
คลังข้อมูลและการทำเหมืองข้อมูลคืออะไร
เผยแพร่แล้ว: 2018-02-22ข้อมูลองค์กรถูกเก็บไว้ในไซโลข้อมูลที่แยกออกจากที่เก็บข้อมูลอื่น ๆ และไซโลแต่ละอันทำหน้าที่พิเศษ – แต่นั่นคือก่อนที่บิ๊กดาต้าจะโจมตีโลก (ถ้าเราอาจพูดโดยพายุ) ตอนนี้ แทบจะเป็นไปไม่ได้เลยที่จะฝึกฝนวิธีการเดียวกันกับชุดข้อมูลขนาดใหญ่เช่นนี้ ลองนึกภาพจำนวนการดึงข้อมูลที่ต้องใช้จากไซโลข้อมูลที่แยกจากกันจำนวนมาก - เพียงเพื่อเรียกใช้แบบสอบถามง่ายๆ ต้องขอบคุณกองข้อมูลจำนวนมหาศาลที่อยู่ในองค์กรและวิธีการวิศวกรรมข้อมูลขนาดใหญ่
มาดูกันว่า Data Warhousing และ Data mining เข้ามามีบทบาทอย่างไร คลังข้อมูลได้รับการพัฒนาเพื่อต่อสู้กับปัญหาการจัดเก็บข้อมูลนี้ โดยพื้นฐานแล้ว Data Warehouses สามารถถูกมองว่าเป็นที่เก็บข้อมูลแบบรวมศูนย์ของข้อมูลที่มาจากแหล่งต่างๆ และอยู่ในรูปแบบต่างๆ ในทางกลับกัน Data Mining เป็นกระบวนการดึงความรู้จาก Data Warehouse ดังกล่าว
ในบทความนี้ เราจะมาดูรายละเอียดเกี่ยวกับ Data Warehouse และ Data Mining เพื่อความเข้าใจที่ดีขึ้น เราได้จัดโครงสร้างบทความดังนี้:
- คลังข้อมูลคืออะไร?
- กระบวนการคลังข้อมูล
- การทำเหมืองข้อมูลคืออะไร?
- กระบวนการ KDD
- กรณีการใช้งานจริงของการขุดข้อมูล
สารบัญ
คลังข้อมูลคืออะไร?
หากเราจะ กำหนด Data Warehouse ก็สามารถอธิบายได้ว่าเป็นการรวบรวมข้อมูลแบบบูรณาการที่มุ่งเน้นเรื่อง ตัวแปรเวลา ไม่ผันผวน การแนะนำ Data Warehousing ยังประกอบด้วยข้อมูลที่รวบรวมจากแหล่งภายนอก จุดประสงค์ของการออกแบบคลังสินค้าคือการวิเคราะห์และกระตุ้นการตัดสินใจทางธุรกิจโดยการรายงานข้อมูลในระดับรวมที่แตกต่างกัน ก่อนที่จะไปต่อจากนี้ มาดูความหมายของคำศัพท์เหล่านี้ในบริบทของ Data Warehouse ก่อน:
หัวเรื่อง-Oriented
องค์กรสามารถใช้ Data Warehouse เพื่อวิเคราะห์หัวข้อเฉพาะ สมมติว่าคุณต้องการดูว่าทีมขายของคุณมีผลงานได้ดีเพียงใดในช่วง 5 ปีที่ผ่านมา คุณสามารถสอบถาม Warehouse ของคุณได้ และมันจะบอกคุณทุกสิ่งที่คุณจำเป็นต้องรู้ ในกรณีนี้ “การขาย” สามารถถือเป็นเรื่องได้
ตัวแปรเวลา
