
6 tipos de funciones de activación en redes neuronales que debes conocer
Publicado: 2020-02-13Con Deep Learning convirtiéndose en una tecnología dominante, últimamente, se ha hablado mucho sobre ANN o redes neuronales artificiales. Hoy en día, ANN es un componente central en diversos dominios emergentes, como el reconocimiento de escritura a mano, la compresión de imágenes, la predicción de la bolsa de valores y mucho más. Obtenga más información sobre los tipos de redes neuronales artificiales en el aprendizaje automático.
Pero, ¿qué es una Red Neuronal Artificial?
La red neuronal artificial es un modelo de aprendizaje profundo que se inspira en la estructura neuronal del cerebro humano. Las ANN se han diseñado para imitar las funciones del cerebro humano que aprenden de las experiencias y se adaptan en consecuencia a la situación. Al igual que el cerebro humano tiene una estructura de varios niveles que contiene miles de millones de neuronas dispuestas en una jerarquía, ANN también tiene una red de neuronas que están interconectadas entre sí a través de axones.
Estas neuronas interconectadas transmiten señales eléctricas (llamadas sinapsis) de una capa a otra. Esta imitación del modelado cerebral permite que la RNA aprenda de la experiencia sin necesidad de intervención humana.
Leer: Red neuronal artificial en minería de datos
Por lo tanto, las ANN son estructuras complejas que contienen elementos adaptativos interconectados conocidos como neuronas artificiales que pueden realizar grandes cálculos para la representación del conocimiento. Poseen todas las cualidades fundamentales del sistema de neuronas biológicas, incluida la capacidad de aprendizaje, robustez, no linealidad, alto paralelismo, tolerancia a fallas y fallas, capacidad para manejar información imprecisa y confusa y capacidad de generalización.

Únase a los cursos de inteligencia artificial en línea de las mejores universidades del mundo: maestrías, programas ejecutivos de posgrado y programa de certificado avanzado en ML e IA para acelerar su carrera.
Tabla de contenido
Características principales de las redes neuronales artificiales
- La no linealidad imparte un mejor ajuste a los datos.
- El alto paralelismo promueve un procesamiento rápido y tolerancia a fallas de hardware.
- La generalización permite la aplicación del modelo a datos no aprendidos.
- Insensibilidad al ruido que permite una predicción precisa incluso para datos inciertos y errores de medición.
- El aprendizaje y la adaptabilidad permiten que el modelo actualice su arquitectura interna de acuerdo con el entorno cambiante.
La computación basada en ANN tiene como objetivo principal diseñar algoritmos matemáticos avanzados que permitan que las Redes Neuronales Artificiales aprendan imitando las funciones de procesamiento de información y adquisición de conocimiento del cerebro humano.
Componentes de Redes Neuronales Artificiales
Las ANN se componen de tres capas o fases centrales: una capa de entrada, una capa oculta y una capa de salida.
- Capa de entrada: la primera capa se alimenta con la entrada, es decir, datos sin procesar. Transmite la información del mundo exterior a la red. En esta capa, no se realiza ningún cálculo: los nodos simplemente transmiten la información a la capa oculta.
- Capa oculta: en esta capa, los nodos se encuentran ocultos detrás de la capa de entrada: comprenden la parte de abstracción en cada red neuronal. Todos los cálculos sobre las características ingresadas a través de la capa de entrada ocurren en la capa o capas ocultas y luego transfiere el resultado a la capa de salida.
- Capa de salida: esta capa muestra los resultados de los cálculos realizados por la red al mundo exterior.
