
Makine Öğrenimi Teorisine Giriş ve Uygulamaları: Örneklerle Görsel Bir Eğitim
Yayınlanan: 2022-03-11Makine Öğrenimi (ML), ML'nin veri madenciliği, doğal dil işleme, görüntü tanıma ve uzman sistemler gibi çok çeşitli kritik uygulamalarda önemli bir rol oynayabileceği konusunda giderek artan bir anlayışla kendine geliyor. ML, tüm bu alanlarda ve daha fazlasında potansiyel çözümler sunar ve gelecekteki uygarlığımızın bir ayağı olmaya adaydır.
Yetenekli makine öğrenimi tasarımcılarının arzı henüz bu talebi karşılamadı. Bunun önemli bir nedeni, ML'nin sadece düz bir şekilde zor olmasıdır. Bu Makine Öğrenimi öğreticisi, ML teorisinin temellerini tanıtır, ortak temaları ve kavramları ortaya koyar, mantığı takip etmeyi ve makine öğrenimi temelleri konusunda rahat olmayı kolaylaştırır.
Makine Öğrenimi Nedir?
Peki "makine öğrenimi" tam olarak nedir? ML aslında bir çok şeydir. Alan oldukça geniştir ve hızla genişlemektedir, sürekli olarak bölümlere ayrılmakta ve alt bölümlere ayrılmakta ve mide bulandırıcı farklı alt uzmanlıklara ve makine öğrenimi türlerine ayrılmaktadır.
Bununla birlikte, bazı temel ortak konular vardır ve kapsayıcı tema, Arthur Samuel tarafından 1959'da yapılan ve sık sık alıntılanan bu ifadeyle en iyi şekilde özetlenebilir: "[Makine Öğrenimi] bilgisayarlara öğrenme yeteneği veren çalışma alanıdır. açıkça programlanmıştır.”
Daha yakın zamanda, 1997'de Tom Mitchell, mühendislik türleri için daha yararlı olduğu kanıtlanmış "iyi kurgulanmış " bir tanım verdi: P ile ölçülen T üzerindeki performansı, E deneyimi ile iyileşir.”
Dolayısıyla, programınızın örneğin yoğun bir kavşaktaki trafik kalıplarını tahmin etmesini istiyorsanız (görev T), geçmiş trafik kalıpları hakkında verilerle (deneyim E) ve başarılı bir şekilde "öğrenmişse" bir makine öğrenme algoritması aracılığıyla çalıştırabilirsiniz. ”, daha sonra gelecekteki trafik modellerini tahmin etmede daha başarılı olacaktır (performans ölçüsü P).
Gerçek dünyadaki birçok problemin oldukça karmaşık doğası, çoğu zaman, onları her seferinde mükemmel bir şekilde çözecek özel algoritmalar icat etmenin imkansız değilse de pratik olmadığı anlamına gelir. Makine öğrenimi sorunlarına örnek olarak, “Bu kanser mi?”, “Bu evin piyasa değeri nedir?”, “Bu insanlardan hangisi birbiriyle iyi arkadaş?”, “Bu roket motoru kalkışta patlayacak mı? ”, “Bu kişi bu filmi beğenecek mi?”, “Bu kim?”, “Ne dedin?”, “Bu şeyi nasıl uçurursun?”. Tüm bu problemler, bir ML projesi için mükemmel hedeflerdir ve aslında ML, her birine büyük bir başarı ile uygulanmıştır.
Makine öğrenimi görevlerinin farklı türleri arasında denetimli ve denetimsiz öğrenme arasında önemli bir ayrım yapılır:
- Denetimli makine öğrenimi: Program, önceden tanımlanmış bir dizi "eğitim örnekleri" üzerinde "eğitilir" ve bu, yeni veriler verildiğinde doğru bir sonuca varma becerisini kolaylaştırır.
- Denetimsiz makine öğrenimi: Programa bir sürü veri verilir ve bunların içindeki kalıpları ve ilişkileri bulması gerekir.
Burada öncelikle denetimli öğrenmeye odaklanacağız, ancak makalenin sonunda konuyu daha fazla takip etmek isteyenler için bazı bağlantılarla birlikte denetimsiz öğrenme hakkında kısa bir tartışma yer alıyor.