Data Warehouses มีหน้าที่จัดเก็บข้อมูลในอดีตสำหรับองค์กร ตัวอย่างเช่น ระบบธุรกรรมสามารถเก็บที่อยู่ล่าสุดของลูกค้าได้ แต่ Data Warehouse จะเก็บที่อยู่ก่อนหน้านี้ทั้งหมดด้วย มันคอยเพิ่มข้อมูลจากแหล่งต่าง ๆ อย่างต่อเนื่อง นอกเหนือจากการเก็บข้อมูลในอดีต นั่นคือสิ่งที่ทำให้เป็นแบบจำลองแปรผันตามเวลา ข้อมูลที่เก็บไว้จะแปรผันตามเวลาเสมอ
ไม่ระเหย
เมื่อข้อมูลถูกเก็บไว้ในคลังข้อมูลแล้ว จะไม่สามารถเปลี่ยนแปลงหรือแก้ไขได้ เราสามารถเพิ่มได้เฉพาะสำเนาที่แก้ไขของข้อมูลที่เราต้องการแก้ไขเท่านั้น
แบบบูรณาการ:
ดังที่เราได้กล่าวไว้ก่อนหน้านี้ Data Warehouse เก็บข้อมูลจากหลายแหล่ง สมมติว่าเรามีแหล่งข้อมูลสองแห่ง – A และ B แหล่งข้อมูลทั้งสองอาจมีประเภทข้อมูลที่แตกต่างกันโดยสิ้นเชิงที่เก็บอยู่ในนั้น แต่เมื่อถูกนำไปยัง Warehouse แหล่งข้อมูลเหล่านั้นจะถูกประมวลผลล่วงหน้า นั่นคือวิธีที่ Data Warehouse รวมข้อมูลจากแหล่งที่มาจำนวนหนึ่ง
กระบวนการคลังข้อมูล
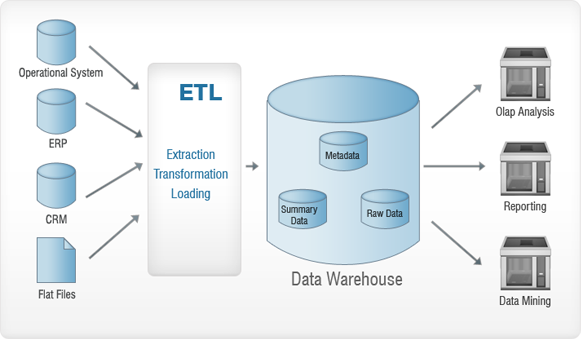
ลองดูที่ภาพด้านบน ข้อมูลที่รวบรวมจากแหล่งต่างๆ (ระบบปฏิบัติการ, ERP, CRM, Flat Files ฯลฯ) ถูกสร้างให้เข้าสู่กระบวนการ ETL ก่อนจะถูกแทรกเข้าไปในคลังข้อมูล โดยพื้นฐานแล้วจะทำเพื่อลบความผิดปกติ หากมี ออกจากข้อมูล เพื่อไม่ให้เกิดอันตรายต่อคลังข้อมูล ETL ย่อมาจาก – Extraction, Transformation และ Loading. มาดูรายละเอียดแต่ละกระบวนการเหล่านี้กันดีกว่า เพื่อให้เข้าใจมากขึ้น เราจะใช้การเปรียบเทียบ - ลองนึกถึงยุคตื่นทองและอ่านต่อ!
การสกัด
การสกัดจะดำเนินการโดยพื้นฐานแล้วเพื่อรวบรวมข้อมูลที่จำเป็นทั้งหมดจากระบบต้นทางโดยใช้ทรัพยากรน้อยที่สุด
ลองนึกถึงขั้นตอนนี้เหมือนกับการร่อนในแม่น้ำเพื่อค้นหาทองคำก้อนใหญ่ ที่สุด
การแปลงร่าง
จุดประสงค์หลักคือการแทรกข้อมูลที่แยกออกมาในฐานข้อมูลในรูปแบบทั่วไป ทั้งนี้เนื่องจากแหล่งข้อมูลต่างๆ จะมีรูปแบบการจัดเก็บข้อมูลที่แตกต่างกัน ตัวอย่างเช่น แหล่งข้อมูลหนึ่งอาจมีข้อมูลในรูปแบบ "วว/ดด/ปปปป" และอีกแหล่งหนึ่งอาจมีรูปแบบ "วว-ดด-ปปปป" ในขั้นตอนนี้ เราจะแปลงเป็นรูปแบบทั่วไป ซึ่งจะใช้สำหรับข้อมูลจากแหล่งที่มาทั้งหมด
ตอนนี้คุณมีก้อนทองคำ คุณทำงานอะไร? ละลายมันลงและเอาสิ่งสกปรกออก
กำลังโหลด
ในขั้นตอนนี้ ข้อมูลที่แปลงแล้วจะถูกโหลดลงในฐานข้อมูลเป้าหมาย
ตอนนี้คุณมีทองคำบริสุทธิ์แล้ว ปั้นเป็นแหวนแล้วขายทิ้ง!
