
مقدمة في نظرية التعلم الآلي وتطبيقاتها: دروس مرئية بأمثلة
نشرت: 2022-03-11بدأ التعلم الآلي (ML) في الظهور ، مع الاعتراف المتزايد بأن تعلم الآلة يمكن أن يلعب دورًا رئيسيًا في مجموعة واسعة من التطبيقات الهامة ، مثل استخراج البيانات ، ومعالجة اللغة الطبيعية ، والتعرف على الصور ، والأنظمة الخبيرة. يوفر ML حلولاً محتملة في جميع هذه المجالات وأكثر ، ومن المقرر أن يكون أحد أعمدة حضارتنا المستقبلية.
توفير مصممي ML القادرين لم يواكب هذا الطلب حتى الآن. أحد الأسباب الرئيسية لذلك هو أن ML هو مجرد معقد. يقدم هذا البرنامج التعليمي لتعلم الآلة أساسيات نظرية التعلم الآلي ، ويضع الموضوعات والمفاهيم المشتركة ، مما يجعل من السهل اتباع المنطق والاعتياد على أساسيات التعلم الآلي.
ما هو التعلم الآلي؟
إذن ما هو "التعلم الآلي" على أي حال؟ ML هو في الواقع الكثير من الأشياء. المجال واسع جدًا ويتوسع بسرعة ، حيث يتم تقسيمه وتقسيمه إلى أجزاء فرعية إلى تخصصات فرعية مختلفة وأنواع مختلفة من التعلم الآلي.
ومع ذلك ، هناك بعض الخيوط المشتركة الأساسية ، وأفضل تلخيص للموضوع الشامل هو هذا البيان المقتبس كثيرًا الذي أدلى به آرثر صموئيل في عام 1959: "[التعلم الآلي هو] مجال الدراسة الذي يمنح أجهزة الكمبيوتر القدرة على التعلم بدون يتم برمجتها بشكل صريح ".
ومؤخراً ، في عام 1997 ، قدم توم ميتشل تعريفًا "في وضع جيد" أثبت أنه أكثر فائدة للأنواع الهندسية: "يُقال أن برنامج الكمبيوتر يتعلم من التجربة E فيما يتعلق ببعض المهام T وبعض مقاييس الأداء P ، إذا يتحسن أدائها على T ، كما تم قياسه بواسطة P ، مع تجربة E. "
لذلك إذا كنت تريد أن يتنبأ برنامجك ، على سبيل المثال ، بأنماط حركة المرور في تقاطع مزدحم (المهمة T) ، فيمكنك تشغيله من خلال خوارزمية التعلم الآلي مع بيانات حول أنماط حركة المرور السابقة (التجربة E) ، وإذا كان قد "تعلم بنجاح" "، فإنه سيؤدي بعد ذلك بشكل أفضل في التنبؤ بأنماط الزيارات المستقبلية (مقياس الأداء P).
على الرغم من ذلك ، غالبًا ما تعني الطبيعة شديدة التعقيد للعديد من مشكلات العالم الحقيقي أن اختراع خوارزميات متخصصة من شأنها حلها تمامًا في كل مرة هو أمر غير عملي ، إن لم يكن مستحيلًا. تتضمن أمثلة مشكلات التعلم الآلي ، "هل هذا سرطان؟" ، "ما القيمة السوقية لهذا المنزل؟" ، "أي من هؤلاء الأشخاص صديقين لبعضهم البعض؟" ، "هل سينفجر محرك الصاروخ هذا عند الإقلاع؟ "،" هل سيحب هذا الشخص هذا الفيلم؟ "،" من هذا؟ "،" ماذا قلت؟ "، و" كيف تطير بهذا الشيء؟ ". كل هذه المشاكل هي أهداف ممتازة لمشروع ML ، وفي الواقع تم تطبيق ML على كل منها بنجاح كبير.
