
Uma introdução à teoria do aprendizado de máquina e suas aplicações: um tutorial visual com exemplos
Publicados: 2022-03-11O Machine Learning (ML) está se destacando, com um crescente reconhecimento de que o ML pode desempenhar um papel fundamental em uma ampla variedade de aplicativos críticos, como mineração de dados, processamento de linguagem natural, reconhecimento de imagem e sistemas especialistas. O ML fornece soluções potenciais em todos esses domínios e muito mais, e deve ser um pilar de nossa futura civilização.
A oferta de designers de ML capazes ainda precisa atender a essa demanda. Uma das principais razões para isso é que o ML é simplesmente complicado. Este tutorial de Machine Learning apresenta os fundamentos da teoria de ML, estabelecendo os temas e conceitos comuns, tornando mais fácil seguir a lógica e se familiarizar com os fundamentos do aprendizado de máquina.
O que é Aprendizado de Máquina?
Então, o que exatamente é “aprendizado de máquina”? ML é realmente um monte de coisas. O campo é bastante vasto e está se expandindo rapidamente, sendo continuamente particionado e sub-particionado ad nauseam em diferentes subespecialidades e tipos de aprendizado de máquina.
Existem alguns tópicos comuns básicos, no entanto, e o tema abrangente é melhor resumido por esta declaração frequentemente citada feita por Arthur Samuel em 1959: “[Machine Learning é o] campo de estudo que dá aos computadores a capacidade de aprender sem sendo explicitamente programado”.
E mais recentemente, em 1997, Tom Mitchell deu uma definição “bem colocada” que provou ser mais útil para os tipos de engenharia: “Diz-se que um programa de computador aprende com a experiência E em relação a alguma tarefa T e alguma medida de desempenho P, se seu desempenho em T, medido por P, melhora com a experiência E.”
Portanto, se você deseja que seu programa preveja, por exemplo, padrões de tráfego em um cruzamento movimentado (tarefa T), você pode executá-lo por meio de um algoritmo de aprendizado de máquina com dados sobre padrões de tráfego anteriores (experiência E) e, se tiver “aprendido com sucesso ”, ele se sairá melhor na previsão de padrões de tráfego futuros (medida de desempenho P).
A natureza altamente complexa de muitos problemas do mundo real, no entanto, muitas vezes significa que inventar algoritmos especializados que os resolverão perfeitamente todas as vezes é impraticável, se não impossível. Exemplos de problemas de aprendizado de máquina incluem: “Isso é câncer?”, “Qual é o valor de mercado desta casa?”, “Quais dessas pessoas são boas amigas umas das outras?”, “Esse motor de foguete explodirá na decolagem? ”, “Essa pessoa vai gostar desse filme?”, “Quem é esse?”, “O que você disse?” e “Como você pilota essa coisa?”. Todos esses problemas são excelentes alvos para um projeto de ML e, de fato, o ML foi aplicado a cada um deles com grande sucesso.
Entre os diferentes tipos de tarefas de ML, uma distinção crucial é feita entre aprendizado supervisionado e não supervisionado:
- Aprendizado de máquina supervisionado: o programa é “treinado” em um conjunto predefinido de “exemplos de treinamento”, que facilitam sua capacidade de chegar a uma conclusão precisa quando recebem novos dados.
- Aprendizado de máquina não supervisionado: o programa recebe um monte de dados e deve encontrar padrões e relacionamentos neles.
Vamos nos concentrar principalmente no aprendizado supervisionado aqui, mas o final do artigo inclui uma breve discussão sobre o aprendizado não supervisionado com alguns links para aqueles que estão interessados em aprofundar o tópico.
Aprendizado de máquina supervisionado
Na maioria das aplicações de aprendizado supervisionado, o objetivo final é desenvolver uma função preditora h(x) afinada (às vezes chamada de “hipótese”). “Aprendizagem” consiste em usar algoritmos matemáticos sofisticados para otimizar esta função de modo que, dados os dados de entrada x sobre um determinado domínio (digamos, metragem quadrada de uma casa), ela preveja com precisão algum valor interessante h(x) (digamos, preço de mercado para a referida casa).