กระบวนการนำข้อมูลจากแหล่งต่าง ๆ และจัดเก็บไว้ใน Data Warehouse (แน่นอนว่าหลังจากกระบวนการ ETL) คือสิ่งที่เรียกว่า Data Warehousing
ตอนนี้ คุณมีข้อมูลของคุณพร้อมแล้ว – ทั้งหมดถูกล้างและพร้อมที่จะไป ขั้นตอนต่อไปควรเป็นอย่างไร? ดึงความรู้ – ใช่!
การขุดข้อมูลเพื่อช่วยเหลือ!
คุณจะเปลี่ยนไปใช้ Data Analytics ได้อย่างไรการทำเหมืองข้อมูลคืออะไร?
การทำเหมืองข้อมูลเป็นกระบวนการง่ายๆ ในการดึงข้อมูลที่ไม่รู้จักมาก่อนแต่อาจมีประโยชน์จากชุดข้อมูล โดย "ไม่ทราบก่อนหน้านี้" เราหมายถึงความรู้ที่สามารถหามาได้หลังจากการขุดค้นคลังข้อมูลอย่างล้ำลึกเท่านั้น กล่าวคือ มันไม่สมเหตุสมผลเลย การทำเหมืองข้อมูลโดยพื้นฐานแล้วจะค้นหารูปแบบความสัมพันธ์ที่มีอยู่ระหว่างองค์ประกอบข้อมูล
ตัวอย่างเช่น ลองนึกภาพว่าคุณเปิดซูเปอร์มาร์เก็ต ในตอนนี้ ประวัติการซื้อของลูกค้าอาจไม่ได้เปิดเผยอะไรมากบนพื้นผิว แต่ถ้าวิเคราะห์อย่างละเอียด – ตระหนักถึงรูปแบบที่เป็นไปได้ เพียงแค่ข้อมูลนี้ก็เพียงพอแล้วที่จะให้อะไรมากมาย หากคุณยังไม่ได้เดา เรากำลังพูดถึง Target ซึ่ง เป็นซูเปอร์มาร์เก็ตที่พบว่า เด็กสาว (ลูกค้า) กำลังตั้งครรภ์ เพียงแค่ศึกษาประวัติการซื้อของเธออย่างรอบคอบ และมองหาแนวโน้มและรูปแบบ ดังนั้นข้อมูลที่ดูเล็กน้อยบนพื้นผิวจึงมีค่ามากเมื่อขุดอย่างระมัดระวัง - และนั่นคือสิ่งที่เราหมายถึงโดย "ความรู้ที่ไม่รู้จักก่อนหน้านี้"
เรารู้สึกว่ามันจะไม่ยุติธรรมสำหรับคุณหากเราให้รสชาติของ Data Warhousing และ Data Mining แก่คุณ และเพิกเฉยต่อภาพรวมโดยสิ้นเชิง – การค้นพบความรู้ในฐานข้อมูล (KDD) การทำเหมืองข้อมูลเป็นขั้นตอนหนึ่งของกระบวนการ KDD มาพูดถึง KDD กันมากขึ้น

รับ ใบรับรองวิทยาศาสตร์ข้อมูล จากมหาวิทยาลัยชั้นนำของโลก เข้าร่วมโปรแกรม Executive PG, Advanced Certificate Programs หรือ Masters Programs ของเราเพื่อติดตามอาชีพของคุณอย่างรวดเร็ว
การค้นพบความรู้ในฐานข้อมูล (KDD)
การทำเหมืองข้อมูลเป็นหนึ่งในขั้นตอนที่สำคัญยิ่งในกระบวนการของ KDD โดยทั่วไปแล้ว KDD จะครอบคลุมทุกอย่างตั้งแต่การเลือกข้อมูลไปจนถึงการประเมินข้อมูลที่ขุดได้ในที่สุด รอบ KDD ที่สมบูรณ์จะแสดงในภาพด้านล่าง:
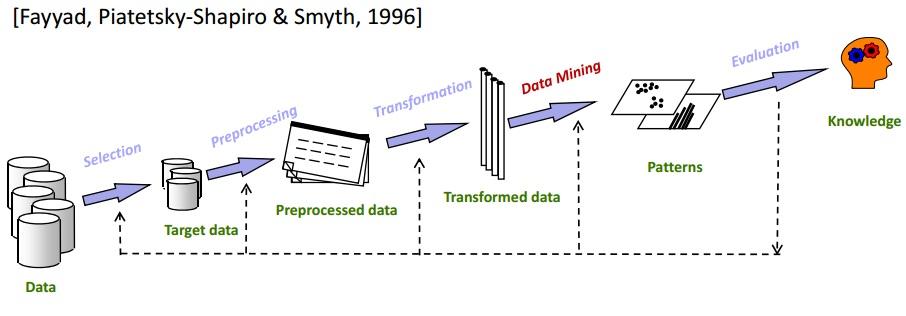
การคัดเลือก
