
บทนำสู่ทฤษฎีแมชชีนเลิร์นนิงและการประยุกต์: การสอนด้วยภาพพร้อมตัวอย่าง
เผยแพร่แล้ว: 2022-03-11การเรียนรู้ของเครื่อง (ML) กำลังเข้ามามีบทบาทด้วยการรับรู้ที่เพิ่มขึ้นว่า ML สามารถมีบทบาทสำคัญในแอปพลิเคชันที่สำคัญมากมาย เช่น การทำเหมืองข้อมูล การประมวลผลภาษาธรรมชาติ การจดจำภาพ และระบบผู้เชี่ยวชาญ ML นำเสนอโซลูชั่นที่เป็นไปได้ในโดเมนทั้งหมดเหล่านี้และอื่นๆ อีกมากมาย และถูกกำหนดให้เป็นเสาหลักของอารยธรรมในอนาคตของเรา
อุปทานของนักออกแบบ ML ที่มีความสามารถยังไม่สามารถตอบสนองความต้องการนี้ได้ เหตุผลหลักสำหรับเรื่องนี้ก็คือ ML นั้นค่อนข้างยุ่งยาก บทช่วยสอนการเรียนรู้ของเครื่องนี้จะแนะนำพื้นฐานของทฤษฎี ML โดยวางธีมและแนวคิดทั่วไป ทำให้ง่ายต่อการปฏิบัติตามตรรกะ และทำความคุ้นเคยกับพื้นฐานของแมชชีนเลิร์นนิง
แมชชีนเลิร์นนิงคืออะไร?
แล้ว “แมชชีนเลิร์นนิง” คืออะไรกันแน่? ML มี หลาย สิ่งหลายอย่างจริงๆ สาขานี้ค่อนข้างกว้างใหญ่และกำลังขยายตัวอย่างรวดเร็ว โดยมีการแบ่งพาร์ติชั่นอย่างต่อเนื่องและแบ่งพาร์ติชั่นย่อยออกเป็นความเชี่ยวชาญย่อยที่แตกต่างกันและประเภทของการเรียนรู้ของเครื่อง
อย่างไรก็ตาม มีหัวข้อทั่วไปพื้นฐานอยู่บ้าง และหัวข้อที่ครอบคลุมนั้นสรุปได้ดีที่สุดโดยคำกล่าวที่อ้างถึงบ่อยๆ นี้โดย Arthur Samuel ย้อนกลับไปในปี 1959: “[Machine Learning is the] สาขาวิชาที่ทำให้คอมพิวเตอร์สามารถเรียนรู้ได้โดยไม่ต้อง ถูกตั้งโปรแกรมไว้อย่างชัดเจน”
และไม่นานมานี้ ในปี 1997 Tom Mitchell ได้ให้คำจำกัดความ "วางตัวดี" ซึ่งพิสูจน์แล้วว่ามีประโยชน์มากกว่าสำหรับประเภทวิศวกรรม: "มีการกล่าวถึงโปรแกรมคอมพิวเตอร์เพื่อเรียนรู้จากประสบการณ์ E เกี่ยวกับงานบางอย่าง T และการวัดประสิทธิภาพ P ถ้า ประสิทธิภาพของมันบน T ซึ่งวัดโดย P นั้นดีขึ้นด้วยประสบการณ์ E”
ดังนั้น หากคุณต้องการให้โปรแกรมของคุณทำนาย เช่น รูปแบบการรับส่งข้อมูลที่ทางแยกที่วุ่นวาย (งาน T) คุณสามารถเรียกใช้ผ่านอัลกอริธึมการเรียนรู้ของเครื่องด้วยข้อมูลเกี่ยวกับรูปแบบการรับส่งข้อมูลที่ผ่านมา (ประสบการณ์ E) และหาก "เรียนรู้สำเร็จ" ” จากนั้นจะคาดการณ์รูปแบบการเข้าชมในอนาคตได้ดีขึ้น (การวัดประสิทธิภาพ P)
แม้ว่าธรรมชาติของปัญหาในโลกแห่งความเป็นจริงจะซับซ้อนอย่างมาก มักจะหมายความว่าการประดิษฐ์อัลกอริธึมเฉพาะทางที่จะแก้ปัญหาเหล่านี้ได้อย่างสมบูรณ์แบบทุกครั้งนั้นเป็นไปไม่ได้ หากไม่สามารถทำได้ ตัวอย่างปัญหาของแมชชีนเลิร์นนิง ได้แก่ “นี่คือมะเร็งหรือเปล่า”, “บ้านหลังนี้มีมูลค่าตลาดเท่าไหร่”, “ใครในนี้เป็นเพื่อนที่ดีต่อกัน”, “เครื่องยนต์จรวดนี้จะระเบิดตอนบินขึ้นหรือไม่? "," คนนี้ชอบหนังเรื่องนี้ไหม ", "นี่ใคร?", "คุณพูดอะไร" และ "คุณบินสิ่งนี้ได้อย่างไร" ปัญหาทั้งหมดเหล่านี้เป็นเป้าหมายที่ยอดเยี่ยมสำหรับโครงการ ML และอันที่จริง ML ได้ถูกนำไปใช้กับแต่ละปัญหาด้วยความสำเร็จอย่างมาก
