
Co to jest magazynowanie danych i eksploracja danych
Opublikowany: 2018-02-22Dane korporacyjne były przechowywane w silosach informacyjnych, które były fizycznie odseparowane od innych repozytoriów danych, a każdy z nich pełnił wyspecjalizowane funkcje – ale to było zanim Big Data uderzyło w świat (jeśli można tak powiedzieć, przez burzę). Teraz praktycznie niemożliwe jest ćwiczenie tych samych metod na tak dużych zbiorach danych. Wystarczy wyobrazić sobie liczbę wyciągów danych, których wymagałoby to z tak wielu fizycznie odseparowanych silosów informacji – tylko po to, aby uruchomić proste zapytanie. Wszystko dzięki niezwykle ogromnemu stosowi danych, które znajdują się w organizacjach i metodach inżynierii Big Data.
Przyjrzyjmy się uważnie, w jaki sposób hurtownia danych i eksploracja danych wkracza na scenę. Hurtownie danych zostały opracowane w celu zwalczania tego problemu przechowywania danych. Zasadniczo hurtownie danych można traktować jako ujednolicone repozytorium danych pochodzących z różnych źródeł i w różnych formatach. Z kolei Data Mining to proces wydobywania wiedzy ze wspomnianej Hurtowni Danych.
W tym artykule przyjrzymy się szczegółowo hurtowni danych i eksploracji danych. Dla lepszego zrozumienia zorganizowaliśmy artykuł w następujący sposób:
- Co to jest hurtownia danych?
- Procesy hurtowni danych
- Co to jest eksploracja danych?
- Proces KDD
- Rzeczywiste przypadki użycia eksploracji danych
Spis treści
Co to jest hurtownia danych?
Gdybyśmy mieli zdefiniować Hurtownię Danych, można by ją wyjaśnić jako zorientowany na przedmiot, zmienny w czasie, nieulotny, zintegrowany zbiór danych. Wprowadzenie do hurtowni danych obejmuje również dane kompilowane ze źródeł zewnętrznych. Celem projektowania Hurtowni jest analiza i wywoływanie decyzji biznesowych poprzez raportowanie danych na innym poziomie zagregowanym. Zanim przejdziemy dalej, przyjrzyjmy się najpierw, co te terminy oznaczają w kontekście hurtowni danych:
Zorientowany na temat
Organizacje mogą używać Hurtowni danych do analizowania określonego obszaru tematycznego. Załóżmy, że chcesz zobaczyć, jak dobrze Twój zespół sprzedaży radził sobie w ciągu ostatnich 5 lat – możesz zapytać magazyn, a powie Ci wszystko, co musisz wiedzieć. W tym przypadku „sprzedaż” może być traktowana jako przedmiot.
Wariant czasowy
Hurtownie danych są odpowiedzialne za przechowywanie danych historycznych dla organizacji. Na przykład system transakcyjny może przechowywać najnowszy adres klienta, ale hurtownia danych będzie również przechowywać wszystkie poprzednie adresy. Ciągle dodaje dane z różnych źródeł, oprócz danych historycznych – to sprawia, że jest to model zmienny w czasie. Przechowywane dane zawsze będą się zmieniać w czasie.
Nielotny
Gdy dane są przechowywane w hurtowni danych, nie można ich zmieniać ani modyfikować. Możemy dodać tylko zmodyfikowaną kopię danych, które chcemy zmodyfikować.
Zintegrowany:
Jak powiedzieliśmy wcześniej, hurtownia danych przechowuje dane z wielu źródeł. Załóżmy, że mamy dwa źródła danych – A i B. Oba źródła mogą zawierać całkowicie różne typy danych, ale kiedy trafiają do magazynu, są poddawane wstępnemu przetwarzaniu. W ten sposób Hurtownia Danych integruje dane z wielu źródeł.
Procesy hurtowni danych
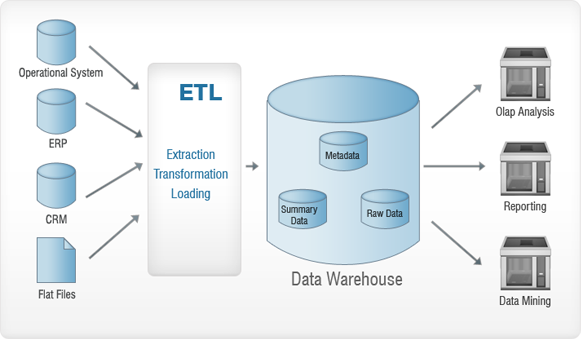
Spójrz na powyższy obrazek. Dane zbierane z różnych źródeł (system operacyjny, ERP, CRM, Flat Files itp.) są poddawane procesowi ETL przed umieszczeniem ich w hurtowni danych. Odbywa się to zasadniczo w celu usunięcia ewentualnych anomalii z danych – tak, aby nie wyrządzić szkody hurtowni danych. ETL to skrót od – Extraction, Transformation i Loading. Przyjrzyjmy się szczegółowo każdemu z tych procesów. Aby lepiej zrozumieć, użyjemy analogii – pomyśl o gorączce złota i czytaj dalej!