การทราบข้อมูลเป้าหมายที่แน่นอนมีความสำคัญสูงสุด การวิเคราะห์การทำเหมืองข้อมูลไปยังชุดย่อยของคลังข้อมูลเป็นขั้นตอนที่สำคัญมาก เนื่องจากการลบองค์ประกอบข้อมูลที่ไม่เกี่ยวข้องจะลดพื้นที่การค้นหาระหว่างขั้นตอนการทำเหมืองข้อมูล
ก่อนการประมวลผล
ในขั้นตอนนี้ ข้อมูลที่เลือกจะปราศจากความผิดปกติและค่าผิดปกติใดๆ โดยทั่วไป ข้อมูลจะถูกล้างอย่างสมบูรณ์ในขั้นตอนนี้ เช่น หากมีบางช่องข้อมูลที่ขาดหายไป จะถูกเติมด้วยค่าที่เหมาะสม ตัวอย่างเช่น ในตารางที่เก็บรายละเอียดของพนักงานขององค์กรของคุณ สมมติว่ามีคอลัมน์สำหรับ "ชื่อกลาง" เป็นไปได้มากว่าพนักงานหลายคนจะว่าง ในสถานการณ์เช่นนี้ ค่าที่เหมาะสมจะถูกเลือก (N/A เช่น)
การแปลงร่าง
ระยะนี้พยายามลดความหลากหลายขององค์ประกอบข้อมูลในขณะที่รักษาคุณภาพของข้อมูล
การขุดข้อมูล
นี่คือขั้นตอนหลักของกระบวนการ KDD ข้อมูลที่แปลงแล้วจะขึ้นอยู่กับวิธีการขุดข้อมูล เช่น การจัดกลุ่ม การจัดกลุ่ม การถดถอย ฯลฯ ซึ่งจะทำซ้ำๆ เพื่อให้ได้ผลลัพธ์ที่ดีที่สุด สามารถใช้เทคนิคต่างๆ ได้ตามความต้องการ
การประเมิน
นี่คือขั้นตอนสุดท้าย ในการนี้ ความรู้ที่ได้รับจะได้รับการจัดทำเป็นเอกสารและนำเสนอเพื่อการวิเคราะห์ต่อไป เครื่องมือการแสดงข้อมูลต่างๆ ถูกนำมาใช้ในขั้นตอนนี้เพื่อแสดงความรู้ที่ได้รับในลักษณะที่สวยงามและเข้าใจได้
Paradox ของ Simpson ส่งผลต่อข้อมูลอย่างไร
กรณีการใช้งานจริงของการขุดข้อมูล
ทุกองค์กรตั้งแต่ Amazon, Flipkart, Netflix, Facebook, Twitter, Instagram ไปจนถึง Walmart ต่างก็นำ Data Mining ไปใช้ให้เกิดประโยชน์ ในส่วนนี้ เราจะพูดถึงกรณีการใช้งานกว้างๆ สี่กรณีของ Data Mining ซึ่งเป็นส่วนหนึ่งของชีวิตประจำวันของคุณ
ผู้ให้บริการ
ผู้ให้บริการโทรคมนาคมใช้ Data Mining เพื่อทำนาย "ปั่นป่วน" ซึ่งเป็นคำที่ใช้เมื่อลูกค้าทิ้งผู้ให้บริการรายอื่น นอกจากนั้น พวกเขายังรวบรวมข้อมูลการเรียกเก็บเงิน การเข้าชมเว็บไซต์ การโต้ตอบกับฝ่ายดูแลลูกค้า และอื่นๆ เพื่อให้คะแนนความน่าจะเป็นแก่ลูกค้าแต่ละราย จากนั้น ลูกค้าที่มีความเสี่ยงสูงที่จะ "เลิกใช้งาน" จะได้รับข้อเสนอและสิ่งจูงใจ
อีคอมเมิร์ซ
อีคอมเมิร์ซเป็นกรณีการใช้งานที่เป็นที่รู้จักมากที่สุดเมื่อพูดถึง Data Mining แน่นอนว่าหนึ่งในนั้นมีชื่อเสียงมากที่สุดคืออเมซอน พวกเขาใช้เทคนิคการขุดที่ซับซ้อนอย่างยิ่ง ลองดูฟังก์ชัน "คนที่ดูผลิตภัณฑ์นั้นชอบสิ่งนี้ด้วย" เป็นต้น!
