
O que é o que é Data Warehousing e Data Mining
Publicados: 2018-02-22Os dados corporativos eram armazenados em silos de informação fisicamente separados de outros repositórios de dados, e cada silo servia a funções especializadas – mas isso foi antes de o Big Data atingir o mundo (por uma tempestade, se assim podemos dizer). Agora, é praticamente impossível praticar os mesmos métodos em conjuntos de dados tão grandes. Imagine o número de extrações de dados que seriam necessárias de tantos desses silos de informações fisicamente separados – apenas para executar uma consulta simples. Tudo graças à enorme pilha de dados que se encontra nas organizações e nos métodos de engenharia de big data.
Vamos ficar de olho em como Data Warehousing e Data mining entram em cena. Data Warehouses foram desenvolvidos para combater este problema de armazenamento de dados. Essencialmente, os Data Warehouses podem ser pensados como um repositório unificado de dados que vêm de várias fontes e estão em vários formatos. A Mineração de Dados, por outro lado, é o processo de extração de conhecimento do referido Data Warehouse.
Neste artigo, vamos dar uma olhada detalhada em Data Warehouse e Data Mining. Para melhor compreensão, estruturamos o artigo da seguinte forma:
- O que é armazenamento de dados?
- Processos de armazenamento de dados
- O que é Mineração de Dados?
- Processo KDD
- Casos de uso da vida real de mineração de dados
Índice
O que é armazenamento de dados?
Se definimos Data Warehouse, ele pode ser explicado como uma coleção de dados integrada, orientada por assunto, variante no tempo, não volátil. A introdução ao Data Warehousing também inclui dados compilados de fontes externas. O objetivo de projetar um Warehouse é analisar e induzir decisões de negócios relatando dados em um nível agregado diferente. Antes de avançarmos daqui, vamos primeiro ver o que esses termos significam no contexto de um Data Warehouse:
Orientado ao assunto
As organizações podem usar o Data Warehouse para analisar uma área de assunto específica. Suponha que você queira ver o desempenho de sua equipe de vendas nos últimos 5 anos – você pode consultar seu Armazém e ele lhe dirá tudo o que você precisa saber. Nesse caso, “vendas” pode ser tratada como um assunto.
Tempo variável
Os Data Warehouses são responsáveis por armazenar dados históricos para as organizações. Por exemplo, um sistema de transações pode conter o endereço mais recente de um cliente, mas um Data Warehouse também conterá todos os endereços anteriores. Ele continua adicionando dados de várias fontes, além de manter os dados históricos – é isso que o torna um modelo variante no tempo. Os dados armazenados sempre variam com o tempo.
Não volátil
Uma vez que os dados são armazenados em um Data Warehouse, eles não podem ser alterados ou modificados. Só podemos adicionar uma cópia modificada dos dados que queremos modificar.
Integrado:
Como dissemos anteriormente, um Data Warehouse contém dados de várias fontes. Digamos que temos duas fontes de dados – A e B. Ambas as fontes podem ter tipos de dados completamente diferentes armazenados nelas, mas quando são trazidas para um Warehouse, são feitas para serem pré-processadas. É assim que um Data Warehouse integra dados de várias fontes.
Processos de armazenamento de dados
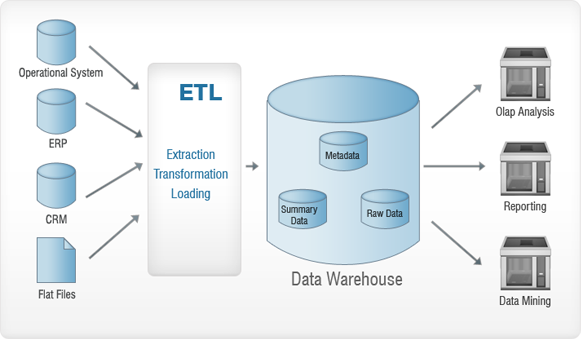
Dê uma olhada na imagem acima. Os dados coletados de várias fontes (sistema operacional, ERP, CRM, Flat Files, etc.) passam por um processo de ETL antes de serem inseridos no data warehouse. Isso é feito essencialmente para remover anomalias, se houver, dos dados – para que nenhum dano seja causado ao Data Warehouse. ETL significa – Extração, Transformação e Carregamento. Vamos dar uma olhada em cada um desses processos em detalhes. Para entender melhor, vamos usar uma analogia – pense em uma corrida do ouro e continue lendo!