Ekstrakcja
Ekstrakcja jest zasadniczo wykonywana w celu zebrania wszystkich wymaganych danych z systemów źródłowych przy użyciu jak najmniejszej ilości zasobów.
Pomyśl o tym kroku jak o płukaniu rzeki w poszukiwaniu jak największych bryłek złota .
Transformacja
Głównym celem jest wstawienie wyodrębnionych danych do bazy danych w ogólnym formacie. Dzieje się tak, ponieważ różne źródła będą miały różne formaty przechowywania danych — na przykład jedno źródło danych może mieć dane w formacie „dd/mm/rrrr”, a drugie może mieć je w formacie „dd-mm-rr”. W tym kroku przekonwertujemy to do formatu uogólnionego — takiego, który będzie używany do danych ze wszystkich źródeł.
Teraz masz samorodek złota. Co robisz? Rozpuść go i usuń zanieczyszczenia.
Ładowanie
Na tym etapie przekształcone dane są ładowane do docelowej bazy danych.
Teraz masz czyste złoto – uformuj pierścionek i sprzedaj!
Proces pobierania danych z różnych źródeł i przechowywania ich w Hurtowni Danych (oczywiście po procesie ETL) to tak zwana hurtownia danych.
Teraz masz już swoje dane – wszystko wyczyszczone i gotowe do pracy. Jaki powinien być następny krok? Wydobywanie wiedzy – tak!
Eksploracja danych na ratunek!
Jak przejść do analizy danych?Co to jest eksploracja danych?
Data Mining to po prostu proces wydobywania nieznanych wcześniej, ale potencjalnie użytecznych informacji ze zbiorów danych. Przez „wcześniej nieznaną” rozumiemy wiedzę, którą można zdobyć dopiero po głębokiej eksploracji hurtowni danych – czyli z pozoru nie będzie miała sensu. Data Mining zasadniczo wyszukuje globalne wzorce relacji, które istnieją między elementami danych.
Na przykład wyobraź sobie, że prowadzisz supermarket. Otóż historia zakupów klienta może na pierwszy rzut oka nie zdradzać wiele, ale jeśli przeanalizuje się ją uważnie – rozpoznając możliwe wzorce, to już sama ta informacja wystarczy, by wiele zdradzić. Jeśli jeszcze tego nie zgadłeś, mówimy o Target – supermarkecie, który odkrył, że nastoletnia dziewczyna (klientka) jest w ciąży, po prostu dokładnie studiując jej historię zakupów i szukając trendów i wzorów. Tak więc informacje, które na pierwszy rzut oka wydawały się tak trywialne, okazały się tak cenne, gdy się je starannie pozyskało – i właśnie to rozumiemy przez „wiedzy wcześniej nieznanej”.
Uważamy, że będzie to niesprawiedliwe, jeśli damy Ci posmak hurtowni danych i eksploracji danych i całkowicie zignorujemy duży obraz — odkrywanie wiedzy w bazach danych (KDD). Eksploracja danych stanowi jeden z etapów procesu KDD. Porozmawiajmy nieco więcej o KDD.

Zdobądź certyfikat nauk o danych z najlepszych światowych uniwersytetów. Dołącz do naszych programów Executive PG, Advanced Certificate Programs lub Masters, aby przyspieszyć swoją karierę.