ซูเปอร์มาร์เก็ต
ซูเปอร์มาร์เก็ตยังเป็นกรณีการใช้งานที่น่าสนใจของ Data Mining การขุดประวัติการซื้อของลูกค้าทำให้พวกเขาเข้าใจรูปแบบการซื้อของพวกเขา ซูเปอร์มาร์เก็ตจะใช้ข้อมูลนี้เพื่อมอบข้อเสนอส่วนบุคคลให้กับลูกค้า โอ้ เราบอกคุณเกี่ยวกับสิ่งที่ Target ใช้ Data Mining หรือไม่? (ใช่เราทำ!)
ค้าปลีก
ผู้ค้าปลีกจะรวมกลุ่มลูกค้าไว้ในกลุ่มความใหม่ ความถี่ และการเงิน (RFM) การใช้ Data Mining พวกเขากำหนดเป้าหมายการตลาดไปยังกลุ่มเหล่านี้ ลูกค้าที่ใช้จ่ายเพียงเล็กน้อยแต่บ่อยครั้งและการซื้อครั้งล่าสุดของเขาค่อนข้างเร็วจะได้รับการจัดการที่แตกต่างจากลูกค้าที่ใช้จ่ายมากแต่เพียงครั้งเดียว
ห่อ…
คลังข้อมูลและการทำเหมืองข้อมูล ประกอบขึ้นเป็นสองกระบวนการที่สำคัญที่สุดที่ดำเนินไปทั่วโลกในปัจจุบัน เกือบทุกสิ่งที่ยิ่งใหญ่ในปัจจุบันเป็นผลมาจากการทำเหมืองข้อมูลที่ซับซ้อน เนื่องจากข้อมูลที่ไม่ถูกขุดนั้นมีประโยชน์ (หรือไร้ประโยชน์) เท่ากับไม่มีข้อมูลเลย
อีกครั้ง เพื่อทำความเข้าใจความแตกต่างระหว่าง Data Mining และ Data Warehousing คุณต้องผ่อนคลาย ตั้งแต่การแนะนำ Data Mining ไปจนถึง Data Warehousing ซึ่งเป็นวิธีการรวมศูนย์ข้อมูลจากแหล่งที่แตกต่างกันในฐานข้อมูลเดียว เราสามารถกำหนด Data warehousing ให้เป็นข้อมูลในอดีตที่คอมไพล์แล้วหรือฟีดข้อมูลแบบเรียลไทม์ที่ให้ข้อมูลอินทรีย์และบูรณาการเป็นส่วนใหญ่
เราหวังว่าบทความนี้จะให้ความกระจ่างแก่คุณเกี่ยวกับ Data Warehousing และ Data Mining และอีกมากมาย โดยสรุป กระบวนการรวบรวม จัดเก็บ และจัดระเบียบข้อมูลในฐานข้อมูลเดียวถือเป็น Data Warehousing เทียบกับ Data Mining ส่วนใหญ่จะดึงข้อมูลที่มีความหมายออกจากข้อมูลโดยใช้มุมมองที่แตกต่างกัน ข้อมูลที่เป็นประโยชน์ทั้งหมดที่รวบรวมไว้สามารถนำมาใช้ในภายหลังเพื่อแก้ไขปัญหาในอนาคตที่อาจขัดขวางการเติบโตของบริษัท และยังสามารถลดต้นทุนได้อีกด้วย หากคุณกำลังมองหาอนาคตที่สดใสและน่าสนใจ และหากการสำรวจคือสิ่งที่คุณหลงใหล การเริ่มต้นจากการเรียนรู้ Whats' What of Data Warehousing และ Data Mining จะเป็นตัวเลือกที่ยอดเยี่ยมสำหรับคุณ
เราหวังว่าบทความนี้จะให้ความกระจ่างแก่คุณเกี่ยวกับความหมายของคำสองคำนี้และอีกมากมาย! หากคุณอยากเรียนรู้เกี่ยวกับวิทยาศาสตร์ข้อมูล ให้ลองดูประกาศนียบัตร PG ด้านวิทยาศาสตร์ข้อมูลของ IIIT-B และ upGrad ซึ่งสร้างขึ้นสำหรับมืออาชีพด้านการทำงานและเสนอกรณีศึกษาและโครงการมากกว่า 10 รายการ เวิร์กช็อปภาคปฏิบัติจริง การให้คำปรึกษากับผู้เชี่ยวชาญในอุตสาหกรรม 1- on-1 กับที่ปรึกษาในอุตสาหกรรม การเรียนรู้มากกว่า 400 ชั่วโมงและความช่วยเหลือด้านงานกับบริษัทชั้นนำ
ธุรกิจต่างๆ ใช้ Data Warhousing และ Data Mining อย่างไร?
