
Pengantar Teori Pembelajaran Mesin dan Aplikasinya: Tutorial Visual dengan Contoh
Diterbitkan: 2022-03-11Machine Learning (ML) hadir dengan sendirinya, dengan pengakuan yang berkembang bahwa ML dapat memainkan peran kunci dalam berbagai aplikasi penting, seperti penambangan data, pemrosesan bahasa alami, pengenalan gambar, dan sistem pakar. ML menyediakan solusi potensial di semua domain ini dan banyak lagi, dan akan menjadi pilar peradaban masa depan kita.
Pasokan desainer ML yang cakap belum dapat memenuhi permintaan ini. Alasan utama untuk ini adalah bahwa ML benar-benar rumit. Tutorial Pembelajaran Mesin ini memperkenalkan dasar-dasar teori ML, meletakkan tema dan konsep umum, membuatnya mudah untuk mengikuti logika dan merasa nyaman dengan dasar-dasar pembelajaran mesin.
Apa itu Pembelajaran Mesin?
Jadi apa sebenarnya "pembelajaran mesin" itu? ML sebenarnya banyak hal. Bidangnya cukup luas dan berkembang pesat, terus-menerus dipartisi dan disub-partisi menjadi sub-spesialisasi dan jenis pembelajaran mesin yang berbeda.
Ada beberapa benang merah dasar, bagaimanapun, dan tema menyeluruh paling baik diringkas oleh pernyataan yang sering dikutip yang dibuat oleh Arthur Samuel pada tahun 1959: “[Pembelajaran Mesin adalah] bidang studi yang memberi komputer kemampuan untuk belajar tanpa diprogram secara eksplisit.”
Dan baru-baru ini, pada tahun 1997, Tom Mitchell memberikan definisi "berpose dengan baik" yang telah terbukti lebih berguna untuk tipe rekayasa: "Sebuah program komputer dikatakan belajar dari pengalaman E sehubungan dengan beberapa tugas T dan beberapa ukuran kinerja P, jika kinerjanya pada T, yang diukur dengan P, meningkat dengan pengalaman E.”
Jadi jika Anda ingin program Anda memprediksi, misalnya, pola lalu lintas di persimpangan yang sibuk (tugas T), Anda dapat menjalankannya melalui algoritme pembelajaran mesin dengan data tentang pola lalu lintas masa lalu (pengalaman E) dan, jika berhasil "dipelajari ”, kemudian akan lebih baik dalam memprediksi pola lalu lintas di masa mendatang (ukuran kinerja P).
Sifat yang sangat kompleks dari banyak masalah dunia nyata, bagaimanapun, sering berarti bahwa menciptakan algoritma khusus yang akan menyelesaikannya dengan sempurna setiap saat tidak praktis, jika bukan tidak mungkin. Contoh masalah pembelajaran mesin termasuk, "Apakah ini kanker?", "Berapa nilai pasar rumah ini?", "Siapa di antara orang-orang ini yang berteman baik satu sama lain?", "Apakah mesin roket ini akan meledak saat lepas landas? ”, “Apakah orang ini akan menyukai film ini?”, “Siapa ini?”, “Apa yang Anda katakan?”, dan “Bagaimana Anda menerbangkan benda ini?”. Semua masalah ini adalah target yang sangat baik untuk sebuah proyek ML, dan sebenarnya ML telah diterapkan pada masing-masing dari mereka dengan sukses besar.
Di antara berbagai jenis tugas ML, ada perbedaan penting antara pembelajaran yang diawasi dan tidak diawasi:
- Pembelajaran mesin yang diawasi: Program ini "dilatih" pada serangkaian "contoh pelatihan" yang telah ditentukan sebelumnya, yang kemudian memfasilitasi kemampuannya untuk mencapai kesimpulan yang akurat saat diberikan data baru.
- Pembelajaran mesin tanpa pengawasan: Program ini diberikan banyak data dan harus menemukan pola dan hubungan di dalamnya.
Kami terutama akan fokus pada pembelajaran yang diawasi di sini, tetapi akhir artikel mencakup diskusi singkat tentang pembelajaran tanpa pengawasan dengan beberapa tautan untuk mereka yang tertarik untuk mengejar topik lebih lanjut.
