
6 tipuri de funcții de activare în rețelele neuronale pe care trebuie să le cunoașteți
Publicat: 2020-02-13În timp ce Deep Learning a devenit o tehnologie mainstream, în ultimul timp, s-a vorbit mult despre ANN-uri sau rețele neuronale artificiale. Astăzi, ANN este o componentă de bază în diverse domenii emergente, cum ar fi recunoașterea scrisului de mână, compresia imaginilor, predicția bursieră și multe altele. Citiți mai multe despre tipurile de rețele neuronale artificiale în învățarea automată.
Dar ce este o rețea neuronală artificială?
Artificial Neural Network este un model de învățare profundă care se inspiră din structura neuronală a creierului uman. ANN-urile au fost concepute pentru a imita funcțiile creierului uman care învață din experiențe și se adaptează în consecință la situație. Așa cum creierul uman are o structură cu mai multe niveluri care conține miliarde de neuroni aranjați într-o ierarhie, ANN are, de asemenea, o rețea de neuroni care sunt interconectați între ei prin intermediul axonilor.
Acești neuroni interconectați transmit semnale electrice (numite sinapse) de la un strat la altul. Această imitație a modelării creierului permite ANN să învețe din experiență fără a necesita intervenția umană.
Citiți: Rețeaua neuronală artificială în minarea datelor
Astfel, ANN-urile sunt structuri complexe care conțin elemente adaptive interconectate cunoscute sub numele de neuroni artificiali care pot efectua calcule mari pentru reprezentarea cunoștințelor. Ei posedă toate calitățile fundamentale ale sistemului neuron biologic, inclusiv capacitatea de învățare, robustețe, neliniaritate, paralelism ridicat, toleranță la erori și eșecuri, capacitatea de a gestiona informații imprecise și neclare și capacitatea de generalizare.

Alăturați-vă cursurilor de inteligență artificială online de la cele mai bune universități din lume - masterat, programe executive postuniversitare și program de certificat avansat în ML și AI pentru a vă accelera cariera.
Cuprins
Caracteristicile de bază ale rețelelor neuronale artificiale
- Neliniaritatea conferă o potrivire mai bună datelor.
- Paralelismul ridicat promovează procesarea rapidă și toleranța la defecțiuni hardware.
- Generalizarea permite aplicarea modelului la datele neînvățate.
- Insensibilitate la zgomot care permite predicții precise chiar și pentru date incerte și erori de măsurare.
- Învățarea și adaptabilitatea permit modelului să își actualizeze arhitectura internă în funcție de mediul în schimbare.
Calculul bazat pe ANN urmărește în primul rând să proiecteze algoritmi matematici avansați care să permită rețelelor neuronale artificiale să învețe prin imitarea funcțiilor de procesare a informațiilor și de achiziție a cunoștințelor ale creierului uman.
Componentele rețelelor neuronale artificiale
ANN-urile sunt compuse din trei straturi de bază sau faze - un strat de intrare, un strat/e ascuns și un strat de ieșire.
- Strat de intrare: primul strat este alimentat cu intrarea, adică cu date brute. Acesta transmite informațiile din lumea exterioară către rețea. În acest strat, nu se efectuează niciun calcul - nodurile doar transmit informațiile la stratul ascuns.
- Strat ascuns: în acest strat, nodurile se află ascunse în spatele stratului de intrare - ele cuprind partea de abstractizare din fiecare rețea neuronală. Toate calculele asupra caracteristicilor introduse prin stratul de intrare au loc în stratul/străturile ascunse, iar apoi, acesta transferă rezultatul în stratul de ieșire.
- Strat de ieșire: Acest strat prezintă rezultatele calculelor efectuate de rețea către lumea exterioară.