Extração
A extração é feita essencialmente para coletar todos os dados necessários dos sistemas de origem usando o mínimo de recursos possível.
Pense neste passo como garimpar o rio em busca de pepitas de ouro o maior possível .
Transformação
O objetivo principal é inserir os dados extraídos no banco de dados em um formato geral. Isso ocorre porque fontes diferentes terão formatos diferentes de armazenamento de dados – por exemplo, uma fonte de dados pode ter dados no formato “dd/mm/aaaa” e a outra pode ter no formato “dd-mm-aa”. Nesta etapa, converteremos isso em um formato generalizado – um que será usado para dados de todas as fontes.
Agora você tem uma pepita de ouro. O que você faz? Derreta-o e remova as impurezas.
Carregando
Nesta etapa, os dados transformados são carregados no banco de dados de destino.
Agora você tem ouro puro - molde-o em um anel e venda-o!
O processo de trazer dados de várias fontes e armazená-los no Data Warehouse (após o processo ETL, é claro), é o que é conhecido como Data Warehousing.
Agora, você tem seus dados no lugar – todos limpos e prontos para serem usados. Qual deve ser o próximo passo? Extraindo conhecimento – sim!
Mineração de dados para o resgate!
Como você pode fazer a transição para a análise de dados?O que é Mineração de Dados?
A mineração de dados é, simplesmente, o processo de extração de informações anteriormente desconhecidas, mas potencialmente úteis, dos conjuntos de dados. Por “anteriormente desconhecido”, queremos dizer conhecimento que pode ser adquirido somente após a mineração profunda do data warehouse – ou seja, não fará sentido na superfície. A Mineração de Dados procura essencialmente os padrões globais de relacionamentos que existem entre os elementos de dados.
Por exemplo, imagine que você administra um supermercado. Agora, o histórico de compras de um cliente pode não parecer revelar muito na superfície, mas, se analisado com cuidado – reconhecendo os possíveis padrões, apenas essa informação é suficiente para fornecer muito. Se você ainda não adivinhou, estamos falando da Target – um supermercado que descobriu que uma adolescente (cliente) estava grávida apenas estudando cuidadosamente seu histórico de compras e procurando tendências e padrões. Assim, as informações que pareciam tão triviais na superfície acabaram sendo de muito valor quando extraídas com cuidado – e é exatamente isso que queremos dizer com “conhecimento anteriormente desconhecido”.
Achamos que será injusto com você se lhe dermos o sabor de Data Warehousing e Data Mining e ignorarmos completamente o quadro geral – Descoberta de Conhecimento em Bancos de Dados (KDD). A Mineração de Dados é uma das etapas de um processo de KDD. Vamos falar um pouco mais sobre KDD.

Obtenha a certificação em ciência de dados das melhores universidades do mundo. Junte-se aos nossos Programas PG Executivos, Programas de Certificado Avançado ou Programas de Mestrado para acelerar sua carreira.