Pembelajaran Mesin yang Diawasi
Di sebagian besar aplikasi pembelajaran yang diawasi, tujuan utamanya adalah untuk mengembangkan fungsi prediktor yang disetel dengan baik h(x) (kadang-kadang disebut "hipotesis"). “Belajar” terdiri dari penggunaan algoritme matematika canggih untuk mengoptimalkan fungsi ini sehingga, dengan memasukkan data x tentang domain tertentu (misalnya, luas persegi sebuah rumah), ia akan secara akurat memprediksi beberapa nilai menarik h(x) (misalnya, harga pasar untuk rumah tersebut).
Dalam praktiknya, x hampir selalu mewakili beberapa titik data. Jadi, misalnya, alat prediksi harga perumahan mungkin tidak hanya mengambil luas persegi ( x1 ) tetapi juga jumlah kamar tidur ( x2 ), jumlah kamar mandi ( x3 ), jumlah lantai ( x4) , tahun dibangun ( x5 ), kode pos ( x6 ), dan seterusnya. Menentukan input mana yang akan digunakan merupakan bagian penting dari desain ML. Namun, demi penjelasan, paling mudah untuk mengasumsikan nilai input tunggal digunakan.
Jadi katakanlah prediktor sederhana kami memiliki bentuk ini:
di mana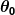 dan
dan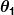 adalah konstanta. Tujuan kami adalah menemukan nilai sempurna dari dan untuk membuat prediktor kami bekerja sebaik mungkin.
adalah konstanta. Tujuan kami adalah menemukan nilai sempurna dari dan untuk membuat prediktor kami bekerja sebaik mungkin.
Mengoptimalkan prediktor h(x) dilakukan dengan menggunakan contoh pelatihan . Untuk setiap contoh pelatihan, kami memiliki nilai input x_train , di mana output yang sesuai, y , diketahui sebelumnya. Untuk setiap contoh, kami menemukan perbedaan antara nilai yang diketahui dan benar y , dan nilai prediksi kami h(x_train) . Dengan contoh pelatihan yang cukup, perbedaan ini memberi kita cara yang berguna untuk mengukur "kesalahan" dari h(x) . Kami kemudian dapat men-tweak h(x) dengan mengutak-atik nilai dan untuk membuatnya "kurang salah". Proses ini dilakukan berulang-ulang sampai sistem konvergen pada nilai terbaik untuk dan . Dengan cara ini, prediktor menjadi terlatih, dan siap untuk melakukan prediksi dunia nyata.
Contoh Pembelajaran Mesin
Kami berpegang pada masalah sederhana di posting ini demi ilustrasi, tetapi alasan ML ada adalah karena, di dunia nyata, masalahnya jauh lebih kompleks. Pada layar datar ini, kami dapat menggambar Anda, paling banyak, kumpulan data tiga dimensi, tetapi masalah ML biasanya berhubungan dengan data dengan jutaan dimensi, dan fungsi prediktor yang sangat kompleks. ML memecahkan masalah yang tidak dapat diselesaikan dengan cara numerik saja.
Dengan mengingat hal itu, mari kita lihat contoh sederhana. Katakanlah kita memiliki data pelatihan berikut, di mana karyawan perusahaan menilai kepuasan mereka pada skala 1 hingga 100:
Pertama, perhatikan bahwa datanya sedikit bising. Artinya, sementara kita dapat melihat bahwa ada polanya (yaitu kepuasan karyawan cenderung naik seiring dengan kenaikan gaji), tidak semuanya cocok dengan rapi pada garis lurus. Ini akan selalu terjadi dengan data dunia nyata (dan kami benar-benar ingin melatih mesin kami menggunakan data dunia nyata!). Jadi, bagaimana kita bisa melatih mesin untuk memprediksi tingkat kepuasan karyawan dengan sempurna? Jawabannya tentu saja kita tidak bisa. Tujuan ML bukanlah untuk membuat tebakan yang “sempurna”, karena ML berurusan dengan domain yang tidak ada hal seperti itu. Tujuannya adalah untuk membuat tebakan yang cukup bagus agar bermanfaat.