Denetimli Makine Öğrenimi
Denetimli öğrenme uygulamalarının çoğunda nihai amaç, ince ayarlanmış bir tahmin fonksiyonu h(x) (bazen “hipotez” olarak adlandırılır) geliştirmektir. "Öğrenme", bu işlevi optimize etmek için karmaşık matematiksel algoritmalar kullanmaktan oluşur, böylece belirli bir alan (örneğin, bir evin metrekaresi) hakkında girdi verisi x verildiğinde, bazı ilginç h(x) değerini (örneğin, piyasa fiyatı) doğru bir şekilde tahmin eder. söz konusu ev için).
Pratikte, x neredeyse her zaman birden çok veri noktasını temsil eder. Dolayısıyla, örneğin, bir konut fiyatı tahmincisi yalnızca metrekareyi ( x1 ) değil, aynı zamanda yatak odası sayısını ( x2 ), banyo sayısını ( x3 ), kat sayısını ( x4) , inşa yılını ( x5 ), posta kodunu da alabilir. ( x6 ) vb. Hangi girdilerin kullanılacağının belirlenmesi, makine öğrenimi tasarımının önemli bir parçasıdır. Ancak, açıklama amacıyla, tek bir giriş değerinin kullanıldığını varsaymak en kolay yoldur.
Diyelim ki basit tahmincimiz şu forma sahip:
nerede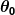 ve
ve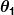 sabitlerdir. Amacımız, mükemmel değerleri bulmaktır. ve tahmincimizin mümkün olduğunca iyi çalışmasını sağlamak için.
sabitlerdir. Amacımız, mükemmel değerleri bulmaktır. ve tahmincimizin mümkün olduğunca iyi çalışmasını sağlamak için.
h(x) tahmin edicisinin optimizasyonu, eğitim örnekleri kullanılarak yapılır. Her eğitim örneği için, karşılık gelen çıktının ( y ) önceden bilindiği x_train girdi değerine sahibiz. Her örnek için, bilinen, doğru değer y ile tahmin edilen h(x_train) değeri arasındaki farkı buluruz. Yeterli eğitim örneğiyle, bu farklılıklar bize h(x) 'in "yanlışlığını" ölçmek için yararlı bir yol sağlar. Daha sonra, değerlerini değiştirerek h(x) ayarını yapabiliriz. ve "daha az yanlış" yapmak için. Bu işlem, sistem için en iyi değerlere yakınsayana kadar defalarca tekrarlanır. ve . Bu şekilde, tahminci eğitilir ve gerçek dünya tahminlerini yapmaya hazır hale gelir.
Makine Öğrenimi Örnekleri
Bu gönderide örnek olsun diye basit problemlere bağlı kaldık, ancak ML'nin var olmasının nedeni, gerçek dünyada problemlerin çok daha karmaşık olmasıdır. Bu düz ekranda size en fazla üç boyutlu bir veri kümesinin resmini çizebiliriz, ancak ML sorunları genellikle milyonlarca boyutlu verilerle ve çok karmaşık tahmin işlevleriyle ilgilenir. ML, yalnızca sayısal yollarla çözülemeyen sorunları çözer.
Bunu akılda tutarak, basit bir örneğe bakalım. Diyelim ki, şirket çalışanlarının memnuniyetlerini 1 ile 100 arasında derecelendirdiği aşağıdaki eğitim verilerine sahibiz:
İlk olarak, verilerin biraz gürültülü olduğuna dikkat edin. Yani, bunun bir modeli olduğunu görebilsek de (yani maaş arttıkça çalışan memnuniyeti de artma eğilimindedir), hepsi düzgün bir çizgiye tam olarak oturmamaktadır. Bu, gerçek dünya verilerinde her zaman böyle olacaktır (ve makinemizi kesinlikle gerçek dünya verilerini kullanarak eğitmek istiyoruz!). Öyleyse, bir çalışanın memnuniyet seviyesini mükemmel bir şekilde tahmin etmek için bir makineyi nasıl eğitebiliriz? Cevap, elbette, yapamayız. ML'nin amacı asla "mükemmel" tahminler yapmak değildir, çünkü ML böyle bir şeyin olmadığı alanlarla ilgilenir. Amaç, faydalı olacak kadar iyi tahminler yapmaktır.
