
El qué es qué del almacenamiento de datos y la minería de datos
Publicado: 2018-02-22Los datos de la empresa se almacenaban en silos de información que estaban físicamente separados de otros repositorios de datos, y cada silo cumplía funciones especializadas, pero eso fue antes de que Big Data golpeara el mundo (por una tormenta, por así decirlo). Ahora, es prácticamente imposible practicar los mismos métodos en conjuntos de datos tan grandes. Solo imagine la cantidad de extracciones de datos que requeriría de tantos silos de información separados físicamente, solo para ejecutar una consulta simple. Todo gracias a la enorme cantidad de datos que se encuentran en las organizaciones y los métodos de ingeniería de big data.
Prestemos atención a cómo entra en escena el almacenamiento de datos y la minería de datos . Los almacenes de datos se desarrollaron para combatir este problema de almacenamiento de datos. Esencialmente, los almacenes de datos se pueden considerar como un depósito unificado de datos que provienen de varias fuentes y se encuentran en varios formatos. La minería de datos, por otro lado, es el proceso de extracción de conocimiento de dicho almacén de datos.
En este artículo, analizaremos en detalle el almacenamiento de datos y la minería de datos. Para una mejor comprensión, hemos estructurado el artículo de la siguiente manera:
- ¿Qué es el almacenamiento de datos?
- Procesos de almacenamiento de datos
- ¿Qué es la minería de datos?
- Proceso KDD
- Casos de uso de la vida real de la minería de datos
Tabla de contenido
¿Qué es el almacenamiento de datos?
Si tuviéramos que definir Data Warehouse, se puede explicar como una colección de datos integrada, no volátil, variable en el tiempo y orientada a temas. La introducción al almacenamiento de datos también comprende datos recopilados de fuentes externas. El propósito de diseñar un Almacén es analizar e inducir decisiones comerciales al informar datos en un nivel agregado diferente. Antes de seguir adelante, primero veamos qué significan estos términos en el contexto de un almacén de datos:
Orientado al sujeto
Las organizaciones pueden utilizar el almacén de datos para analizar un área temática específica. Suponga que desea ver qué tan bien se ha desempeñado su equipo de ventas en los últimos 5 años: puede consultar su Almacén y le dirá todo lo que necesita saber. En este caso, las "ventas" pueden tratarse como un tema.
Variante de tiempo
Los almacenes de datos son responsables de almacenar datos históricos para las organizaciones. Por ejemplo, un sistema de transacciones puede contener la dirección más reciente de un cliente, pero un almacén de datos también puede contener todas las direcciones anteriores. Continuamente agrega datos de varias fuentes, además de mantener los datos históricos, eso es lo que lo convierte en un modelo variable en el tiempo. Los datos almacenados siempre variarán con el tiempo.
No volátil
Una vez que los datos se almacenan en un almacén de datos, no se pueden alterar ni modificar. Solo podemos añadir una copia modificada de los datos que queremos modificar.
Integrado:
Como dijimos anteriormente, un almacén de datos contiene datos de múltiples fuentes. Digamos que tenemos dos fuentes de datos: A y B. Ambas fuentes pueden tener tipos de datos completamente diferentes almacenados en ellas, pero cuando se llevan a un almacén, se someten a un procesamiento previo. Así es como un almacén de datos integra datos de varias fuentes.
Procesos de almacenamiento de datos
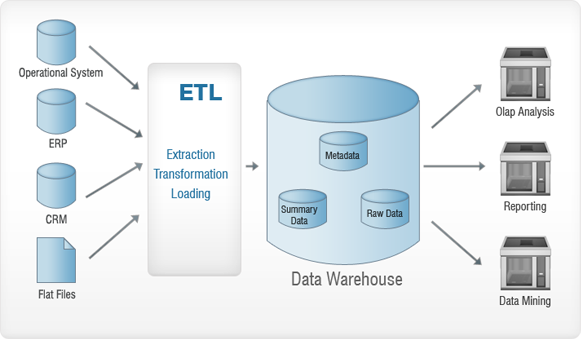
Echa un vistazo a la imagen de arriba. Los datos que se recopilan de varias fuentes (sistema operativo, ERP, CRM, Flat Files, etc.) se someten a un proceso ETL antes de insertarse en el almacén de datos. Esto se hace esencialmente para eliminar anomalías, si las hay, de los datos, de modo que no se causen daños al almacén de datos. ETL significa: extracción, transformación y carga. Echemos un vistazo a cada uno de estos procesos en detalle. Para entenderlo mejor, usaremos una analogía: ¡piense en la fiebre del oro y siga leyendo!
