
Che cos'è il data warehousing e il data mining
Pubblicato: 2018-02-22I dati aziendali erano archiviati in silos di informazioni fisicamente separati dagli altri archivi di dati e ogni silo serviva a funzioni specializzate, ma ciò accadeva prima che i Big Data colpissero il mondo (con una tempesta, se possiamo dire). Ora, è praticamente impossibile praticare gli stessi metodi su set di dati così grandi. Immagina il numero di estrazioni di dati che richiederebbe da tanti di questi silos di informazioni fisicamente separati, solo per eseguire una semplice query. Tutto grazie all'enorme mucchio di dati che si trovano nelle organizzazioni e nei metodi di ingegneria dei big data.
Teniamo d'occhio come entrano in scena Data Warehousing e Data mining . I Data Warehouse sono stati sviluppati per combattere questo problema di archiviazione dei dati. In sostanza, i Data Warehouse possono essere considerati come un repository unificato di dati che provengono da varie fonti e sono in vari formati. Il Data Mining, d'altra parte, è il processo di estrazione della conoscenza da detto Data Warehouse.
In questo articolo, daremo uno sguardo dettagliato a Data Warehouse e Data Mining. Per una migliore comprensione, abbiamo strutturato l'articolo come segue:
- Che cos'è il Data Warehouse?
- Processi di Data Warehouse
- Che cos'è il data mining?
- Processo KDD
- Casi d'uso reali del data mining
Sommario
Che cos'è il Data Warehouse?
Se dovessimo definire Data Warehouse, può essere spiegato come una raccolta integrata di dati orientata al soggetto, variabile nel tempo, non volatile. L'introduzione al Data Warehousing comprende anche dati compilati da fonti esterne. Lo scopo della progettazione di un Warehouse è analizzare e indurre decisioni aziendali riportando i dati a un livello aggregato diverso. Prima di procedere oltre, diamo un'occhiata a cosa significano questi termini nel contesto di un Data Warehouse:
Orientato al soggetto
Le organizzazioni possono utilizzare il Data Warehouse per analizzare un'area tematica specifica. Supponiamo di voler vedere quanto bene ha funzionato il tuo team di vendita negli ultimi 5 anni: puoi interrogare il tuo magazzino e ti dirà tutto ciò che devi sapere. In questo caso, le “vendite” possono essere trattate come un soggetto.
Variante temporale
I data warehouse sono responsabili della memorizzazione dei dati storici per le organizzazioni. Ad esempio, un sistema di transazione può contenere l'indirizzo più recente di un cliente, ma un Data Warehouse conterrà anche tutti gli indirizzi precedenti. Continua ad aggiungere continuamente dati da varie fonti, oltre a mantenere i dati storici: questo è ciò che lo rende un modello variabile nel tempo. I dati memorizzati varieranno sempre nel tempo.
Non volatile
Una volta che i dati sono archiviati in un Data Warehouse, non possono essere alterati o modificati. Possiamo solo aggiungere una copia modificata dei dati che vogliamo modificare.
Integrato:
Come abbiamo detto in precedenza, un Data Warehouse contiene dati provenienti da più origini. Supponiamo di avere due origini dati: A e B. Entrambe le origini potrebbero contenere tipi di dati completamente diversi archiviati, ma quando vengono portati in un magazzino, vengono sottoposti a preelaborazione. È così che un Data Warehouse integra i dati provenienti da una serie di fonti.
Processi di Data Warehouse
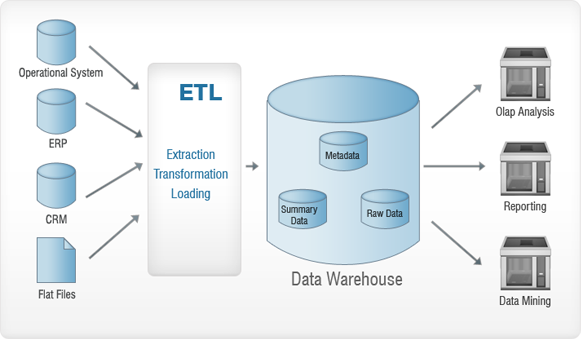
Dai un'occhiata all'immagine sopra. I dati che vengono raccolti da varie fonti (sistema operativo, ERP, CRM, Flat Files, ecc.) vengono sottoposti a un processo ETL prima di essere inseriti nel data warehouse. Questo viene essenzialmente fatto per rimuovere eventuali anomalie dai dati, in modo che non venga causato alcun danno al Data Warehouse. ETL sta per – Estrazione, Trasformazione e Caricamento. Diamo un'occhiata a ciascuno di questi processi in dettaglio. Per capire meglio, useremo un'analogia: pensa a una corsa all'oro e continua a leggere!