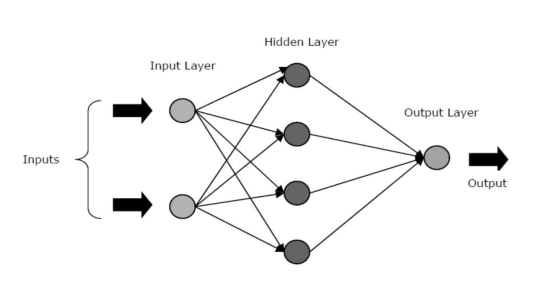
Sursă
Rețelele neuronale pot fi clasificate în diferite tipuri în funcție de activitatea stratului/străturilor ascunse. De exemplu, într-o rețea neuronală simplă, unitățile ascunse își pot construi reprezentarea unică a intrării. Aici, ponderile dintre unitățile ascunse și cele de intrare decid când fiecare unitate ascunsă este activă.
Astfel, prin ajustarea acestor greutăți, stratul ascuns poate alege ce ar trebui să reprezinte. Alte arhitecturi includ modelele cu un singur strat și multistrat. Într-un singur strat, există de obicei doar un strat de intrare și un strat de ieșire - îi lipsește un strat ascuns. În timp ce, într-un model cu mai multe straturi, există unul sau mai multe straturi ascunse.
Ce sunt funcțiile de activare într-o rețea neuronală?
După cum am menționat mai devreme, ANN-urile sunt o componentă crucială a multor structuri care ajută la revoluționarea lumii din jurul nostru. Dar te-ai întrebat vreodată cum oferă ANN-urile performanțe de ultimă generație pentru a găsi soluții la problemele din lumea reală?
Răspunsul este – Funcții de activare.
ANN-urile folosesc funcții de activare (AF) pentru a efectua calcule complexe în straturile ascunse și apoi transfera rezultatul în stratul de ieșire. Scopul principal al AF-urilor este de a introduce proprietăți neliniare în rețeaua neuronală.
Ele convertesc semnalele de intrare liniare ale unui nod în semnale de ieșire neliniare pentru a facilita învățarea polinoamelor de ordin înalt care depășesc un grad pentru rețelele adânci. Un aspect unic al AF-urilor este că sunt diferențiabile - acest lucru le ajută să funcționeze în timpul propagării inverse a rețelelor neuronale.
Care este nevoie de neliniaritate?
Dacă funcțiile de activare nu sunt aplicate, semnalul de ieșire ar fi o funcție liniară, care este un polinom de un grad. Deși este ușor de rezolvat ecuații liniare, acestea au un coeficient de complexitate limitat și, prin urmare, au mai puțină putere de a învăța mapări funcționale complexe din date. Astfel, fără AF, o rețea neuronală ar fi un model de regresie liniară cu abilități limitate.
Acest lucru cu siguranță nu este ceea ce ne dorim de la o rețea neuronală. Sarcina rețelelor neuronale este de a calcula calcule extrem de complicate. În plus, fără AF, rețelele neuronale nu pot învăța și modela alte date complicate, inclusiv imagini, vorbire, videoclipuri, audio etc.
AF-urile ajută rețelele neuronale să dea sens unor seturi de Big Data complicate, dimensionale și neliniare, care au o arhitectură complicată - conțin mai multe straturi ascunse între stratul de intrare și cel de ieșire.
Citiți: Deep Learning vs Neural Network
Acum, fără alte prelungiri, să ne aprofundăm în diferitele tipuri de funcții de activare utilizate în ANN-uri.
Tipuri de funcții de activare
1. Funcția sigmoidă
Într-un ANN, funcția sigmoidă este un AF neliniar utilizat în principal în rețelele neuronale de tip feedforward. Este o funcție reală diferențiabilă, definită pentru valori reale de intrare și care conține derivate pozitive peste tot cu un anumit grad de netezime. Funcția sigmoidă apare în stratul de ieșire al modelelor de învățare profundă și este utilizată pentru prezicerea rezultatelor bazate pe probabilități. Funcția sigmoidă este reprezentată ca:
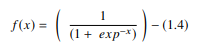
Sursă
În general, derivatele funcției sigmoide sunt aplicate algoritmilor de învățare. Graficul funcției sigmoide are formă de „S”.
Unele dintre dezavantajele majore ale funcției sigmoid includ saturația gradientului, convergența lentă, gradienții ascuțiți de umezeală în timpul propagării inverse de la straturile ascunse mai profunde la straturile de intrare și ieșirea centrată diferită de zero care face ca actualizările gradientului să se propage în direcții diferite.