ในบรรดางาน ML ประเภทต่างๆ ความแตกต่างที่สำคัญระหว่างการเรียนรู้ภายใต้การดูแลและการเรียนรู้ที่ไม่ได้รับการดูแล:
- แมชชีนเลิร์นนิงภายใต้การดูแล: โปรแกรมได้รับการ "ฝึกฝน" ในชุด "ตัวอย่างการฝึกอบรม" ที่กำหนดไว้ล่วงหน้า ซึ่งช่วยให้สามารถบรรลุข้อสรุปที่ถูกต้องเมื่อได้รับข้อมูลใหม่
- แมชชีนเลิร์นนิงแบบไม่มีผู้ดูแล: โปรแกรมได้รับข้อมูลจำนวนมาก และต้องค้นหารูปแบบและความสัมพันธ์ในนั้น
เราจะเน้นที่การเรียนรู้ภายใต้การดูแลเป็นหลัก แต่ส่วนท้ายของบทความมีการอภิปรายสั้น ๆ เกี่ยวกับการเรียนรู้แบบไม่มีผู้ดูแลพร้อมลิงก์สำหรับผู้สนใจติดตามหัวข้อต่อไป
แมชชีนเลิร์นนิงภายใต้การดูแล
ในแอปพลิเคชันการเรียนรู้ภายใต้การดูแลส่วนใหญ่ เป้าหมายสูงสุดคือการพัฒนาฟังก์ชันตัวทำนายที่ปรับแต่งอย่างประณีต h(x) (บางครั้งเรียกว่า "สมมติฐาน") “การเรียนรู้” ประกอบด้วยการใช้อัลกอริธึมทางคณิตศาสตร์ที่ซับซ้อนเพื่อปรับฟังก์ชันนี้ให้เหมาะสม เพื่อให้ข้อมูลอินพุต x เกี่ยวกับโดเมนหนึ่งๆ (เช่น พื้นที่เป็นตารางฟุตของบ้าน) จะคาดการณ์มูลค่าที่น่าสนใจ h(x) ได้อย่างแม่นยำ (เช่น ราคาตลาด สำหรับบ้านดังกล่าว)
ในทางปฏิบัติ x มักจะแทนจุดข้อมูลหลายจุด ตัวอย่างเช่น ตัวทำนายราคาบ้านอาจใช้พื้นที่ไม่เพียงแค่ตารางฟุต ( x1 ) แต่ยังรวมถึงจำนวนห้องนอน ( x2 ) จำนวนห้องน้ำ ( x3 ) จำนวนชั้น ( x4) ปีที่สร้าง ( x5 ) รหัสไปรษณีย์ ( x6 ) และอื่นๆ การพิจารณาว่าจะใช้อินพุตใดเป็นส่วนสำคัญของการออกแบบ ML อย่างไรก็ตาม เพื่อเป็นการอธิบาย เป็นการง่ายที่สุดที่จะถือว่าใช้ค่าอินพุตเดียว
สมมุติว่าตัวทำนายอย่างง่ายของเรามีรูปแบบนี้:
ที่ไหน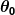 และ
และ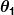 เป็นค่าคงที่ เป้าหมายของเราคือการค้นหาค่าที่สมบูรณ์แบบของ และ เพื่อให้ตัวทำนายของเราทำงานได้ดีที่สุด
เป็นค่าคงที่ เป้าหมายของเราคือการค้นหาค่าที่สมบูรณ์แบบของ และ เพื่อให้ตัวทำนายของเราทำงานได้ดีที่สุด
การเพิ่มประสิทธิภาพตัวทำนาย h(x) ทำได้โดยใช้ ตัวอย่างการฝึกอบรม สำหรับตัวอย่างการฝึกแต่ละครั้ง เรามีค่าอินพุต x_train ซึ่งทราบเอาต์พุตที่สอดคล้องกัน y ล่วงหน้า สำหรับแต่ละตัวอย่าง เราพบความแตกต่างระหว่างค่าที่ทราบ ค่าที่ถูกต้อง y และค่าที่คาดการณ์ไว้ h(x_train) ด้วยตัวอย่างการฝึกอบรมที่เพียงพอ ความแตกต่างเหล่านี้ทำให้เรามีวิธีที่มีประโยชน์ในการวัด "ความไม่ถูกต้อง" ของ h(x) จากนั้นเราสามารถปรับแต่ง h(x) โดยปรับแต่งค่าของ และ เพื่อให้มัน "ผิดพลาดน้อยลง" กระบวนการนี้ซ้ำแล้วซ้ำอีกจนกว่าระบบจะบรรจบกับค่าที่ดีที่สุดสำหรับ และ . ด้วยวิธีนี้ ผู้ทำนายจะได้รับการฝึกฝน และพร้อมที่จะทำการทำนายในโลกแห่งความเป็นจริง
