
Une introduction à la théorie de l'apprentissage automatique et à ses applications : un didacticiel visuel avec des exemples
Publié: 2022-03-11L'apprentissage automatique (ML) prend tout son sens, avec une reconnaissance croissante que ML peut jouer un rôle clé dans un large éventail d'applications critiques, telles que l'exploration de données, le traitement du langage naturel, la reconnaissance d'images et les systèmes experts. ML fournit des solutions potentielles dans tous ces domaines et plus encore, et est destiné à être un pilier de notre future civilisation.
L'offre de concepteurs ML compétents doit encore rattraper cette demande. L'une des principales raisons à cela est que le ML est tout simplement délicat. Ce didacticiel d'apprentissage automatique présente les bases de la théorie de l'apprentissage automatique, en énonçant les thèmes et concepts communs, ce qui facilite le suivi de la logique et se familiarise avec les bases de l'apprentissage automatique.
Qu'est-ce que l'apprentissage automatique ?
Alors, qu'est-ce que le "machine learning" exactement ? ML est en fait beaucoup de choses. Le domaine est assez vaste et se développe rapidement, étant continuellement partitionné et sous-partitionné ad nauseam en différentes sous-spécialités et types d'apprentissage automatique.
Il existe cependant quelques points communs de base, et le thème général est mieux résumé par cette déclaration souvent citée d'Arthur Samuel en 1959 : "[L'apprentissage automatique est le] domaine d'étude qui donne aux ordinateurs la capacité d'apprendre sans étant explicitement programmé.
Et plus récemment, en 1997, Tom Mitchell a donné une définition « bien posée » qui s'est avérée plus utile aux types d'ingénieurs : « On dit qu'un programme informatique apprend de l'expérience E par rapport à une tâche T et à une mesure de performance P, si sa performance sur T, mesurée par P, s'améliore avec l'expérience E.
Donc, si vous voulez que votre programme prédise, par exemple, les modèles de trafic à une intersection très fréquentée (tâche T), vous pouvez l'exécuter via un algorithme d'apprentissage automatique avec des données sur les modèles de trafic passés (expérience E) et, s'il a réussi à "apprendre ”, il réussira alors mieux à prédire les modèles de trafic futurs (mesure de performance P).
Cependant, la nature très complexe de nombreux problèmes du monde réel signifie souvent qu'il est peu pratique, voire impossible, d'inventer des algorithmes spécialisés qui les résoudront parfaitement à chaque fois. Voici des exemples de problèmes d'apprentissage automatique : "Est-ce un cancer ?", "Quelle est la valeur marchande de cette maison ?", "Lesquelles de ces personnes sont de bons amis ?", "Ce moteur de fusée va-t-il exploser au décollage ? », « Cette personne aimera-t-elle ce film ? », « Qui est-ce ? », « Qu'avez-vous dit ? » et « Comment pilotez-vous ce truc ? ». Tous ces problèmes sont d'excellentes cibles pour un projet ML, et en fait ML a été appliqué à chacun d'eux avec un grand succès.
Parmi les différents types de tâches ML, une distinction cruciale est établie entre l'apprentissage supervisé et non supervisé :
- Apprentissage automatique supervisé : le programme est "formé" sur un ensemble prédéfini d'"exemples de formation", ce qui facilite ensuite sa capacité à parvenir à une conclusion précise lorsqu'il reçoit de nouvelles données.
- Apprentissage automatique non supervisé : le programme reçoit un ensemble de données et doit y trouver des modèles et des relations.
Nous nous concentrerons principalement sur l'apprentissage supervisé ici, mais la fin de l'article comprend une brève discussion sur l'apprentissage non supervisé avec quelques liens pour ceux qui souhaitent approfondir le sujet.
Apprentissage automatique supervisé
Dans la majorité des applications d'apprentissage supervisé, le but ultime est de développer une fonction prédictive finement réglée h(x) (parfois appelée « hypothèse »). "L'apprentissage" consiste à utiliser des algorithmes mathématiques sophistiqués pour optimiser cette fonction de sorte que, étant donné les données d'entrée x sur un certain domaine (disons, la superficie d'une maison), il prédira avec précision une valeur intéressante h(x) (par exemple, le prix du marché pour ladite maison).
En pratique, x représente presque toujours plusieurs points de données. Ainsi, par exemple, un prédicteur du prix du logement peut prendre non seulement la superficie en pieds carrés ( x1 ), mais également le nombre de chambres ( x2 ), le nombre de salles de bains ( x3 ), le nombre d'étages ( x4) , l'année de construction ( x5 ), le code postal. ( x6 ), et ainsi de suite. La détermination des entrées à utiliser est une partie importante de la conception ML. Cependant, pour des raisons d'explication, il est plus facile de supposer qu'une seule valeur d'entrée est utilisée.