Na prática, x quase sempre representa vários pontos de dados. Assim, por exemplo, um preditor de preço de habitação pode levar não apenas metragem quadrada ( x1 ), mas também número de quartos ( x2 ), número de banheiros ( x3 ), número de andares ( x4) , ano de construção ( x5 ), código postal ( x6 ), e assim por diante. Determinar quais entradas usar é uma parte importante do design de ML. No entanto, para fins de explicação, é mais fácil assumir que um único valor de entrada é usado.
Então, digamos que nosso preditor simples tenha esta forma:
Onde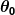 e
e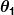 são constantes. Nosso objetivo é encontrar os valores perfeitos de e para fazer nosso preditor funcionar o melhor possível.
são constantes. Nosso objetivo é encontrar os valores perfeitos de e para fazer nosso preditor funcionar o melhor possível.
A otimização do preditor h(x) é feita usando exemplos de treinamento . Para cada exemplo de treinamento, temos um valor de entrada x_train , para o qual uma saída correspondente, y , é conhecida antecipadamente. Para cada exemplo, encontramos a diferença entre o valor conhecido e correto y e nosso valor previsto h(x_train) . Com exemplos de treinamento suficientes, essas diferenças nos dão uma maneira útil de medir a “incorreção” de h(x) . Podemos então ajustar h(x) ajustando os valores de e para torná-lo “menos errado”. Este processo é repetido várias vezes até que o sistema tenha convergido para os melhores valores para e . Dessa forma, o preditor é treinado e está pronto para fazer algumas previsões do mundo real.
Exemplos de aprendizado de máquina
Nós nos apegamos a problemas simples neste post para fins de ilustração, mas a razão pela qual o ML existe é porque, no mundo real, os problemas são muito mais complexos. Nesta tela plana, podemos desenhar uma imagem de, no máximo, um conjunto de dados tridimensional, mas os problemas de ML geralmente lidam com dados com milhões de dimensões e funções de previsão muito complexas. O ML resolve problemas que não podem ser resolvidos apenas por meios numéricos.
Com isso em mente, vejamos um exemplo simples. Digamos que temos os seguintes dados de treinamento, em que os funcionários da empresa classificaram sua satisfação em uma escala de 1 a 100:
Primeiro, observe que os dados são um pouco barulhentos. Ou seja, embora possamos ver que há um padrão para isso (ou seja, a satisfação do funcionário tende a aumentar à medida que o salário aumenta), nem tudo se encaixa perfeitamente em uma linha reta. Este sempre será o caso com dados do mundo real (e absolutamente queremos treinar nossa máquina usando dados do mundo real!). Então, como podemos treinar uma máquina para prever perfeitamente o nível de satisfação de um funcionário? A resposta, claro, é que não podemos. O objetivo do ML nunca é fazer suposições “perfeitas”, porque o ML lida em domínios onde não existe tal coisa. O objetivo é fazer suposições que sejam boas o suficiente para serem úteis.
Isso lembra um pouco a famosa afirmação do matemático e professor de estatística britânico George EP Box de que “todos os modelos estão errados, mas alguns são úteis”.
Machine Learning baseia-se fortemente em estatísticas. Por exemplo, quando treinamos nossa máquina para aprender, temos que fornecer uma amostra aleatória estatisticamente significativa como dados de treinamento. Se o conjunto de treinamento não for aleatório, corremos o risco de padrões de aprendizado de máquina que não estão realmente lá. E se o conjunto de treinamento for muito pequeno (veja a lei dos grandes números), não aprenderemos o suficiente e podemos até chegar a conclusões imprecisas. Por exemplo, tentar prever padrões de satisfação em toda a empresa com base apenas em dados da alta administração provavelmente seria propenso a erros.
Com esse entendimento, vamos dar à nossa máquina os dados que recebemos acima e fazer com que ela aprenda. Primeiro temos que inicializar nosso preditor h(x) com alguns valores razoáveis de e . Agora, nosso preditor fica assim quando colocado sobre nosso conjunto de treinamento:
Se perguntarmos a esse preditor sobre a satisfação de um funcionário que ganha US$ 60 mil, ele prevê uma classificação de 27:
É óbvio que este foi um palpite terrível e que esta máquina não sabe muito.
