
机器学习理论及其应用简介:带有示例的可视化教程
已发表: 2022-03-11机器学习 (ML) 正在发挥作用,人们越来越认识到 ML 可以在广泛的关键应用中发挥关键作用,例如数据挖掘、自然语言处理、图像识别和专家系统。 ML 在所有这些领域以及更多领域提供潜在的解决方案,并将成为我们未来文明的支柱。
有能力的 ML 设计师的供应尚未赶上这一需求。 造成这种情况的一个主要原因是 ML 非常棘手。 本机器学习教程介绍了机器学习理论的基础知识,阐述了共同的主题和概念,使其易于遵循逻辑并熟悉机器学习基础知识。
什么是机器学习?
那么究竟什么是“机器学习”呢? ML实际上是很多东西。 该领域非常广阔并且正在迅速扩展,不断地被划分和子划分为不同的子专业和机器学习类型。
然而,有一些基本的共同点,最重要的主题是 Arthur Samuel 在 1959 年经常引用的一句话: “[机器学习是] 让计算机能够在没有被明确编程。”
最近,在 1997 年,Tom Mitchell 给出了一个“恰当的”定义,该定义已被证明对工程类型更有用: “一个计算机程序据说可以从经验 E 中学习一些任务 T 和一些性能度量 P,如果它在 T 上的表现,以 P 衡量,随着经验 E 而提高。”
因此,如果您希望您的程序预测,例如,繁忙路口的交通模式(任务 T),您可以通过机器学习算法运行它,其中包含有关过去交通模式的数据(经验 E),如果它成功“学习”,然后它将在预测未来的流量模式(性能测量 P)方面做得更好。
然而,许多现实世界问题的高度复杂性通常意味着发明专门的算法来每次都能完美地解决它们是不切实际的,如果不是不可能的话。 机器学习问题的例子包括,“这是癌症吗?”,“这所房子的市场价值是多少?”,“这些人中谁是彼此的好朋友?”,“这台火箭发动机起飞时会爆炸吗? ”、“这个人会喜欢这部电影吗?”、“这是谁?”、“你说什么?”和“你怎么飞这个东西?”。 所有这些问题都是 ML 项目的优秀目标,事实上 ML 已经成功地应用于每个问题。
在不同类型的 ML 任务中,有监督学习和无监督学习之间存在重要区别:
- 监督机器学习:该程序在一组预定义的“训练示例”上进行“训练”,然后在给定新数据时促进其得出准确结论的能力。
- 无监督机器学习:给程序一堆数据,必须在其中找到模式和关系。
我们将在这里主要关注监督学习,但文章的结尾包括对无监督学习的简要讨论,并为有兴趣进一步研究该主题的人提供了一些链接。
监督机器学习
在大多数监督学习应用中,最终目标是开发一个微调的预测函数h(x) (有时称为“假设”)。 “学习”包括使用复杂的数学算法来优化这个函数,这样,给定关于某个领域的输入数据x (比如,房子的平方英尺),它将准确地预测一些有趣的值h(x) (比如,市场价格对于所说的房子)。
在实践中, x几乎总是代表多个数据点。 因此,例如,房价预测器可能不仅需要平方英尺 ( x1 ),还需要卧室数量 ( x2 )、浴室数量 ( x3 )、楼层数 ( x4) 、建造年份 ( x5 )、邮政编码( x6 ) 等等。 确定使用哪些输入是 ML 设计的重要组成部分。 但是,为了便于解释,最容易假设使用单个输入值。
因此,假设我们的简单预测器具有以下形式:
在哪里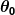 和
和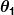 是常数。 我们的目标是找到完美的价值观和使我们的预测器尽可能好地工作。
是常数。 我们的目标是找到完美的价值观和使我们的预测器尽可能好地工作。
使用训练示例优化预测器h(x) 。 对于每个训练示例,我们都有一个输入值x_train ,其对应的输出y是事先已知的。 对于每个示例,我们找到已知的正确值y和我们的预测值h(x_train)之间的差异。 有了足够多的训练样本,这些差异为我们提供了一种衡量h(x)的“错误”的有用方法。 然后我们可以通过调整h(x)的值来调整和使其“少错”。 这个过程一遍又一遍地重复,直到系统收敛到最佳值和. 通过这种方式,预测器得到训练,并准备好进行一些现实世界的预测。