Supposons donc que notre prédicteur simple ait cette forme :
où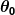 et
et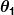 sont des constantes. Notre objectif est de trouver les valeurs parfaites de et pour que notre prédicteur fonctionne au mieux.
sont des constantes. Notre objectif est de trouver les valeurs parfaites de et pour que notre prédicteur fonctionne au mieux.
L'optimisation du prédicteur h(x) est effectuée à l'aide d'exemples d'apprentissage . Pour chaque exemple d'entraînement, nous avons une valeur d'entrée x_train , pour laquelle une sortie correspondante, y , est connue à l'avance. Pour chaque exemple, nous trouvons la différence entre la valeur connue et correcte y et notre valeur prédite h(x_train) . Avec suffisamment d'exemples de formation, ces différences nous donnent un moyen utile de mesurer le "faux" de h(x) . Nous pouvons ensuite ajuster h(x) en ajustant les valeurs de et pour le rendre "moins faux". Ce processus est répété encore et encore jusqu'à ce que le système ait convergé vers les meilleures valeurs pour et . De cette façon, le prédicteur est formé et prêt à effectuer des prédictions dans le monde réel.
Exemples d'apprentissage automatique
Nous nous en tenons à des problèmes simples dans cet article à des fins d'illustration, mais la raison pour laquelle ML existe est que, dans le monde réel, les problèmes sont beaucoup plus complexes. Sur cet écran plat, nous pouvons vous dessiner une image d'au plus un ensemble de données en trois dimensions, mais les problèmes de ML traitent généralement des données avec des millions de dimensions et des fonctions de prédiction très complexes. ML résout des problèmes qui ne peuvent pas être résolus uniquement par des moyens numériques.
Dans cet esprit, regardons un exemple simple. Supposons que nous disposions des données de formation suivantes, dans lesquelles les employés de l'entreprise ont évalué leur satisfaction sur une échelle de 1 à 100 :
Tout d'abord, notez que les données sont un peu bruyantes. C'est-à-dire que même si nous pouvons voir qu'il y a une tendance (c'est-à-dire que la satisfaction des employés a tendance à augmenter à mesure que le salaire augmente), tout ne s'inscrit pas parfaitement sur une ligne droite. Ce sera toujours le cas avec des données du monde réel (et nous voulons absolument former notre machine en utilisant des données du monde réel !). Alors comment entraîner une machine à prédire parfaitement le niveau de satisfaction d'un employé ? La réponse, bien sûr, est que nous ne pouvons pas. L'objectif du ML n'est jamais de faire des suppositions "parfaites", car le ML traite de domaines où cela n'existe pas. Le but est de faire des suppositions suffisamment bonnes pour être utiles.
Cela rappelle quelque peu la célèbre déclaration du mathématicien et professeur de statistique britannique George EP Box selon laquelle « tous les modèles sont faux, mais certains sont utiles ».
L'apprentissage automatique s'appuie fortement sur les statistiques. Par exemple, lorsque nous entraînons notre machine à apprendre, nous devons lui donner un échantillon aléatoire statistiquement significatif comme données d'apprentissage. Si l'ensemble d'apprentissage n'est pas aléatoire, nous courons le risque de modèles d'apprentissage automatique qui n'existent pas réellement. Et si l'ensemble d'apprentissage est trop petit (voir loi des grands nombres), nous n'apprendrons pas assez et nous pourrons même arriver à des conclusions inexactes. Par exemple, tenter de prédire les modèles de satisfaction à l'échelle de l'entreprise en se basant uniquement sur les données de la haute direction serait probablement source d'erreurs.
Avec cette compréhension, donnons à notre machine les données qui nous ont été données ci-dessus et faisons-la apprendre. Nous devons d'abord initialiser notre prédicteur h(x) avec des valeurs raisonnables de et . Maintenant, notre prédicteur ressemble à ceci lorsqu'il est placé sur notre ensemble d'entraînement :
Si nous demandons à ce prédicteur la satisfaction d'un employé gagnant 60 000 $, il prédira une note de 27 :
Il est évident que c'était une supposition terrible et que cette machine ne sait pas grand-chose.