Estrazione
L'estrazione viene essenzialmente eseguita per raccogliere tutti i dati richiesti dai sistemi di origine utilizzando il minor numero di risorse possibile.
Pensa a questo passo come fare una panoramica del fiume alla ricerca di pepite d'oro il più grandi possibile .
Trasformazione
L'obiettivo principale è inserire i dati estratti nel database in un formato generale. Questo perché origini diverse avranno formati diversi di archiviazione dei dati, ad esempio, un'origine dati potrebbe avere dati nel formato "gg/mm/aaaa" e l'altra potrebbe averli nel formato "gg-mm-aa". In questo passaggio, lo convertiremo in un formato generalizzato, uno che verrà utilizzato per i dati da tutte le origini.
Ora hai una pepita d'oro. Cosa fai? Fatelo sciogliere ed eliminate le impurità.
Caricamento in corso
In questo passaggio, i dati trasformati vengono caricati nel database di destinazione.
Ora hai l'oro puro: modellalo in un anello e vendilo!
Il processo di acquisizione di dati da varie fonti e di archiviazione nel Data Warehouse (dopo il processo ETL, ovviamente), è noto come Data Warehousing.
Ora hai i tuoi dati a posto, tutti ripuliti e pronti per l'uso. Quale dovrebbe essere il prossimo passo? Estrarre conoscenza – sì!
Data Mining in soccorso!
Come puoi passare all'analisi dei dati?Che cos'è il data mining?
Il data mining è, molto semplicemente, il processo di estrazione di informazioni precedentemente sconosciute ma potenzialmente utili dai set di dati. Per “precedentemente sconosciuto” intendiamo una conoscenza che può essere acquisita solo dopo aver scavato in profondità il data warehouse, ovvero non avrà senso in superficie. Il data mining cerca essenzialmente i modelli globali di relazioni che esistono tra gli elementi di dati.
Ad esempio, immagina di gestire un supermercato. Ora, la cronologia degli acquisti di un cliente potrebbe non sembrare molto in superficie, ma, se analizzata attentamente, riconoscendo i possibili schemi, allora solo queste informazioni sono sufficienti per dare molto. Se non l'hai ancora indovinato, stiamo parlando di Target, un supermercato che ha scoperto che una ragazza adolescente (cliente) era incinta solo studiando attentamente la sua cronologia degli acquisti e cercando tendenze e modelli. Quindi, le informazioni che sembravano così banali in superficie si sono rivelate di così tanto valore se estratte con attenzione - ed è esattamente ciò che intendiamo per "conoscenza precedentemente sconosciuta".
Riteniamo che non sarebbe giusto nei tuoi confronti se ti dessimo il sapore del Data Warehousing e del Data Mining e ignoriamo completamente il quadro generale: Knowledge Discovery in Databases (KDD). Il data mining costituisce uno dei passaggi di un processo KDD. Parliamo un po' di più di KDD.

Ottieni la certificazione di data science dalle migliori università del mondo. Unisciti ai nostri programmi Executive PG, Advanced Certificate Program o Masters per accelerare la tua carriera.