Descoberta de Conhecimento em Bancos de Dados (KDD)
A mineração de dados é uma das etapas mais cruciais no processo de KDD. O KDD basicamente cobre tudo, desde a seleção de dados até a avaliação final dos dados extraídos. O ciclo completo do KDD é mostrado na imagem abaixo:
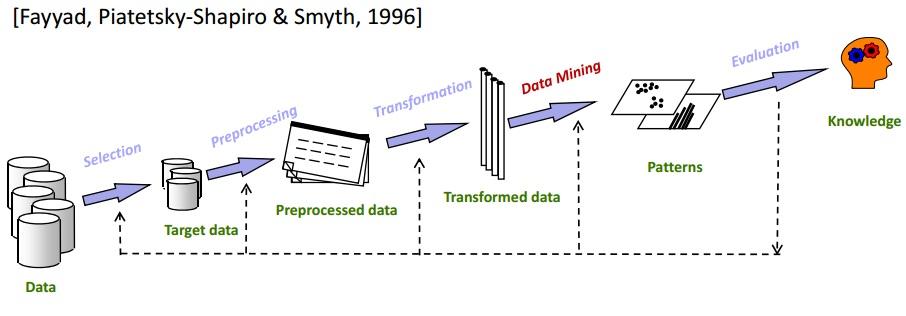
Seleção
É de extrema importância conhecer os dados exatos do alvo. Analisar o subconjunto de Data Mining para Data Warehousing é uma etapa muito importante porque a remoção de elementos de dados não relacionados reduzirá o espaço de pesquisa durante a fase de Data Mining .
Pré-processando
Nesta etapa, os dados selecionados são liberados de quaisquer anomalias e outliers. Basicamente, os dados são completamente limpos nesta fase. Por exemplo, se houver alguns campos de dados ausentes, eles serão preenchidos com os valores apropriados. Por exemplo, na tabela que armazena os detalhes dos funcionários de sua organização, suponha que haja uma coluna para “Nome do meio”. Provavelmente, estará vazio para muitos funcionários. Nesse cenário, um valor apropriado é escolhido (N/A, por ex).
Transformação
Esta fase tenta reduzir a variedade de elementos de dados, preservando a qualidade das informações.
Mineração de dados
Esta é a fase principal de um processo KDD. Os dados transformados são submetidos a métodos de mineração de dados como agrupamento, agrupamento, regressão, etc. Isso é feito de forma iterativa para trazer os melhores resultados. Diferentes técnicas podem ser usadas dependendo dos requisitos.
Avaliação
Este é o passo final. Neste, o conhecimento obtido é documentado e apresentado para posterior análise. Várias ferramentas de Visualização de Dados são usadas nesta etapa para retratar o conhecimento adquirido de uma forma bonita e compreensível.
Como o paradoxo de Simpson afeta os dados?
Casos de uso da vida real de mineração de dados
Todas as organizações, da Amazon, Flipkart, Netflix, Facebook, Twitter, Instagram e até Walmart, estão colocando a Mineração de Dados em bom uso. Nesta seção, falaremos sobre quatro amplos casos de uso de Data Mining que são parte integrante do seu dia-a-dia.
Provedores de serviço
Os provedores de serviços de telecomunicações usam Data Mining para prever o “churn” – um termo usado por eles para quando um cliente os troca por outro provedor. Além disso, eles coletam informações de cobrança, visitas ao site, interações de atendimento ao cliente e outras coisas para dar a cada cliente uma pontuação de probabilidade. Então, aqueles clientes que estão em maior risco de “churning” recebem ofertas e incentivos.
Comércio eletrônico
O comércio eletrônico é facilmente o caso de uso mais conhecido quando se trata de mineração de dados. Um dos mais famosos deles é, claro, a Amazon. Eles usam técnicas de mineração extremamente sofisticadas. Confira a funcionalidade “Pessoas que viram esse produto, também gostaram disso”, por exemplo!
Supermercados
Os supermercados também são um caso de uso interessante de mineração de dados. A mineração do histórico de compras dos clientes permite que eles entendam seus padrões de compra. Esta informação é então utilizada pelos supermercados para fornecer ofertas personalizadas aos clientes. Ah, e nós falamos sobre o que a Target fez usando Data Mining? (Sim nós fizemos!)
Retalho
Os varejistas agrupam seus clientes em grupos de Recência, Frequência e Monetário (RFM). Usando Data Mining, eles direcionam o marketing para esses grupos. Um cliente que gasta pouco, mas com frequência e sua última compra foi relativamente recente, será tratado de forma diferente de um cliente que gastou muito, mas apenas uma vez.
