
Qu'est-ce que l'entreposage de données et l'exploration de données ?
Publié: 2018-02-22Les données d'entreprise étaient stockées dans des silos d'informations physiquement séparés des autres référentiels de données, et chaque silo remplissait des fonctions spécialisées - mais c'était avant que le Big Data ne frappe le monde (par une tempête, si l'on peut dire). Maintenant, il est pratiquement impossible de pratiquer les mêmes méthodes sur des ensembles de données aussi volumineux. Imaginez simplement le nombre d'extraits de données qu'il faudrait à partir d'un si grand nombre de ces silos d'informations physiquement séparés - uniquement pour exécuter une simple requête. Tout cela grâce à la pile de données extrêmement massive qui repose sur les organisations et les méthodes d'ingénierie du Big Data.
Gardons un œil attentif sur la façon dont l'entreposage de données et l'exploration de données entrent en scène. Les entrepôts de données ont été développés pour lutter contre ce problème de stockage des données. Essentiellement, les entrepôts de données peuvent être considérés comme un référentiel unifié de données provenant de diverses sources et se présentant sous divers formats. L'exploration de données, quant à elle, est le processus d'extraction de connaissances dudit entrepôt de données.
Dans cet article, nous examinerons en détail l'entrepôt de données et l'exploration de données. Pour une meilleure compréhension, nous avons structuré l'article comme suit :
- Qu'est-ce que l'entreposage de données ?
- Processus d'entrepôt de données
- Qu'est-ce que l'exploration de données ?
- Processus KDD
- Cas d'utilisation réels de l'exploration de données
Table des matières
Qu'est-ce que l'entreposage de données ?
Si nous devions définir Data Warehouse, cela peut être expliqué comme une collection de données intégrée, orientée sujet, variant dans le temps, non volatile. L'introduction à l'entreposage de données comprend également des données compilées provenant de sources externes. Le but de la conception d'un entrepôt est d'analyser et d'induire des décisions commerciales en rapportant des données à un niveau agrégé différent. Avant d'aller plus loin, regardons d'abord ce que signifient ces termes dans le contexte d'un entrepôt de données :
Orienté sujet
Les organisations peuvent utiliser l'entrepôt de données pour analyser un domaine spécifique. Supposons que vous souhaitiez voir les performances de votre équipe de vente au cours des 5 dernières années. Vous pouvez interroger votre entrepôt et il vous dira tout ce que vous devez savoir. Dans ce cas, les « ventes » peuvent être traitées comme un sujet.
Variant dans le temps
Les entrepôts de données sont responsables du stockage des données historiques des organisations. Par exemple, un système de transaction peut contenir l'adresse la plus récente d'un client, mais un entrepôt de données contiendra également toutes les adresses précédentes. Il continue d'ajouter en permanence des données provenant de diverses sources, en plus de conserver les données historiques - c'est ce qui en fait un modèle variant dans le temps. Les données stockées varieront toujours avec le temps.
Non volatile
Une fois que les données sont stockées dans un entrepôt de données, elles ne peuvent plus être altérées ou modifiées. Nous ne pouvons ajouter qu'une copie modifiée des données que nous voulons modifier.
Intégré:
Comme nous l'avons dit précédemment, un entrepôt de données contient des données provenant de plusieurs sources. Supposons que nous ayons deux sources de données - A et B. Les deux sources peuvent contenir des types de données complètement différents, mais lorsqu'elles sont amenées dans un entrepôt, elles sont soumises à un prétraitement. C'est ainsi qu'un entrepôt de données intègre des données provenant de plusieurs sources.
Processus d'entrepôt de données
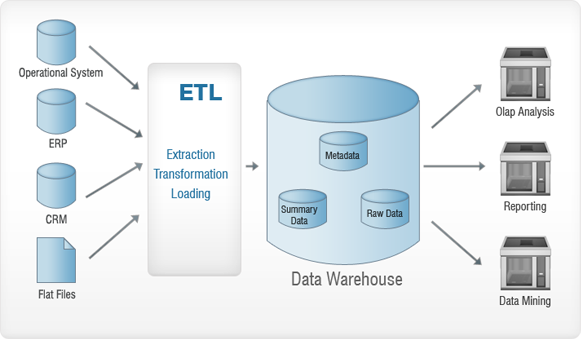
Jetez un oeil à l'image ci-dessus. Les données collectées à partir de diverses sources (système opérationnel, ERP, CRM, fichiers plats, etc.) sont soumises à un processus ETL avant d'être insérées dans l'entrepôt de données. Ceci est essentiellement fait pour supprimer les anomalies, le cas échéant, des données - afin qu'aucun dommage ne soit causé à l'entrepôt de données. ETL signifie - Extraction, Transformation et Chargement. Examinons en détail chacun de ces processus. Pour mieux comprendre, nous allons utiliser une analogie - pensez à une ruée vers l'or et lisez la suite !