ตัวอย่างการเรียนรู้ของเครื่อง
เรายึดติดอยู่กับปัญหาง่ายๆ ในโพสต์นี้เพื่อให้เห็นภาพ แต่เหตุผลที่ ML มีอยู่ก็เพราะในโลกแห่งความจริง ปัญหานั้นซับซ้อนกว่ามาก บนจอแบนนี้ เราสามารถวาดภาพของคุณ อย่างมากที่สุด ชุดข้อมูลสามมิติ แต่ปัญหา ML มักจะจัดการกับข้อมูลที่มีมิตินับล้าน และฟังก์ชันการทำนายที่ซับซ้อนมาก ML แก้ปัญหาที่ไม่สามารถแก้ไขได้ด้วยวิธีการทางตัวเลขเพียงอย่างเดียว
ลองมาดูตัวอย่างง่ายๆ สมมติว่าเรามีข้อมูลการฝึกอบรมต่อไปนี้ ซึ่งพนักงานของบริษัทได้ให้คะแนนความพึงพอใจในระดับ 1 ถึง 100:
ขั้นแรก สังเกตว่าข้อมูลมีสัญญาณรบกวนเล็กน้อย นั่นคือ ในขณะที่เราจะเห็นได้ว่ามีรูปแบบอยู่ (เช่น ความพึงพอใจของพนักงานมีแนวโน้มที่จะเพิ่มขึ้นเมื่อเงินเดือนสูงขึ้น) แต่ก็ไม่ได้สอดคล้องกันเป็นเส้นตรงทั้งหมด กรณีนี้มักจะเกิดขึ้นกับข้อมูลในโลกแห่งความเป็นจริง (และเราต้องการฝึกเครื่องของเราโดยใช้ข้อมูลในโลกแห่งความเป็นจริง!) แล้วเราจะฝึกเครื่องจักรเพื่อทำนายระดับความพึงพอใจของพนักงานได้อย่างไร แน่นอน คำตอบคือเราไม่สามารถ เป้าหมายของ ML ไม่ใช่การคาดเดาที่ "สมบูรณ์แบบ" เพราะ ML เกี่ยวข้องกับโดเมนที่ไม่มีสิ่งดังกล่าว เป้าหมายคือการคาดเดาที่ดีพอที่จะเป็นประโยชน์
ค่อนข้างชวนให้นึกถึงคำกล่าวที่มีชื่อเสียงของนักคณิตศาสตร์ชาวอังกฤษและศาสตราจารย์ด้านสถิติ George EP Box ที่ว่า “แบบจำลองทั้งหมดไม่ถูกต้อง แต่บางรุ่นก็มีประโยชน์”
แมชชีนเลิร์นนิงสร้างสถิติอย่างมาก ตัวอย่างเช่น เมื่อเราฝึกเครื่องจักรให้เรียนรู้ เราต้องสุ่มตัวอย่างที่มีนัยสำคัญทางสถิติให้เป็นข้อมูลการฝึก หากชุดการฝึกไม่สุ่มเสี่ยง เราจะเสี่ยงต่อรูปแบบการเรียนรู้ของเครื่องที่ไม่มีอยู่จริง และถ้าชุดการฝึกมีขนาดเล็กเกินไป (ดูกฎที่มีจำนวนมาก) เราจะไม่เรียนรู้เพียงพอและอาจถึงขั้นสรุปที่ไม่ถูกต้อง ตัวอย่างเช่น การพยายามคาดการณ์รูปแบบความพึงพอใจทั่วทั้งบริษัทโดยพิจารณาจากข้อมูลจากผู้บริหารระดับสูงเพียงอย่างเดียวอาจเกิดข้อผิดพลาดได้ง่าย
ด้วยความเข้าใจนี้ ให้เครื่องของเราได้รับข้อมูลที่เราได้รับข้างต้นและให้มันเรียนรู้ ก่อนอื่นเราต้องเริ่มต้นตัวทำนายของเรา h(x) ด้วยค่าที่เหมาะสมของ และ . ตอนนี้ตัวทำนายของเรามีลักษณะเช่นนี้เมื่อวางไว้เหนือชุดการฝึกของเรา:
หากเราขอให้พนักงานทำนายความพึงพอใจของพนักงานที่ทำเงินได้ 60,000 เหรียญสหรัฐ เครื่องจะทำนายคะแนนที่ 27:
เห็นได้ชัดว่านี่เป็นการเดาที่แย่มากและเครื่องนี้ไม่รู้อะไรมาก