机器学习示例
为了说明,我们在这篇文章中坚持简单的问题,但 ML 存在的原因是因为在现实世界中,问题要复杂得多。 在这个平面屏幕上,我们最多可以为您绘制一张 3D 数据集的图片,但 ML 问题通常处理数百万维的数据和非常复杂的预测函数。 ML 解决了仅靠数值方法无法解决的问题。
考虑到这一点,让我们看一个简单的例子。 假设我们有以下培训数据,其中公司员工对他们的满意度评分为 1 到 100:
首先,请注意数据有点嘈杂。 也就是说,虽然我们可以看到它有一个规律(即员工的满意度往往会随着工资的上涨而上升),但它并不完全符合一条直线。 现实世界的数据总是如此(我们绝对希望使用现实世界的数据来训练我们的机器!)。 那么我们如何训练机器完美预测员工的满意度呢? 答案当然是我们不能。 ML 的目标绝不是做出“完美”的猜测,因为 ML 处理的领域是不存在这样的事情的。 目标是做出足够有用的猜测。
这有点让人想起英国数学家和统计学教授 George EP Box 的名言“所有模型都是错误的,但有些是有用的”。
机器学习在很大程度上建立在统计数据之上。 例如,当我们训练我们的机器进行学习时,我们必须给它一个统计上显着的随机样本作为训练数据。 如果训练集不是随机的,我们就会冒着机器学习模式实际上并不存在的风险。 如果训练集太小(参见大数定律),我们将无法学习到足够的知识,甚至可能得出不准确的结论。 例如,试图仅根据来自高层管理人员的数据来预测公司范围内的满意度模式很可能容易出错。
有了这种理解,让我们给我们的机器上面给出的数据并让它学习它。 首先,我们必须用一些合理的值初始化我们的预测器h(x) 和. 现在我们的预测器在我们的训练集上看起来像这样:
如果我们问这个预测器对收入 6 万美元的员工的满意度,它会预测评分为 27:
很明显,这是一个可怕的猜测,而且这台机器知道的并不多。
所以现在,让我们给这个预测器我们训练集中的所有薪水,并计算得到的预测满意度评分与相应员工的实际满意度评分之间的差异。 如果我们执行一点数学魔法(我将很快描述),我们可以非常确定地计算出 13.12 的值和 0.61 将为我们提供更好的预测器。
如果我们重复这个过程,比如 1500 次,我们的预测器最终会看起来像这样:
此时,如果我们重复这个过程,我们会发现和不会再有任何明显的变化,因此我们看到系统已经收敛。 如果我们没有犯任何错误,这意味着我们已经找到了最佳预测器。 因此,如果我们现在再次询问机器对年收入 6 万美元的员工的满意度,它预测的满意度大约为 60。
现在我们正在取得进展。
机器学习回归:关于复杂性的说明
上面的例子在技术上是一个简单的单变量线性回归问题,实际上可以通过推导一个简单的正规方程并完全跳过这个“调整”过程来解决。 但是,考虑一个如下所示的预测器:
该函数接受四个维度的输入,并具有多种多项式项。 推导该函数的正规方程是一项重大挑战。 许多现代机器学习问题需要数千甚至数百万维数据来构建使用数百个系数的预测。 预测一个有机体的基因组将如何表达,或者五十年后的气候会是什么样子,就是这类复杂问题的例子。
幸运的是,面对这种复杂性,ML 系统采用的迭代方法更具弹性。 机器学习系统不是使用蛮力,而是“摸索”到答案。 对于大问题,这会更好。 虽然这并不意味着 ML 可以解决所有任意复杂的问题(它不能),但它确实是一个非常灵活和强大的工具。
梯度下降——最小化“错误”
让我们仔细看看这个迭代过程是如何工作的。 在上面的例子中,我们如何确保和每一步都在变得更好,而不是更糟? 答案在于我们前面提到的“错误的衡量”,以及一些微积分。
错误度量被称为成本函数(又名损失函数),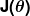 . 输入
. 输入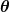 表示我们在预测器中使用的所有系数。 所以在我们的例子中, 真的是一对和.