2. Funcția tangentă hiperbolică (Tanh)
Funcția tangentă hiperbolică, aka, funcția tanh, este un alt tip de AF. Este o funcție mai netedă, centrată pe zero, având un interval între -1 și 1. Ca rezultat, rezultatul funcției tanh este reprezentat de:
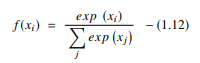
Sursă
Funcția tanh este mult mai utilizată decât funcția sigmoid, deoarece oferă performanțe de antrenament mai bune pentru rețelele neuronale multistrat. Cel mai mare avantaj al funcției tanh este că produce o ieșire centrată pe zero, susținând astfel procesul de retropropagare. Funcția tanh a fost folosită mai ales în rețelele neuronale recurente pentru procesarea limbajului natural și sarcinile de recunoaștere a vorbirii.
Cu toate acestea, și funcția tanh are o limitare - la fel ca și funcția sigmoidă, nu poate rezolva problema gradientului care dispare. De asemenea, funcția tanh poate atinge un gradient de 1 numai atunci când valoarea de intrare este 0 (x este zero). Ca rezultat, funcția poate produce niște neuroni morți în timpul procesului de calcul.
3. Funcția Softmax
Funcția softmax este un alt tip de AF folosit în rețelele neuronale pentru a calcula distribuția probabilității dintr-un vector de numere reale. Această funcție generează o ieșire care variază între valorile 0 și 1 și cu suma probabilităților fiind egală cu 1. Funcția softmax este reprezentată după cum urmează:
Sursă
Această funcție este utilizată în principal în modelele cu mai multe clase, unde returnează probabilitățile fiecărei clase, clasa țintă având cea mai mare probabilitate. Apare în aproape toate straturile de ieșire ale arhitecturii DL unde sunt utilizate. Diferența principală dintre sigmoid și softmax AF este că, în timp ce primul este utilizat în clasificarea binară, cel din urmă este utilizat pentru clasificarea multivariată.
4. Funcția Softsign
Funcția softsign este un alt AF care este utilizat în calculul rețelelor neuronale. Deși este în primul rând în probleme de calcul de regresie, în zilele noastre este folosit și în aplicațiile text-to-speech bazate pe DL. Este un polinom patratic, reprezentat prin:
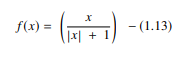
Sursă
Aici „x” este egal cu valoarea absolută a intrării.
Principala diferență dintre funcția softsign și funcția tanh este că, spre deosebire de funcția tanh care converge exponențial, funcția softsign converge într-o formă polinomială.
5. Funcția Rectified Linear Unit (ReLU).
Unul dintre cele mai populare AF din modelele DL, funcția Rectified Linear Unit (ReLU), este un AF cu învățare rapidă, care promite să ofere performanțe de ultimă generație cu rezultate excelente. În comparație cu alte AF, cum ar fi funcțiile sigmoid și tanh, funcția ReLU oferă performanțe mult mai bune și generalizare în învățarea profundă. Funcția este o funcție aproape liniară care păstrează proprietățile modelelor liniare, ceea ce le face ușor de optimizat cu metode de coborâre a gradientului.
Funcția ReLU efectuează o operație de prag pe fiecare element de intrare în care toate valorile mai mici decât zero sunt setate la zero. Astfel, ReLU este reprezentat ca:
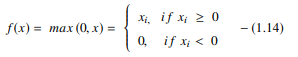
Sursă
Prin rectificarea valorilor intrărilor mai mici decât zero și setarea lor la zero, această funcție elimină problema gradientului de dispariție observată în tipurile anterioare de funcții de activare (sigmoid și tanh).
Cel mai semnificativ avantaj al utilizării funcției ReLU în calcul este că garantează o calcul mai rapidă - nu calculează exponențiale și diviziunile, sporind astfel viteza totală de calcul. Un alt aspect critic al funcției ReLU este că introduce dispersie în unitățile ascunse prin stropirea valorilor între zero și maxim.