ตอนนี้ ให้เงินเดือน ทั้งหมด จากชุดการฝึกอบรมของเรากับตัวทำนายนี้ และนำความแตกต่างระหว่างการให้คะแนนความพึงพอใจที่คาดการณ์ไว้กับคะแนนความพึงพอใจที่แท้จริงของพนักงานที่เกี่ยวข้องกัน หากเราแสดงมายากลทางคณิตศาสตร์เล็กน้อย (ซึ่งฉันจะอธิบายในเร็วๆ นี้) เราสามารถคำนวณค่า 13.12 นั้นได้ด้วยความแน่นอนที่สูงมาก และ 0.61 สำหรับ จะให้คำทำนายที่ดีกว่าแก่เรา
และถ้าเราทำซ้ำขั้นตอนนี้ เช่น 1500 ครั้ง ตัวทำนายของเราจะออกมาเป็นแบบนี้:
ณ จุดนี้ถ้าเราทำซ้ำขั้นตอนเราจะพบว่า และ จะไม่เปลี่ยนแปลงด้วยจำนวนที่เห็นได้อีกต่อไป ดังนั้นเราจึงเห็นว่าระบบได้บรรจบกัน หากเราไม่ได้ทำผิดพลาด แสดงว่าเราพบตัวทำนายที่เหมาะสมที่สุดแล้ว ดังนั้น หากตอนนี้เราถามเครื่องอีกครั้งสำหรับคะแนนความพึงพอใจของพนักงานที่ทำเงินได้ 60,000 เหรียญสหรัฐ เครื่องจะคาดการณ์คะแนนประมาณ 60
ตอนนี้เรากำลังจะไปที่ไหนสักแห่ง
การถดถอยของการเรียนรู้ของเครื่อง: หมายเหตุเกี่ยวกับความซับซ้อน
ตัวอย่างข้างต้นเป็นปัญหาง่ายๆ ในทางเทคนิคของการถดถอยเชิงเส้นแบบไม่แปรผัน ซึ่งในความเป็นจริงสามารถแก้ไขได้โดยการหาสมการธรรมดาอย่างง่ายแล้วข้ามกระบวนการ "ปรับ" นี้ไปโดยสิ้นเชิง อย่างไรก็ตาม ให้พิจารณาตัวทำนายที่มีลักษณะดังนี้:
ฟังก์ชันนี้รับอินพุตในสี่มิติและมีพจน์พหุนามที่หลากหลาย การหาสมการปกติสำหรับฟังก์ชันนี้เป็นความท้าทายที่สำคัญ ปัญหาแมชชีนเลิร์นนิงสมัยใหม่จำนวนมากใช้ข้อมูลหลายพันหรือหลายล้านมิติเพื่อสร้างการคาดคะเนโดยใช้ค่าสัมประสิทธิ์นับร้อย การคาดการณ์ว่าจีโนมของสิ่งมีชีวิตจะแสดงออกมาอย่างไร หรือสภาพอากาศจะเป็นอย่างไรในห้าสิบปี เป็นตัวอย่างของปัญหาที่ซับซ้อนดังกล่าว
โชคดีที่วิธีการวนซ้ำที่ใช้โดยระบบ ML มีความยืดหยุ่นมากกว่าเมื่อเผชิญกับความซับซ้อนดังกล่าว แทนที่จะใช้กำลังเดรัจฉาน ระบบการเรียนรู้ของเครื่องจะ “รู้สึกไปตามทาง” เพื่อหาคำตอบ สำหรับปัญหาใหญ่ วิธีนี้ได้ผลดีกว่ามาก แม้ว่าจะไม่ได้หมายความว่า ML สามารถแก้ปัญหาที่ซับซ้อนตามอำเภอใจได้ทั้งหมด (แต่ทำไม่ได้) แต่ก็ทำให้เครื่องมือมีความยืดหยุ่นและทรงพลังอย่างเหลือเชื่อ
Gradient Descent - ลด "ความผิด" ให้น้อยที่สุด
มาดูกันดีกว่าว่ากระบวนการวนซ้ำนี้ทำงานอย่างไร จากตัวอย่างข้างต้น เราจะแน่ใจได้อย่างไรว่า และ ดีขึ้นในแต่ละขั้นตอนและไม่แย่ลง? คำตอบอยู่ใน "การวัดความผิด" ที่เราเคยพูดพาดพิงถึงก่อนหน้านี้ พร้อมด้วยแคลคูลัสเล็กน้อย

การวัดความไม่ถูกต้องเรียกว่า ฟังก์ชันต้นทุน (aka, ฟังก์ชันการสูญเสีย )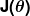 . อินพุต
. อินพุต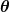 แสดงถึงสัมประสิทธิ์ทั้งหมดที่เราใช้ในตัวทำนายของเรา ดังนั้นในกรณีของเรา เป็นคู่แท้ และ .