Odkrywanie wiedzy w bazach danych (KDD)
Eksploracja danych to jeden z ważniejszych etapów procesu KDD. KDD zasadniczo obejmuje wszystko, od selekcji danych do ostatecznej oceny wydobytych danych. Pełny cykl KDD pokazano na poniższym obrazku:
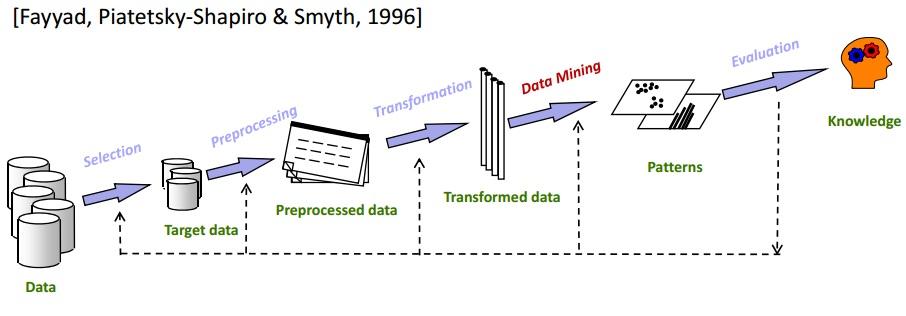
Wybór
Niezwykle ważna jest znajomość dokładnych danych docelowych. Analiza podzbioru Data Mining do Data Warehousing jest bardzo ważnym krokiem, ponieważ usunięcie niepowiązanych elementów danych zmniejszy przestrzeń wyszukiwania w fazie Data Mining .
Wstępne przetwarzanie
Na tym etapie wybrane dane są uwalniane od wszelkich anomalii i wartości odstających. Zasadniczo w tej fazie dane są całkowicie czyszczone. Na przykład, jeśli brakuje niektórych pól danych, są one wypełniane odpowiednimi wartościami. Załóżmy na przykład, że w tabeli, w której są przechowywane dane pracowników Twojej organizacji, znajduje się kolumna „Drugie imię”. Są szanse, że dla wielu pracowników będzie pusty. W takim scenariuszu wybierana jest odpowiednia wartość (nie dotyczy, na przykład).
Transformacja
Ta faza ma na celu zmniejszenie różnorodności elementów danych przy jednoczesnym zachowaniu jakości informacji.
Eksploracja danych
To jest główna faza procesu KDD. Przekształcone dane są poddawane metodom eksploracji danych, takim jak grupowanie, grupowanie, regresja itp. Odbywa się to iteracyjnie, aby uzyskać najlepsze wyniki. W zależności od wymagań można zastosować różne techniki.
Ocena
To jest ostatni krok. W tym przypadku uzyskana wiedza jest dokumentowana i przedstawiana do dalszej analizy. Na tym etapie wykorzystywane są różne narzędzia do wizualizacji danych, aby w piękny i zrozumiały sposób przedstawić zdobytą wiedzę.
Jak paradoks Simpsona wpływa na dane?
Rzeczywiste przypadki użycia eksploracji danych
Każda organizacja, od Amazon, Flipkart, Netflix, po Facebooka, Twittera, Instagram, a nawet Walmart, dobrze wykorzystuje Data Mining. W tej sekcji omówimy cztery szerokie przypadki użycia Data Mining, które są integralną częścią Twojego codziennego życia.
Usługodawcy
Dostawcy usług telekomunikacyjnych wykorzystują Data Mining do przewidywania „odpływu” – terminu używanego przez nich, gdy klient porzuca ich dla innego dostawcy. Oprócz tego zestawiają informacje rozliczeniowe, wizyty w witrynie, interakcje z obsługą klienta i inne tego typu rzeczy, aby dać każdemu klientowi ocenę prawdopodobieństwa. Następnie ci klienci, którzy są bardziej narażeni na odejście, otrzymują oferty i zachęty.
Handel elektroniczny
Handel elektroniczny jest najbardziej znanym przypadkiem użycia, jeśli chodzi o Data Mining. Jednym z najbardziej znanych jest oczywiście Amazon. Wykorzystują niezwykle wyrafinowane techniki wydobywcze. Sprawdź na przykład funkcję „Osoby, które oglądały ten produkt, też polubiły ten”!
Supermarkety
Supermarkety są również interesującym przypadkiem użycia Data Mining. Eksploracja historii zakupów klientów pozwala im zrozumieć ich wzorce zakupowe. Te informacje są następnie wykorzystywane przez supermarkety do dostarczania klientom spersonalizowanych ofert. Aha, a czy mówiliśmy ci o tym, co Target zrobił przy użyciu Data Mining? (Tak zrobiliśmy!)
Sprzedaż detaliczna
Detaliści grupują swoich klientów w grupy Recency, Frequency i Monetary (RFM). Korzystając z Data Mining, kierują marketing do tych grup. Klient, który wydaje niewiele, ale często, a jego ostatni zakup był stosunkowo nowy, będzie traktowany inaczej niż klient, który wydał dużo, ale tylko raz.
