
6 types de fonction d'activation dans les réseaux de neurones que vous devez connaître
Publié: 2020-02-13Le Deep Learning devenant une technologie courante, on a beaucoup parlé ces derniers temps des RNA ou des réseaux de neurones artificiels. Aujourd'hui, ANN est un composant essentiel dans divers domaines émergents tels que la reconnaissance de l'écriture manuscrite, la compression d'images, la prédiction boursière, et bien plus encore. En savoir plus sur les types de réseaux de neurones artificiels dans l'apprentissage automatique.
Mais qu'est-ce qu'un réseau de neurones artificiels ?
Le réseau de neurones artificiels est un modèle d'apprentissage en profondeur qui s'inspire de la structure neuronale du cerveau humain. Les RNA ont été conçus pour imiter les fonctions du cerveau humain qui apprennent des expériences et s'adaptent en conséquence à la situation. Comme le cerveau humain a une structure à plusieurs niveaux contenant des milliards de neurones disposés dans une hiérarchie, ANN a également un réseau de neurones qui sont interconnectés les uns aux autres via des axones.
Ces neurones interconnectés transmettent des signaux électriques (appelés synapses) d'une couche à l'autre. Cette imitation de la modélisation du cerveau permet à l'ANN d'apprendre de l'expérience sans nécessiter d'intervention humaine.
Lire : Réseau de neurones artificiels dans l'exploration de données
Ainsi, les ANN sont des structures complexes contenant des éléments adaptatifs interconnectés connus sous le nom de neurones artificiels qui peuvent effectuer de grands calculs pour la représentation des connaissances. Ils possèdent toutes les qualités fondamentales du système neuronal biologique, y compris la capacité d'apprentissage, la robustesse, la non-linéarité, le parallélisme élevé, la tolérance aux pannes et aux pannes, la capacité à gérer des informations imprécises et floues et la capacité de généralisation.

Rejoignez les cours d'intelligence artificielle en ligne des meilleures universités du monde - Masters, Executive Post Graduate Programs et Advanced Certificate Program in ML & AI pour accélérer votre carrière.
Table des matières
Principales caractéristiques des réseaux de neurones artificiels
- La non-linéarité donne un meilleur ajustement aux données.
- Un parallélisme élevé favorise un traitement rapide et une tolérance aux pannes matérielles.
- La généralisation permet l'application du modèle à des données non apprises.
- Insensibilité au bruit qui permet une prédiction précise même pour des données incertaines et des erreurs de mesure.
- L'apprentissage et l'adaptabilité permettent au modèle de mettre à jour son architecture interne en fonction de l'évolution de l'environnement.
L'informatique basée sur les ANN vise principalement à concevoir des algorithmes mathématiques avancés qui permettent aux réseaux de neurones artificiels d'apprendre en imitant les fonctions de traitement de l'information et d'acquisition des connaissances du cerveau humain.
Composants des réseaux de neurones artificiels
Les ANN sont composés de trois couches ou phases principales - une couche d'entrée, une ou plusieurs couches cachées et une couche de sortie.
- Couche d'entrée : la première couche est alimentée par l'entrée, c'est-à-dire les données brutes. Il transmet les informations du monde extérieur au réseau. Dans cette couche, aucun calcul n'est effectué - les nœuds transmettent simplement les informations à la couche cachée.
- Couche cachée : dans cette couche, les nœuds sont cachés derrière la couche d'entrée - ils comprennent la partie d'abstraction dans chaque réseau de neurones. Tous les calculs sur les entités saisies via la couche d'entrée se produisent dans la ou les couches cachées, puis transfèrent le résultat à la couche de sortie.
- Couche de sortie : cette couche décrit les résultats des calculs effectués par le réseau vers le monde extérieur.
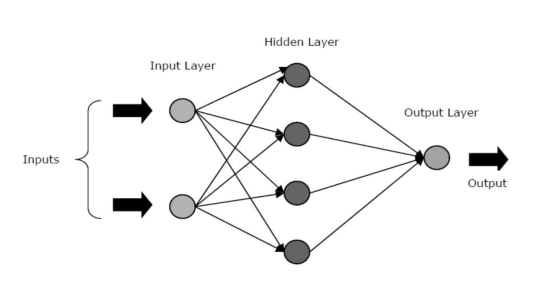
La source
Les réseaux de neurones peuvent être classés en différents types en fonction de l'activité de la ou des couches cachées. Par exemple, dans un réseau neuronal simple, les unités cachées peuvent construire leur représentation unique de l'entrée. Ici, les poids entre les unités cachées et d'entrée décident quand chaque unité cachée est active.
