
6 tipos de função de ativação em redes neurais que você precisa conhecer
Publicados: 2020-02-13Com o Deep Learning se tornando uma tecnologia mainstream, ultimamente, tem havido muita conversa sobre ANNs ou Redes Neurais Artificiais. Hoje, a ANN é um componente central em diversos domínios emergentes, como reconhecimento de manuscrito, compactação de imagem, previsão de bolsa de valores e muito mais. Leia mais sobre tipos de redes neurais artificiais em aprendizado de máquina.
Mas o que é uma Rede Neural Artificial?
A Rede Neural Artificial é um modelo de Deep Learning que se inspira na estrutura neural do cérebro humano. As RNAs foram projetadas para imitar as funções do cérebro humano que aprendem com as experiências e se adaptam de acordo com a situação. Assim como o cérebro humano possui uma estrutura multicamadas contendo bilhões de neurônios dispostos em uma hierarquia, a RNA também possui uma rede de neurônios que são interconectados entre si por meio de axônios.
Esses neurônios interconectados passam sinais elétricos (chamados sinapses) de uma camada para outra. Essa imitação da modelagem cerebral permite que a RNA aprenda com a experiência sem exigir intervenção humana.
Leia: Rede Neural Artificial em Mineração de Dados
Assim, as RNAs são estruturas complexas contendo elementos adaptativos interconectados conhecidos como neurônios artificiais que podem realizar grandes cálculos para representação do conhecimento. Eles possuem todas as qualidades fundamentais do sistema de neurônios biológicos, incluindo capacidade de aprendizado, robustez, não linearidade, alto paralelismo, tolerância a falhas e falhas, capacidade de lidar com informações imprecisas e difusas e capacidade de generalização.

Participe dos Cursos de Inteligência Artificial on-line das principais universidades do mundo - Mestrados, Programas de Pós-Graduação Executiva e Programa de Certificado Avançado em ML e IA para acelerar sua carreira.
Índice
Principais Características das Redes Neurais Artificiais
- A não linearidade confere um melhor ajuste aos dados.
- O alto paralelismo promove processamento rápido e tolerância a falhas de hardware.
- A generalização permite a aplicação do modelo a dados não aprendidos.
- Insensibilidade ao ruído que permite uma previsão precisa mesmo para dados incertos e erros de medição.
- O aprendizado e a adaptabilidade permitem que o modelo atualize sua arquitetura interna de acordo com o ambiente em mudança.
A computação baseada em ANN visa principalmente projetar algoritmos matemáticos avançados que permitem que as redes neurais artificiais aprendam imitando as funções de processamento de informações e aquisição de conhecimento do cérebro humano.
Componentes de Redes Neurais Artificiais
As RNAs são compostas por três camadas ou fases principais – uma camada de entrada, camada/s ocultas e uma camada de saída.
- Camada de Entrada: A primeira camada é alimentada com a entrada, ou seja, dados brutos. Ele transmite as informações do mundo exterior para a rede. Nesta camada, nenhum cálculo é realizado – os nós apenas passam a informação para a camada oculta.
- Camada Oculta: Nesta camada, os nós ficam escondidos atrás da camada de entrada – eles compreendem a parte de abstração em cada rede neural. Todos os cálculos das feições inseridas pela camada de entrada ocorrem na(s) camada(s) oculta(s) e, então, transfere o resultado para a camada de saída.
- Camada de Saída: Esta camada descreve os resultados dos cálculos realizados pela rede para o mundo exterior.
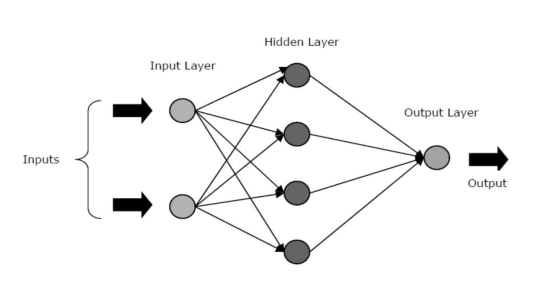
Fonte
As redes neurais podem ser categorizadas em diferentes tipos com base na atividade da(s) camada(s) oculta(s). Por exemplo, em uma rede neural simples, as unidades ocultas podem construir sua representação única da entrada. Aqui, os pesos entre as unidades ocultas e de entrada decidem quando cada unidade oculta está ativa.
Assim, ajustando esses pesos, a camada oculta pode escolher o que deve representar. Outras arquiteturas incluem os modelos de camada única e multicamadas. Em uma única camada, geralmente há apenas uma camada de entrada e saída – falta uma camada oculta. Considerando que, em um modelo multicamadas, há uma ou mais camadas ocultas.
O que são funções de ativação em uma rede neural?
Como mencionamos anteriormente, as RNAs são um componente crucial de muitas estruturas que estão ajudando a revolucionar o mundo ao nosso redor. Mas você já se perguntou como as RNAs oferecem desempenho de última geração para encontrar soluções para problemas do mundo real?