Extracción
La extracción se realiza esencialmente para recopilar todos los datos necesarios de los sistemas de origen utilizando la menor cantidad de recursos posible.
Piense en este paso como recorrer el río en busca de pepitas de oro lo más grandes posible .
Transformación
El objetivo principal es insertar los datos extraídos en la base de datos en un formato general. Esto se debe a que diferentes fuentes tendrán diferentes formatos de almacenamiento de datos; por ejemplo, una fuente de datos puede tener datos en formato "dd/mm/aaaa" y la otra puede tenerlos en formato "dd-mm-aa". En este paso, convertiremos esto a un formato generalizado, uno que se usará para datos de todas las fuentes.
Ahora tienes una pepita de oro. ¿A qué te dedicas? Derrítelo y elimina las impurezas.
Cargando
En este paso, los datos transformados se cargan en la base de datos de destino.
Ahora tienes oro puro: ¡moldéalo en un anillo y véndelo!
El proceso de traer datos de varias fuentes y almacenarlos en el Data Warehouse (después del proceso ETL, por supuesto), es lo que se conoce como Data Warehousing.
Ahora, tiene sus datos en su lugar, todos limpios y listos para usar. ¿Cuál debería ser el siguiente paso? Extraer conocimiento – ¡sí!
¡Minería de datos al rescate!
¿Cómo puede hacer la transición al análisis de datos?¿Qué es la minería de datos?
La minería de datos es, simplemente, el proceso de extraer información previamente desconocida pero potencialmente útil de los conjuntos de datos. Por "anteriormente desconocido", nos referimos al conocimiento que se puede adquirir solo después de realizar una exploración profunda del almacén de datos, es decir, no tendrá sentido en la superficie. La minería de datos esencialmente busca los patrones globales de relaciones que existen entre los elementos de datos.
Por ejemplo, imagina que tienes un supermercado. Ahora bien, es posible que el historial de compras de un cliente no parezca revelar mucho en la superficie, pero si se analiza cuidadosamente, reconociendo los posibles patrones, entonces esta información es suficiente para revelar mucho. Si aún no lo ha adivinado, estamos hablando de Target, un supermercado que descubrió que una adolescente (cliente) estaba embarazada simplemente estudiando cuidadosamente su historial de compras y buscando tendencias y patrones. Entonces, la información que parecía tan trivial en la superficie resultó ser de mucho valor cuando se extrajo con cuidado, y eso es exactamente lo que queremos decir con "conocimiento previamente desconocido".
Sentimos que sería injusto para usted si le damos el sabor del almacenamiento de datos y la minería de datos e ignoramos por completo el panorama general: descubrimiento de conocimiento en bases de datos (KDD). La minería de datos forma uno de los pasos de un proceso KDD. Hablemos un poco más sobre KDD.

Obtenga una certificación en ciencia de datos de las mejores universidades del mundo. Únase a nuestros programas Executive PG, programas de certificación avanzada o programas de maestría para acelerar su carrera.