แสดงถึงสัมประสิทธิ์ทั้งหมดที่เราใช้ในตัวทำนายของเรา ดังนั้นในกรณีของเรา เป็นคู่แท้ และ .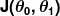 ให้การวัดทางคณิตศาสตร์แก่เราว่าตัวทำนายของเราผิดอย่างไรเมื่อใช้ค่าที่กำหนดของ และ .
ให้การวัดทางคณิตศาสตร์แก่เราว่าตัวทำนายของเราผิดอย่างไรเมื่อใช้ค่าที่กำหนดของ และ .
การเลือกฟังก์ชันต้นทุนเป็นอีกหนึ่งส่วนสำคัญของโปรแกรม ML ในบริบทที่แตกต่างกัน การ "ผิด" อาจหมายถึงสิ่งที่แตกต่างกันมาก ในตัวอย่างความพึงพอใจของพนักงาน มาตรฐานที่เป็นที่ยอมรับคือฟังก์ชันกำลังสองน้อยที่สุดเชิงเส้น:
หากมีกำลังสองน้อยที่สุด บทลงโทษสำหรับการเดาที่ไม่ถูกต้องจะเพิ่มขึ้นเป็นกำลังสองโดยมีความแตกต่างระหว่างการเดากับคำตอบที่ถูกต้อง ดังนั้นจึงทำหน้าที่เป็นการวัดความผิดพลาดที่ "เข้มงวดมาก" ฟังก์ชันต้นทุนคำนวณค่าปรับโดยเฉลี่ยจากตัวอย่างการฝึกอบรมทั้งหมด
ตอนนี้เราเห็นว่าเป้าหมายของเราคือการค้นหา และ สำหรับตัวทำนายของเรา h(x) เพื่อให้ฟังก์ชันต้นทุนของเรา มีขนาดเล็กที่สุด เราเรียกพลังของแคลคูลัสเพื่อทำสิ่งนี้ให้สำเร็จ
พิจารณาพล็อตฟังก์ชันต้นทุนต่อไปนี้สำหรับปัญหาการเรียนรู้ของเครื่องโดยเฉพาะ:
ที่นี่เราสามารถเห็นต้นทุนที่เกี่ยวข้องกับค่าต่างๆ ของ และ . เราจะเห็นว่ากราฟมีชามเล็กน้อยตามรูปร่างของมัน ด้านล่างของชามแสดงถึงต้นทุนที่ต่ำที่สุดที่ตัวทำนายของเราสามารถให้เราได้ตามข้อมูลการฝึกอบรมที่ให้มา เป้าหมายคือ "กลิ้งลงเขา" และค้นหา และ สอดคล้องกับจุดนี้
นี่คือที่มาของแคลคูลัสในบทช่วยสอนการเรียนรู้ของเครื่อง เพื่อให้คำอธิบายนี้สามารถจัดการได้ ฉันจะไม่เขียนสมการที่นี่ แต่โดยพื้นฐานแล้ว สิ่งที่เราทำคือใช้เกรเดียนต์ของ ซึ่งเป็นคู่ของอนุพันธ์ของ (หนึ่งมากกว่า และอีกอันหนึ่ง ). การไล่ระดับสีจะแตกต่างกันไปตามค่าต่างๆ ของ และ และบอกเราว่า “เนินลาดคืออะไร” และโดยเฉพาะอย่างยิ่ง “ทางลงทางไหน” สำหรับสิ่งเหล่านี้โดยเฉพาะ ส. ตัวอย่างเช่น เมื่อเราแทนค่าปัจจุบันของ ในการไล่ระดับก็อาจบอกเราได้ว่าการเติม to . เล็กน้อย และลบเล็กน้อยจาก จะพาเราไปในทิศทางของต้นทุนการทำงาน-พื้นหุบเขา เลยขอเสริมนิดนึง และลบเล็กน้อยจาก และ โว้ว! เราได้ทำอัลกอริธึมการเรียนรู้ของเราครบหนึ่งรอบแล้ว ตัวทำนายที่อัปเดตของเรา h(x) = + x จะแสดงผลการทำนายที่ดีขึ้นกว่าเดิม เครื่องของเราตอนนี้ฉลาดขึ้นเล็กน้อย