Ainsi, en ajustant ces poids, la couche cachée peut choisir ce qu'elle doit représenter. D'autres architectures incluent les modèles monocouche et multicouche. Dans une seule couche, il n'y a généralement qu'une couche d'entrée et de sortie - il manque une couche cachée. Alors que, dans un modèle multicouche, il y a une ou plusieurs couches cachées.
Que sont les fonctions d'activation dans un réseau de neurones ?
Comme nous l'avons mentionné précédemment, les RNA sont un élément crucial de nombreuses structures qui contribuent à révolutionner le monde qui nous entoure. Mais vous êtes-vous déjà demandé comment les ANN offrent des performances de pointe pour trouver des solutions aux problèmes du monde réel ?
La réponse est - Fonctions d'activation.
Les ANN utilisent des fonctions d'activation (AF) pour effectuer des calculs complexes dans les couches cachées, puis transfèrent le résultat à la couche de sortie. L'objectif principal des AF est d'introduire des propriétés non linéaires dans le réseau de neurones.
Ils convertissent les signaux d'entrée linéaires d'un nœud en signaux de sortie non linéaires pour faciliter l'apprentissage de polynômes d'ordre élevé allant au-delà d'un degré pour les réseaux profonds. Un aspect unique des AF est qu'ils sont différenciables - cela les aide à fonctionner pendant la rétropropagation des réseaux de neurones.
Quel est le besoin de non-linéarité ?
Si les fonctions d'activation ne sont pas appliquées, le signal de sortie serait une fonction linéaire, qui est un polynôme d'un degré. Bien qu'il soit facile de résoudre des équations linéaires, elles ont un quotient de complexité limité et, par conséquent, ont moins de pouvoir pour apprendre des mappages fonctionnels complexes à partir de données. Ainsi, sans AF, un réseau de neurones serait un modèle de régression linéaire aux capacités limitées.
Ce n'est certainement pas ce que nous attendons d'un réseau de neurones. La tâche des réseaux de neurones est de calculer des calculs très compliqués. De plus, sans AF, les réseaux de neurones ne peuvent pas apprendre et modéliser d'autres données complexes, notamment les images, la parole, les vidéos, l'audio, etc.
Les AF aident les réseaux de neurones à donner un sens aux ensembles de Big Data complexes, de grande dimension et non linéaires qui ont une architecture complexe - ils contiennent plusieurs couches cachées entre la couche d'entrée et la couche de sortie.
Lire : Apprentissage en profondeur contre réseau de neurones
Maintenant, sans plus tarder, plongeons dans les différents types de fonctions d'activation utilisées dans les ANN.
Types de fonctions d'activation
1. Fonction sigmoïde
Dans un ANN, la fonction sigmoïde est une AF non linéaire utilisée principalement dans les réseaux de neurones à anticipation. Il s'agit d'une fonction réelle différentiable, définie pour des valeurs d'entrée réelles et contenant des dérivées positives partout avec un degré spécifique de lissage. La fonction sigmoïde apparaît dans la couche de sortie des modèles d'apprentissage en profondeur et est utilisée pour prédire les sorties basées sur la probabilité. La fonction sigmoïde est représentée par :
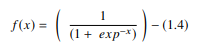
La source
Généralement, les dérivées de la fonction sigmoïde sont appliquées à des algorithmes d'apprentissage. Le graphique de la fonction sigmoïde est en forme de 'S'.
Certains des principaux inconvénients de la fonction sigmoïde incluent la saturation du gradient, la convergence lente, les gradients d'humidité prononcés lors de la rétropropagation depuis les couches cachées plus profondes vers les couches d'entrée et la sortie centrée non nulle qui provoque la propagation des mises à jour du gradient dans des directions variables.