Bu, İngiliz matematikçi ve istatistik profesörü George EP Box'ın “bütün modeller yanlıştır, ancak bazıları faydalıdır” şeklindeki ünlü ifadesini biraz andırıyor.
Makine Öğrenimi, ağırlıklı olarak istatistikler üzerine kuruludur. Örneğin, makinemizi öğrenmek için eğittiğimizde, ona eğitim verisi olarak istatistiksel olarak anlamlı bir rastgele örnek vermeliyiz. Eğitim seti rastgele değilse, aslında orada olmayan makine öğrenimi kalıpları riskiyle karşı karşıya kalırız. Ve eğer eğitim seti çok küçükse (büyük sayılar yasasına bakınız), yeterince öğrenemeyeceğiz ve hatta yanlış sonuçlara varabiliriz. Örneğin, yalnızca üst yönetimden alınan verilere dayanarak şirket çapında memnuniyet kalıplarını tahmin etmeye çalışmak, muhtemelen hataya açık olacaktır.
Bu anlayışla yukarıda verdiğimiz verileri makinemize verelim ve öğrenmesini sağlayalım. İlk önce h(x) tahmincimizi bazı makul değerlerle başlatmamız gerekiyor. ve . Şimdi tahmincimiz, eğitim setimizin üzerine yerleştirildiğinde şöyle görünür:
Bu tahmin ediciye 60 bin dolar kazanan bir çalışanın memnuniyetini sorarsak, 27 derecesini tahmin eder:
Bunun korkunç bir tahmin olduğu ve bu makinenin pek bir şey bilmediği açık.
Şimdi, bu tahminciye eğitim setimizin tüm maaşlarını verelim ve sonuçta ortaya çıkan tahmini memnuniyet derecelendirmeleri ile ilgili çalışanların gerçek memnuniyet derecelendirmeleri arasındaki farkları alalım. Biraz matematiksel sihirbazlık yaparsak (ki bunu birazdan anlatacağım), çok yüksek bir kesinlikle hesaplayabiliriz. ve 0.61 için bize daha iyi bir tahminci verecekler.
Ve eğer bu işlemi 1500 kez tekrar edersek, tahmincimiz şöyle görünecek:
Bu noktada işlemi tekrar edersek şunu buluruz. ve artık kayda değer miktarda değişmeyecek ve böylece sistemin yakınsadığını görüyoruz. Herhangi bir hata yapmadıysak, bu en uygun tahmin ediciyi bulduğumuz anlamına gelir. Buna göre, şimdi makineye tekrar 60 bin dolar kazanan çalışanın memnuniyet derecesini sorarsak, yaklaşık 60'lık bir derecelendirme tahmin edecektir.
Şimdi bir yere varıyoruz.
Makine Öğrenimi Regresyonu: Karmaşıklık Üzerine Bir Not
Yukarıdaki örnek, teknik olarak basit bir tek değişkenli doğrusal regresyon problemidir ve gerçekte basit bir normal denklem türetilerek ve bu "ayar" sürecini tamamen atlayarak çözülebilir. Ancak, şuna benzeyen bir tahmin edici düşünün:
Bu fonksiyon girdiyi dört boyutta alır ve çeşitli polinom terimlerine sahiptir. Bu fonksiyon için normal bir denklem türetmek önemli bir zorluktur. Birçok modern makine öğrenimi problemi, yüzlerce katsayı kullanarak tahminler oluşturmak için binlerce hatta milyonlarca veri boyutunu alır. Bir organizmanın genomunun nasıl ifade edileceğini veya elli yıl içinde iklimin nasıl olacağını tahmin etmek, bu tür karmaşık problemlere örnektir.
Neyse ki, ML sistemleri tarafından alınan yinelemeli yaklaşım, bu tür karmaşıklık karşısında çok daha dayanıklıdır. Kaba kuvvet kullanmak yerine, bir makine öğrenimi sistemi cevaba “yolunu bulur”. Büyük problemler için bu çok daha iyi çalışır. Bu, ML'nin tüm keyfi olarak karmaşık sorunları çözebileceği anlamına gelmese de (olamaz), inanılmaz derecede esnek ve güçlü bir araç yapar.