Alors maintenant, donnons à ce prédicteur tous les salaires de notre ensemble de formation, et prenons les différences entre les notes de satisfaction prédites qui en résultent et les notes de satisfaction réelles des employés correspondants. Si nous effectuons un peu de magie mathématique (que je décrirai brièvement), nous pouvons calculer, avec une très grande certitude, que les valeurs de 13,12 pour et 0,61 pour vont nous donner un meilleur prédicteur.
Et si nous répétons ce processus, disons 1500 fois, notre prédicteur finira par ressembler à ceci :
À ce stade, si nous répétons le processus, nous constaterons que et ne changera plus de manière appréciable et nous voyons donc que le système a convergé. Si nous n'avons commis aucune erreur, cela signifie que nous avons trouvé le prédicteur optimal. En conséquence, si nous demandons maintenant à nouveau à la machine la note de satisfaction de l'employé qui gagne 60 000 $, elle prédira une note d'environ 60.
Maintenant, nous arrivons quelque part.
Régression d'apprentissage automatique : une note sur la complexité
L'exemple ci-dessus est techniquement un problème simple de régression linéaire univariée, qui en réalité peut être résolu en dérivant une simple équation normale et en sautant complètement ce processus de "réglage". Cependant, considérez un prédicteur qui ressemble à ceci :
Cette fonction prend en entrée quatre dimensions et a une variété de termes polynomiaux. Dériver une équation normale pour cette fonction est un défi important. De nombreux problèmes d'apprentissage automatique modernes nécessitent des milliers, voire des millions de dimensions de données pour construire des prédictions à l'aide de centaines de coefficients. Prédire comment le génome d'un organisme sera exprimé, ou à quoi ressemblera le climat dans cinquante ans, sont des exemples de ces problèmes complexes.
Heureusement, l'approche itérative adoptée par les systèmes ML est beaucoup plus résistante face à une telle complexité. Au lieu d'utiliser la force brute, un système d'apprentissage automatique "tâte son chemin" vers la réponse. Pour les gros problèmes, cela fonctionne beaucoup mieux. Bien que cela ne signifie pas que ML peut résoudre tous les problèmes arbitrairement complexes (ce n'est pas le cas), cela en fait un outil incroyablement flexible et puissant.
Descente de gradient - Minimiser le « tort »
Examinons de plus près le fonctionnement de ce processus itératif. Dans l'exemple ci-dessus, comment s'assurer et s'améliorent à chaque pas et ne s'aggravent pas ? La réponse réside dans notre « mesure de l'erreur » à laquelle nous avons fait allusion précédemment, ainsi qu'un peu de calcul.

La mesure de l'erreur est connue sous le nom de fonction de coût (aka, fonction de perte ),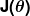 . L'entrée
. L'entrée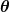 représente tous les coefficients que nous utilisons dans notre prédicteur. Donc dans notre cas, c'est vraiment la paire et .
représente tous les coefficients que nous utilisons dans notre prédicteur. Donc dans notre cas, c'est vraiment la paire et .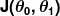 nous donne une mesure mathématique de l'erreur de notre prédicteur lorsqu'il utilise les valeurs données de et .
nous donne une mesure mathématique de l'erreur de notre prédicteur lorsqu'il utilise les valeurs données de et .
Le choix de la fonction de coût est un autre élément important d'un programme ML. Dans différents contextes, avoir « tort » peut signifier des choses très différentes. Dans notre exemple de satisfaction des employés, la norme bien établie est la fonction linéaire des moindres carrés :
Avec les moindres carrés, la pénalité pour une mauvaise estimation augmente de manière quadratique avec la différence entre l'estimation et la bonne réponse, elle agit donc comme une mesure très "stricte" de l'erreur. La fonction de coût calcule une pénalité moyenne sur tous les exemples de formation.
Alors maintenant, nous voyons que notre objectif est de trouver et pour notre prédicteur h(x) tel que notre fonction de coût est le plus petit possible. Nous faisons appel à la puissance du calcul pour y parvenir.
Considérez le graphique suivant d'une fonction de coût pour un problème particulier d'apprentissage automatique :
Ici, nous pouvons voir le coût associé à différentes valeurs de et . Nous pouvons voir que le graphique a un léger bol à sa forme. Le bas du bol représente le coût le plus bas que notre prédicteur peut nous donner en fonction des données d'entraînement données. Le but est de "dévaler la colline" et de trouver et correspondant à ce point.