2. Fonction tangente hyperbolique (Tanh)
La fonction tangente hyperbolique, alias la fonction tanh, est un autre type d'AF. Il s'agit d'une fonction plus lisse, centrée sur zéro, comprise entre -1 et 1. Par conséquent, la sortie de la fonction tanh est représentée par :
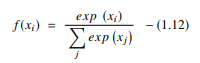
La source
La fonction tanh est beaucoup plus largement utilisée que la fonction sigmoïde car elle offre de meilleures performances d'entraînement pour les réseaux de neurones multicouches. Le plus grand avantage de la fonction tanh est qu'elle produit une sortie centrée sur zéro, prenant ainsi en charge le processus de rétropropagation. La fonction tanh a été principalement utilisée dans les réseaux de neurones récurrents pour les tâches de traitement du langage naturel et de reconnaissance de la parole.
Cependant, la fonction tanh a également une limitation - tout comme la fonction sigmoïde, elle ne peut pas résoudre le problème du gradient de fuite. De plus, la fonction tanh ne peut atteindre un gradient de 1 que lorsque la valeur d'entrée est 0 (x est zéro). En conséquence, la fonction peut produire des neurones morts pendant le processus de calcul.
3. Fonction Softmax
La fonction softmax est un autre type d'AF utilisé dans les réseaux de neurones pour calculer la distribution de probabilité à partir d'un vecteur de nombres réels. Cette fonction génère une sortie comprise entre les valeurs 0 et 1 et la somme des probabilités étant égale à 1. La fonction softmax est représentée comme suit :
La source
Cette fonction est principalement utilisée dans les modèles multi-classes où elle renvoie les probabilités de chaque classe, la classe cible ayant la probabilité la plus élevée. Il apparaît dans presque toutes les couches de sortie de l'architecture DL où ils sont utilisés. La principale différence entre le sigmoïde et le softmax AF est que, tandis que le premier est utilisé dans la classification binaire, le second est utilisé pour la classification multivariée.
4. Fonction de signature logicielle
La fonction softsign est un autre AF utilisé dans l'informatique de réseau neuronal. Bien qu'il soit principalement utilisé dans les problèmes de calcul de régression, il est également utilisé de nos jours dans les applications de synthèse vocale basées sur DL. C'est un polynôme quadratique, représenté par :
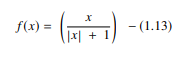
La source
Ici, "x" est égal à la valeur absolue de l'entrée.
La principale différence entre la fonction softsign et la fonction tanh est que, contrairement à la fonction tanh qui converge de manière exponentielle, la fonction softsign converge sous une forme polynomiale.
5. Fonction d'unité linéaire rectifiée (ReLU)
L'un des AF les plus populaires des modèles DL, la fonction d'unité linéaire rectifiée (ReLU), est un AF à apprentissage rapide qui promet d'offrir des performances de pointe avec des résultats exceptionnels. Par rapport à d'autres AF comme les fonctions sigmoïde et tanh, la fonction ReLU offre de bien meilleures performances et généralisation dans l'apprentissage en profondeur. La fonction est une fonction presque linéaire qui conserve les propriétés des modèles linéaires, ce qui les rend faciles à optimiser avec des méthodes de descente de gradient.
La fonction ReLU effectue une opération de seuil sur chaque élément d'entrée où toutes les valeurs inférieures à zéro sont définies sur zéro. Ainsi, le ReLU est représenté par :
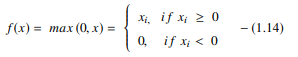
La source
En rectifiant les valeurs des entrées inférieures à zéro et en les mettant à zéro, cette fonction élimine le problème de gradient de fuite observé dans les types antérieurs de fonctions d'activation (sigmoïde et tanh).
L'avantage le plus important de l'utilisation de la fonction ReLU dans le calcul est qu'elle garantit un calcul plus rapide - elle ne calcule pas les exponentielles et les divisions, augmentant ainsi la vitesse de calcul globale. Un autre aspect critique de la fonction ReLU est qu'elle introduit de la parcimonie dans les unités cachées en écrasant les valeurs entre zéro et le maximum.