Descubrimiento de conocimiento en bases de datos (KDD)
La minería de datos es uno de los pasos más cruciales en el proceso de KDD. KDD básicamente cubre todo, desde la selección de datos hasta la evaluación final de los datos extraídos. El ciclo completo de KDD se muestra en la siguiente imagen:
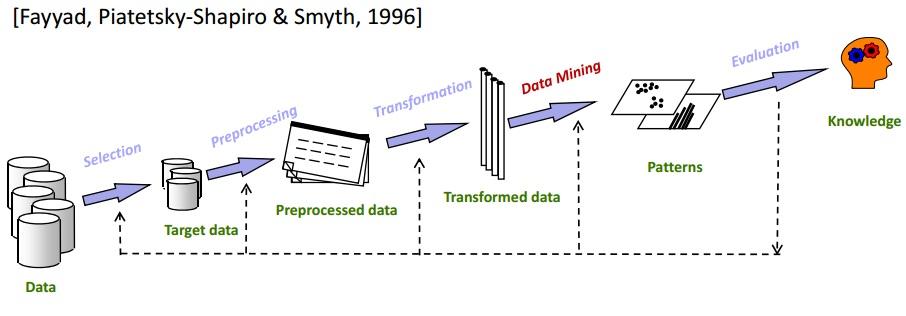
Selección
Es de suma importancia conocer los datos exactos del objetivo. El análisis del subconjunto de minería de datos a almacenamiento de datos es un paso muy importante porque la eliminación de elementos de datos no relacionados reducirá el espacio de búsqueda durante la fase de minería de datos .
Preprocesamiento
En este paso, los datos seleccionados se liberan de anomalías y valores atípicos. Básicamente, los datos se limpian por completo en esta fase. Por ejemplo, si faltan algunos campos de datos, se llenan con los valores apropiados. Por ejemplo, en la tabla que almacena los detalles de los empleados de su organización, suponga que hay una columna para "Segundo nombre". Lo más probable es que esté vacío para muchos empleados. En tal escenario, se elige un valor apropiado (N/A, por ejemplo).
Transformación
Esta fase intenta reducir la variedad de elementos de datos preservando la calidad de la información.
Procesamiento de datos
Esta es la fase principal de un proceso KDD. Los datos transformados se someten a métodos de minería de datos como agrupación, agrupación, regresión, etc. Esto se hace de forma iterativa para obtener los mejores resultados. Se pueden utilizar diferentes técnicas dependiendo de los requisitos.
Evaluación
Este es el paso final. En este, el conocimiento obtenido se documenta y presenta para su posterior análisis. Varias herramientas de visualización de datos se utilizan en este paso para representar el conocimiento adquirido de una manera hermosa y comprensible.
¿Cómo afecta la paradoja de Simpson a los datos?
Casos de uso de la vida real de la minería de datos
Todas las organizaciones, desde Amazon, Flipkart, Netflix, hasta Facebook, Twitter, Instagram e incluso Walmart, están haciendo un buen uso de la minería de datos. En esta sección, hablaremos sobre cuatro amplios casos de uso de minería de datos que son una parte integral de su vida cotidiana.
Proveedores de servicio
Los proveedores de servicios de telecomunicaciones utilizan la minería de datos para predecir la "abandono", un término que utilizan cuando un cliente los abandona por otro proveedor. Aparte de eso, recopilan información de facturación, visitas al sitio web, interacciones de atención al cliente y otras cosas similares para dar a cada cliente un puntaje de probabilidad. Luego, aquellos clientes que corren un mayor riesgo de "abandono" reciben ofertas e incentivos.
comercio electrónico
El comercio electrónico es fácilmente el caso de uso más conocido cuando se trata de minería de datos. Uno de los más famosos es, por supuesto, Amazon. Utilizan técnicas de minería extremadamente sofisticadas. Echa un vistazo a la funcionalidad "A las personas que vieron ese producto, también les gustó este", por ejemplo.
supermercados
Los supermercados también son un caso de uso interesante de la minería de datos. La extracción del historial de compras de los clientes les permite comprender sus patrones de compra. Esta información es luego utilizada por los supermercados para ofrecer ofertas personalizadas a los clientes. Ah, ¿y les contamos qué hizo Target con la minería de datos? (¡Si lo hicimos!)
Venta minorista
Los minoristas agrupan a sus clientes en grupos de Recency, Frequency y Monetary (RFM). Mediante la minería de datos, dirigen el marketing a estos grupos. Un cliente que gasta poco pero con frecuencia y su última compra fue bastante reciente será tratado de manera diferente que un cliente que gastó mucho pero solo una vez.
