
データウェアハウジングとデータマイニングの概要
公開: 2018-02-22エンタープライズデータは、他のデータリポジトリから物理的に離れた情報サイロに保存され、各サイロは特殊な機能を果たしましたが、それはビッグデータが世界に打撃を与える前のことでした(言うまでもなく嵐によって)。 現在、このような大規模なデータセットで同じ方法を実行することは事実上不可能です。 単純なクエリを実行するためだけに、このような物理的に分離された情報サイロの多くから必要となるデータ抽出の数を想像してみてください。 組織とビッグデータエンジニアリング手法にある非常に大量のデータのおかげです。
データウェアハウジングとデータマイニングがどのように登場するかを注意深く見守っていきましょう。 データウェアハウスは、このデータストレージの問題に対処するために開発されました。 基本的に、データウェアハウスは、さまざまなソースからのさまざまな形式のデータの統合リポジトリと考えることができます。 一方、データマイニングは、前述のデータウェアハウスから知識を抽出するプロセスです。
この記事では、データウェアハウスとデータマイニングについて詳しく見ていきます。 理解を深めるために、記事は次のように構成されています。
- データウェアハウジングとは何ですか?
- データウェアハウスプロセス
- データマイニングとは何ですか?
- KDDプロセス
- 実際の使用-データマイニングの事例
目次
データウェアハウジングとは何ですか?
データウェアハウスを定義する場合、それはサブジェクト指向、時変、不揮発性、統合されたデータのコレクションとして説明できます。 データウェアハウスの概要には、外部ソースからのコンパイル済みデータも含まれます。 ウェアハウスを設計する目的は、さまざまな集計レベルでデータをレポートすることにより、ビジネス上の意思決定を分析および誘導することです。 ここから先に進む前に、まず、データウェアハウスのコンテキストでこれらの用語が何を意味するかを見てみましょう。
サブジェクト指向。
組織は、データウェアハウスを使用して特定のサブジェクト領域を分析できます。 過去5年間の営業チームの業績を確認したいとします。倉庫に問い合わせると、知っておく必要のあるすべてのことがわかります。 この場合、「販売」を対象として扱うことができます。
時変
データウェアハウスは、組織の履歴データを保存する責任があります。 たとえば、トランザクションシステムは顧客の最新の住所を保持できますが、データウェアハウスは以前のすべての住所も保持します。 履歴データを保持することは別として、さまざまなソースからのデータを継続的に追加し続けます。これが時変モデルになります。 保存されるデータは常に時間とともに変化します。
不揮発性
データがデータウェアハウスに保存されると、変更または変更することはできません。 変更したいデータの変更されたコピーのみを追加できます。
統合:
前に述べたように、データウェアハウスは複数のソースからのデータを保持します。 AとBの2つのデータソースがあるとします。どちらのソースにもまったく異なるタイプのデータが保存されている可能性がありますが、ウェアハウスに持ち込まれると、前処理が行われます。 これが、データウェアハウスが多数のソースからのデータを統合する方法です。
データウェアハウスプロセス
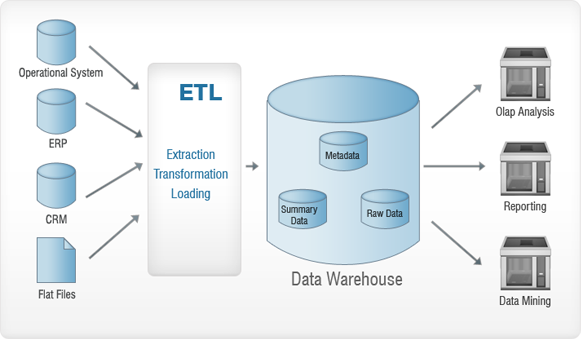
上の画像を見てください。 さまざまなソース(運用システム、ERP、CRM、フラットファイルなど)から収集されたデータは、データウェアハウスに挿入される前にETLプロセスを経て作成されます。 これは基本的に、データから異常がある場合はそれを削除するために行われます。これにより、データウェアハウスに害が生じることはありません。 ETLは、抽出、変換、および読み込みの略です。 これらの各プロセスを詳しく見ていきましょう。 よりよく理解するために、アナロジーを使用します–ゴールドラッシュを考えて読み進めてください!
抽出
抽出は基本的に、可能な限り少ないリソースを使用してソースシステムから必要なすべてのデータを収集するために行われます。
このステップは、できるだけ大きな金塊を探して川をパンするようなものだと考えてください。
変身
主な目的は、抽出されたデータを一般的な形式でデータベースに挿入することです。 これは、ソースごとにデータの保存形式が異なるためです。たとえば、一方のデータソースには「dd / mm / yyyy」形式のデータがあり、もう一方のデータソースには「dd-mm-yy」形式のデータがある場合があります。 このステップでは、これを一般化された形式に変換します。これは、すべてのソースからのデータに使用されます。
これで金塊ができました。 職業はなんですか? それを溶かし、不純物を取り除きます。
読み込み中
このステップでは、変換されたデータがターゲットデータベースにロードされます。
これで純金ができました–リングに成形して、売り払ってください!