6. Fonction des unités linéaires exponentielles (ELU)
La fonction d'unités linéaires exponentielles (ELU) est un AF qui est également utilisé pour accélérer la formation des réseaux de neurones (tout comme la fonction ReLU). Le plus grand avantage de la fonction ELU est qu'elle peut éliminer le problème du gradient de fuite en utilisant l'identité pour les valeurs positives et en améliorant les caractéristiques d'apprentissage du modèle.
Les ELU ont des valeurs négatives qui rapprochent l'activation unitaire moyenne de zéro, réduisant ainsi la complexité de calcul et améliorant la vitesse d'apprentissage. L'ELU est une excellente alternative au ReLU - il diminue les décalages de biais en poussant l'activation moyenne vers zéro pendant le processus d'apprentissage.
La fonction d'unité linéaire exponentielle est représentée par :
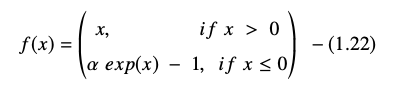
La dérivée ou gradient de l'équation ELU est présentée comme suit :
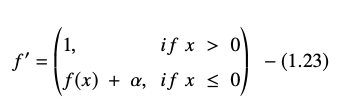
La source
Ici, "α" est égal à l'hyperparamètre ELU qui contrôle le point de saturation pour les entrées nettes négatives, qui est généralement défini sur 1,0. Cependant, la fonction ELU a une limitation - elle n'est pas centrée sur zéro.
Conclusion
Aujourd'hui, les AF comme ReLU et ELU ont attiré une attention maximale car ils aident à éliminer le problème du gradient de fuite qui cause des problèmes majeurs dans le processus de formation et dégrade la précision et les performances des modèles de réseaux neuronaux.
Découvrez le programme de certification avancée en apprentissage automatique et cloud avec IIT Madras, la meilleure école d'ingénieurs du pays, pour créer un programme qui vous enseigne non seulement l'apprentissage automatique, mais également son déploiement efficace à l'aide de l'infrastructure cloud. Notre objectif avec ce programme est d'ouvrir les portes de l'institut le plus sélectif du pays et de donner aux apprenants l'accès à des professeurs et à des ressources incroyables afin de maîtriser une compétence en forte croissance.
Qu'est-ce qu'un réseau de neurones artificiels ?
L'ANN est un modèle d'apprentissage en profondeur qui s'inspire de la structure neuronale du cerveau humain. Les RNA ont été créés pour reproduire les activités du cerveau humain, qui apprend de ses expériences et s'adapte à son environnement. ANN contient un réseau de neurones qui sont connectés les uns aux autres par des axones, de la même manière que l'esprit humain a une structure à plusieurs niveaux avec des milliards de neurones disposés en hiérarchie. Des signaux électriques (appelés synapses) sont envoyés d'une couche à l'autre par ces neurones reliés. L'ANN peut apprendre de l'expérience sans avoir besoin d'intervention humaine grâce à cette approximation de la modélisation du cerveau.
Quelles sont les fonctions d'activation dans les réseaux de neurones ?
Les ANN utilisent des fonctions d'activation (AF) dans les couches cachées pour effectuer des calculs complexes, puis transférer les résultats vers la couche de sortie. L'objectif fondamental des AF est de donner au réseau de neurones des qualités non linéaires. Ils transforment les signaux d'entrée linéaires d'un nœud en signaux de sortie non linéaires pour aider les réseaux profonds à apprendre des polynômes d'ordre élevé à plus d'un degré. Les AF sont distincts en ce qu'ils sont différentiables, ce qui facilite leur rôle lors de la rétropropagation du réseau neuronal.
Quel est le besoin de non-linéarité ?
Si aucune fonction d'activation n'est utilisée, le signal de sortie est une transformation linéaire, qui est un polynôme à un degré. Bien que les équations linéaires soient simples à résoudre, elles ont un faible quotient de complexité, ce qui limite leur capacité à apprendre des mappages complexes à partir de données. Un réseau de neurones sans AF sera un modèle linéaire généralisé avec des capacités limitées. Ce n'est pas le genre de performance que nous attendons d'un réseau de neurones. Les réseaux de neurones sont utilisés pour effectuer des calculs extrêmement complexes. De plus, les réseaux de neurones ne peuvent pas apprendre et représenter d'autres données complexes sans AF, telles que les photos, la voix, les films, l'audio, etc.