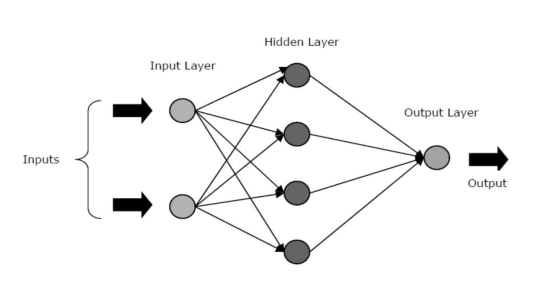
Fuente
Las redes neuronales se pueden clasificar en diferentes tipos según la actividad de la capa o capas ocultas. Por ejemplo, en una red neuronal simple, las unidades ocultas pueden construir su representación única de la entrada. Aquí, los pesos entre las unidades ocultas y de entrada deciden cuándo está activa cada unidad oculta.
Por lo tanto, al ajustar estos pesos, la capa oculta puede elegir lo que debería representar. Otras arquitecturas incluyen los modelos de capa única y multicapa. En una sola capa, generalmente solo hay una capa de entrada y otra de salida; carece de una capa oculta. Mientras que, en un modelo multicapa, hay una o más de una capa oculta.
¿Qué son las funciones de activación en una red neuronal?
Como mencionamos anteriormente, las ANN son un componente crucial de muchas estructuras que están ayudando a revolucionar el mundo que nos rodea. Pero, ¿alguna vez se ha preguntado cómo ofrecen las ANN un rendimiento de última generación para encontrar soluciones a los problemas del mundo real?
La respuesta es: funciones de activación.
Las ANN utilizan funciones de activación (AF) para realizar cálculos complejos en las capas ocultas y luego transferir el resultado a la capa de salida. El objetivo principal de los AF es introducir propiedades no lineales en la red neuronal.
Convierten las señales de entrada lineales de un nodo en señales de salida no lineales para facilitar el aprendizaje de polinomios de alto orden que van más allá de un grado para redes profundas. Un aspecto único de los AF es que son diferenciables, lo que les ayuda a funcionar durante la retropropagación de las redes neuronales.
¿Cuál es la necesidad de la no linealidad?
Si no se aplican funciones de activación, la señal de salida sería una función lineal, que es un polinomio de un grado. Si bien es fácil resolver ecuaciones lineales, tienen un cociente de complejidad limitado y, por lo tanto, tienen menos poder para aprender mapeos funcionales complejos a partir de datos. Por lo tanto, sin AF, una red neuronal sería un modelo de regresión lineal con capacidades limitadas.
Esto ciertamente no es lo que queremos de una red neuronal. La tarea de las redes neuronales es realizar cálculos muy complicados. Además, sin AF, las redes neuronales no pueden aprender y modelar otros datos complicados, como imágenes, voz, videos, audio, etc.
Los AF ayudan a las redes neuronales a dar sentido a conjuntos de Big Data complicados, de alta dimensión y no lineales que tienen una arquitectura intrincada: contienen múltiples capas ocultas entre la capa de entrada y la de salida.
Leer: Deep Learning Vs Neural Network
Ahora, sin más preámbulos, profundicemos en los diferentes tipos de funciones de activación que se utilizan en las ANN.
Tipos de funciones de activación
1. Función sigmoidea
En una ANN, la función sigmoidea es un AF no lineal que se utiliza principalmente en redes neuronales de avance. Es una función real diferenciable, definida para valores de entrada reales y que contiene derivadas positivas en todas partes con un grado específico de suavidad. La función sigmoidea aparece en la capa de salida de los modelos de aprendizaje profundo y se usa para predecir salidas basadas en probabilidad. La función sigmoidea se representa como:
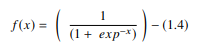
Fuente
Generalmente, las derivadas de la función sigmoidea se aplican a algoritmos de aprendizaje. La gráfica de la función sigmoidea tiene forma de 'S'.
Algunos de los principales inconvenientes de la función sigmoidea incluyen la saturación del gradiente, la convergencia lenta, los gradientes húmedos pronunciados durante la retropropagación desde capas ocultas más profundas hacia las capas de entrada y una salida centrada distinta de cero que hace que las actualizaciones del gradiente se propaguen en distintas direcciones.