さまざまなソースからデータを取得してデータウェアハウスに保存するプロセス(もちろん、ETLプロセスの後)は、データウェアハウスと呼ばれるものです。
これで、データが適切に配置されました。すべてがクリーンアップされ、準備が整いました。 次のステップは何ですか? 知識の抽出–はい!
データマイニングが救いの手を差し伸べます!
どうすればデータ分析に移行できますか?データマイニングとは何ですか?
データマイニングは、非常に簡単に言えば、これまで知られていなかったが潜在的に有用な情報をデータセットから抽出するプロセスです。 「これまで知られていなかった」とは、データウェアハウスを深く掘り下げた後にのみ取得できる知識を意味します。つまり、表面上は意味がありません。 データマイニングは基本的に、データ要素間に存在するグローバルパターンの関係を検索します。
たとえば、スーパーマーケットを経営しているとします。 さて、顧客の購入履歴は表面上は多くを明らかにするようには見えないかもしれませんが、注意深く分析すると、考えられるパターンを認識し、この情報だけで多くを与えることができます。 まだ推測していない場合は、ターゲットについて話します。ターゲットは、購入履歴を注意深く調べ、傾向とパターンを探すだけで、10代の少女(顧客)が妊娠していることを把握したスーパーマーケットです。 したがって、表面上は非常に些細なように見えた情報は、注意深く採掘したときに非常に価値があることがわかりました。これは、まさに「これまで知られていなかった知識」が意味するものです。

データウェアハウジングとデータマイニングのフレーバーを提供し、全体像であるデータベースの知識発見(KDD)を完全に無視すると、不公平になると思います。 データマイニングは、KDDプロセスのステップの1つです。KDDについてもう少し話しましょう。
世界のトップ大学からデータサイエンス認定を取得します。 エグゼクティブPGプログラム、高度な証明書プログラム、または修士プログラムに参加して、キャリアを早めに進めましょう。
データベースにおける知識発見(KDD)
データマイニングは、KDDのプロセスにおける最も重要なステップの1つです。 KDDは基本的に、データの選択から最終的にマイニングされたデータの評価まで、すべてをカバーします。 完全なKDDサイクルを下の画像に示します。
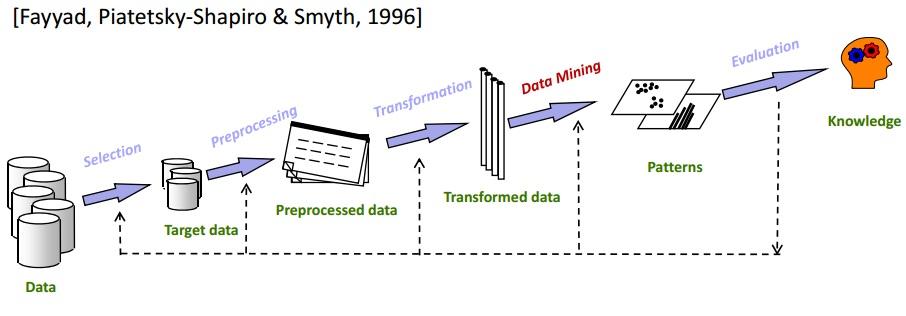
選択
正確なターゲットデータを知ることが最も重要です。 データマイニングをデータウェアハウスサブセットに分析することは非常に重要なステップです。これは、関連のないデータ要素を削除すると、データマイニングフェーズでの検索スペースが削減されるためです。
前処理
このステップでは、選択したデータから異常値や外れ値が解放されます。 基本的に、データはこのフェーズで完全にクリーンアップされます。 同様に、欠落しているデータフィールドがいくつかある場合、それらは適切な値で埋められます。 たとえば、組織の従業員の詳細を格納するテーブルに、「ミドルネーム」の列があるとします。 多くの従業員にとっては空になる可能性があります。 このようなシナリオでは、適切な値が選択されます(たとえば、N / A)。
変身
このフェーズでは、情報の品質を維持しながら、データ要素の種類を減らします。
データマイニング
これは、KDDプロセスのメインフェーズです。 変換されたデータは、グループ化、クラスタリング、回帰などのデータマイニング手法にかけられます。これは、最良の結果をもたらすために繰り返し実行されます。 要件に応じて、さまざまな手法を使用できます。
評価
これが最後のステップです。 この中で、得られた知識は文書化され、さらなる分析のために提示されます。 このステップでは、さまざまなデータ視覚化ツールを使用して、取得した知識を美しく理解しやすい方法で表現します。
シンプソンのパラドックスはデータにどのように影響しますか?