من بين الأنواع المختلفة لمهام ML ، يوجد تمييز حاسم بين التعلم الخاضع للإشراف والتعلم غير الخاضع للإشراف:
- التعلم الآلي الخاضع للإشراف: يتم "تدريب" البرنامج على مجموعة محددة مسبقًا من "أمثلة التدريب" ، والتي تسهل بعد ذلك قدرته على الوصول إلى نتيجة دقيقة عند إعطائه بيانات جديدة.
- التعلم الآلي غير الخاضع للإشراف: يُعطى البرنامج مجموعة من البيانات ويجب أن يجد أنماطًا وعلاقات فيها.
سنركز هنا بشكل أساسي على التعلم الخاضع للإشراف ، لكن نهاية المقالة تتضمن مناقشة موجزة للتعلم غير الخاضع للإشراف مع بعض الروابط لأولئك الذين يرغبون في متابعة الموضوع بشكل أكبر.
تعلم الآلة الخاضع للإشراف
في غالبية تطبيقات التعلم الخاضع للإشراف ، يكون الهدف النهائي هو تطوير وظيفة توقع مضبوطة بدقة h(x) (تسمى أحيانًا "الفرضية"). يتكون "التعلم" من استخدام خوارزميات رياضية معقدة لتحسين هذه الوظيفة بحيث ، نظرًا لبيانات الإدخال x حول مجال معين (على سبيل المثال ، المساحة المربعة للمنزل) ، فإنه سيتنبأ بدقة ببعض القيمة المثيرة للاهتمام h(x) (على سبيل المثال ، سعر السوق عن البيت المذكور).
من الناحية العملية ، تمثل x دائمًا نقاط بيانات متعددة. لذلك ، على سبيل المثال ، قد لا يأخذ متنبئ أسعار المساكن قدمًا مربعة ( x1 ) فقط ولكن أيضًا عدد غرف النوم ( x2 ) ، وعدد الحمامات ( x3 ) ، وعدد الطوابق ( x4) ، والسنة المبنية ( x5 ) ، والرمز البريدي ( x6 ) وهكذا دواليك. يعد تحديد المدخلات التي يجب استخدامها جزءًا مهمًا من تصميم ML. ومع ذلك ، من أجل التفسير ، من الأسهل افتراض استخدام قيمة إدخال واحدة.
لنفترض أن المتنبئ البسيط لدينا لديه هذا الشكل:
أين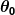 و
و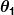 ثوابت. هدفنا هو إيجاد القيم المثالية لـ و لجعل المتنبئ يعمل بشكل جيد قدر الإمكان.
ثوابت. هدفنا هو إيجاد القيم المثالية لـ و لجعل المتنبئ يعمل بشكل جيد قدر الإمكان.
يتم تحسين المتنبئ h(x) باستخدام أمثلة تدريبية . لكل مثال تدريبي ، لدينا قيمة إدخال x_train ، والتي يُعرف الناتج المقابل لها مسبقًا ، y . لكل مثال ، نجد الفرق بين القيمة المعروفة والصحيحة y والقيمة المتوقعة h(x_train) . مع وجود أمثلة تدريب كافية ، تعطينا هذه الاختلافات طريقة مفيدة لقياس "خطأ" h(x) . يمكننا بعد ذلك تعديل h(x) عن طريق تعديل قيم و لجعلها "أقل خطأ". تتكرر هذه العملية مرارًا وتكرارًا حتى يتقارب النظام مع أفضل القيم لـ و . بهذه الطريقة ، يتم تدريب المتنبئ ، ويكون جاهزًا للقيام ببعض التنبؤات الواقعية.
أمثلة على تعلم الآلة
نتمسك بالمشكلات البسيطة في هذا المنشور من أجل التوضيح ، ولكن سبب وجود ML هو أنه في العالم الحقيقي ، تكون المشكلات أكثر تعقيدًا. على هذه الشاشة المسطحة ، يمكننا رسم صورة لمجموعة بيانات ثلاثية الأبعاد على الأكثر ، لكن مشاكل تعلم الآلة تتعامل عادةً مع بيانات بملايين الأبعاد ، ووظائف توقع معقدة للغاية. يحل التعلم الآلي المشكلات التي لا يمكن حلها بالوسائل العددية وحدها.