Então, agora, vamos dar a esse preditor todos os salários do nosso conjunto de treinamento e tomar as diferenças entre os índices de satisfação previstos resultantes e os índices de satisfação reais dos funcionários correspondentes. Se fizermos um pouco de mágica matemática (que descreverei em breve), podemos calcular, com grande certeza, que valores de 13,12 para e 0,61 para vão nos dar uma previsão melhor.
E se repetirmos esse processo, digamos 1500 vezes, nosso preditor ficará assim:
Neste ponto, se repetirmos o processo, descobriremos que e não mudará mais em quantidade apreciável e, assim, vemos que o sistema convergiu. Se não cometemos nenhum erro, isso significa que encontramos o preditor ideal. Da mesma forma, se agora perguntarmos à máquina novamente o índice de satisfação do funcionário que ganha $ 60 mil, ele preverá um índice de aproximadamente 60.
Agora estamos chegando a algum lugar.
Regressão de aprendizado de máquina: uma observação sobre a complexidade
O exemplo acima é tecnicamente um problema simples de regressão linear univariada, que na realidade pode ser resolvido derivando uma equação normal simples e ignorando completamente esse processo de “ajuste”. No entanto, considere um preditor que se parece com isso:
Esta função recebe entrada em quatro dimensões e tem uma variedade de termos polinomiais. Deduzir uma equação normal para esta função é um desafio significativo. Muitos problemas modernos de aprendizado de máquina levam milhares ou até milhões de dimensões de dados para construir previsões usando centenas de coeficientes. Prever como o genoma de um organismo será expresso, ou como será o clima em cinquenta anos, são exemplos de problemas tão complexos.
Felizmente, a abordagem iterativa adotada pelos sistemas de ML é muito mais resiliente diante de tal complexidade. Em vez de usar força bruta, um sistema de aprendizado de máquina “sente o caminho” para a resposta. Para grandes problemas, isso funciona muito melhor. Embora isso não signifique que o ML possa resolver todos os problemas arbitrariamente complexos (não pode), ele é uma ferramenta incrivelmente flexível e poderosa.
Descida Gradiente - Minimizando o “erro”
Vamos dar uma olhada em como esse processo iterativo funciona. No exemplo acima, como podemos ter certeza e estão melhorando a cada passo, e não piorando? A resposta está em nossa “medição do erro” aludida anteriormente, junto com um pouco de cálculo.

A medida de erro é conhecida como função de custo (também conhecida como função de perda ),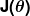 . A entrada
. A entrada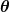 representa todos os coeficientes que estamos usando em nosso preditor. Então, no nosso caso, é realmente o par e .
representa todos os coeficientes que estamos usando em nosso preditor. Então, no nosso caso, é realmente o par e .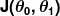 nos dá uma medida matemática de quão errado nosso preditor está quando ele usa os valores dados de e .
nos dá uma medida matemática de quão errado nosso preditor está quando ele usa os valores dados de e .
A escolha da função de custo é outra parte importante de um programa de ML. Em diferentes contextos, estar “errado” pode significar coisas muito diferentes. Em nosso exemplo de satisfação do funcionário, o padrão bem estabelecido é a função linear dos mínimos quadrados:
Com os mínimos quadrados, a penalidade por um palpite errado aumenta quadraticamente com a diferença entre o palpite e a resposta correta, então funciona como uma medida muito “estrita” de erro. A função de custo calcula uma penalidade média sobre todos os exemplos de treinamento.
Então agora vemos que nosso objetivo é encontrar e para nosso preditor h(x) tal que nossa função de custo é o menor possível. Apelamos ao poder do cálculo para conseguir isso.
Considere o seguinte gráfico de uma função de custo para algum problema específico de Machine Learning:
Aqui podemos ver o custo associado a diferentes valores de e . Podemos ver que o gráfico tem uma pequena tigela em sua forma. A parte inferior da tigela representa o menor custo que nosso preditor pode nos fornecer com base nos dados de treinamento fornecidos. O objetivo é “rolar morro abaixo” e encontrar e correspondente a este ponto.