Empacotando…
Data Warehousing e Data Mining constituem dois dos processos mais importantes que estão literalmente executando o mundo hoje. Quase todas as grandes coisas hoje são resultado de uma sofisticada mineração de dados. Porque dados não minerados são tão úteis (ou inúteis) quanto nenhum dado.
Mais uma vez, para entender a diferença entre Data Mining e Data Warehousing, você precisa se entregar, desde a introdução ao Data Mining até o Data Warehousing - que é um método que centraliza todos os dados de fontes diferentes em um banco de dados. Podemos definir Data warehousing como dados históricos compilados ou feeds de dados em tempo real que devolvem principalmente informações orgânicas e integradas.
Esperamos que este artigo tenha esclarecido o que é Data Warehousing e Data Mining e muito mais. Para concluir, o processo de coleta, armazenamento e organização de informações em um único banco de dados é considerado como Data Warehousing vs. Data Mining é principalmente extrair informações significativas dos dados usando uma perspectiva diferente. Todas as informações úteis que são coletadas podem ser usadas posteriormente para resolver problemas futuros que podem ser um obstáculo para o crescimento da empresa e podem até reduzir custos. Se você está procurando por um futuro brilhante e fascinante e se a exploração é sua paixão, começar por aprender o que é Data Warehousing e Data Mining seria uma excelente opção para você.
Esperamos que este artigo tenha esclarecido o que esses dois termos significam e muito mais! Se você está curioso para aprender sobre ciência de dados, confira o PG Diploma in Data Science do IIIT-B & upGrad, que é criado para profissionais que trabalham e oferece mais de 10 estudos de caso e projetos, workshops práticos práticos, orientação com especialistas do setor, 1- on-1 com mentores do setor, mais de 400 horas de aprendizado e assistência de trabalho com as principais empresas.
Como as empresas usam Data Warehousing e Data Mining?
Tanto a mineração de dados quanto o armazenamento de dados são técnicas de inteligência de negócios para transformar informações (ou dados) em conhecimento utilizável.
A mineração de dados é um método de análise estatística. Ferramentas técnicas são usadas por analistas para consultar e classificar gigabytes de dados em busca de tendências. As empresas utilizam esses dados para tomar melhores decisões de negócios com base em sua compreensão dos comportamentos de seus consumidores e fornecedores.
Data Warehousing é o processo de projetar como os dados são armazenados para facilitar a geração de relatórios e análises. De acordo com especialistas em data warehouse, os vários armazenamentos de dados são conceitual e fisicamente integrados e relacionados entre si. Os dados de uma empresa normalmente são salvos em vários bancos de dados.
Qual é a principal diferença entre Data Warehousing e Data Mining? Qual é mais prático no mundo dos negócios?
Um data warehouse é um sistema de armazenamento de dados. Geralmente envolve uma variedade de tipos de dados adquiridos de várias fontes para uma variedade de objetivos. O processo de armazenar esses dados com disciplina para que possam ser recuperados posteriormente é conhecido como data warehousing.
O processo de extração de dados é conhecido como mineração de dados. Implica localizar as informações mais pertinentes para um objetivo específico. Pode vir do seu data warehouse ou de algum outro lugar. Você antecipa o refinamento e a limpeza dos dados extraídos, assim como faria com o minério real.
Quanto melhores forem seus sistemas de armazenamento, mais fácil será minerar.
Os processos de mineração de dados e KDD são semelhantes?
Embora KDD e Mineração de Dados sejam os termos frequentemente trocados, eles se referem a dois conceitos distintos, mas relacionados.
A Mineração de Dados é um componente do processo KDD que lida com o reconhecimento de padrões nos dados, enquanto o KDD é todo o processo de extração de conhecimento dos dados. Dito de outra forma, Data Mining é apenas a aplicação de um algoritmo específico para atingir o objetivo final do processo de KDD.