مع أخذ ذلك في الاعتبار ، دعونا نلقي نظرة على مثال بسيط. لنفترض أن لدينا بيانات التدريب التالية ، حيث صنف موظفو الشركة رضاهم على مقياس من 1 إلى 100:
أولاً ، لاحظ أن البيانات صاخبة قليلاً. أي ، بينما يمكننا أن نرى أن هناك نمطًا لها (أي يميل رضا الموظف إلى الارتفاع مع ارتفاع الراتب) ، إلا أنه لا يتناسب تمامًا مع خط مستقيم. سيكون هذا هو الحال دائمًا مع بيانات العالم الحقيقي (ونريد تمامًا تدريب أجهزتنا باستخدام بيانات العالم الحقيقي!). إذن كيف يمكننا تدريب آلة على التنبؤ تمامًا بمستوى رضا الموظف؟ الجواب بالطبع هو أننا لا نستطيع. لا يتمثل هدف ML في إجراء تخمينات "كاملة" أبدًا ، لأن ML يتعامل في المجالات التي لا يوجد فيها شيء من هذا القبيل. الهدف هو عمل تخمينات جيدة بما يكفي لتكون مفيدة.
إنه يذكرنا إلى حد ما بالتصريح الشهير لعالم الرياضيات البريطاني وأستاذ الإحصاء جورج إي بوكس بأن "جميع النماذج خاطئة ، لكن بعضها مفيد".
يعتمد التعلم الآلي بشكل كبير على الإحصائيات. على سبيل المثال ، عندما ندرب آلتنا على التعلم ، علينا أن نعطيها عينة عشوائية ذات دلالة إحصائية كبيانات تدريب. إذا لم تكن مجموعة التدريب عشوائية ، فإننا نخاطر بأنماط التعلم الآلي غير الموجودة بالفعل. وإذا كانت مجموعة التدريب صغيرة جدًا (انظر قانون الأعداد الكبيرة) ، فلن نتعلم بما فيه الكفاية وقد نتوصل إلى استنتاجات غير دقيقة. على سبيل المثال ، من المحتمل أن تكون محاولة التنبؤ بأنماط الرضا على مستوى الشركة استنادًا إلى بيانات من الإدارة العليا وحدها عرضة للخطأ.
مع هذا الفهم ، دعنا نعطي أجهزتنا البيانات التي قدمناها أعلاه ونجعلها تتعلمها. أولاً ، يتعين علينا تهيئة المتنبئ h(x) ببعض القيم المعقولة لـ و . الآن يبدو متنبئنا هكذا عند وضعه فوق مجموعة التدريب الخاصة بنا:
إذا طلبنا من هذا المتنبئ إرضاء الموظف الذي يكسب 60 ألف دولار ، فإنه يتوقع تصنيف 27:
من الواضح أن هذا كان تخمينًا رهيبًا وأن هذه الآلة لا تعرف الكثير.
والآن ، دعنا نمنح هذا المتنبئ جميع الرواتب من مجموعة التدريب لدينا ، ونأخذ الاختلافات بين تقييمات الرضا المتوقعة الناتجة وتقييمات الرضا الفعلية للموظفين المقابلين. إذا أجرينا القليل من السحر الرياضي (الذي سأصفه بعد قليل) ، فيمكننا حساب ، بدرجة عالية جدًا من اليقين ، تلك القيم 13.12 لـ و 0.61 لـ سيعطينا متنبئًا أفضل.
وإذا كررنا هذه العملية ، على سبيل المثال 1500 مرة ، سينتهي متنبئنا بالشكل التالي:
في هذه المرحلة ، إذا كررنا العملية ، فسنجد ذلك و لن يتغير بأي مبلغ ملموس بعد الآن ، وبالتالي نرى أن النظام قد تقارب. إذا لم نرتكب أي أخطاء ، فهذا يعني أننا وجدنا المتنبئ الأمثل. وفقًا لذلك ، إذا طلبنا الآن من الجهاز مرة أخرى تقدير رضا الموظف الذي يكسب 60 ألف دولار ، فسوف يتوقع تصنيفًا يقارب 60.