Scoperta della conoscenza nei database (KDD)
Il data mining è uno dei passaggi più cruciali nel processo di KDD. KDD copre sostanzialmente tutto, dalla selezione dei dati alla valutazione finale dei dati estratti. Il ciclo completo di KDD è mostrato nell'immagine seguente:
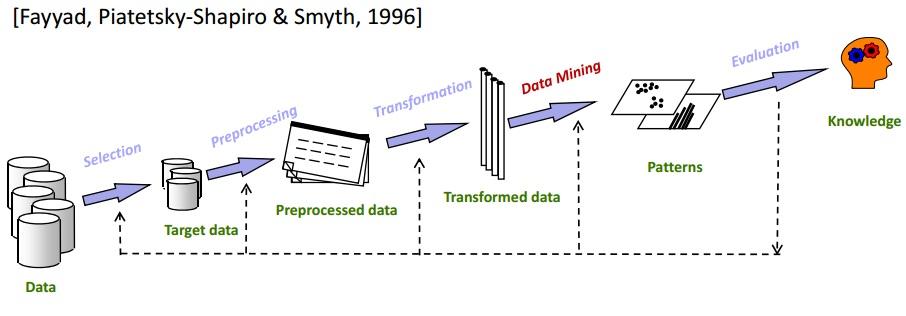
Selezione
È della massima importanza conoscere i dati esatti dell'obiettivo. L'analisi del sottoinsieme di Data Mining in Data Warehousing è un passaggio molto importante perché la rimozione di elementi di dati non correlati ridurrà lo spazio di ricerca durante la fase di Data Mining .
Pre-elaborazione
In questa fase, i dati selezionati vengono liberati da eventuali anomalie e valori anomali. Fondamentalmente, i dati vengono completamente puliti in questa fase. Ad esempio, se ci sono campi dati mancanti, vengono riempiti con valori appropriati. Ad esempio, nella tabella che memorizza i dettagli dei dipendenti della tua organizzazione, supponi che sia presente una colonna per "Secondo nome". È probabile che sarà vuoto per molti dipendenti. In tale scenario, viene scelto un valore appropriato (N/A, per esempio).
Trasformazione
Questa fase tenta di ridurre la varietà di elementi di dati preservando la qualità delle informazioni.
Estrazione dei dati
Questa è la fase principale di un processo KDD. I dati trasformati sono soggetti a metodi di data mining come raggruppamento, clustering, regressione, ecc. Questo viene fatto in modo iterativo per ottenere i migliori risultati. Diverse tecniche possono essere utilizzate a seconda delle esigenze.
Valutazione
Questo è il passo finale. In questo, le conoscenze acquisite vengono documentate e presentate per ulteriori analisi. In questa fase vengono utilizzati vari strumenti di visualizzazione dei dati per rappresentare le conoscenze acquisite in un modo bello e comprensibile.
In che modo il paradosso di Simpson influisce sui dati?
Casi d'uso reali del data mining
Ogni organizzazione, da Amazon, Flipkart, Netflix, Facebook, Twitter, Instagram e persino Walmart, sta facendo buon uso del Data Mining. In questa sezione parleremo di quattro ampi casi d'uso del data mining che sono parte integrante della tua vita quotidiana.
Fornitori di servizi
I fornitori di servizi di telecomunicazione utilizzano il Data Mining per prevedere il "abbandono", un termine usato da loro per quando un cliente li abbandona per un altro fornitore. Oltre a ciò, raccolgono informazioni di fatturazione, visite al sito Web, interazioni con l'assistenza clienti e altre cose simili per dare a ciascun cliente un punteggio di probabilità. Quindi, ai clienti che corrono un rischio più elevato di "sfornare" vengono offerte offerte e incentivi.
Commercio elettronico
L'e-commerce è facilmente il caso d'uso più noto quando si tratta di data mining. Uno dei più famosi è, ovviamente, Amazon. Usano tecniche minerarie estremamente sofisticate. Ad esempio, dai un'occhiata alla funzionalità "Le persone che hanno visto quel prodotto, hanno apprezzato anche questo"!
Supermercati
Anche i supermercati sono un caso d'uso interessante del Data Mining. L'estrazione della cronologia degli acquisti dei clienti consente loro di comprendere i loro modelli di acquisto. Queste informazioni vengono quindi utilizzate dai supermercati per fornire offerte personalizzate ai clienti. Oh, e ti abbiamo parlato di cosa ha fatto Target utilizzando il Data Mining? (Sì, abbiamo fatto!)
Vedere al dettaglio
I rivenditori raggruppano i loro clienti in gruppi Recency, Frequency e Monetary (RFM). Utilizzando il data mining, indirizzano il marketing a questi gruppi. Un cliente che spende poco ma frequentemente e il suo ultimo acquisto è stato abbastanza recente sarà gestito in modo diverso rispetto a un cliente che ha speso molto ma solo una volta.