C'est là qu'intervient le calcul dans ce didacticiel d'apprentissage automatique. Afin de garder cette explication gérable, je n'écrirai pas les équations ici, mais essentiellement ce que nous faisons est de prendre le gradient de , qui est la paire de dérivées de (un de plus et un de plus ). Le gradient sera différent pour chaque valeur différente de et , et nous dit quelle est la "pente de la colline" et, en particulier, "quel est le chemin vers le bas", pour ces particuliers s. Par exemple, lorsque nous branchons nos valeurs actuelles de dans le dégradé, cela peut nous dire que l'ajout d'un peu à et en soustrayant un peu de nous emmènera dans la direction du plancher de la vallée de la fonction de coût. Par conséquent, nous ajoutons un peu à , et soustraire un peu de , et voila ! Nous avons terminé un tour de notre algorithme d'apprentissage. Notre prédicteur mis à jour, h(x) = + x, renverra de meilleures prédictions qu'auparavant. Notre machine est maintenant un peu plus intelligente.
Ce processus d'alternance entre le calcul du gradient actuel et la mise à jour du s à partir des résultats, est connue sous le nom de descente de gradient.
Cela couvre la théorie de base sous-jacente à la majorité des systèmes d'apprentissage automatique supervisés. Mais les concepts de base peuvent être appliqués de différentes manières, en fonction du problème à résoudre.
Problèmes de classification dans l'apprentissage automatique
Dans le cadre du BC supervisé, deux sous-catégories principales sont :
- Systèmes d'apprentissage automatique de régression : systèmes où la valeur prédite se situe quelque part sur un spectre continu. Ces systèmes nous aident à répondre aux questions « Combien ? » ou "Combien?".
- Systèmes d'apprentissage automatique de classification : systèmes où nous recherchons une prédiction par oui ou par non, comme "Ce cancer est-il cancéreux ?", "Ce cookie répond-il à nos normes de qualité ?", etc.
Il s'avère que la théorie sous-jacente de l'apprentissage automatique est plus ou moins la même. Les principales différences sont la conception du prédicteur h(x) et la conception de la fonction de coût .
Jusqu'à présent, nos exemples se sont concentrés sur les problèmes de régression, alors examinons maintenant également un exemple de classification.
Voici les résultats d'une étude de test de la qualité des cookies, où les exemples de formation ont tous été étiquetés comme "bon cookie" ( y = 1 ) en bleu ou "mauvais cookie" ( y = 0 ) en rouge.
En classification, un prédicteur de régression n'est pas très utile. Ce que nous voulons généralement, c'est un prédicteur qui fait une supposition entre 0 et 1. Dans un classificateur de qualité de cookie, une prédiction de 1 représenterait une supposition très sûre que le cookie est parfait et tout à fait appétissant. Une prédiction de 0 représente une confiance élevée dans le fait que le cookie est une source d'embarras pour l'industrie des cookies. Les valeurs comprises dans cette plage représentent moins de confiance, nous pourrions donc concevoir notre système de telle sorte que la prédiction de 0,6 signifie "Mec, c'est un appel difficile, mais je vais y aller avec oui, vous pouvez vendre ce cookie", tandis qu'une valeur exactement dans le milieu, à 0,5, pourrait représenter une incertitude complète. Ce n'est pas toujours ainsi que la confiance est distribuée dans un classificateur, mais c'est une conception très courante et qui fonctionne aux fins de notre illustration.
Il s'avère qu'il existe une fonction intéressante qui capture bien ce comportement. C'est ce qu'on appelle la fonction sigmoïde, g(z) , et ça ressemble à ceci :
z est une représentation de nos entrées et coefficients, tels que :
de sorte que notre prédicteur devient :
Notez que la fonction sigmoïde transforme notre sortie dans la plage comprise entre 0 et 1.
La logique derrière la conception de la fonction de coût est également différente dans la classification. Encore une fois, nous demandons "qu'est-ce que cela signifie pour une supposition d'être fausse?" et cette fois, une très bonne règle empirique est que si la bonne estimation était 0 et que nous avons deviné 1, alors nous avions complètement et totalement tort, et vice-versa. Puisque vous ne pouvez pas avoir plus tort qu'absolument tort, la pénalité dans ce cas est énorme. Alternativement, si la bonne estimation était 0 et que nous avons deviné 0, notre fonction de coût ne devrait pas ajouter de coût à chaque fois que cela se produit. Si la supposition était bonne, mais que nous n'étions pas complètement confiants (par exemple y = 1 , mais h(x) = 0.8 ), cela devrait avoir un petit coût, et si notre supposition était fausse mais que nous n'étions pas complètement confiants ( par exemple y = 1 mais h(x) = 0.3 ), cela devrait avoir un coût important, mais pas autant que si nous nous trompions complètement.