ทั้งการทำเหมืองข้อมูลและคลังข้อมูลเป็นเทคนิคทางธุรกิจสำหรับการแปลงข้อมูล (หรือข้อมูล) ให้เป็นความรู้ที่ใช้งานได้
การทำเหมืองข้อมูลเป็นวิธีการวิเคราะห์ทางสถิติ นักวิเคราะห์ใช้เครื่องมือทางเทคนิคในการสืบค้นและจัดเรียงข้อมูลขนาดกิกะไบต์เพื่อค้นหาแนวโน้ม จากนั้นธุรกิจต่างๆ จะใช้ข้อมูลนี้ในการตัดสินใจทางธุรกิจที่ดีขึ้นโดยอิงจากความเข้าใจในพฤติกรรมของผู้บริโภคและซัพพลายเออร์ของตน
คลังข้อมูลเป็นกระบวนการของการออกแบบวิธีการจัดเก็บข้อมูลเพื่ออำนวยความสะดวกในการรายงานและการวิเคราะห์ ตามที่ผู้เชี่ยวชาญด้านคลังข้อมูลระบุว่า ที่เก็บข้อมูลจำนวนมากมีทั้งแบบบูรณาการทางแนวคิดและทางกายภาพ และมีความเกี่ยวข้องกัน ข้อมูลของบริษัทมักจะถูกบันทึกไว้ในหลายฐานข้อมูล
อะไรคือความแตกต่างหลักระหว่าง Data Warehousing และ Data Mining? ในโลกธุรกิจอันไหนใช้งานได้จริงมากกว่ากัน?
คลังข้อมูลเป็นระบบจัดเก็บข้อมูล โดยปกติแล้วจะมีข้อมูลหลายประเภทที่ได้มาจากแหล่งข้อมูลต่างๆ เพื่อวัตถุประสงค์ที่หลากหลาย กระบวนการจัดเก็บข้อมูลนี้อย่างมีระเบียบวินัยเพื่อให้สามารถเรียกค้นข้อมูลได้ในภายหลังเรียกว่าคลังข้อมูล
กระบวนการดึงข้อมูลเรียกว่าการทำเหมืองข้อมูล เกี่ยวข้องกับการค้นหาข้อมูลที่เกี่ยวข้องมากที่สุดสำหรับเป้าหมายเฉพาะ อาจมาจากคลังข้อมูลของคุณหรือจากที่อื่นทั้งหมด คุณคาดหวังการกลั่นและทำความสะอาดข้อมูลที่คุณขุด เช่นเดียวกับที่คุณทำกับแร่จริง
ยิ่งระบบคลังสินค้าของคุณดีขึ้นเท่าไร การขุดก็จะยิ่งง่ายขึ้นเท่านั้น
กระบวนการ Data Mining และ KDD คล้ายกันหรือไม่
แม้ว่า KDD และ Data Mining เป็นคำศัพท์ที่มีการแลกเปลี่ยนกันบ่อยครั้ง แต่ก็อ้างถึงแนวคิดที่แตกต่างกันสองประการแต่เกี่ยวข้องกัน
การทำเหมืองข้อมูลเป็นส่วนประกอบภายในกระบวนการ KDD ที่เกี่ยวข้องกับการจดจำรูปแบบในข้อมูล ในขณะที่ KDD เป็นกระบวนการทั้งหมดในการดึงความรู้จากข้อมูล กล่าวอีกนัยหนึ่ง Data Mining เป็นเพียงการประยุกต์ใช้อัลกอริธึมเฉพาะเพื่อให้บรรลุวัตถุประสงค์สูงสุดของกระบวนการ KDD