Extraction
L'extraction est essentiellement effectuée pour collecter toutes les données requises à partir des systèmes sources en utilisant le moins de ressources possible.
Pensez à cette étape comme balayer la rivière à la recherche de pépites d'or aussi grosses que possible .
Transformation
L'objectif principal est d'insérer les données extraites dans la base de données dans un format général. En effet, différentes sources auront différents formats de stockage des données - par exemple, une source de données peut avoir des données au format "jj/mm/aaaa", et l'autre peut les avoir au format "jj-mm-aa". Dans cette étape, nous allons convertir cela dans un format généralisé - un format qui sera utilisé pour les données de toutes les sources.
Maintenant, vous avez une pépite d'or. Que fais-tu? Faites-le fondre et éliminez les impuretés.
Chargement
Dans cette étape, les données transformées sont chargées dans la base de données cible.
Maintenant que vous avez de l'or pur, moulez-le en un anneau et vendez-le !
Le processus consistant à importer des données de diverses sources et à les stocker dans l'entrepôt de données (après le processus ETL, bien sûr) est ce que l'on appelle l'entreposage de données.
Maintenant, vous avez vos données en place - toutes nettoyées et prêtes à l'emploi. Quelle devrait être la prochaine étape ? Extraire des connaissances – oui !
Le Data Mining à la rescousse !
Comment pouvez-vous passer à l'analyse de données ?Qu'est-ce que l'exploration de données ?
L'exploration de données est, tout simplement, le processus d'extraction d'informations auparavant inconnues mais potentiellement utiles à partir des ensembles de données. Par « précédemment inconnu », nous entendons des connaissances qui ne peuvent être acquises qu'après une exploration approfondie de l'entrepôt de données, c'est-à-dire qu'elles n'auront aucun sens en surface. L'exploration de données recherche essentiellement les modèles globaux de relations qui existent entre les éléments de données.
Par exemple, imaginez que vous dirigez un supermarché. Maintenant, l'historique d'achat d'un client peut ne pas sembler révéler grand-chose à première vue, mais s'il est analysé avec soin - en reconnaissant les modèles possibles, cette information suffit à en révéler beaucoup. Si vous ne l'avez pas encore deviné, nous parlons de Target - un supermarché qui a découvert qu'une adolescente (cliente) était enceinte simplement en étudiant attentivement son historique d'achat et en recherchant les tendances et les modèles. Ainsi, les informations qui semblaient si insignifiantes à la surface se sont avérées d'une telle valeur lorsqu'elles ont été soigneusement exploitées - et c'est exactement ce que nous entendons par "connaissances auparavant inconnues".
Nous pensons que ce serait injuste envers vous si nous vous donnions la saveur de l'entreposage de données et de l'exploration de données et ignorons complètement la vue d'ensemble - la découverte des connaissances dans les bases de données (KDD). L'exploration de données constitue l'une des étapes d'un processus KDD. Parlons un peu plus de KDD.

Obtenez une certification en science des données des meilleures universités du monde. Rejoignez nos programmes Executive PG, Advanced Certificate Programs ou Masters Programs pour accélérer votre carrière.