É aqui que entra o cálculo neste tutorial de aprendizado de máquina. Para manter essa explicação administrável, não escreverei as equações aqui, mas essencialmente o que fazemos é pegar o gradiente de , que é o par de derivadas de (um sobre e mais um ). O gradiente será diferente para cada valor diferente de e , e nos diz qual é a “inclinação do morro” e, em particular, “qual é a descida”, para esses s. Por exemplo, quando colocamos nossos valores atuais de no gradiente, isso pode nos dizer que adicionar um pouco e subtraindo um pouco de nos levará na direção do piso do vale da função de custo. Portanto, acrescentamos um pouco , e subtraia um pouco de , e voilá! Concluímos uma rodada de nosso algoritmo de aprendizado. Nosso preditor atualizado, h(x) = + x, retornará melhores previsões do que antes. Nossa máquina é agora um pouco mais inteligente.
Este processo de alternar entre calcular o gradiente atual e atualizar o s dos resultados, é conhecido como gradiente descendente.
Isso cobre a teoria básica subjacente à maioria dos sistemas supervisionados de aprendizado de máquina. Mas os conceitos básicos podem ser aplicados de várias maneiras diferentes, dependendo do problema em questão.
Problemas de classificação em aprendizado de máquina
No ML supervisionado, duas subcategorias principais são:
- Sistemas de aprendizado de máquina de regressão: Sistemas em que o valor previsto cai em algum lugar em um espectro contínuo. Esses sistemas nos ajudam com perguntas de "Quanto?" ou “Quantos?”.
- Sistemas de aprendizado de máquina de classificação: Sistemas em que buscamos uma previsão de sim ou não, como “Este tumer é canceroso?”, “Este cookie atende aos nossos padrões de qualidade?” e assim por diante.
Como se vê, a teoria subjacente do Machine Learning é mais ou menos a mesma. As principais diferenças são o design do preditor h(x) e o design da função de custo .
Nossos exemplos até agora se concentraram em problemas de regressão, então vamos agora também dar uma olhada em um exemplo de classificação.
Aqui estão os resultados de um estudo de teste de qualidade de cookies, onde todos os exemplos de treinamento foram rotulados como “bom cookie” ( y = 1 ) em azul ou “bad cookie” ( y = 0 ) em vermelho.
Na classificação, um preditor de regressão não é muito útil. O que geralmente queremos é um preditor que faça uma estimativa entre 0 e 1. Em um classificador de qualidade de biscoito, uma previsão de 1 representaria um palpite muito confiante de que o biscoito é perfeito e totalmente de dar água na boca. Uma previsão de 0 representa alta confiança de que o cookie é um embaraço para a indústria de cookies. Os valores que se enquadram nesse intervalo representam menos confiança, portanto, podemos projetar nosso sistema de modo que a previsão de 0,6 signifique "Cara, essa é uma decisão difícil, mas vou dizer sim, você pode vender esse biscoito", enquanto um valor exatamente em o meio, em 0,5, pode representar incerteza completa. Nem sempre é assim que a confiança é distribuída em um classificador, mas é um design muito comum e funciona para os propósitos de nossa ilustração.
Acontece que há uma boa função que captura bem esse comportamento. É chamada de função sigmoid, g(z) , e se parece com isso:
z é alguma representação de nossas entradas e coeficientes, como:
para que nosso preditor se torne:
Observe que a função sigmóide transforma nossa saída no intervalo entre 0 e 1.
A lógica por trás do design da função de custo também é diferente na classificação. Novamente perguntamos “o que significa uma suposição estar errada?” e desta vez uma regra muito boa é que se o palpite correto foi 0 e nós adivinhamos 1, então estávamos completamente e totalmente errados, e vice-versa. Como você não pode estar mais errado do que absolutamente errado, a penalidade neste caso é enorme. Alternativamente, se a estimativa correta for 0 e nós adivinharmos 0, nossa função de custo não deve adicionar nenhum custo para cada vez que isso acontecer. Se o palpite estivesse certo, mas não estivéssemos completamente confiantes (por exemplo, y = 1 , mas h(x) = 0.8 ), isso deveria vir com um pequeno custo, e se nosso palpite estivesse errado, mas não estivéssemos completamente confiantes ( por exemplo, y = 1 mas h(x) = 0.3 ), isso deve vir com algum custo significativo, mas não tanto quanto se estivéssemos completamente errados.