Gradient Descent - “Yanlışlığı” En Aza İndirme
Bu yinelemeli sürecin nasıl çalıştığına daha yakından bakalım. Yukarıdaki örnekte, nasıl emin olabiliriz? ve her adımda daha iyiye gidiyor ve daha da kötüye gitmiyor mu? Cevap, küçük bir hesapla birlikte daha önce ima edilen “yanlışlık ölçümümüzde” yatmaktadır.

Yanlışlık ölçüsü, maliyet fonksiyonu (diğer adıyla kayıp fonksiyonu ) olarak bilinir.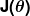 . Girdi
. Girdi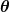 tahmincimizde kullandığımız tüm katsayıları temsil eder. Yani bizim durumumuzda, gerçekten çift mi ve .
tahmincimizde kullandığımız tüm katsayıları temsil eder. Yani bizim durumumuzda, gerçekten çift mi ve .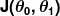 bize, verilen değerleri kullandığında tahmincimizin ne kadar yanlış olduğuna dair matematiksel bir ölçüm verir. ve .
bize, verilen değerleri kullandığında tahmincimizin ne kadar yanlış olduğuna dair matematiksel bir ölçüm verir. ve .
Maliyet fonksiyonunun seçimi, bir ML programının bir diğer önemli parçasıdır. Farklı bağlamlarda, “yanlış” olmak çok farklı anlamlara gelebilir. Çalışan memnuniyeti örneğimizde, yerleşik standart, doğrusal en küçük kareler işlevidir:
En küçük karelerle, kötü bir tahminin cezası, tahmin ve doğru cevap arasındaki farkla ikinci dereceden artar, bu nedenle çok "katı" bir yanlışlık ölçümü görevi görür. Maliyet işlevi, tüm eğitim örnekleri üzerinden ortalama bir ceza hesaplar.
Şimdi amacımızın bulmak olduğunu görüyoruz. ve h(x) tahmincimiz için maliyet fonksiyonumuz mümkün olduğunca küçüktür. Bunu başarmak için matematiğin gücünden yararlanıyoruz.
Belirli bir Makine Öğrenimi problemi için aşağıdaki maliyet fonksiyonunun grafiğini göz önünde bulundurun:
Burada farklı değerlerle ilişkili maliyeti görebiliriz. ve . Grafiğin şekline göre hafif bir kase olduğunu görebiliriz. Kasenin alt kısmı, verilen eğitim verilerine dayanarak tahmincimizin bize verebileceği en düşük maliyeti temsil eder. Amaç “tepeden aşağı yuvarlanmak” ve ve bu noktaya karşılık gelir.
Bu makine öğrenimi eğitiminde matematiğin devreye girdiği yer burasıdır. Bu açıklamayı yönetilebilir kılmak adına, burada denklemleri yazmayacağım, ama esasen yaptığımız şey, gradyanını almaktır. , türev çifti olan (bir tanesi bitti ve bir üzeri ). Gradyan, her farklı değer için farklı olacaktır. ve , ve bize “tepenin eğiminin” ne olduğunu ve özellikle bu belirli alanlar için “hangi yolun aşağı olduğunu” söyler. s. Örneğin, mevcut değerlerimizi bağladığımızda gradyanda, bize biraz eklemenin olduğunu söyleyebilir ve biraz çıkarma bizi maliyet-fonksiyon-vadi katı yönünde götürecek. Bu nedenle, biraz ekliyoruz , ve biraz çıkarın ve işte! Öğrenme algoritmamızın bir turunu tamamladık. Güncellenmiş tahmincimiz, h(x) = + x, öncekinden daha iyi tahminler getirecektir. Makinemiz artık biraz daha akıllı.
Mevcut gradyanın hesaplanması ve güncellenmesi arasında değişen bu süreç sonuçlardan s, gradyan inişi olarak bilinir.
Bu, denetimli Makine Öğrenimi sistemlerinin çoğunun altında yatan temel teoriyi kapsar. Ancak temel kavramlar, eldeki soruna bağlı olarak çeşitli farklı şekillerde uygulanabilir.
Makine Öğreniminde Sınıflandırma Problemleri
Denetimli makine öğrenimi kapsamında iki ana alt kategori vardır:
- Regresyon makine öğrenimi sistemleri: Tahmin edilen değerin sürekli bir spektrumda bir yere düştüğü sistemler. Bu sistemler bize “Ne kadar?” sorularında yardımcı oluyor. veya "Kaç tane?".