2. Función tangente hiperbólica (Tanh)
La función tangente hiperbólica, también conocida como función tanh, es otro tipo de AF. Es una función más suave, centrada en cero, que tiene un rango entre -1 y 1. Como resultado, la salida de la función tanh está representada por:
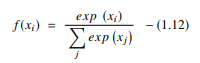
Fuente
La función tanh se usa mucho más que la función sigmoide, ya que ofrece un mejor rendimiento de entrenamiento para redes neuronales multicapa. La mayor ventaja de la función tanh es que produce una salida centrada en cero, lo que respalda el proceso de retropropagación. La función tanh se ha utilizado principalmente en redes neuronales recurrentes para tareas de procesamiento de lenguaje natural y reconocimiento de voz.
Sin embargo, la función tanh también tiene una limitación: al igual que la función sigmoidea, no puede resolver el problema del gradiente de fuga. Además, la función tanh solo puede alcanzar un gradiente de 1 cuando el valor de entrada es 0 (x es cero). Como resultado, la función puede producir algunas neuronas muertas durante el proceso de cálculo.
3. Función Softmax
La función softmax es otro tipo de AF utilizado en redes neuronales para calcular la distribución de probabilidad a partir de un vector de números reales. Esta función genera una salida que oscila entre los valores 0 y 1 y con la suma de las probabilidades igual a 1. La función softmax se representa de la siguiente manera:
Fuente
Esta función se utiliza principalmente en modelos multiclase en los que devuelve las probabilidades de cada clase, siendo la clase objetivo la que tiene la probabilidad más alta. Aparece en casi todas las capas de salida de la arquitectura DL donde se utilizan. La principal diferencia entre el sigmoide y el softmax AF es que mientras el primero se usa en la clasificación binaria, el segundo se usa para la clasificación multivariada.
4. Función de señal suave
La función softsign es otro AF que se utiliza en la computación de redes neuronales. Aunque se utiliza principalmente en problemas de cálculo de regresión, hoy en día también se utiliza en aplicaciones de texto a voz basadas en DL. Es un polinomio cuadrático, representado por:
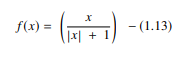
Fuente
Aquí "x" es igual al valor absoluto de la entrada.
La principal diferencia entre la función softsign y la función tanh es que, a diferencia de la función tanh que converge exponencialmente, la función softsign converge en forma polinomial.
5. Función de unidad lineal rectificada (ReLU)
Uno de los AF más populares en los modelos DL, la función de unidad lineal rectificada (ReLU), es un AF de aprendizaje rápido que promete ofrecer un rendimiento de vanguardia con resultados estelares. En comparación con otras funciones AF, como las funciones sigmoide y tanh, la función ReLU ofrece un rendimiento y una generalización mucho mejores en el aprendizaje profundo. La función es una función casi lineal que conserva las propiedades de los modelos lineales, lo que los hace fáciles de optimizar con métodos de descenso de gradiente.
La función ReLU realiza una operación de umbral en cada elemento de entrada donde todos los valores menores que cero se establecen en cero. Así, la ReLU se representa como:
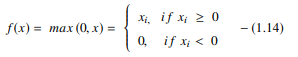
Fuente
Al rectificar los valores de las entradas por debajo de cero y establecerlos en cero, esta función elimina el problema del gradiente de fuga observado en los tipos anteriores de funciones de activación (sigmoide y tanh).
La ventaja más significativa de usar la función ReLU en el cálculo es que garantiza un cálculo más rápido: no calcula exponenciales ni divisiones, lo que aumenta la velocidad de cálculo general. Otro aspecto crítico de la función ReLU es que introduce escasez en las unidades ocultas al aplastar los valores entre cero y el máximo.