Découverte des connaissances dans les bases de données (KDD)
L'exploration de données est l'une des étapes les plus cruciales du processus de KDD. KDD couvre essentiellement tout, de la sélection des données à l'évaluation finale des données extraites. Le cycle KDD complet est illustré dans l'image ci-dessous :
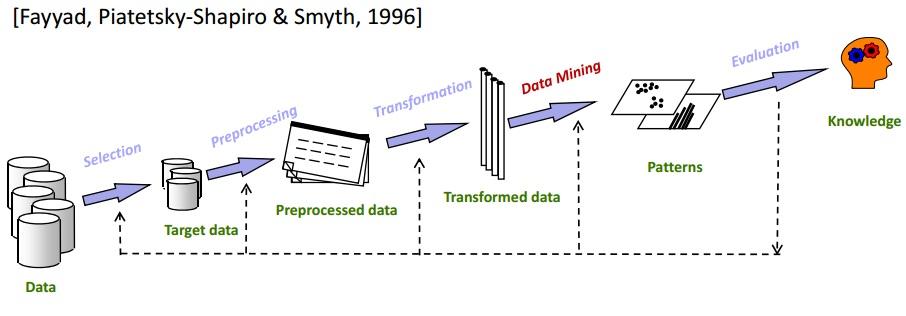
Sélection
Il est de la plus haute importance de connaître les données cibles exactes. L'analyse du sous-ensemble Data Mining vers Data Warehousing est une étape très importante car la suppression d'éléments de données non liés réduira l'espace de recherche pendant la phase de Data Mining .
Pré-traitement
Dans cette étape, les données sélectionnées sont débarrassées de toutes les anomalies et valeurs aberrantes. Fondamentalement, les données sont complètement nettoyées dans cette phase. Par exemple, s'il manque des champs de données, ils sont remplis avec les valeurs appropriées. Par exemple, dans le tableau qui stocke les détails des employés de votre organisation, supposons qu'il y ait une colonne pour « Deuxième prénom ». Il y a de fortes chances qu'il soit vide pour de nombreux employés. Dans un tel scénario, une valeur appropriée est choisie (N/A, par ex).
Transformation
Cette phase tente de réduire la variété des éléments de données tout en préservant la qualité des informations.
Exploration de données
Il s'agit de la phase principale d'un processus KDD. Les données transformées sont soumises à des méthodes d'exploration de données telles que le regroupement, le clustering, la régression, etc. Cela se fait de manière itérative pour obtenir les meilleurs résultats. Différentes techniques peuvent être utilisées selon les besoins.
Évaluation
C'est la dernière étape. En cela, les connaissances acquises sont documentées et présentées pour une analyse plus approfondie. Divers outils de visualisation de données sont utilisés dans cette étape pour décrire les connaissances acquises d'une manière belle et compréhensible.
Comment le paradoxe de Simpson affecte-t-il les données ?
Cas d'utilisation réels de l'exploration de données
Chaque organisation d'Amazon, Flipkart, Netflix, Facebook, Twitter, Instagram, même Walmart, fait bon usage de l'exploration de données. Dans cette section, nous parlerons de quatre grands cas d'utilisation du Data Mining qui font partie intégrante de votre vie quotidienne.
Les fournisseurs de services
Les fournisseurs de services de télécommunications utilisent l'exploration de données pour prédire le «churn» - un terme qu'ils utilisent lorsqu'un client les abandonne pour un autre fournisseur. En dehors de cela, ils rassemblent les informations de facturation, les visites de sites Web, les interactions avec le service client et d'autres éléments similaires pour donner à chaque client un score de probabilité. Ensuite, les clients qui présentent un risque plus élevé de « barattage » reçoivent des offres et des incitations.
Commerce électronique
Le commerce électronique est de loin le cas d'utilisation le plus connu en matière de Data Mining. L'un des plus célèbres d'entre eux est, bien sûr, Amazon. Ils utilisent des techniques minières extrêmement sophistiquées. Découvrez la fonctionnalité "Les personnes qui ont vu ce produit ont également aimé cela" par exemple !
Supermarchés
Les supermarchés sont également un cas d'utilisation intéressant du Data Mining. L'exploration de l'historique d'achat des clients leur permet de comprendre leurs habitudes d'achat. Ces informations sont ensuite utilisées par les supermarchés pour proposer des offres personnalisées aux clients. Oh, et vous avons-nous parlé de ce que Target a fait en utilisant le Data Mining ? (Oui!)
Vendre au détail
Les détaillants classent leurs clients dans des groupes de récence, de fréquence et monétaire (RFM). En utilisant l'exploration de données, ils ciblent le marketing sur ces groupes. Un client qui dépense peu mais fréquemment et dont le dernier achat est assez récent sera traité différemment d'un client qui a dépensé beaucoup mais une seule fois.