A resposta é – Funções de ativação.
As RNAs usam funções de ativação (AFs) para realizar cálculos complexos nas camadas ocultas e depois transferir o resultado para a camada de saída. O objetivo principal dos AFs é introduzir propriedades não lineares na rede neural.
Eles convertem os sinais de entrada linear de um nó em sinais de saída não lineares para facilitar o aprendizado de polinômios de alta ordem que vão além de um grau para redes profundas. Um aspecto único dos AFs é que eles são diferenciáveis – isso os ajuda a funcionar durante a retropropagação das redes neurais.
Qual é a necessidade de não linearidade?
Se as funções de ativação não forem aplicadas, o sinal de saída seria uma função linear, que é um polinômio de um grau. Embora seja fácil resolver equações lineares, elas têm um quociente de complexidade limitado e, portanto, têm menos poder para aprender mapeamentos funcionais complexos a partir de dados. Assim, sem AFs, uma rede neural seria um modelo de regressão linear com habilidades limitadas.
Isso certamente não é o que queremos de uma rede neural. A tarefa das redes neurais é computar cálculos altamente complicados. Além disso, sem AFs, as redes neurais não podem aprender e modelar outros dados complicados, incluindo imagens, fala, vídeos, áudio etc.
Os AFs ajudam as redes neurais a entender conjuntos de Big Data complicados, de alta dimensão e não lineares que possuem uma arquitetura complexa – eles contêm várias camadas ocultas entre as camadas de entrada e saída.
Leia: Deep Learning vs Rede Neural
Agora, sem mais delongas, vamos mergulhar nos diferentes tipos de funções de ativação usadas nas RNAs.
Tipos de funções de ativação
1. Função sigmóide
Em uma RNA, a função sigmóide é um AF não linear usado principalmente em redes neurais feedforward. É uma função real diferenciável, definida para valores reais de entrada, e contendo derivadas positivas em todos os lugares com um grau específico de suavidade. A função sigmóide aparece na camada de saída dos modelos de aprendizado profundo e é usada para prever saídas baseadas em probabilidade. A função sigmóide é representada como:
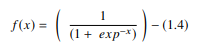
Fonte
Geralmente, as derivadas da função sigmóide são aplicadas a algoritmos de aprendizado. O gráfico da função sigmóide tem a forma de 'S'.
Algumas das principais desvantagens da função sigmóide incluem saturação de gradiente, convergência lenta, gradientes úmidos nítidos durante a retropropagação de camadas ocultas mais profundas para as camadas de entrada e saída centrada diferente de zero que faz com que as atualizações de gradiente se propaguem em direções variadas.

2. Função Tangente Hiperbólica (Tanh)
A função tangente hiperbólica, também conhecida como função tanh, é outro tipo de AF. É uma função mais suave e centrada em zero com um intervalo entre -1 e 1. Como resultado, a saída da função tanh é representada por:
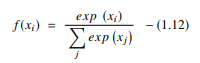
Fonte
A função tanh é muito mais usada do que a função sigmoid, pois oferece melhor desempenho de treinamento para redes neurais multicamadas. A maior vantagem da função tanh é que ela produz uma saída centrada em zero, suportando assim o processo de retropropagação. A função tanh tem sido usada principalmente em redes neurais recorrentes para processamento de linguagem natural e tarefas de reconhecimento de fala.
No entanto, a função tanh também tem uma limitação – assim como a função sigmóide, ela não pode resolver o problema do gradiente de fuga. Além disso, a função tanh só pode atingir um gradiente de 1 quando o valor de entrada for 0 (x é zero). Como resultado, a função pode produzir alguns neurônios mortos durante o processo de computação.
3. Função Softmax
A função softmax é outro tipo de AF usado em redes neurais para calcular a distribuição de probabilidade a partir de um vetor de números reais. Esta função gera uma saída que varia entre os valores 0 e 1 e com a soma das probabilidades igual a 1. A função softmax é representada da seguinte forma:
Fonte
Esta função é usada principalmente em modelos multiclasse onde ela retorna probabilidades de cada classe, com a classe alvo tendo a maior probabilidade. Ele aparece em quase todas as camadas de saída da arquitetura DL onde são utilizados. A principal diferença entre o sigmoid e o softmax AF é que enquanto o primeiro é usado na classificação binária, o último é usado na classificação multivariada.
4. Função Softsign
A função softsign é outro AF usado na computação de redes neurais. Embora seja principalmente em problemas de computação de regressão, hoje em dia também é usado em aplicativos de conversão de texto em voz baseados em DL. É um polinômio quadrático, representado por:
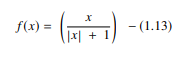
Fonte
Aqui “x” é igual ao valor absoluto da entrada.
A principal diferença entre a função softsign e a função tanh é que ao contrário da função tanh que converge exponencialmente, a função softsign converge em uma forma polinomial.