6. Función de unidades lineales exponenciales (ELU)
La función de unidades lineales exponenciales (ELU) es un AF que también se utiliza para acelerar el entrenamiento de redes neuronales (al igual que la función ReLU). La mayor ventaja de la función ELU es que puede eliminar el problema del gradiente de fuga utilizando la identidad para valores positivos y mejorando las características de aprendizaje del modelo.
Los ELU tienen valores negativos que acercan la activación de la unidad media a cero, lo que reduce la complejidad computacional y mejora la velocidad de aprendizaje. El ELU es una excelente alternativa al ReLU: reduce los cambios de sesgo al empujar la activación media hacia cero durante el proceso de entrenamiento.
La función de unidad lineal exponencial se representa como:
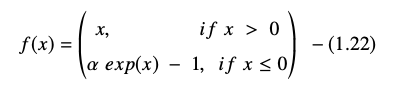
La derivada o gradiente de la ecuación ELU se presenta como:
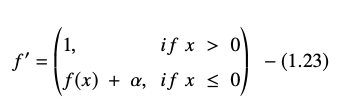
Fuente
Aquí “α” es igual al hiperparámetro ELU que controla el punto de saturación para entradas netas negativas, que generalmente se establece en 1.0. Sin embargo, la función ELU tiene una limitación: no está centrada en cero.
Conclusión
Hoy en día, AF como ReLU y ELU han ganado la máxima atención ya que ayudan a eliminar el problema del gradiente de fuga que causa problemas importantes en el proceso de entrenamiento y degrada la precisión y el rendimiento de los modelos de redes neuronales.
Consulte el Programa de certificación avanzada en aprendizaje automático y nube con IIT Madras, la mejor escuela de ingeniería del país para crear un programa que le enseñe no solo el aprendizaje automático sino también la implementación efectiva del mismo utilizando la infraestructura de la nube. Nuestro objetivo con este programa es abrir las puertas del instituto más selectivo del país y brindar a los estudiantes acceso a profesores y recursos increíbles para dominar una habilidad que está en alto y en crecimiento.
¿Qué es una Red Neuronal Artificial?
La ANN es un modelo de aprendizaje profundo inspirado en la estructura neuronal del cerebro humano. Las ANN se crearon para replicar las actividades del cerebro humano, que aprenden de sus experiencias y se adaptan a su entorno. ANN contiene una red de neuronas que están conectadas entre sí por axones, similar a cómo la mente humana tiene una estructura de varios niveles con miles de millones de neuronas dispuestas en una jerarquía. Estas neuronas conectadas envían señales eléctricas (llamadas sinapsis) de una capa a la siguiente. La RNA puede aprender de la experiencia sin necesidad de intervención humana gracias a esta aproximación del modelado cerebral.
¿Qué son las funciones de activación en las redes neuronales?
Las ANN emplean funciones de activación (AF) en las capas ocultas para realizar cálculos complejos y luego transferir los resultados a la capa de salida. El objetivo básico de los AF es dotar a la red neuronal de cualidades no lineales. Convierten las señales de entrada lineales de un nodo en señales de salida no lineales para ayudar a las redes profundas a aprender polinomios de alto orden con más de un grado. Los AF son distintos porque son diferenciables, lo que ayuda a su función durante la retropropagación de la red neuronal.
¿Cuál es la necesidad de la no linealidad?
Si no se utilizan funciones de activación, la señal de salida es una transformación lineal, que es un polinomio de un grado. Si bien las ecuaciones lineales son fáciles de resolver, tienen un cociente de complejidad bajo, lo que limita su capacidad para aprender mapeos complicados a partir de datos. Una red neuronal sin AF será un modelo lineal generalizado con capacidades limitadas. Este no es el tipo de rendimiento que queremos de una red neuronal. Las redes neuronales se utilizan para realizar cálculos extremadamente complejos. Además, las redes neuronales no pueden aprender y representar otros datos complejos sin AF, como fotos, voz, películas, audio, etc.