Terminando…
El almacenamiento de datos y la minería de datos constituyen dos de los procesos más importantes que están funcionando literalmente en el mundo de hoy. Casi todo lo importante hoy en día es el resultado de una sofisticada extracción de datos. Porque los datos no extraídos son tan útiles (o inútiles) como no tener ningún dato.
Nuevamente, para comprender la diferencia entre la minería de datos y el almacenamiento de datos, debe darse el gusto, desde la introducción a la minería de datos hasta el almacenamiento de datos, que es un método que centraliza los datos de fuentes dispares en una base de datos. Podemos definir el almacenamiento de datos como datos históricos compilados o alimentación de datos en tiempo real que devuelve información principalmente orgánica e integrada.
Esperamos que este artículo le haya aclarado qué es el almacenamiento de datos, la minería de datos y mucho más. Para concluir, el proceso de recopilar, almacenar y organizar información en una sola base de datos se considera como Data Warehousing vs. Data Mining, que consiste principalmente en extraer información significativa de los datos utilizando una perspectiva diferente. Toda la información útil que se recopila se puede utilizar posteriormente para resolver problemas futuros que pueden ser un obstáculo en el crecimiento de la empresa e incluso pueden reducir costos. Si está buscando un futuro brillante y fascinante y si la exploración es su pasión, comenzar a aprender el qué es qué del almacenamiento de datos y la minería de datos sería una excelente opción para usted.
¡Esperamos que este artículo te haya aclarado lo que significan estos dos términos y mucho más! Si tiene curiosidad por aprender sobre ciencia de datos, consulte el Diploma PG en ciencia de datos de IIIT-B y upGrad, creado para profesionales que trabajan y ofrece más de 10 estudios de casos y proyectos, talleres prácticos, tutoría con expertos de la industria, 1- on-1 con mentores de la industria, más de 400 horas de aprendizaje y asistencia laboral con las mejores empresas.
¿Cómo utilizan las empresas el almacenamiento de datos y la minería de datos?
Tanto la minería de datos como el almacenamiento de datos son técnicas de inteligencia comercial para transformar información (o datos) en conocimiento utilizable.
La minería de datos es un método de análisis estadístico. Los analistas utilizan herramientas técnicas para consultar y clasificar gigabytes de datos en busca de tendencias. Luego, las empresas utilizan estos datos para tomar mejores decisiones comerciales en función de su comprensión de los comportamientos de sus consumidores y proveedores.
El almacenamiento de datos es el proceso de diseñar cómo se almacenan los datos para facilitar la elaboración de informes y el análisis. Según los especialistas en almacenamiento de datos, los numerosos almacenes de datos están tanto conceptual como físicamente integrados y relacionados entre sí. Los datos de una empresa normalmente se guardan en múltiples bases de datos.
¿Cuál es la diferencia central entre el almacenamiento de datos y la minería de datos? ¿Cuál es más práctico en el mundo de los negocios?
Un almacén de datos es un sistema de almacenamiento de datos. Por lo general, implica una variedad de tipos de datos adquiridos de múltiples fuentes para una variedad de objetivos. El proceso de almacenar estos datos con disciplina para que puedan recuperarse más tarde se conoce como almacenamiento de datos.
El proceso de extracción de datos se conoce como minería de datos. Implica localizar la información más pertinente para un objetivo en particular. Puede provenir de su almacén de datos o de algún otro lugar por completo. Anticipa refinar y limpiar los datos que extrae, tal como lo haría con el mineral real.
Cuanto mejores sean sus sistemas de almacenamiento, más fácil será extraerlos.
¿Son similares los procesos de minería de datos y KDD?
Aunque KDD y Data Mining son los términos que se intercambian con frecuencia, se refieren a dos conceptos distintos pero relacionados.
La minería de datos es un componente dentro del proceso KDD que se ocupa del reconocimiento de patrones en los datos, mientras que KDD es todo el proceso de extracción de conocimiento de los datos. Para decirlo de otra manera, la minería de datos es solo la aplicación de un algoritmo específico para lograr el propósito final del proceso KDD.