5. Função de Unidade Linear Retificada (ReLU)
Um dos AFs mais populares em modelos DL, a função de unidade linear retificada (ReLU), é um AF de aprendizado rápido que promete oferecer desempenho de última geração com resultados estelares. Em comparação com outros AFs, como as funções sigmoid e tanh, a função ReLU oferece desempenho e generalização muito melhores em aprendizado profundo. A função é uma função quase linear que retém as propriedades dos modelos lineares, o que os torna fáceis de otimizar com métodos gradientes-descendentes.
A função ReLU executa uma operação de limite em cada elemento de entrada em que todos os valores menores que zero são definidos como zero. Assim, o ReLU é representado como:
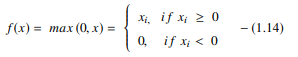
Fonte
Ao retificar os valores das entradas menores que zero e defini-los como zero, esta função elimina o problema do gradiente de fuga observado nos tipos anteriores de funções de ativação (sigmoid e tanh).
A vantagem mais significativa de usar a função ReLU na computação é que ela garante uma computação mais rápida – ela não calcula exponenciais e divisões, aumentando assim a velocidade geral de computação. Outro aspecto crítico da função ReLU é que ela introduz esparsidade nas unidades ocultas espremendo os valores entre zero e o máximo.
6. Função de Unidades Lineares Exponenciais (ELUs)
A função de unidades lineares exponenciais (ELUs) é um AF que também é usado para acelerar o treinamento de redes neurais (assim como a função ReLU). A maior vantagem da função ELU é que ela pode eliminar o problema do gradiente de fuga usando identidade para valores positivos e melhorando as características de aprendizado do modelo.
As ELUs têm valores negativos que aproximam a ativação da unidade média de zero, reduzindo assim a complexidade computacional e melhorando a velocidade de aprendizado. O ELU é uma excelente alternativa ao ReLU – ele diminui os desvios de polarização ao empurrar a ativação média para zero durante o processo de treinamento.
A função de unidade linear exponencial é representada como:
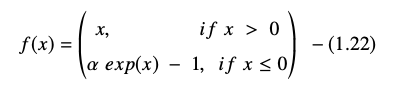
A derivada ou gradiente da equação ELU é apresentada como:
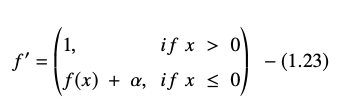
Fonte
Aqui, “α” é igual ao hiperparâmetro ELU que controla o ponto de saturação para entradas líquidas negativas, que geralmente é definido como 1,0. No entanto, a função ELU tem uma limitação – não é centrada em zero.
Conclusão
Hoje, AFs como ReLU e ELU ganharam atenção máxima, pois ajudam a eliminar o problema do gradiente de fuga que causa grandes problemas no treinamento do processo de treinamento e degrada a precisão e o desempenho dos modelos de rede neural.
Confira Programa de Certificação Avançada em Machine Learning & Cloud com o IIT Madras, a melhor escola de engenharia do país para criar um programa que ensine não apenas machine learning, mas também a implantação efetiva do mesmo usando a infraestrutura em nuvem. Nosso objetivo com este programa é abrir as portas do instituto mais seletivo do país e dar aos alunos acesso a incríveis professores e recursos para dominar uma habilidade que está em alta e em crescimento
O que é uma rede neural artificial?
A RNA é um modelo de Deep Learning inspirado na estrutura neural do cérebro humano. As RNAs foram criadas para replicar as atividades do cérebro humano, que aprendem com suas experiências e se adaptam ao ambiente. A RNA contém uma rede de neurônios que estão conectados uns aos outros por axônios, semelhante à forma como a mente humana tem uma estrutura de várias camadas com bilhões de neurônios organizados em uma hierarquia. Sinais elétricos (chamados sinapses) são enviados de uma camada para outra por esses neurônios ligados. A RNA pode aprender com a experiência sem a necessidade de envolvimento humano graças a essa aproximação da modelagem cerebral.
O que são funções de ativação em redes neurais?
As RNAs empregam funções de ativação (AFs) nas camadas ocultas para realizar cálculos complexos e depois transferir os resultados para a camada de saída. O objetivo básico dos AFs é fornecer qualidades não lineares à rede neural. Eles transformam os sinais de entrada linear de um nó em sinais de saída não lineares para ajudar as redes profundas a aprender polinômios de alta ordem com mais de um grau. Os AFs são distintos por serem diferenciáveis, o que auxilia seu papel durante a retropropagação da rede neural.
Qual é a necessidade de não linearidade?
Se nenhuma função de ativação for usada, o sinal de saída é uma transformação linear, que é um polinômio de um grau. Embora as equações lineares sejam simples de resolver, elas têm um quociente de baixa complexidade, o que limita sua capacidade de aprender mapeamentos complicados a partir de dados. Uma rede neural sem AFs será um modelo linear generalizado com capacidades limitadas. Este não é o tipo de desempenho que queremos de uma rede neural. As redes neurais são usadas para realizar cálculos extremamente complexos. Além disso, as redes neurais não podem aprender e representar outros dados complexos sem AFs, como fotos, voz, filmes, áudio e assim por diante.