- Sınıflandırma makine öğrenimi sistemleri: "Bu tümör kanserli mi?", "Bu çerez kalite standartlarımızı karşılıyor mu?" vb. gibi bir evet-hayır tahmini aradığımız sistemler.
Görünen o ki, temeldeki Makine Öğrenimi teorisi aşağı yukarı aynıdır. Başlıca farklar, h(x) tahmincisinin tasarımı ve maliyet fonksiyonunun tasarımıdır. .
Şimdiye kadarki örneklerimiz regresyon problemlerine odaklandı, şimdi bir sınıflandırma örneğine de bakalım.
Burada, eğitim örneklerinin tümünün mavi renkte "iyi çerez" ( y = 1 ) veya kırmızı renkte "kötü çerez" ( y = 0 ) olarak etiketlendiği bir çerez kalite testi çalışmasının sonuçları verilmiştir.
Sınıflandırmada, bir regresyon tahmincisi çok kullanışlı değildir. Genellikle istediğimiz, 0 ile 1 arasında bir tahminde bulunan bir tahmin edicidir. Bir çerez kalite sınıflandırıcısında, 1 tahmini, çerezin mükemmel ve tamamen ağız sulandıran olduğuna dair çok emin bir tahmini temsil eder. 0 tahmini, çerezin çerez endüstrisi için bir utanç kaynağı olduğuna dair yüksek güveni temsil eder. Bu aralığa düşen değerler daha az güveni temsil eder, bu nedenle sistemimizi 0,6 tahmini "Dostum, bu zor bir karar, ama evet ile gideceğim, o çerezi satabilirsin" anlamına gelecek şekilde tasarlayabiliriz. orta, 0,5'te, tam belirsizliği temsil edebilir. Bu, her zaman bir sınıflandırıcıda güvenin nasıl dağıtıldığı değildir, ancak çok yaygın bir tasarımdır ve gösterimimizin amaçları için çalışır.
Bu davranışı iyi yakalayan güzel bir işlev olduğu ortaya çıktı. Buna sigmoid işlevi denir, g(z) ve şuna benzer:
z , girdilerimizin ve katsayılarımızın bir temsilidir, örneğin:
böylece tahmincimiz şöyle olur:
Sigmoid fonksiyonunun çıktımızı 0 ile 1 arasında bir aralığa dönüştürdüğüne dikkat edin.
Maliyet fonksiyonunun tasarımının arkasındaki mantık da sınıflandırmada farklıdır. Yine “bir tahminin yanlış olması ne anlama gelir?” diye soruyoruz. ve bu sefer çok iyi bir kural, eğer doğru tahmin 0 ise ve biz 1 tahmin edersek, o zaman tamamen ve tamamen yanılmışızdır ve bunun tersi de geçerlidir. Kesinlikle yanlış olmaktan daha fazla yanlış olamayacağınız için, bu durumda ceza çok büyük. Alternatif olarak, doğru tahmin 0 ise ve biz 0 tahmin edersek, maliyet fonksiyonumuz bunun her gerçekleştiğinde herhangi bir maliyet eklememelidir. Tahmin doğruysa, ancak tam olarak emin değilsek (örneğin, y = 1 , ancak h(x) = 0.8 ), bunun küçük bir maliyeti olmalı ve tahminimiz yanlışsa ancak tam olarak emin değilsek ( örneğin y = 1 ama h(x) = 0.3 ), bunun önemli bir maliyeti olmalı, ancak tamamen yanılıyormuşuz kadar değil.
Bu davranış, günlük işlevi tarafından şu şekilde yakalanır:
Yine maliyet fonksiyonu bize tüm eğitim örneklerimizin ortalama maliyetini verir.
Burada h(x) tahmin edicisinin ve maliyet fonksiyonunun nasıl olduğunu açıkladık. regresyon ve sınıflandırma arasında farklılık gösterir, ancak gradyan inişi hala iyi çalışıyor.
Bir sınıflandırma tahmincisi, sınır çizgisi çizilerek görselleştirilebilir; yani, tahminin "evet"ten (0,5'ten büyük bir tahmin) "hayır"a (0,5'ten küçük bir tahmin) değiştiği engel. İyi tasarlanmış bir sistemle, çerez verilerimiz şuna benzeyen bir sınıflandırma sınırı oluşturabilir:
Şimdi bu, çerezler hakkında bir iki şey bilen bir makine!