Ce comportement est capturé par la fonction log, de sorte que :
Encore une fois, la fonction de coût nous donne le coût moyen sur l'ensemble de nos exemples de formation.
Nous avons donc décrit ici comment le prédicteur h(x) et la fonction de coût diffèrent entre la régression et la classification, mais la descente de gradient fonctionne toujours bien.
Un prédicteur de classification peut être visualisé en traçant la ligne de démarcation ; c'est-à-dire la barrière où la prédiction passe d'un « oui » (une prédiction supérieure à 0,5) à un « non » (une prédiction inférieure à 0,5). Avec un système bien conçu, nos données de cookies peuvent générer une limite de classification qui ressemble à ceci :
Voilà une machine qui connaît une chose ou deux sur les cookies !
Une introduction aux réseaux de neurones
Aucune discussion sur l'apprentissage automatique ne serait complète sans au moins mentionner les réseaux de neurones. Non seulement les réseaux de neurones offrent un outil extrêmement puissant pour résoudre des problèmes très difficiles, mais ils offrent également des indices fascinants sur le fonctionnement de notre propre cerveau et des possibilités intrigantes pour créer un jour des machines vraiment intelligentes.
Les réseaux de neurones sont bien adaptés aux modèles d'apprentissage automatique où le nombre d'entrées est gigantesque. Le coût de calcul de la gestion d'un tel problème est tout simplement trop écrasant pour les types de systèmes dont nous avons discuté ci-dessus. Il s'avère cependant que les réseaux de neurones peuvent être réglés efficacement à l'aide de techniques qui sont étonnamment similaires à la descente de gradient en principe.
Une discussion approfondie des réseaux de neurones dépasse le cadre de ce didacticiel, mais je vous recommande de consulter notre article précédent sur le sujet.
Apprentissage automatique non supervisé
L'apprentissage automatique non supervisé est généralement chargé de trouver des relations dans les données. Il n'y a pas d'exemples de formation utilisés dans ce processus. Au lieu de cela, le système reçoit un ensemble de données et est chargé d'y trouver des modèles et des corrélations. Un bon exemple est l'identification de groupes d'amis proches dans les données des réseaux sociaux.
Les algorithmes d'apprentissage automatique utilisés pour ce faire sont très différents de ceux utilisés pour l'apprentissage supervisé, et le sujet mérite son propre article. Cependant, pour quelque chose à mâcher en attendant, jetez un œil aux algorithmes de clustering tels que k-means, et examinez également les systèmes de réduction de dimensionnalité tels que l'analyse des composants principaux. Notre article précédent sur le Big Data aborde également un certain nombre de ces sujets plus en détail.
Conclusion
Nous avons couvert une grande partie de la théorie de base sous-jacente au domaine de l'apprentissage automatique ici, mais bien sûr, nous n'avons qu'effleuré la surface.
Gardez à l'esprit que pour vraiment appliquer les théories contenues dans cette introduction à des exemples réels d'apprentissage automatique, une compréhension beaucoup plus approfondie des sujets abordés ici est nécessaire. Il existe de nombreuses subtilités et pièges dans le ML, et de nombreuses façons de se laisser égarer par ce qui semble être une machine à penser parfaitement bien réglée. Presque toutes les parties de la théorie de base peuvent être jouées et modifiées à l'infini, et les résultats sont souvent fascinants. Beaucoup évoluent vers de tout nouveaux domaines d'études mieux adaptés à des problèmes particuliers.
De toute évidence, l'apprentissage automatique est un outil incroyablement puissant. Dans les années à venir, il promet d'aider à résoudre certains de nos problèmes les plus urgents, ainsi qu'à ouvrir de nouveaux mondes d'opportunités pour les entreprises de science des données. La demande d'ingénieurs en apprentissage automatique ne fera que continuer à croître, offrant des chances incroyables de faire partie de quelque chose de grand. J'espère que vous envisagerez de vous lancer dans l'action !
Reconnaissance
Cet article s'inspire largement du matériel enseigné par le professeur de Stanford, le Dr Andrew Ng, dans son cours gratuit et ouvert sur l'apprentissage automatique. Le cours couvre tout ce qui est discuté dans cet article en profondeur et donne des tonnes de conseils pratiques pour le praticien ML. Je ne saurais trop recommander ce cours à ceux qui souhaitent explorer davantage ce domaine fascinant.
- Modèles Sound Logic et Monotonic AI
- Scolariser Flappy Bird : un didacticiel d'apprentissage par renforcement