نحن الآن نصل إلى مكان ما.
انحدار تعلم الآلة: ملاحظة حول التعقيد
المثال أعلاه هو من الناحية الفنية مشكلة بسيطة للانحدار الخطي أحادي المتغير ، والتي يمكن حلها في الواقع عن طريق اشتقاق معادلة عادية بسيطة وتخطي عملية "الضبط" هذه تمامًا. ومع ذلك ، ضع في اعتبارك متنبئًا يشبه هذا:
تأخذ هذه الوظيفة مدخلات في أربعة أبعاد ولها مجموعة متنوعة من المصطلحات كثيرة الحدود. يعد اشتقاق معادلة عادية لهذه الوظيفة تحديًا كبيرًا. تتطلب العديد من مشكلات التعلم الآلي الحديثة آلافًا أو حتى ملايين أبعاد البيانات لبناء تنبؤات باستخدام مئات المعاملات. إن التنبؤ بكيفية التعبير عن جينوم الكائن الحي ، أو كيف سيكون شكل المناخ بعد خمسين عامًا ، هي أمثلة على مثل هذه المشكلات المعقدة.
لحسن الحظ ، فإن النهج التكراري الذي تتبعه أنظمة تعلم الآلة أكثر مرونة في مواجهة مثل هذا التعقيد. بدلاً من استخدام القوة الغاشمة ، فإن نظام التعلم الآلي "يشعر بطريقته" للإجابة. بالنسبة للمشاكل الكبيرة ، يعمل هذا بشكل أفضل. في حين أن هذا لا يعني أن ML يمكنه حل جميع المشكلات المعقدة بشكل تعسفي (لا يمكنه ذلك) ، إلا أنه يمثل أداة مرنة وقوية بشكل لا يصدق.
الانحدار المتدرج - تقليل "الخطأ"
دعونا نلقي نظرة فاحصة على كيفية عمل هذه العملية التكرارية. في المثال أعلاه ، كيف نتأكد و تتحسن مع كل خطوة وليس أسوأ؟ تكمن الإجابة في "قياس الخطأ" الذي أشرنا إليه سابقًا ، جنبًا إلى جنب مع القليل من التفاضل والتكامل.

يُعرف مقياس الخطأ باسم دالة التكلفة (ويعرف أيضًا باسم وظيفة الخسارة ) ،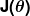 . المدخل
. المدخل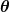 تمثل جميع المعاملات التي نستخدمها في المتنبئ. لذلك في حالتنا ، هو حقا الزوج و .
تمثل جميع المعاملات التي نستخدمها في المتنبئ. لذلك في حالتنا ، هو حقا الزوج و .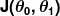 يعطينا قياسًا رياضيًا لمدى خطأ متنبئنا عندما يستخدم القيم المعطاة لـ و .
يعطينا قياسًا رياضيًا لمدى خطأ متنبئنا عندما يستخدم القيم المعطاة لـ و .
يعد اختيار وظيفة التكلفة جزءًا مهمًا آخر من برنامج ML. في سياقات مختلفة ، يمكن أن يعني كونك "مخطئًا" أشياء مختلفة جدًا. في مثال رضا الموظف لدينا ، المعيار الراسخ هو دالة المربعات الصغرى الخطية:
في المربعات الصغرى ، ترتفع عقوبة التخمين السيئ تربيعيًا مع الاختلاف بين التخمين والإجابة الصحيحة ، لذا فهي تعمل كمقياس "صارم" جدًا للخطأ. تحسب دالة التكلفة متوسط العقوبة على جميع أمثلة التدريب.
والآن نرى أن هدفنا هو إيجاد و للتنبؤ لدينا h(x) مثل دالة التكلفة لدينا صغيرة قدر الإمكان. نحن ندعو قوة التفاضل والتكامل لتحقيق ذلك.