Esse comportamento é capturado pela função de log, de modo que:
Novamente, a função custo nos dá o custo médio de todos os nossos exemplos de treinamento.
Então aqui descrevemos como o preditor h(x) e a função de custo diferem entre regressão e classificação, mas o gradiente descendente ainda funciona bem.
Um preditor de classificação pode ser visualizado desenhando a linha de fronteira; ou seja, a barreira onde a previsão muda de um “sim” (uma previsão maior que 0,5) para um “não” (uma previsão menor que 0,5). Com um sistema bem projetado, nossos dados de cookies podem gerar um limite de classificação semelhante a este:
Agora que é uma máquina que sabe uma coisa ou duas sobre cookies!
Uma introdução às redes neurais
Nenhuma discussão sobre Machine Learning estaria completa sem pelo menos mencionar as redes neurais. As redes neurais não apenas oferecem uma ferramenta extremamente poderosa para resolver problemas muito difíceis, mas também oferecem dicas fascinantes sobre o funcionamento de nossos próprios cérebros e possibilidades intrigantes para um dia criar máquinas verdadeiramente inteligentes.
As redes neurais são adequadas para modelos de aprendizado de máquina onde o número de entradas é gigantesco. O custo computacional de lidar com esse problema é muito grande para os tipos de sistemas que discutimos acima. Como se vê, no entanto, as redes neurais podem ser ajustadas de forma eficaz usando técnicas que são surpreendentemente semelhantes ao gradiente descendente em princípio.
Uma discussão completa sobre redes neurais está além do escopo deste tutorial, mas recomendo conferir nosso post anterior sobre o assunto.
Aprendizado de máquina não supervisionado
O aprendizado de máquina não supervisionado geralmente é encarregado de encontrar relacionamentos nos dados. Não há exemplos de treinamento usados neste processo. Em vez disso, o sistema recebe um conjunto de dados e é encarregado de encontrar padrões e correlações neles. Um bom exemplo é identificar grupos de amigos unidos em dados de redes sociais.
Os algoritmos de Machine Learning usados para fazer isso são muito diferentes daqueles usados para aprendizado supervisionado, e o tópico merece um post próprio. No entanto, para algo para mastigar nesse meio tempo, dê uma olhada em algoritmos de agrupamento, como k-means, e também observe sistemas de redução de dimensionalidade, como análise de componentes principais. Nosso post anterior sobre big data discute vários desses tópicos com mais detalhes também.
Conclusão
Cobrimos grande parte da teoria básica subjacente ao campo de Aprendizado de Máquina aqui, mas é claro que mal arranhamos a superfície.
Lembre-se de que, para realmente aplicar as teorias contidas nesta introdução a exemplos de aprendizado de máquina da vida real, é necessária uma compreensão muito mais profunda dos tópicos discutidos aqui. Existem muitas sutilezas e armadilhas no ML, e muitas maneiras de se desviar pelo que parece ser uma máquina de pensamento perfeitamente bem afinada. Quase todas as partes da teoria básica podem ser manipuladas e alteradas infinitamente, e os resultados são frequentemente fascinantes. Muitos crescem em novos campos de estudo que são mais adequados para problemas específicos.
Claramente, o Machine Learning é uma ferramenta incrivelmente poderosa. Nos próximos anos, promete ajudar a resolver alguns de nossos problemas mais prementes, além de abrir novos mundos de oportunidades para empresas de ciência de dados. A demanda por engenheiros de Machine Learning continuará crescendo, oferecendo chances incríveis de fazer parte de algo grande. Espero que você considere entrar em ação!
Reconhecimento
Este artigo baseia-se fortemente no material ensinado pelo professor de Stanford Dr. Andrew Ng em seu curso de aprendizado de máquina gratuito e aberto. O curso abrange tudo o que foi discutido neste artigo em grande profundidade e oferece muitos conselhos práticos para o praticante de ML. Eu não posso recomendar este curso o suficiente para aqueles interessados em explorar mais este campo fascinante.
- Modelos de lógica sonora e IA monotônica
- Escolar Flappy Bird: Um Tutorial de Aprendizagem por Reforço