表示我们在预测器中使用的所有系数。 所以在我们的例子中, 真的是一对和.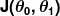 给我们一个数学测量,当它使用给定的值时,我们的预测器是多么错误和.
给我们一个数学测量,当它使用给定的值时,我们的预测器是多么错误和.

成本函数的选择是 ML 程序的另一个重要部分。 在不同的情况下,“错误”可能意味着非常不同的事情。 在我们的员工满意度示例中,公认的标准是线性最小二乘函数:
使用最小二乘法,错误猜测的惩罚随着猜测和正确答案之间的差异呈二次方上升,因此它可以作为一种非常“严格”的错误度量。 成本函数计算所有训练示例的平均惩罚。
所以现在我们看到我们的目标是找到和对于我们的预测器h(x)使得我们的成本函数尽可能小。 我们呼吁微积分的力量来实现这一点。
考虑以下某些特定机器学习问题的成本函数图:
在这里,我们可以看到与不同值相关的成本和. 我们可以看到该图的形状有一个轻微的碗状。 碗的底部代表我们的预测器根据给定的训练数据可以给我们的最低成本。 目标是“滚下山”,找到和对应于这一点。
这就是微积分进入本机器学习教程的地方。 为了使这个解释易于理解,我不会在这里写出方程式,但基本上我们所做的是取梯度,它是的导数对(一个以上还有一个)。 对于每个不同的值,梯度会有所不同和,并告诉我们“山坡是什么”,尤其是“哪条路向下”,因为这些特殊的s。 例如,当我们插入我们的当前值时进入渐变,它可能会告诉我们,添加一点并从中减去一点将把我们带到成本函数谷底的方向。 因此,我们加一点, 并减去一点,瞧! 我们已经完成了一轮学习算法。 我们更新的预测器,h(x) = + x,将返回比以前更好的预测。 我们的机器现在更智能了。
这个在计算当前梯度和更新梯度之间交替的过程结果中的 s 称为梯度下降。
这涵盖了大多数监督机器学习系统的基本理论。 但是,根据手头的问题,可以以多种不同的方式应用基本概念。
机器学习中的分类问题
在有监督的 ML 下,两个主要的子类别是:
- 回归机器学习系统:被预测的值落在连续范围内某处的系统。 这些系统帮助我们解决“多少钱?”的问题。 或“有多少?”。
- 分类机器学习系统:我们寻求是或否预测的系统,例如“这个肿瘤是否癌变?”、“这个 cookie 符合我们的质量标准吗?”等等。
事实证明,基本的机器学习理论或多或少是相同的。 主要区别在于预测器h(x)的设计和成本函数的设计.