Ini agak mengingatkan pada pernyataan terkenal oleh matematikawan Inggris dan profesor statistik George EP Box bahwa "semua model salah, tetapi beberapa berguna".
Machine Learning sangat dibangun di atas statistik. Misalnya, ketika kita melatih mesin kita untuk belajar, kita harus memberikan sampel acak yang signifikan secara statistik sebagai data pelatihan. Jika set pelatihan tidak acak, kami menanggung risiko pola pembelajaran mesin yang sebenarnya tidak ada. Dan jika set pelatihan terlalu kecil (lihat hukum bilangan besar), kita tidak akan cukup belajar dan bahkan mungkin mencapai kesimpulan yang tidak akurat. Misalnya, mencoba memprediksi pola kepuasan seluruh perusahaan berdasarkan data dari manajemen tingkat atas saja kemungkinan besar akan rawan kesalahan.
Dengan pemahaman ini, mari berikan mesin kita data yang telah kita berikan di atas dan minta dia mempelajarinya. Pertama kita harus menginisialisasi prediktor h(x) dengan beberapa nilai wajar dari dan . Sekarang prediktor kami terlihat seperti ini ketika ditempatkan di atas set pelatihan kami:
Jika kita menanyakan prediktor ini untuk kepuasan seorang karyawan yang menghasilkan $60k, itu akan memprediksi peringkat 27:
Jelas bahwa ini adalah tebakan yang buruk dan mesin ini tidak tahu banyak.
Jadi sekarang, mari berikan prediksi ini semua gaji dari set pelatihan kami, dan ambil perbedaan antara peringkat kepuasan yang diprediksi dan peringkat kepuasan aktual dari karyawan terkait. Jika kita melakukan sedikit sihir matematika (yang akan saya jelaskan segera), kita dapat menghitung, dengan kepastian yang sangat tinggi, bahwa nilai 13,12 untuk dan 0,61 untuk akan memberi kita prediktor yang lebih baik.
Dan jika kita mengulangi proses ini, katakanlah 1500 kali, prediksi kita akan berakhir seperti ini:
Pada titik ini, jika kita mengulangi prosesnya, kita akan menemukan bahwa dan tidak akan berubah dengan jumlah yang cukup besar lagi dan dengan demikian kita melihat bahwa sistem telah konvergen. Jika kami tidak melakukan kesalahan, ini berarti kami telah menemukan prediktor yang optimal. Oleh karena itu, jika sekarang kita bertanya lagi kepada mesin untuk peringkat kepuasan karyawan yang menghasilkan $60k, mesin akan memprediksi peringkat sekitar 60.
Sekarang kita menuju suatu tempat.
Regresi Pembelajaran Mesin: Catatan tentang Kompleksitas
Contoh di atas secara teknis merupakan masalah sederhana dari regresi linier univariat, yang pada kenyataannya dapat diselesaikan dengan menurunkan persamaan normal sederhana dan melewatkan proses "penyetelan" ini sama sekali. Namun, pertimbangkan prediktor yang terlihat seperti ini:
Fungsi ini mengambil input dalam empat dimensi dan memiliki berbagai suku polinomial. Menurunkan persamaan normal untuk fungsi ini merupakan tantangan yang signifikan. Banyak masalah pembelajaran mesin modern membutuhkan ribuan atau bahkan jutaan dimensi data untuk membangun prediksi menggunakan ratusan koefisien. Memprediksi bagaimana genom suatu organisme akan diekspresikan, atau seperti apa iklim dalam lima puluh tahun, adalah contoh dari masalah kompleks tersebut.
Untungnya, pendekatan berulang yang diambil oleh sistem ML jauh lebih tangguh dalam menghadapi kompleksitas seperti itu. Alih-alih menggunakan kekerasan, sistem pembelajaran mesin “merasakan jalannya” untuk menjawabnya. Untuk masalah besar, ini bekerja jauh lebih baik. Meskipun ini tidak berarti bahwa ML dapat menyelesaikan semua masalah kompleks yang sewenang-wenang (tidak bisa), ML memang menjadi alat yang sangat fleksibel dan kuat.