กระบวนการสลับระหว่างการคำนวณการไล่ระดับสีปัจจุบันและการอัปเดต s จากผลลัพธ์ เรียกว่า gradient descent
ซึ่งครอบคลุมทฤษฎีพื้นฐานที่เป็นพื้นฐานของระบบการเรียนรู้ของเครื่องส่วนใหญ่ภายใต้การดูแล แต่แนวคิดพื้นฐานสามารถนำไปใช้ได้หลากหลายวิธี ขึ้นอยู่กับปัญหาที่มีอยู่
ปัญหาการจำแนกประเภทในการเรียนรู้ของเครื่อง
ภายใต้ ML ภายใต้การดูแล สองหมวดหมู่ย่อยหลักคือ:
- ระบบการเรียนรู้ของเครื่องถดถอย: ระบบที่ค่าที่คาดการณ์ตกอยู่ที่ใดที่หนึ่งในสเปกตรัมที่ต่อเนื่องกัน ระบบเหล่านี้ช่วยให้เรามีคำถามว่า "เท่าไหร่" หรือ “เท่าไหร่?”
- ระบบการเรียนรู้ของเครื่องจำแนกประเภท: ระบบที่เราขอคำทำนายใช่หรือไม่ใช่ เช่น "เนื้องอกนี้เป็นมะเร็งหรือไม่", "คุกกี้นี้ตรงตามมาตรฐานคุณภาพของเราหรือไม่" เป็นต้น
ปรากฎว่าทฤษฎีการเรียนรู้ของเครื่องพื้นฐานมีความเหมือนกันไม่มากก็น้อย ความแตกต่างที่สำคัญคือการออกแบบตัวทำนาย h(x) และการออกแบบฟังก์ชันต้นทุน .
จนถึงตอนนี้ ตัวอย่างของเราเน้นไปที่ปัญหาการถดถอย ดังนั้น ตอนนี้เรามาดูตัวอย่างการจัดหมวดหมู่กัน
ต่อไปนี้คือผลการศึกษาการทดสอบคุณภาพคุกกี้ โดยตัวอย่างการฝึกอบรมทั้งหมดระบุว่า "คุกกี้ที่ดี" ( y = 1 ) เป็นสีน้ำเงินหรือ "คุกกี้ไม่ถูกต้อง" ( y = 0 ) เป็นสีแดง
ในการจำแนกประเภท ตัวทำนายการถดถอยไม่มีประโยชน์มากนัก สิ่งที่เรามักต้องการคือตัวทำนายที่คาดเดาระหว่าง 0 ถึง 1 ในตัวแยกประเภทคุณภาพคุกกี้ การคาดคะเน 1 จะแสดงถึงการเดาที่มั่นใจมากว่าคุกกี้นั้นสมบูรณ์แบบและน่ารับประทานอย่างยิ่ง การคาดคะเน 0 แสดงถึงความมั่นใจอย่างสูงว่าคุกกี้สร้างความอับอายให้กับอุตสาหกรรมคุกกี้ ค่าที่ตกอยู่ในช่วงนี้แสดงถึงความมั่นใจน้อยลง ดังนั้นเราจึงอาจออกแบบระบบของเราโดยที่การคาดคะเน 0.6 หมายถึง “ผู้ชาย นั่นเป็นการเรียกร้องที่ยาก แต่ฉันจะตอบว่า ใช่ คุณสามารถขายคุกกี้นั้นได้” ในขณะที่ค่านั้นอยู่ตรง ค่ากลางที่ 0.5 อาจแสดงถึงความไม่แน่นอนทั้งหมด นี่ไม่ใช่การกระจายความมั่นใจในตัวแยกประเภทเสมอไป แต่เป็นการออกแบบทั่วไปและใช้งานได้ตามวัตถุประสงค์ของภาพประกอบของเรา
ปรากฎว่ามีฟังก์ชันที่ดีที่จับพฤติกรรมนี้ได้ดี เรียกว่าฟังก์ชัน sigmoid g(z) และมีลักษณะดังนี้:
z คือตัวแทนของอินพุตและสัมประสิทธิ์ของเรา เช่น:
เพื่อให้ตัวทำนายของเรากลายเป็น:
ขอให้สังเกตว่าฟังก์ชัน sigmoid แปลงเอาต์พุตของเราเป็นช่วงระหว่าง 0 ถึง 1