到目前为止,我们的示例都集中在回归问题上,所以现在让我们来看看一个分类示例。
这是 cookie 质量测试研究的结果,其中所有训练示例都被标记为蓝色的“好 cookie”( y = 1 )或红色的“坏 cookie”( y = 0 )。
在分类中,回归预测器不是很有用。 我们通常想要的是一个在 0 和 1 之间进行猜测的预测器。在 cookie 质量分类器中,预测为 1 表示非常有把握地猜测 cookie 是完美的并且完全令人垂涎三尺。 预测值为 0 表示高度相信 cookie 对 cookie 行业来说是一种尴尬。 落在这个范围内的值代表较低的信心,所以我们可以设计我们的系统,使 0.6 的预测意味着“伙计,这是一个艰难的决定,但我会同意,你可以卖掉那个 cookie”,而一个值正好在中间的 0.5 可能代表完全的不确定性。 这并不总是分类器中置信度的分布方式,但它是一种非常常见的设计,并且可以用于我们的说明。
事实证明,有一个很好的函数可以很好地捕捉到这种行为。 它被称为 sigmoid 函数g(z) ,它看起来像这样:
z是我们的输入和系数的一些表示,例如:
这样我们的预测器就变成了:
请注意,sigmoid 函数将我们的输出转换为 0 到 1 之间的范围。
成本函数设计背后的逻辑在分类上也有所不同。 我们再次问“猜测错误是什么意思?” 这一次,一个非常好的经验法则是,如果正确的猜测是 0 而我们猜测的是 1,那么我们就完全完全错误,反之亦然。 既然你错得比绝对错还大,那么在这种情况下的惩罚是巨大的。 或者,如果正确的猜测是 0 而我们猜测的是 0,那么我们的成本函数不应该为每次发生这种情况添加任何成本。 如果猜测是正确的,但我们并不完全有信心(例如y = 1 ,但h(x) = 0.8 ),这应该会带来很小的成本,如果我们的猜测是错误的,但我们并不完全有信心(例如y = 1但h(x) = 0.3 ),这应该会带来一些显着的成本,但不会像我们完全错误的那样多。
此行为由 log 函数捕获,例如:
再次,成本函数为我们提供了所有训练示例的平均成本。
所以在这里我们已经描述了预测器h(x)和成本函数回归和分类之间有所不同,但梯度下降仍然可以正常工作。
可以通过绘制边界线来可视化分类预测器; 即,预测从“是”(预测大于 0.5)变为“否”(预测小于 0.5)的障碍。 通过精心设计的系统,我们的 cookie 数据可以生成如下所示的分类边界:
现在这是一台对 cookie 了解一两件事的机器!
神经网络简介
如果不至少提及神经网络,对机器学习的讨论是不完整的。 神经网络不仅为解决非常棘手的问题提供了一种极其强大的工具,而且还为我们自己的大脑工作提供了迷人的提示,以及有朝一日创造真正智能机器的有趣可能性。
神经网络非常适合输入数量巨大的机器学习模型。 对于我们上面讨论的系统类型来说,处理这样一个问题的计算成本太高了。 然而,事实证明,可以使用原则上与梯度下降非常相似的技术来有效地调整神经网络。
对神经网络的全面讨论超出了本教程的范围,但我建议您查看我们之前关于该主题的帖子。
无监督机器学习
无监督机器学习的任务通常是寻找数据中的关系。 此过程中没有使用任何训练示例。 取而代之的是,系统被赋予一组数据,并负责寻找其中的模式和相关性。 一个很好的例子是识别社交网络数据中关系密切的朋友群体。
用于执行此操作的机器学习算法与用于监督学习的算法非常不同,该主题值得单独发表。 但是,与此同时,如果想了解一些东西,请查看聚类算法,例如 k-means,并查看降维系统,例如主成分分析。 我们之前关于大数据的文章也更详细地讨论了其中一些主题。
结论
我们已经在这里介绍了机器学习领域的大部分基本理论,但当然,我们只触及了皮毛。
请记住,要将本简介中包含的理论真正应用于现实生活中的机器学习示例,需要对本文讨论的主题有更深入的理解。 ML 中存在许多微妙之处和陷阱,并且有许多方式会被看似完美调整的思维机器引入歧途。 基本理论的几乎每个部分都可以无休止地玩弄和修改,结果往往令人着迷。 许多人成长为更适合特定问题的全新研究领域。
显然,机器学习是一个非常强大的工具。 在未来几年,它有望帮助解决我们最紧迫的一些问题,并为数据科学公司开辟全新的机会世界。 对机器学习工程师的需求只会继续增长,为成为大事的一部分提供了难以置信的机会。 我希望你会考虑加入行动!
致谢
本文大量借鉴了斯坦福教授吴恩达博士在他的免费开放机器学习课程中教授的材料。 该课程深入涵盖了本文中讨论的所有内容,并为 ML 从业者提供了大量实用建议。 对于那些有兴趣进一步探索这个迷人领域的人,我不能高度推荐这门课程。
- 健全的逻辑和单调的 AI 模型
- Schooling Flappy Bird:强化学习教程