Avvolgendo…
Data Warehousing e Data Mining costituiscono due dei processi più importanti che gestiscono letteralmente il mondo di oggi. Quasi ogni grande cosa oggi è il risultato di un sofisticato data mining. Perché i dati non estratti sono utili (o inutili) come nessun dato.
Ancora una volta, per capire la differenza tra Data Mining e Data Warehousing devi indulgere, dall'introduzione al Data Mining al Data Warehousing, che è un metodo che centralizza tutti i dati da fonti disparate in un unico database. Possiamo definire il data warehousing come dati storici compilati o feed di dati in tempo reale che restituiscono informazioni per lo più organiche e integrate.
Ci auguriamo che questo articolo ti abbia fornito chiarezza su cosa sono Data Warehousing e Data Mining e molto altro. Per concludere, il processo di raccolta, archiviazione e organizzazione delle informazioni in un unico database è considerato come Data Warehousing vs. Data Mining consiste principalmente nell'estrazione di informazioni significative dai dati utilizzando una prospettiva diversa. Tutte le informazioni utili che vengono raccolte possono essere utilizzate successivamente per risolvere problemi futuri che potrebbero essere di ostacolo alla crescita dell'azienda e possono anche ridurre i costi. Se sei alla ricerca di un futuro luminoso e affascinante e se l'esplorazione è la tua passione, iniziare dall'apprendimento del Che cos'è il Data Warehousing e il Data Mining sarebbe un'ottima opzione per te.
Speriamo che questo articolo ti abbia dato chiarezza su cosa significano questi due termini e molto altro! Se sei curioso di conoscere la scienza dei dati, dai un'occhiata al Diploma PG in Data Science di IIIT-B e upGrad, creato per i professionisti che lavorano e offre oltre 10 casi di studio e progetti, workshop pratici pratici, tutoraggio con esperti del settore, 1- on-1 con mentori del settore, oltre 400 ore di apprendimento e assistenza al lavoro con le migliori aziende.
In che modo le aziende utilizzano il Data Warehousing e il Data Mining?
Sia il data mining che il data warehousing sono tecniche di business intelligence per trasformare informazioni (o dati) in conoscenze utilizzabili.
Il data mining è un metodo di analisi statistica. Gli strumenti tecnici vengono utilizzati dagli analisti per interrogare e ordinare gigabyte di dati alla ricerca di tendenze. Le aziende utilizzano quindi questi dati per prendere decisioni aziendali migliori in base alla loro comprensione dei comportamenti dei loro consumatori e fornitori.
Il Data Warehousing è il processo di progettazione del modo in cui i dati vengono archiviati al fine di facilitare il reporting e l'analisi. Secondo gli specialisti del data warehouse, i numerosi datastore sono sia concettualmente che fisicamente integrati e correlati tra loro. I dati di un'azienda vengono generalmente salvati in più database.
Qual è la differenza fondamentale tra Data Warehousing e Data Mining? Qual è più pratico nel mondo degli affari?
Un data warehouse è un sistema di archiviazione dati. Di solito comporta una varietà di tipi di dati acquisiti da più fonti per una varietà di obiettivi. Il processo di archiviazione di questi dati con disciplina in modo che possano essere recuperati in seguito è noto come data warehousing.
Il processo di estrazione dei dati è noto come data mining. Implica l'individuazione delle informazioni più pertinenti per un obiettivo particolare. Potrebbe provenire dal tuo data warehouse o da qualche altra parte. Prevedi di raffinare e pulire i dati che estrai, proprio come faresti con il minerale reale.
Migliori sono i tuoi sistemi di magazzino, più facile sarà il mio.
I processi di Data Mining e KDD sono simili?
Sebbene KDD e Data Mining siano i termini che vengono frequentemente scambiati, si riferiscono a due concetti distinti ma correlati.
Il data mining è un componente all'interno del processo KDD che si occupa del riconoscimento dei modelli nei dati, mentre KDD è l'intero processo di estrazione della conoscenza dai dati. Per dirla in altro modo, il Data Mining è solo l'applicazione di un algoritmo specifico per raggiungere lo scopo finale del processo KDD.