実際の使用-データマイニングの事例
Amazon、Flipkart、Netflix、Facebook、Twitter、Instagram、さらにはWalmartに至るまで、すべての組織がデータマイニングを有効に活用しています。 このセクションでは、日常生活に欠かせないデータマイニングの4つの幅広いユースケースについて説明します。
サービスプロバイダー
テレコムサービスプロバイダーは、データマイニングを使用して、「チャーン」を予測します。これは、顧客が別のプロバイダーにサービスを提供する際に使用する用語です。 それとは別に、彼らは請求情報、ウェブサイトへの訪問、カスタマーケアのやりとりなどを照合して、各顧客に確率スコアを与えます。 次に、「解約」のリスクが高い顧客には、オファーとインセンティブが提供されます。
Eコマース
Eコマースは、データマイニングに関して最もよく知られているユースケースです。 それらの中で最も有名なものの1つは、もちろん、Amazonです。 彼らは非常に洗練された採掘技術を使用しています。 たとえば、「その製品を見た人、これも気に入った」機能をチェックしてください。
スーパーマーケット
スーパーマーケットもデータマイニングの興味深いユースケースです。 顧客の購入履歴をマイニングすることで、顧客は購入パターンを理解できます。 この情報は、スーパーマーケットが顧客にパーソナライズされたオファーを提供するために使用されます。 ああ、ターゲットがデータマイニングを使用して何をしたかについてお話しましたか? (はい、やりました!)
小売り
小売業者は、顧客を最新性、頻度、および金銭(RFM)グループに分類します。 データマイニングを使用して、これらのグループにマーケティングをターゲティングします。 支出が少ないが頻繁で、最後の購入がかなり最近の顧客は、多くを費やしたが1回だけの顧客とは異なる方法で処理されます。
まとめ…
データウェアハウジングとデータマイニングは、今日世界を文字通り実行している最も重要なプロセスの2つを構成しています。 今日のほとんどすべての重要なことは、高度なデータマイニングの結果です。 マイニングされていないデータは、データがまったくないのと同じくらい有用(または役に立たない)だからです。
繰り返しになりますが、データマイニングとデータウェアハウスの違いを理解するには、データマイニングの概要からデータウェアハウスまで、さまざまなソースからのデータをすべて1つのデータベースに一元化する方法です。 データウェアハウジングは、コンパイルされた履歴データまたはリアルタイムのデータフィードとして定義でき、ほとんどが有機的で統合された情報を返します。
この記事で、データウェアハウジングやデータマイニングなどとは何かが明確になることを願っています。 結論として、単一のデータベースに情報を収集、保存、整理するプロセスは、データウェアハウスとデータマイニングの違いとして、ほとんどの場合、異なる視点を使用してデータから意味のある情報を抽出していると見なされます。 収集されたすべての有用な情報は、会社の成長の障害となる可能性のある将来の問題を解決するために後で使用でき、コストも削減できます。 あなたが明るく魅力的な未来を探していて、探検があなたの情熱であるなら、データウェアハウスとデータマイニングのWhats'Whatを学ぶことから始めることはあなたにとって素晴らしいオプションでしょう。
この記事で、これら2つの用語の意味などが明確になったことを願っています。 データサイエンスについて知りたい場合は、IIIT-BとupGradのデータサイエンスのPGディプロマをチェックしてください。これは、働く専門家向けに作成され、10以上のケーススタディとプロジェクト、実践的なハンズオンワークショップ、業界の専門家とのメンターシップ、1- on-1業界のメンター、400時間以上の学習、トップ企業との仕事の支援。
企業はデータウェアハウジングとデータマイニングをどのように使用していますか?
データマイニングとデータウェアハウジングはどちらも、情報(またはデータ)を使用可能な知識に変換するためのビジネスインテリジェンス技術です。
データマイニングは統計分析手法です。 アナリストは、トレンドを検索するためにギガバイト単位のデータを照会およびソートするために技術ツールを使用します。 次に、企業はこのデータを利用して、消費者とサプライヤーの行動の理解に基づいて、より良いビジネス上の意思決定を行います。
データウェアハウジングは、レポートと分析を容易にするためにデータを保存する方法を設計するプロセスです。 データウェアハウスの専門家によると、多数のデータストアは概念的にも物理的にも統合されており、相互に関連しています。 会社のデータは通常、複数のデータベースに保存されます。
データウェアハウスとデータマイニングの主な違いは何ですか? ビジネスの世界でどちらがより実用的ですか?
データウェアハウスはデータストレージシステムです。 通常、さまざまな目的のために複数のソースから取得されたさまざまな種類のデータが必要になります。 このデータを規律を持って保存し、後で取得できるようにするプロセスは、データウェアハウジングと呼ばれます。
データを抽出するプロセスは、データマイニングとして知られています。 それは特定の目標に最も適切な情報を見つけることを伴います。 それはあなたのデータウェアハウスから、または完全にどこか他の場所から来ているかもしれません。 実際の鉱石の場合と同じように、マイニングしたデータを精緻化してクリーンアップすることを期待しています。
倉庫システムが優れているほど、マイニングが容易になります。
データマイニングとKDDプロセスは似ていますか?
KDDとデータマイニングは頻繁に交換される用語ですが、これらは2つの異なるが関連する概念を指します。
データマイニングは、データのパターンの認識を処理するKDDプロセス内のコンポーネントですが、KDDはデータから知識を抽出するプロセス全体です。 別の言い方をすれば、データマイニングは、KDDプロセスの究極の目的を達成するための特定のアルゴリズムのアプリケーションにすぎません。