Sinir Ağlarına Giriş
En azından sinir ağlarından bahsetmeden hiçbir Makine Öğrenimi tartışması tamamlanmış sayılmaz. Sinir ağları sadece çok zor problemleri çözmek için son derece güçlü bir araç sunmakla kalmaz, aynı zamanda kendi beynimizin işleyişine dair büyüleyici ipuçları ve bir gün gerçekten akıllı makineler yaratmak için ilgi çekici olanaklar sunar.
Sinir ağları, girdi sayısının devasa olduğu makine öğrenimi modellerine çok uygundur. Böyle bir sorunu ele almanın hesaplama maliyeti, yukarıda tartıştığımız sistem türleri için çok fazla. Bununla birlikte, ortaya çıktığı gibi, sinir ağları, prensipte gradyan inişine çarpıcı biçimde benzeyen teknikler kullanılarak etkin bir şekilde ayarlanabilir.
Sinir ağlarının kapsamlı bir tartışması bu eğitimin kapsamı dışındadır, ancak konuyla ilgili önceki yazımıza göz atmanızı tavsiye ederim.
Denetimsiz Makine Öğrenimi
Denetimsiz makine öğrenimi, genellikle veriler içindeki ilişkileri bulmakla görevlidir. Bu süreçte kullanılan hiçbir eğitim örneği yoktur. Bunun yerine, sisteme bir dizi veri verilir ve buradaki kalıpları ve korelasyonları bulmakla görevlendirilir. İyi bir örnek, sosyal ağ verilerinde birbirine sıkı sıkıya bağlı arkadaş gruplarını belirlemektir.
Bunu yapmak için kullanılan Makine Öğrenimi algoritmaları, denetimli öğrenme için kullanılanlardan çok farklıdır ve konu kendi gönderisini hak ediyor. Bununla birlikte, bu arada üzerinde durulması gereken bir şey için, k-ortalamalar gibi kümeleme algoritmalarına bir göz atın ve ayrıca temel bileşen analizi gibi boyutsallık azaltma sistemlerine bakın. Büyük verilerle ilgili önceki yazımız da bu konuların bir kısmını daha ayrıntılı olarak tartışıyor.
Çözüm
Burada Makine Öğrenimi alanının altında yatan temel teorinin çoğunu ele aldık, ancak elbette yüzeyi ancak zar zor çizebildik.
Bu girişte yer alan teorileri gerçek hayattaki makine öğrenimi örneklerine gerçekten uygulamak için burada tartışılan konuların çok daha derinden anlaşılması gerektiğini unutmayın. ML'de pek çok incelik ve tuzak vardır ve mükemmel şekilde ayarlanmış bir düşünce makinesi gibi görünen şey tarafından yanlış yönlendirilmenin birçok yolu vardır. Temel teorinin hemen hemen her parçası ile sonsuza kadar oynanabilir ve değiştirilebilir ve sonuçlar genellikle büyüleyicidir. Birçoğu, belirli sorunlara daha uygun olan yepyeni çalışma alanlarına dönüşür.
Açıkçası, Makine Öğrenimi inanılmaz derecede güçlü bir araçtır. Önümüzdeki yıllarda, en acil sorunlarımızdan bazılarının çözülmesine yardımcı olmanın yanı sıra veri bilimi firmaları için yepyeni fırsatlar dünyasının kapılarını açmayı vaat ediyor. Makine Öğrenimi mühendislerine olan talep, yalnızca büyümeye devam edecek ve büyük bir şeyin parçası olmak için inanılmaz fırsatlar sunacak. Umarım harekete geçmeyi düşünürsünüz!
teşekkür
Bu makale ağırlıklı olarak Stanford Profesörü Dr. Andrew Ng tarafından ücretsiz ve açık Makine Öğrenimi kursunda öğretilen materyalden yararlanmaktadır. Kurs, bu makalede tartışılan her şeyi derinlemesine ele alır ve makine öğrenimi uygulayıcısı için tonlarca pratik tavsiye verir. Bu büyüleyici alanı daha fazla keşfetmek isteyenler için bu kursu yeterince tavsiye edemem.
- Ses Mantığı ve Monotonik Yapay Zeka Modelleri
- Flappy Bird Eğitimi: Takviye Edici Öğrenme Eğitimi