ضع في اعتبارك المخطط التالي لدالة التكلفة لبعض مشكلات التعلم الآلي المعينة:
هنا يمكننا أن نرى التكلفة المرتبطة بقيم مختلفة لـ و . يمكننا أن نرى أن الرسم البياني له وعاء صغير على شكله. يمثل الجزء السفلي من الوعاء أقل تكلفة يمكن أن يقدمها لنا المتنبئ بناءً على بيانات التدريب المقدمة. الهدف هو "دحرجة التل" ، والعثور عليها و المقابلة لهذه النقطة.
هذا هو المكان الذي يأتي فيه حساب التفاضل والتكامل في هذا البرنامج التعليمي للتعلم الآلي. من أجل الإبقاء على هذا التفسير قابلاً للإدارة ، لن أكتب المعادلات هنا ، ولكن ما نفعله في الأساس هو أخذ التدرج اللوني لـ ، وهو زوج من مشتقات (أكثر من وواحد ). سيكون التدرج مختلفًا لكل قيمة مختلفة لـ و ، ويخبرنا ما هو "منحدر التل" ، وعلى وجه الخصوص ، "أي طريق لأسفل" ، بالنسبة لهذه س. على سبيل المثال ، عندما نعوض بالقيم الحالية لـ في التدرج ، فقد يخبرنا ذلك بإضافة القليل إلى وطرح القليل من ستأخذنا في اتجاه أرضية وظيفة التكلفة. لذلك ، نضيف القليل إلى ، وطرح القليل من ، وفويلا! لقد أكملنا جولة واحدة من خوارزمية التعلم الخاصة بنا. المتنبئ المحدث ، h (x) = + x ، سيعيد تنبؤات أفضل من ذي قبل. أصبحت آلتنا الآن أكثر ذكاءً قليلاً.
هذه العملية من التناوب بين حساب التدرج الحالي وتحديث يُعرف s من النتائج باسم الانحدار التدريجي.
يغطي ذلك النظرية الأساسية التي تقوم عليها غالبية أنظمة التعلم الآلي الخاضعة للإشراف. ولكن يمكن تطبيق المفاهيم الأساسية بعدة طرق مختلفة ، اعتمادًا على المشكلة المطروحة.
مشاكل التصنيف في التعلم الآلي
تحت إشراف غسل الأموال ، هناك فئتان فرعيتان رئيسيتان هما:
- أنظمة التعلم الآلي للانحدار: الأنظمة التي تقع فيها القيمة المتوقعة في مكان ما على طيف مستمر. تساعدنا هذه الأنظمة في طرح أسئلة "كم؟" أو "كم عدد؟".
- تصنيف أنظمة التعلم الآلي: الأنظمة التي نسعى فيها للحصول على تنبؤ بنعم أو لا ، مثل "هل هذا الورم سرطاني؟" ، "هل يفي ملف تعريف الارتباط هذا بمعايير الجودة لدينا؟" ، وما إلى ذلك.
كما اتضح ، فإن نظرية التعلم الآلي الأساسية هي نفسها إلى حد ما. الاختلافات الرئيسية هي تصميم المتنبئ h(x) وتصميم دالة التكلفة .
ركزت أمثلةنا حتى الآن على مشاكل الانحدار ، لذلك دعونا الآن نلقي نظرة أيضًا على مثال على التصنيف.
فيما يلي نتائج دراسة اختبار جودة ملفات تعريف الارتباط ، حيث تم تصنيف أمثلة التدريب على أنها إما "ملف تعريف ارتباط جيد" ( y = 1 ) باللون الأزرق أو "ملف تعريف ارتباط سيئ" ( y = 0 ) باللون الأحمر.