Emballer…
L'entreposage de données et l'exploration de données constituent deux des processus les plus importants qui dirigent littéralement le monde aujourd'hui. Presque chaque grande chose aujourd'hui est le résultat d'une exploration de données sophistiquée. Parce que les données non extraites sont aussi utiles (ou inutiles) que pas de données du tout.
Encore une fois, pour comprendre la différence entre l'exploration de données et l'entreposage de données, vous devez vous adonner, de l'introduction à l'exploration de données à l'entreposage de données, qui est une méthode centralisant toutes les données provenant de sources disparates dans une seule base de données. Nous pouvons définir l'entreposage de données comme des données historiques compilées ou un flux de données en temps réel qui renvoie principalement des informations organiques et intégrées.
Nous espérons que cet article vous a donné des éclaircissements sur ce qu'est l'entreposage de données et l'exploration de données et bien plus encore. Pour conclure, le processus de collecte, de stockage et d'organisation des informations dans une seule base de données est considéré comme l'entreposage de données par rapport à l'exploration de données consiste principalement à extraire des informations significatives des données en utilisant une perspective différente. Toutes les informations utiles collectées peuvent être utilisées par la suite pour résoudre de futurs problèmes qui pourraient constituer un obstacle à la croissance de l'entreprise et même réduire les coûts. Si vous êtes à la recherche d'un avenir brillant et fascinant et si l'exploration est votre passion, commencer par apprendre le quoi de l'entreposage de données et de l'exploration de données serait une excellente option pour vous.
Nous espérons que cet article vous a éclairé sur la signification de ces deux termes et bien plus encore ! Si vous êtes curieux d'en savoir plus sur la science des données, consultez le diplôme PG de IIIT-B & upGrad en science des données qui est créé pour les professionnels en activité et propose plus de 10 études de cas et projets, des ateliers pratiques, un mentorat avec des experts de l'industrie, 1- on-1 avec des mentors de l'industrie, plus de 400 heures d'apprentissage et d'aide à l'emploi avec les meilleures entreprises.
Comment les entreprises utilisent-elles le Data Warehousing et le Data Mining ?
L'exploration de données et l'entreposage de données sont des techniques d'intelligence d'affaires permettant de transformer des informations (ou des données) en connaissances utilisables.
L'exploration de données est une méthode d'analyse statistique. Les outils techniques sont utilisés par les analystes pour interroger et trier des gigaoctets de données à la recherche de tendances. Les entreprises utilisent ensuite ces données pour prendre de meilleures décisions commerciales en fonction de leur compréhension des comportements de leurs consommateurs et fournisseurs.
L'entreposage de données est le processus de conception de la manière dont les données sont stockées afin de faciliter la création de rapports et l'analyse. Selon les spécialistes des entrepôts de données, les nombreux magasins de données sont à la fois conceptuellement et physiquement intégrés et liés les uns aux autres. Les données d'une entreprise sont généralement enregistrées dans plusieurs bases de données.
Quelle est la principale différence entre l'entreposage de données et l'exploration de données ? Qu'est-ce qui est le plus pratique dans le monde des affaires ?
Un entrepôt de données est un système de stockage de données. Cela implique généralement une variété de types de données acquises à partir de plusieurs sources pour une variété d'objectifs. Le processus de stockage de ces données avec discipline afin qu'elles puissent être récupérées ultérieurement est connu sous le nom d'entreposage de données.
Le processus d'extraction de données est connu sous le nom d'exploration de données. Il s'agit de localiser les informations les plus pertinentes pour un objectif particulier. Cela peut provenir de votre entrepôt de données ou d'un autre endroit. Vous prévoyez d'affiner et de nettoyer les données que vous extrayez, comme vous le feriez avec du vrai minerai.
Plus vos systèmes d'entreposage sont bons, plus il sera facile d'exploiter.
Le Data Mining et le processus KDD sont-ils similaires ?
Bien que KDD et Data Mining soient les termes fréquemment échangés, ils font référence à deux concepts distincts mais liés.
L'exploration de données est un composant du processus KDD qui traite de la reconnaissance de modèles dans les données, tandis que KDD est l'ensemble du processus d'extraction de connaissances à partir de données. En d'autres termes, le Data Mining n'est que l'application d'un algorithme spécifique pour atteindre l'objectif ultime du processus KDD.