Gradient Descent - Meminimalkan “Kesalahan”
Mari kita lihat lebih dekat bagaimana proses berulang ini bekerja. Dalam contoh di atas, bagaimana kita memastikan dan semakin baik dengan setiap langkah, dan tidak lebih buruk? Jawabannya terletak pada "pengukuran kesalahan" kami yang disinggung sebelumnya, bersama dengan sedikit kalkulus.

Ukuran kesalahan dikenal sebagai fungsi biaya (alias, fungsi kerugian ),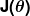 . masukan
. masukan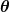 mewakili semua koefisien yang kami gunakan dalam prediktor kami. Jadi dalam kasus kami, benar-benar pasangan dan .
mewakili semua koefisien yang kami gunakan dalam prediktor kami. Jadi dalam kasus kami, benar-benar pasangan dan .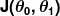 memberi kita pengukuran matematis tentang seberapa salah prediktor kita ketika menggunakan nilai yang diberikan dari dan .
memberi kita pengukuran matematis tentang seberapa salah prediktor kita ketika menggunakan nilai yang diberikan dari dan .
Pilihan fungsi biaya adalah bagian penting lain dari program ML. Dalam konteks yang berbeda, menjadi "salah" dapat berarti hal yang sangat berbeda. Dalam contoh kepuasan karyawan kami, standar mapan adalah fungsi kuadrat terkecil linier:
Dengan kuadrat terkecil, hukuman untuk tebakan buruk naik secara kuadrat dengan perbedaan antara tebakan dan jawaban yang benar, jadi ini bertindak sebagai pengukuran kesalahan yang sangat "ketat". Fungsi biaya menghitung penalti rata-rata atas semua contoh pelatihan.
Jadi sekarang kita melihat bahwa tujuan kita adalah menemukan dan untuk prediktor kami h(x) sedemikian rupa sehingga fungsi biaya kami adalah sekecil mungkin. Kami menyerukan kekuatan kalkulus untuk mencapai hal ini.
Pertimbangkan plot fungsi biaya berikut untuk beberapa masalah Pembelajaran Mesin tertentu:
Di sini kita dapat melihat biaya yang terkait dengan nilai yang berbeda dari dan . Kita bisa melihat grafik memiliki sedikit mangkuk dengan bentuknya. Bagian bawah mangkuk mewakili biaya terendah yang dapat diberikan oleh prediktor kami berdasarkan data pelatihan yang diberikan. Tujuannya adalah untuk "berguling menuruni bukit", dan menemukan dan sesuai dengan titik ini.
Di sinilah kalkulus masuk ke tutorial pembelajaran mesin ini. Demi menjaga agar penjelasan ini dapat dikelola, saya tidak akan menuliskan persamaannya di sini, tetapi pada dasarnya yang kita lakukan adalah mengambil gradien dari , yang merupakan pasangan turunan dari (satu selesai dan satu berakhir ). Gradien akan berbeda untuk setiap nilai yang berbeda dari dan , dan memberi tahu kita apa "lereng bukit itu" dan, khususnya, "jalan mana yang turun", untuk ini S. Misalnya, ketika kita memasukkan nilai kita saat ini dari ke dalam gradien, itu mungkin memberi tahu kita bahwa menambahkan sedikit ke dan mengurangi sedikit dari akan membawa kita ke arah lantai lembah fungsi biaya. Oleh karena itu, kami menambahkan sedikit ke , dan kurangi sedikit dari , dan voila! Kami telah menyelesaikan satu putaran algoritma pembelajaran kami. Prediktor kami yang diperbarui, h(x) = + x, akan mengembalikan prediksi yang lebih baik dari sebelumnya. Mesin kami sekarang sedikit lebih pintar.
Proses bergantian antara menghitung gradien saat ini, dan memperbarui s dari hasil, dikenal sebagai penurunan gradien.
Itu mencakup teori dasar yang mendasari sebagian besar sistem Pembelajaran Mesin yang diawasi. Tetapi konsep dasar dapat diterapkan dalam berbagai cara yang berbeda, tergantung pada masalah yang dihadapi.
Masalah Klasifikasi dalam Pembelajaran Mesin
Di bawah ML yang diawasi, dua subkategori utama adalah:
- Sistem pembelajaran mesin regresi: Sistem di mana nilai yang diprediksi jatuh di suatu tempat pada spektrum berkelanjutan. Sistem ini membantu kita dengan pertanyaan “Berapa banyak?” atau “Berapa?”.