ตรรกะเบื้องหลังการออกแบบฟังก์ชันต้นทุนก็แตกต่างกันในการจัดประเภท เราถามอีกครั้งว่า “การเดาผิดหมายความว่าอย่างไร” และคราวนี้กฎทั่วไปที่ดีก็คือถ้าการเดาที่ถูกต้องคือ 0 และเราเดา 1 เราก็ผิดทั้งหมดและในทางกลับกัน เนื่องจากคุณไม่สามารถผิดพลาดได้มากไปกว่าความผิดพลาดโดยสิ้นเชิง บทลงโทษในกรณีนี้จึงมหาศาล อีกทางเลือกหนึ่ง หากการเดาที่ถูกต้องคือ 0 และเราเดาว่า 0 ฟังก์ชันต้นทุนของเราไม่ควรบวกต้นทุนใดๆ สำหรับแต่ละเหตุการณ์ที่เกิดขึ้น หากการเดานั้นถูก แต่เราไม่มั่นใจอย่างสมบูรณ์ (เช่น y = 1 แต่ h(x) = 0.8 ) สิ่งนี้ควรมาพร้อมกับค่าใช้จ่ายเล็กน้อย และหากการเดาของเราผิดแต่เราไม่มั่นใจอย่างสมบูรณ์ ( เช่น y = 1 แต่ h(x) = 0.3 ) ควรมีค่าใช้จ่ายที่สำคัญ แต่ไม่มากเท่ากับว่าเราคิดผิดทั้งหมด
ลักษณะการทำงานนี้ถูกจับโดยฟังก์ชันบันทึก เช่น:
อีกครั้ง ฟังก์ชันต้นทุน ทำให้เรามีค่าใช้จ่ายเฉลี่ยสำหรับตัวอย่างการฝึกอบรมทั้งหมดของเรา
ที่นี่เราได้อธิบายวิธีที่ตัวทำนาย h(x) และฟังก์ชันต้นทุน ต่างกันระหว่างการถดถอยและการจำแนกประเภท แต่การไล่ระดับสียังคงใช้ได้ดี
ตัวทำนายการจำแนกประเภทสามารถมองเห็นได้โดยการวาดเส้นขอบเขต กล่าวคือ อุปสรรคที่คำทำนายเปลี่ยนจาก "ใช่" (คำทำนายที่มากกว่า 0.5) เป็น "ไม่" (คำทำนายที่น้อยกว่า 0.5) ด้วยระบบที่ออกแบบมาอย่างดี ข้อมูลคุกกี้ของเราสามารถสร้างขอบเขตการจำแนกประเภทที่มีลักษณะดังนี้:
ตอนนี้เป็นเครื่องที่รู้สิ่งหนึ่งหรือสองเรื่องเกี่ยวกับคุกกี้!
บทนำสู่โครงข่ายประสาทเทียม
การอภิปรายเกี่ยวกับแมชชีนเลิร์นนิงจะไม่สมบูรณ์หากไม่ได้กล่าวถึงโครงข่ายประสาทเทียม โครงข่ายประสาทไม่เพียงแต่นำเสนอเครื่องมือที่ทรงพลังอย่างยิ่งในการแก้ปัญหาที่ยากมาก แต่ยังเสนอคำแนะนำที่น่าสนใจเกี่ยวกับการทำงานของสมองของเราเอง และความเป็นไปได้ที่น่าสนใจสำหรับหนึ่งวันในการสร้างเครื่องจักรที่ชาญฉลาดอย่างแท้จริง
โครงข่ายประสาทเทียมมีความเหมาะสมอย่างยิ่งกับโมเดลการเรียนรู้ของเครื่องที่อินพุตมีจำนวนมาก ค่าใช้จ่ายในการจัดการปัญหาดังกล่าวมากเกินไปสำหรับประเภทของระบบที่เราได้กล่าวถึงข้างต้น อย่างไรก็ตาม ผลปรากฎว่า โครงข่ายประสาทเทียมสามารถปรับได้อย่างมีประสิทธิภาพโดยใช้เทคนิคที่คล้ายคลึงกับหลักการเกรเดียนต์ในหลักการอย่างน่าทึ่ง
การอภิปรายอย่างละเอียดเกี่ยวกับโครงข่ายประสาทเทียมอยู่นอกเหนือขอบเขตของบทช่วยสอนนี้ แต่ฉันขอแนะนำให้ดูโพสต์ก่อนหน้าของเราในหัวข้อนี้
การเรียนรู้ของเครื่องโดยไม่ได้รับการดูแล