في التصنيف ، لا يعتبر توقع الانحدار مفيدًا جدًا. ما نريده عادة هو متنبئ يقوم بالتخمين في مكان ما بين 0 و 1. في مصنف جودة ملفات تعريف الارتباط ، يمثل توقع 1 تخمينًا واثقًا جدًا بأن ملف تعريف الارتباط مثالي وشهي تمامًا. يمثل توقع القيمة 0 ثقة عالية في أن ملف تعريف الارتباط يمثل إحراجًا لصناعة ملفات تعريف الارتباط. تمثل القيم التي تقع ضمن هذا النطاق ثقة أقل ، لذلك قد نصمم نظامنا بحيث يعني التنبؤ بـ 0.6 "يا رجل ، هذه دعوة صعبة ، لكنني سأوافق على نعم ، يمكنك بيع ملف تعريف الارتباط هذا" ، بينما القيمة بالضبط في قد يمثل الوسط ، عند 0.5 ، حالة عدم يقين كاملة. هذه ليست دائمًا الطريقة التي يتم بها توزيع الثقة في المصنف ولكنه تصميم شائع جدًا ويعمل لأغراض الرسم التوضيحي الخاص بنا.
اتضح أن هناك وظيفة لطيفة تلتقط هذا السلوك جيدًا. تسمى الوظيفة السينية g(z) ، وهي تبدو كالتالي:
z هو تمثيل لمدخلاتنا ومعاملاتنا ، مثل:
بحيث يصبح متنبئنا:
لاحظ أن الدالة السينية تحول ناتجنا إلى النطاق بين 0 و 1.
يختلف المنطق الكامن وراء تصميم دالة التكلفة أيضًا في التصنيف. نسأل مرة أخرى "ماذا يعني أن يكون التخمين خاطئًا؟" وهذه المرة قاعدة أساسية جيدة جدًا وهي أنه إذا كان التخمين الصحيح هو 0 وخمننا 1 ، فنحن مخطئون تمامًا والعكس صحيح. نظرًا لأنك لا يمكن أن تكون مخطئًا أكثر من الخطأ المطلق ، فإن العقوبة في هذه الحالة هائلة. بدلاً من ذلك ، إذا كان التخمين الصحيح هو 0 وخمننا 0 ، فلا يجب أن تضيف دالة التكلفة أي تكلفة لكل مرة يحدث ذلك. إذا كان التخمين صحيحًا ، لكننا لم نكن واثقين تمامًا (على سبيل المثال ، y = 1 ، لكن h(x) = 0.8 ) ، يجب أن يأتي هذا بتكلفة بسيطة ، وإذا كان تخميننا خاطئًا لكننا لم نكن واثقين تمامًا ( على سبيل المثال y = 1 ولكن h(x) = 0.3 ) ، يجب أن يأتي هذا مع بعض التكلفة الكبيرة ، ولكن ليس بقدر ما لو كنا مخطئين تمامًا.
يتم التقاط هذا السلوك من خلال وظيفة السجل ، مثل:
مرة أخرى ، دالة التكلفة يعطينا متوسط التكلفة على جميع أمثلة التدريب لدينا.
لذلك وصفنا هنا كيفية المتنبئ h(x) ودالة التكلفة تختلف بين الانحدار والتصنيف ، لكن النسب المتدرج لا يزال يعمل بشكل جيد.
يمكن تصور متنبئ التصنيف عن طريق رسم خط الحدود ؛ أي الحاجز حيث يتغير التنبؤ من "نعم" (توقع أكبر من 0.5) إلى "لا" (توقع أقل من 0.5). باستخدام نظام جيد التصميم ، يمكن لبيانات ملفات تعريف الارتباط الخاصة بنا إنشاء حد تصنيف يبدو كالتالي:
الآن هذه آلة تعرف شيئًا أو شيئين عن ملفات تعريف الارتباط!
مقدمة للشبكات العصبية
لن تكتمل أي مناقشة حول التعلم الآلي بدون ذكر الشبكات العصبية على الأقل. لا توفر الشبكات العصبية فقط أداة قوية للغاية لحل المشكلات الصعبة للغاية ، ولكنها تقدم أيضًا تلميحات رائعة حول طريقة عمل أدمغتنا ، وإمكانيات مثيرة للاهتمام لإنشاء آلات ذكية حقًا في يوم من الأيام.