- Sistem pembelajaran mesin klasifikasi: Sistem di mana kami mencari prediksi ya atau tidak, seperti "Apakah tumor ini bersifat kanker?", "Apakah cookie ini memenuhi standar kualitas kami?", dan seterusnya.
Ternyata, teori Machine Learning yang mendasarinya kurang lebih sama. Perbedaan utama adalah desain prediktor h(x) dan desain fungsi biaya .
Contoh kita sejauh ini berfokus pada masalah regresi, jadi sekarang mari kita lihat juga contoh klasifikasi.
Berikut adalah hasil studi pengujian kualitas cookie, di mana semua contoh pelatihan telah diberi label sebagai “kue yang baik” ( y = 1 ) dengan warna biru atau “kue buruk” ( y = 0 ) dengan warna merah.
Dalam klasifikasi, prediktor regresi tidak terlalu berguna. Yang biasanya kita inginkan adalah prediktor yang membuat tebakan antara 0 dan 1. Dalam pengklasifikasi kualitas kue, prediksi 1 akan mewakili tebakan yang sangat yakin bahwa kue itu sempurna dan benar-benar menggugah selera. Prediksi 0 menunjukkan keyakinan tinggi bahwa cookie merupakan hal yang memalukan bagi industri cookie. Nilai yang berada dalam kisaran ini menunjukkan kepercayaan yang lebih rendah, jadi kami mungkin merancang sistem kami sedemikian rupa sehingga prediksi 0,6 berarti "Wah, itu panggilan yang sulit, tapi saya akan setuju, Anda bisa menjual cookie itu," sementara nilai persis di tengah, pada 0,5, mungkin mewakili ketidakpastian lengkap. Ini tidak selalu bagaimana kepercayaan didistribusikan dalam pengklasifikasi tetapi ini adalah desain yang sangat umum dan berfungsi untuk tujuan ilustrasi kami.
Ternyata ada fungsi bagus yang menangkap perilaku ini dengan baik. Ini disebut fungsi sigmoid, g(z) , dan terlihat seperti ini:
z adalah beberapa representasi dari input dan koefisien kami, seperti:
sehingga prediktor kami menjadi:
Perhatikan bahwa fungsi sigmoid mengubah output kita menjadi rentang antara 0 dan 1.
Logika di balik desain fungsi biaya juga berbeda dalam klasifikasi. Sekali lagi kami bertanya "apa artinya tebakan salah?" dan kali ini aturan praktis yang sangat baik adalah jika tebakan yang benar adalah 0 dan kami menebak 1, maka kami sepenuhnya salah dan sebaliknya. Karena Anda tidak bisa lebih salah daripada benar-benar salah, hukuman dalam kasus ini sangat besar. Atau jika tebakan yang benar adalah 0 dan kami menebak 0, fungsi biaya kami seharusnya tidak menambahkan biaya apa pun untuk setiap kali hal ini terjadi. Jika tebakannya benar, tetapi kami tidak sepenuhnya yakin (mis. y = 1 , tetapi h(x) = 0.8 ), ini akan membutuhkan biaya yang kecil, dan jika tebakan kami salah tetapi kami tidak sepenuhnya yakin ( misalnya y = 1 tapi h(x) = 0.3 ), ini harus datang dengan beberapa biaya yang signifikan, tapi tidak sebanyak jika kita benar-benar salah.
Perilaku ini ditangkap oleh fungsi log, sehingga:
Sekali lagi, fungsi biaya memberi kami biaya rata-rata untuk semua contoh pelatihan kami.
Jadi di sini kami telah menjelaskan bagaimana prediktor h(x) dan fungsi biaya berbeda antara regresi dan klasifikasi, tetapi penurunan gradien masih berfungsi dengan baik.
Prediktor klasifikasi dapat divisualisasikan dengan menggambar garis batas; yaitu, penghalang di mana prediksi berubah dari "ya" (prediksi lebih besar dari 0,5) menjadi "tidak" (prediksi kurang dari 0,5). Dengan sistem yang dirancang dengan baik, data cookie kami dapat menghasilkan batas klasifikasi yang terlihat seperti ini:
Nah, itu adalah mesin yang tahu satu atau dua hal tentang cookie!