Podsumowanie…
Magazynowanie danych i eksploracja danych to dwa najważniejsze procesy, które dosłownie rządzą dzisiejszym światem. Prawie każda wielka rzecz w dzisiejszych czasach jest wynikiem zaawansowanej eksploracji danych. Ponieważ niezbadane dane są tak samo przydatne (lub bezużyteczne), jak ich brak.
Ponownie, aby zrozumieć różnicę między eksploracją danych a magazynowaniem danych, musisz sobie pozwolić, od wprowadzenia do eksploracji danych do hurtowni danych — która jest metodą, która polega na centralizacji danych z różnych źródeł w jednej bazie danych. Magazynowanie danych możemy zdefiniować jako skompilowane dane historyczne lub źródło danych w czasie rzeczywistym, które dostarcza głównie organiczne i zintegrowane informacje.
Mamy nadzieję, że ten artykuł wyjaśnił Ci, czym jest hurtownia danych, eksploracja danych i wiele więcej. Podsumowując, proces gromadzenia, przechowywania i organizowania informacji w jednej bazie danych jest uważany za taki, jak hurtownia danych vs. eksploracja danych polega głównie na wydobywaniu istotnych informacji z danych przy użyciu innej perspektywy. Wszystkie zebrane przydatne informacje można później wykorzystać do rozwiązywania przyszłych problemów, które mogą stanowić przeszkodę w rozwoju firmy, a nawet obniżyć koszty. Jeśli szukasz świetlanej i fascynującej przyszłości, a eksploracja jest Twoją pasją, rozpoczęcie od nauki hurtowni danych i eksploracji danych będzie dla Ciebie doskonałą opcją.
Mamy nadzieję, że ten artykuł wyjaśnił ci, co oznaczają te dwa terminy i wiele więcej! Jeśli jesteś zainteresowany nauką o danych, sprawdź IIIT-B i upGrad's PG Diploma in Data Science, który jest stworzony dla pracujących profesjonalistów i oferuje ponad 10 studiów przypadków i projektów, praktyczne warsztaty praktyczne, mentoring z ekspertami z branży, 1- on-1 z mentorami branżowymi, ponad 400 godzin nauki i pomocy w pracy z najlepszymi firmami.
W jaki sposób firmy korzystają z hurtowni danych i eksploracji danych?
Zarówno eksploracja danych, jak i hurtownie danych to techniki analizy biznesowej służące do przekształcania informacji (lub danych) w użyteczną wiedzę.
Eksploracja danych to metoda analizy statystycznej. Narzędzia techniczne są używane przez analityków do wyszukiwania i sortowania gigabajtów danych w poszukiwaniu trendów. Firmy wykorzystują następnie te dane do podejmowania lepszych decyzji biznesowych w oparciu o zrozumienie zachowań swoich konsumentów i dostawców.
Magazynowanie danych to proces projektowania sposobu przechowywania danych w celu ułatwienia raportowania i analizy. Według specjalistów od hurtowni danych, liczne magazyny danych są zintegrowane koncepcyjnie i fizycznie oraz powiązane ze sobą. Dane firmy są zazwyczaj zapisywane w wielu bazach danych.
Jaka jest podstawowa różnica między magazynowaniem danych a eksploracją danych? Co jest bardziej praktyczne w świecie biznesu?
Hurtownia danych to system przechowywania danych. Zwykle wiąże się to z różnymi rodzajami danych pozyskiwanych z wielu źródeł dla różnych celów. Proces przechowywania tych danych z dyscypliną, tak aby można je było później odzyskać, nazywa się magazynowaniem danych.
Proces wydobywania danych jest znany jako eksploracja danych. Polega na zlokalizowaniu najbardziej istotnych informacji dla konkretnego celu. Może pochodzić z hurtowni danych lub z innego miejsca. Przewidujesz dopracowanie i oczyszczenie danych, które wydobywasz, tak jak w przypadku prawdziwej rudy.
Im lepsze są twoje systemy magazynowe, tym łatwiej będzie je wydobywać.
Czy proces Data Mining i KDD są podobne?
Chociaż KDD i Data Mining to terminy często wymieniane, odnoszą się one do dwóch odrębnych, ale powiązanych ze sobą pojęć.
Data Mining to element procesu KDD zajmujący się rozpoznawaniem wzorców w danych, natomiast KDD to cały proces wydobywania wiedzy z danych. Innymi słowy, Data Mining to po prostu zastosowanie określonego algorytmu do osiągnięcia ostatecznego celu procesu KDD.