6. Funcția de unități liniare exponențiale (ELU).
Funcția de unități liniare exponențiale (ELU) este un AF care este, de asemenea, utilizat pentru a accelera antrenamentul rețelelor neuronale (la fel ca și funcția ReLU). Cel mai mare avantaj al funcției ELU este că poate elimina problema gradientului de dispariție prin utilizarea identității pentru valori pozitive și prin îmbunătățirea caracteristicilor de învățare ale modelului.
ELU-urile au valori negative care împing activarea medie a unității mai aproape de zero, reducând astfel complexitatea de calcul și îmbunătățind viteza de învățare. ELU este o alternativă excelentă la ReLU - scade schimbările de părtinire împingând activarea medie spre zero în timpul procesului de antrenament.
Funcția unitate liniară exponențială este reprezentată ca:
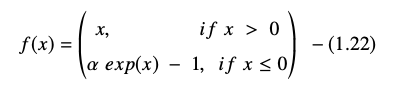
Derivata sau gradientul ecuației ELU este prezentată astfel:
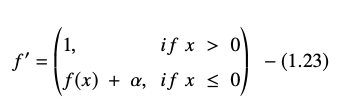
Sursă
Aici „α” este egal cu hiperparametrul ELU care controlează punctul de saturație pentru intrările nete negative, care este de obicei setat la 1,0. Cu toate acestea, funcția ELU are o limitare - nu este centrată pe zero.
Concluzie
Astăzi, AF-uri precum ReLU și ELU au câștigat atenție maximă, deoarece ajută la eliminarea problemei gradientului care dispare care cauzează probleme majore în procesul de antrenament și degradează acuratețea și performanța modelelor de rețele neuronale.
Consultați Programul de certificare avansată în Machine Learning și Cloud cu IIT Madras, cea mai bună școală de inginerie din țară pentru a crea un program care vă învață nu numai învățarea automată, ci și implementarea eficientă a acestuia folosind infrastructura cloud. Scopul nostru cu acest program este de a deschide ușile celui mai selectiv institut din țară și de a oferi cursanților acces la facultăți și resurse uimitoare pentru a stăpâni o abilitate care este în creștere și în creștere.
Ce este o rețea neuronală artificială?
ANN este un model de învățare profundă care este inspirat de structura neuronală a creierului uman. ANN-urile au fost create pentru a reproduce activitățile creierului uman, care învață din experiențele lor și se adaptează la mediul înconjurător. ANN conține o rețea de neuroni care sunt conectați între ei prin axoni, similar modului în care mintea umană are o structură cu mai multe niveluri, cu miliarde de neuroni aranjați într-o ierarhie. Semnalele electrice (numite sinapse) sunt trimise de la un strat la altul de către acești neuroni legați. ANN poate învăța din experiență fără a fi nevoie de implicarea umană datorită acestei aproximări a modelării creierului.
Care sunt funcțiile de activare în rețelele neuronale?
ANN-urile folosesc funcții de activare (AF) în straturile ascunse pentru a efectua calcule complexe și apoi pentru a transfera rezultatele în stratul de ieșire. Scopul de bază al AF este de a oferi rețelei neuronale calități neliniare. Ele transformă semnalele de intrare liniare ale unui nod în semnale de ieșire neliniare pentru a ajuta rețelele profunde să învețe polinoame de ordin înalt cu mai mult de un grad. AF-urile sunt distincte prin faptul că sunt diferențiabile, ceea ce le ajută rolul în timpul propagării inverse a rețelei neuronale.
Care este nevoie de neliniaritate?
Dacă nu sunt utilizate funcții de activare, semnalul de ieșire este o transformare liniară, care este un polinom de un grad. În timp ce ecuațiile liniare sunt simplu de rezolvat, ele au un coeficient de complexitate scăzut, ceea ce le limitează capacitatea de a învăța mapări complicate din date. O rețea neuronală fără AF va fi un model liniar generalizat cu capacități limitate. Acesta nu este genul de performanță pe care o dorim de la o rețea neuronală. Rețelele neuronale sunt folosite pentru a efectua calcule extrem de complexe. În plus, rețelele neuronale nu pot învăța și reprezenta alte date complexe fără AF, cum ar fi fotografii, voce, filme, sunet și așa mai departe.