الشبكات العصبية مناسبة تمامًا لنماذج التعلم الآلي حيث يكون عدد المدخلات ضخمًا. التكلفة الحسابية للتعامل مع مثل هذه المشكلة باهظة للغاية لأنواع الأنظمة التي ناقشناها أعلاه. كما اتضح ، مع ذلك ، يمكن ضبط الشبكات العصبية بشكل فعال باستخدام تقنيات تشبه إلى حد كبير النسب المتدرج من حيث المبدأ.
إن المناقشة الشاملة للشبكات العصبية هي خارج نطاق هذا البرنامج التعليمي ، لكنني أوصي بمراجعة منشورنا السابق حول هذا الموضوع.
التعلم الآلي غير الخاضع للإشراف
عادةً ما يتم تكليف التعلم الآلي غير الخاضع للإشراف بإيجاد العلاقات داخل البيانات. لا توجد أمثلة تدريبية مستخدمة في هذه العملية. بدلاً من ذلك ، يتم إعطاء النظام مجموعة بيانات ومكلف بإيجاد الأنماط والارتباطات فيها. وخير مثال على ذلك هو تحديد مجموعات الأصدقاء المترابطة في بيانات الشبكات الاجتماعية.
تختلف خوارزميات التعلم الآلي المستخدمة للقيام بذلك اختلافًا كبيرًا عن تلك المستخدمة في التعلم الخاضع للإشراف ، ويستحق الموضوع المنشور الخاص به. ومع ذلك ، لكي تمضغ شيئًا ما في هذه الأثناء ، ألق نظرة على خوارزميات التجميع مثل k-mean ، وانظر أيضًا في أنظمة تقليل الأبعاد مثل تحليل المكون الأساسي. تناقش منشوراتنا السابقة حول البيانات الضخمة عددًا من هذه الموضوعات بمزيد من التفصيل أيضًا.
خاتمة
لقد غطينا الكثير من النظرية الأساسية الكامنة وراء مجال التعلم الآلي هنا ، لكننا بالطبع بالكاد خدشنا السطح.
ضع في اعتبارك أنه لتطبيق النظريات الواردة في هذه المقدمة على أمثلة التعلم الآلي الواقعية ، من الضروري فهم أعمق بكثير للموضوعات التي تمت مناقشتها هنا. هناك العديد من التفاصيل الدقيقة والمزالق في تعلم الآلة ، والعديد من الطرق التي تجعلك تضل طريق ما يبدو أنه آلة تفكير مضبوطة جيدًا. يمكن اللعب بكل جزء من النظرية الأساسية تقريبًا وتغييره إلى ما لا نهاية ، والنتائج غالبًا ما تكون رائعة. ينمو الكثير إلى مجالات دراسة جديدة تمامًا تتناسب بشكل أفضل مع مشاكل معينة.
من الواضح أن التعلم الآلي هو أداة قوية بشكل لا يصدق. في السنوات القادمة ، يعد بالمساعدة في حل بعض مشاكلنا الأكثر إلحاحًا ، بالإضافة إلى فتح عوالم جديدة كاملة من الفرص لشركات علوم البيانات. سيستمر الطلب على مهندسي التعلم الآلي في النمو ، مما يوفر فرصًا لا تصدق لتكون جزءًا من شيء كبير. آمل أن تفكر في المشاركة في الحدث!
إعتراف
تعتمد هذه المقالة بشكل كبير على المواد التي يدرسها الأستاذ في جامعة ستانفورد الدكتور أندرو نغ في دورة التعلم الآلي المجانية والمفتوحة. تغطي الدورة كل ما تمت مناقشته في هذه المقالة بعمق كبير ، وتقدم الكثير من النصائح العملية لممارس ML. لا يمكنني أن أوصي بهذه الدورة بدرجة كافية للراغبين في استكشاف هذا المجال الرائع.
- منطق الصوت ونماذج الذكاء الاصطناعي الرتيبة
- مدرسة فلابي بيرد: برنامج تعليمي للتعلم التعزيزي