โดยทั่วไปแล้วแมชชีนเลิร์นนิงที่ไม่มีผู้ดูแลจะได้รับมอบหมายให้ค้นหาความสัมพันธ์ภายในข้อมูล ไม่มีตัวอย่างการฝึกอบรมที่ใช้ในกระบวนการนี้ แต่ระบบจะได้รับชุดข้อมูลและมอบหมายให้ค้นหารูปแบบและความสัมพันธ์ในนั้น ตัวอย่างที่ดีคือการระบุกลุ่มเพื่อนที่สนิทสนมกันในข้อมูลเครือข่ายสังคมออนไลน์
อัลกอริธึมการเรียนรู้ของเครื่องที่ใช้ในการดำเนินการนี้แตกต่างอย่างมากจากอัลกอริทึมที่ใช้สำหรับการเรียนรู้ภายใต้การดูแล และหัวข้อก็เป็นประโยชน์ต่อโพสต์ของตัวเอง อย่างไรก็ตาม สำหรับบางสิ่งที่ต้องเคี้ยวในระหว่างนี้ ให้ดูอัลกอริธึมการจัดกลุ่ม เช่น ค่าเฉลี่ย k และพิจารณาระบบการลดขนาดด้วย เช่น การวิเคราะห์องค์ประกอบหลัก โพสต์ก่อนหน้าของเราเกี่ยวกับข้อมูลขนาดใหญ่จะกล่าวถึงหัวข้อเหล่านี้ในรายละเอียดเพิ่มเติมเช่นกัน
บทสรุป
เราได้กล่าวถึงทฤษฎีพื้นฐานมากมายที่เป็นรากฐานของการเรียนรู้ด้วยเครื่องแล้ว แต่แน่นอนว่า เราแทบไม่ได้ขีดข่วนพื้นผิวเลย
โปรดจำไว้ว่า ในการนำทฤษฎีที่มีอยู่ในบทนำนี้ไปใช้กับตัวอย่างแมชชีนเลิร์นนิงในชีวิตจริง จำเป็นต้องมีความเข้าใจอย่างลึกซึ้งยิ่งขึ้นในหัวข้อที่กล่าวถึงในที่นี้ มีรายละเอียดปลีกย่อยและข้อผิดพลาดมากมายใน ML และมีหลายวิธีที่จะหลงผิดโดยสิ่งที่ดูเหมือนจะเป็นเครื่องคิดที่ปรับแต่งมาอย่างดี เกือบทุกส่วนของทฤษฎีพื้นฐานสามารถเล่นและเปลี่ยนแปลงได้ไม่รู้จบ และผลลัพธ์ก็มักจะน่าทึ่ง หลายคนเติบโตเป็นสาขาวิชาใหม่ทั้งหมดที่เหมาะกับปัญหาเฉพาะมากกว่า
เห็นได้ชัดว่า Machine Learning เป็นเครื่องมือที่ทรงพลังอย่างเหลือเชื่อ ในอีกไม่กี่ปีข้างหน้า เราสัญญาว่าจะช่วยแก้ปัญหาเร่งด่วนที่สุดบางส่วนของเรา ตลอดจนเปิดโลกแห่งโอกาสใหม่ให้กับบริษัทวิทยาศาสตร์ข้อมูล ความต้องการวิศวกรของแมชชีนเลิร์นนิงจะเพิ่มมากขึ้นเรื่อยๆ ซึ่งมอบโอกาสอันน่าทึ่งที่จะได้เป็นส่วนหนึ่งของสิ่งที่ยิ่งใหญ่ ฉันหวังว่าคุณจะพิจารณาลงมือปฏิบัติ!
การรับทราบ
บทความนี้ใช้เนื้อหาที่สอนโดยศาสตราจารย์ ดร. แอนดรูว์ อึ้ง จากสแตนฟอร์ดในหลักสูตรการเรียนรู้ของเครื่องที่ไม่มีค่าใช้จ่ายและเปิดกว้าง หลักสูตรครอบคลุมทุกอย่างที่กล่าวถึงในบทความนี้ในเชิงลึก และให้คำแนะนำเชิงปฏิบัติมากมายสำหรับผู้ปฏิบัติงาน ML ฉันไม่สามารถแนะนำหลักสูตรนี้ได้มากพอสำหรับผู้ที่สนใจสำรวจสาขาที่น่าสนใจนี้ต่อไป
- โมเดล AI ของเสียงลอจิกและโมโนโทนิก
- Schooling Flappy Bird: แบบฝึกหัดการเรียนรู้การเสริมแรง