Pengantar Neural Network
Tidak ada diskusi tentang Pembelajaran Mesin yang akan lengkap tanpa setidaknya menyebutkan jaringan saraf. Jaringan saraf tidak hanya menawarkan alat yang sangat kuat untuk memecahkan masalah yang sangat sulit, tetapi juga menawarkan petunjuk menarik tentang cara kerja otak kita sendiri, dan kemungkinan menarik untuk suatu hari nanti menciptakan mesin yang benar-benar cerdas.
Jaringan saraf sangat cocok untuk model pembelajaran mesin di mana jumlah input sangat besar. Biaya komputasi untuk menangani masalah seperti itu terlalu besar untuk jenis sistem yang telah kita bahas di atas. Namun, ternyata, jaringan saraf dapat disetel secara efektif menggunakan teknik yang sangat mirip dengan penurunan gradien pada prinsipnya.
Diskusi menyeluruh tentang jaringan saraf berada di luar cakupan tutorial ini, tetapi saya sarankan untuk memeriksa posting kami sebelumnya tentang masalah ini.
Pembelajaran Mesin Tanpa Pengawasan
Pembelajaran mesin tanpa pengawasan biasanya ditugaskan untuk menemukan hubungan dalam data. Tidak ada contoh pelatihan yang digunakan dalam proses ini. Sebaliknya, sistem diberikan satu set data dan ditugaskan untuk menemukan pola dan korelasi di dalamnya. Contoh yang baik adalah mengidentifikasi kelompok teman dekat dalam data jejaring sosial.
Algoritme Pembelajaran Mesin yang digunakan untuk melakukan ini sangat berbeda dari yang digunakan untuk pembelajaran yang diawasi, dan topiknya sesuai dengan postingannya sendiri. Namun, untuk sesuatu untuk dikunyah sementara itu, lihatlah algoritma pengelompokan seperti k-means, dan juga lihat ke dalam sistem pengurangan dimensi seperti analisis komponen prinsip. Posting kami sebelumnya tentang data besar membahas sejumlah topik ini secara lebih rinci juga.
Kesimpulan
Kami telah membahas banyak teori dasar yang mendasari bidang Pembelajaran Mesin di sini, tetapi tentu saja, kami baru saja menggores permukaannya.
Ingatlah bahwa untuk benar-benar menerapkan teori yang terkandung dalam pengantar ini ke contoh pembelajaran mesin kehidupan nyata, pemahaman yang lebih mendalam tentang topik yang dibahas di sini diperlukan. Ada banyak seluk-beluk dan jebakan dalam ML, dan banyak cara untuk disesatkan oleh apa yang tampaknya merupakan mesin pemikiran yang disetel dengan sempurna. Hampir setiap bagian dari teori dasar dapat dimainkan dan diubah tanpa henti, dan hasilnya seringkali menarik. Banyak yang tumbuh menjadi bidang studi baru yang lebih cocok untuk masalah tertentu.
Jelas, Machine Learning adalah alat yang sangat kuat. Di tahun-tahun mendatang, ia berjanji untuk membantu memecahkan beberapa masalah kami yang paling mendesak, serta membuka peluang dunia baru bagi perusahaan ilmu data. Permintaan untuk insinyur Pembelajaran Mesin hanya akan terus tumbuh, menawarkan peluang luar biasa untuk menjadi bagian dari sesuatu yang besar. Saya harap Anda akan mempertimbangkan untuk ikut serta dalam aksi!
Pengakuan
Artikel ini banyak mengambil materi yang diajarkan oleh Profesor Stanford Dr. Andrew Ng dalam kursus Pembelajaran Mesinnya yang gratis dan terbuka. Kursus ini mencakup semua yang dibahas dalam artikel ini secara mendalam, dan memberikan banyak saran praktis untuk praktisi ML. Saya tidak dapat merekomendasikan kursus ini cukup tinggi bagi mereka yang tertarik untuk menjelajahi lebih jauh bidang yang menarik ini.
- Logika Suara dan Model AI Monotonik
- Schooling Flappy Bird: Tutorial Pembelajaran Penguatan