектре. Эти системы помогают нам с вопросами «Сколько?» или «Сколько?».
- Системы машинного обучения классификации: Системы, в которых мы ищем прогноз «да» или «нет», например «Является ли эта опухоль раковой?», «Это печенье соответствует нашим стандартам качества?» и так далее.
Как оказалось, основная теория машинного обучения более или менее одинакова. Основные различия заключаются в конструкции предиктора h(x) и конструкции функции стоимости. .
До сих пор наши примеры были сосредоточены на проблемах регрессии, поэтому давайте теперь также рассмотрим пример классификации.
Вот результаты исследования качества файлов cookie, где все обучающие примеры были помечены как «хорошие файлы cookie» ( y = 1 ) синим цветом или «плохие файлы cookie» ( y = 0 ) красным цветом.
В классификации предиктор регрессии не очень полезен. Обычно нам нужен предсказатель, который делает предположение где-то между 0 и 1. В классификаторе качества файлов cookie прогноз 1 будет представлять очень уверенное предположение о том, что печенье идеальное и очень аппетитное. Прогноз 0 означает высокую степень уверенности в том, что файл cookie является помехой для индустрии файлов cookie. Значения, попадающие в этот диапазон, представляют меньшую достоверность, поэтому мы можем спроектировать нашу систему таким образом, чтобы предсказание 0,6 означало: «Чувак, это трудный выбор, но я соглашусь с да, вы можете продать это печенье», в то время как значение точно в средний балл 0,5 может означать полную неопределенность. Это не всегда то, как доверие распределяется в классификаторе, но это очень распространенный дизайн, который подходит для целей нашей иллюстрации.
Оказывается, есть хорошая функция, которая хорошо фиксирует это поведение. Она называется сигмовидной функцией g(z) и выглядит примерно так:
z — некоторое представление наших входных данных и коэффициентов, например:
так что наш предиктор становится:
Обратите внимание, что сигмовидная функция преобразует наш вывод в диапазон от 0 до 1.
Логика построения функции затрат также различается по классификации. Мы снова спрашиваем: «Что значит, если догадка ошибочна?» и на этот раз очень хорошее эмпирическое правило заключается в том, что если правильное предположение было 0, а мы угадали 1, то мы были полностью и совершенно неправы, и наоборот. Поскольку вы не можете быть более неправы, чем абсолютно неправы, наказание в этом случае огромно. В качестве альтернативы, если правильное предположение было 0, а мы угадали 0, наша функция стоимости не должна добавлять никаких затрат каждый раз, когда это происходит. Если догадка была верной, но мы не были полностью уверены (например, y = 1 , но h(x) = 0.8 ), это должно сопровождаться небольшими затратами, и если наша догадка была неверной, но мы не были полностью уверены ( например, y = 1 , но h(x) = 0.3 ), это должно быть сопряжено со значительными затратами, но не такими большими, как если бы мы были полностью неправы.
Это поведение фиксируется функцией журнала, так что:
Опять функция стоимости. дает нам среднюю стоимость по всем нашим обучающим примерам.
Итак, здесь мы описали, как предиктор h(x) и функция стоимости отличаются между регрессией и классификацией, но градиентный спуск по-прежнему работает нормально.
Предиктор классификации можно визуализировать, нарисовав граничную линию; т. е. барьер, при котором прогноз изменяется с «да» (прогноз больше 0,5) на «нет» (прогноз меньше 0,5). В хорошо спроектированной системе наши данные cookie могут генерировать границу классификации, которая выглядит следующим образом:
Теперь это машина, которая кое-что знает о файлах cookie!
Введение в нейронные сети
Ни одно обсуждение машинного обучения не будет полным без упоминания хотя бы нейронных сетей. Нейронные сети не только предлагают чрезвычайно мощный инструмент для решения очень сложных проблем, но также предлагают увлекательные подсказки о работе нашего собственного мозга и интригующие возможности для создания действительно интеллектуальных машин за один день.
Нейронные сети хорошо подходят для моделей машинного обучения, где количество входных данных огромно. Вычислительные затраты на решение такой задачи слишком велики для тех типов систем, которые мы обсуждали выше. Однако оказывается, что нейронные сети можно эффективно настраивать с помощью методов, которые в принципе поразительно похожи на градиентный спуск.
Подробное обсуждение нейронных сетей выходит за рамки этого руководства, но я рекомендую ознакомиться с нашим предыдущим постом на эту тему.
Неконтролируемое машинное обучение
Неконтролируемое машинное обучение обычно направлено на поиск взаимосвязей в данных. В этом процессе не используются обучающие примеры. Вместо этого системе дается набор данных и ставится задача найти в них закономерности и корреляции. Хороший пример — выявление сплоченных групп друзей в данных социальных сетей.
Алгоритмы машинного обучения, используемые для этого, сильно отличаются от тех, которые используются для обучения с учителем, и эта тема заслуживает отдельного поста. Однако, чтобы тем временем что-то пожевать, взгляните на алгоритмы кластеризации, такие как k-средние, а также изучите системы уменьшения размерности, такие как анализ основных компонентов. В нашей предыдущей публикации о больших данных также более подробно обсуждался ряд этих тем.
Заключение
Здесь мы рассмотрели большую часть базовой теории, лежащей в основе области машинного обучения, но, конечно, мы лишь слегка коснулись поверхности.
Имейте в виду, что для реального применения теорий, содержащихся в этом введении, к реальным примерам машинного обучения необходимо гораздо более глубокое понимание обсуждаемых здесь тем. В машинном обучении есть много тонкостей и подводных камней, а также множество способов сбиться с пути того, что кажется идеально отлаженной мыслящей машиной. Почти с каждой частью базовой теории можно играть и изменять бесконечно, и результаты часто бывают ошеломляющими. Многие вырастают в совершенно новые области исследований, которые лучше подходят для решения конкретных проблем.
Очевидно, что машинное обучение — невероятно мощный инструмент. В ближайшие годы он обещает помочь решить некоторые из наших самых насущных проблем, а также открыть совершенно новые возможности для фирм, занимающихся наукой о данных. Спрос на инженеров по машинному обучению будет только расти, предлагая невероятные шансы стать частью чего-то большого. Надеюсь, вы подумаете о том, чтобы принять участие в акции!
Подтверждение
Эта статья в значительной степени основана на материалах, преподаваемых профессором Стэнфордского университета доктором Эндрю Нг в его бесплатном и открытом курсе по машинному обучению. Курс подробно охватывает все, что обсуждается в этой статье, и дает массу практических советов практикующим специалистам по машинному обучению. Я не могу рекомендовать этот курс тем, кто заинтересован в дальнейшем изучении этой увлекательной области.
- Звуковая логика и монотонные модели ИИ
- Обучение Flappy Bird: Учебное пособие по обучению с подкреплением